Elegir su topología HA
Hay varias formas de conservar la alta disponibilidad con las bases de datos. Puede usar IP virtuales (VRRP) para administrar la disponibilidad del host, puede usar administradores de recursos como Zookeeper y Etcd para (re) configurar sus aplicaciones o usar balanceadores de carga/proxies para distribuir la carga de trabajo entre todos los hosts disponibles.
Las IP virtuales necesitan una aplicación para administrarlas (MHA, Orchestrator), algunas secuencias de comandos (Keepalived, Pacemaker/Corosync) o un ingeniero para realizar la conmutación por error manualmente y la toma de decisiones en el proceso puede volverse compleja. La conmutación por error de IP virtual es un proceso directo y simple que elimina la dirección IP de un host, la asigna a otro y usa arp para enviar una respuesta ARP gratuita. En teoría, una IP virtual se puede mover en un segundo, pero pasarán unos segundos antes de que la aplicación de administración de conmutación por error esté segura de que el host ha fallado y actúe en consecuencia. En realidad, esto debería ser entre 10 y 30 segundos. Otra limitación de las IP virtuales es que algunos proveedores de la nube no le permiten administrar sus propias IP virtuales ni asignarlas en absoluto. Por ejemplo, Google no le permite hacer eso en sus nodos de cómputo.
Los administradores de recursos como Zookeeper y Etcd pueden monitorear sus bases de datos y (re)configurar sus aplicaciones una vez que un host falla o un esclavo es ascendido a maestro. En general, esta es una buena idea, pero implementar sus comprobaciones con Zookeeper y Etcd es una tarea compleja.
Un equilibrador de carga o proxy se ubicará entre la aplicación y el host de la base de datos y funcionará de manera transparente como si el cliente se conectara directamente al host de la base de datos. Al igual que con la IP virtual y los administradores de recursos, los balanceadores de carga y los proxies también necesitan monitorear los hosts y redirigir el tráfico si un host está inactivo. ClusterControl admite dos proxies:HAProxy y ProxySQL, y ambos son compatibles con la replicación maestro-esclavo de MySQL y el clúster de Galera. Tanto HAProxy como ProxySQL tienen sus propios casos de uso, también los describiremos en esta publicación.
¿Por qué necesita un equilibrador de carga?
En teoría, no necesita un balanceador de carga, pero en la práctica preferirá uno. Te explicamos por qué.
Si tiene una configuración de IP virtual, todo lo que tiene que hacer es apuntar su aplicación a la dirección IP (virtual) correcta y todo debería estar bien en cuanto a la conexión. Pero supongamos que ha escalado el número de réplicas de lectura, es posible que desee proporcionar direcciones IP virtuales para cada una de esas réplicas de lectura también por motivos de mantenimiento o disponibilidad. Esto podría convertirse en un grupo muy grande de direcciones IP virtuales que debe administrar. Si una de esas réplicas de lectura tuvo una falla, debe reasignar la IP virtual a otro host o, de lo contrario, su aplicación se conectará a un host que está inactivo o, en el peor de los casos, a un servidor retrasado con datos obsoletos. Por lo tanto, es necesario mantener el estado de replicación de la aplicación que administra las IP virtuales.
También para Galera existe un desafío similar:en teoría, puede agregar tantos hosts como desee a la configuración de su aplicación y elegir uno al azar. El mismo problema surge cuando este host está inactivo:es posible que termine conectándose a un host no disponible. Además, el uso de todos los hosts para lecturas y escrituras también podría causar reversiones debido al bloqueo optimista en Galera. Si dos conexiones intentan escribir en la misma fila al mismo tiempo, una de ellas recibirá una reversión. En caso de que su carga de trabajo tenga tales actualizaciones simultáneas, se recomienda usar solo un nodo en Galera para escribir. Por lo tanto, desea un administrador que realice un seguimiento del estado interno de su clúster de base de datos.
Tanto HAProxy como ProxySQL le ofrecerán la funcionalidad para monitorear los hosts de bases de datos MySQL/MariaDB y mantener el estado de su clúster y su topología. Para las configuraciones de replicación, en caso de que una réplica esclava esté inactiva, tanto HAProxy como ProxySQL pueden redistribuir las conexiones a otro host. Pero si un maestro de replicación está inactivo, HAProxy denegará la conexión y ProxySQL devolverá un error adecuado al cliente. Para las configuraciones de Galera, ambos balanceadores de carga pueden elegir un nodo maestro del clúster de Galera y solo enviar las operaciones de escritura a ese nodo específico.
En la superficie, HAProxy y ProxySQL pueden parecer soluciones similares, pero difieren mucho en las características y la forma en que distribuyen las conexiones y consultas. HAProxy admite una serie de algoritmos de equilibrio, como conexiones mínimas, fuente, aleatorias y por turnos, mientras que ProxySQL distribuye las conexiones mediante el algoritmo de turno por turnos basado en el peso (peso igual significa distribución equitativa). Dado que ProxySQL es un proxy inteligente, reconoce la base de datos y también puede analizar sus consultas. ProxySQL puede realizar una división de lectura/escritura en función de las reglas de consulta donde puede reenviar las consultas a los esclavos o maestros designados en su clúster. ProxySQL incluye funciones adicionales como reescritura de consultas, almacenamiento en caché y firewall de consultas con generación de estadísticas detalladas en tiempo real sobre la carga de trabajo.
Esa debería ser suficiente información básica sobre este tema, así que veamos cómo puede implementar balanceadores de carga para la replicación de MySQL y las topologías de Galera.
Implementación de HAProxy
Usar ClusterControl para implementar HAProxy en un clúster de Galera es fácil:vaya al clúster correspondiente y seleccione "Agregar balanceador de carga":
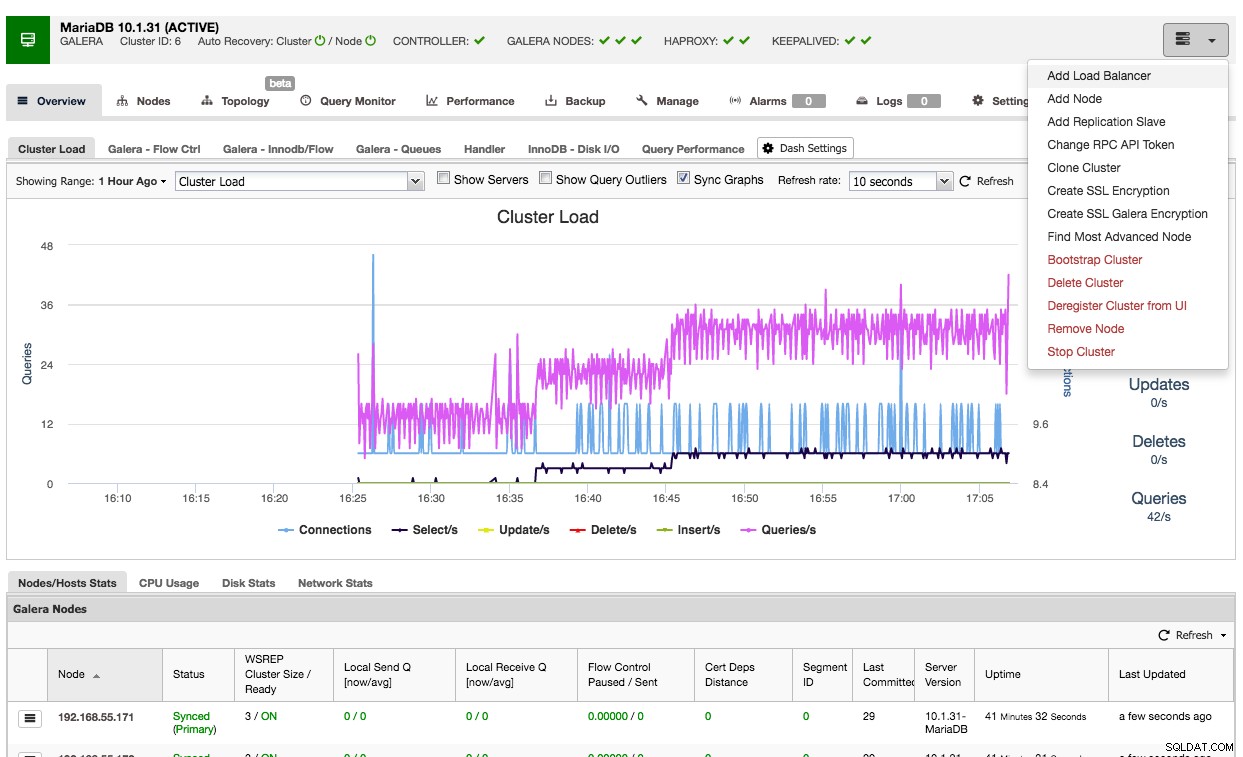
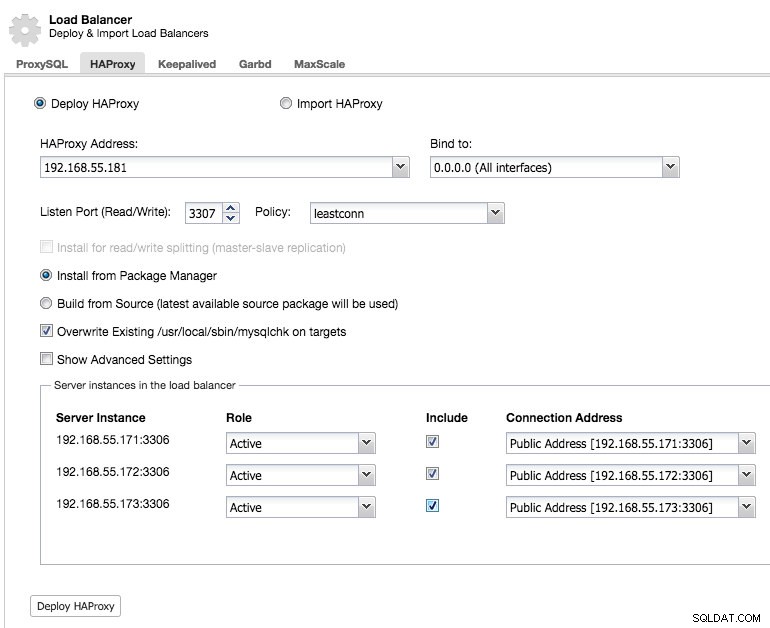
Y podrá implementar una instancia HAProxy agregando la dirección del host y seleccionando las instancias del servidor que desea incluir en la configuración:
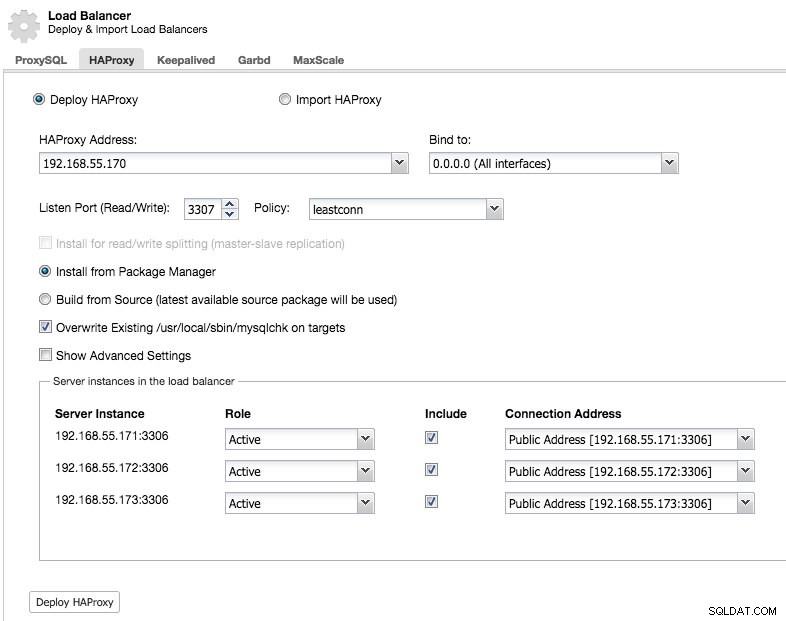
De manera predeterminada, la instancia de HAProxy se configurará para enviar conexiones a las instancias del servidor que reciben la menor cantidad de conexiones, pero puede cambiar esa política a turno rotatorio o fuente.
En la configuración avanzada, puede establecer tiempos de espera, la cantidad máxima de conexiones e incluso proteger el proxy mediante la inclusión en la lista blanca de un rango de IP para las conexiones.
En la pestaña de nodos de ese clúster, aparecerá el nodo HAProxy:
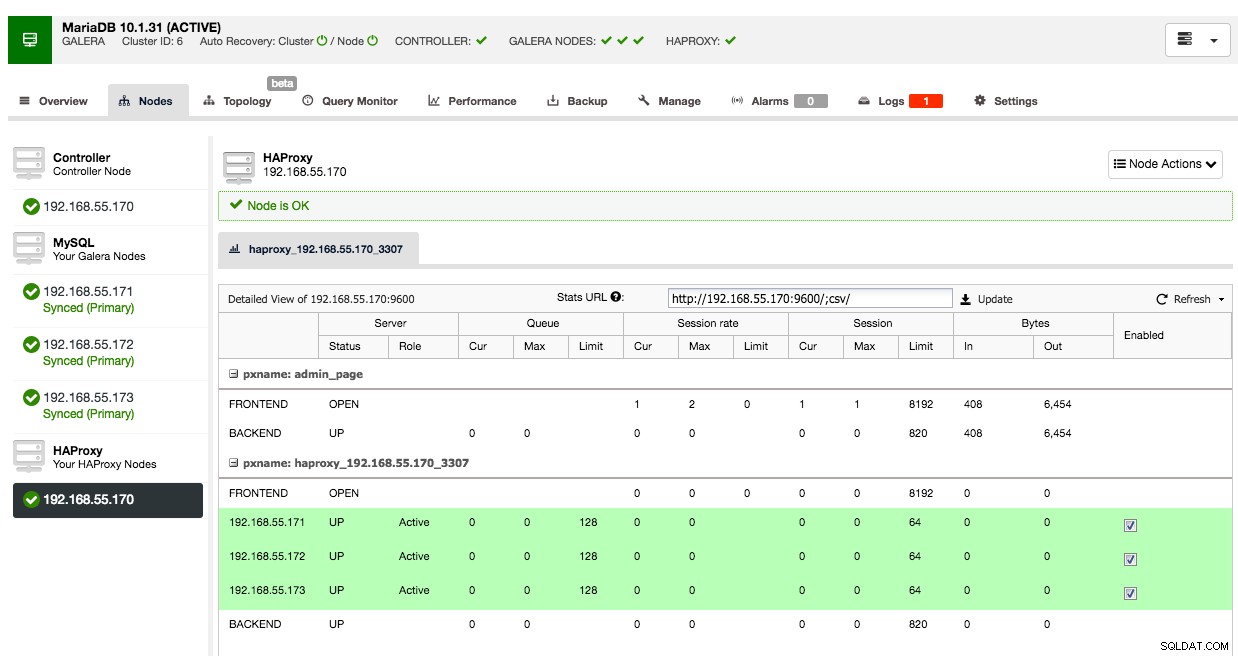
Ahora su clúster Galera también está disponible a través del nodo HAProxy recién implementado en el puerto 3307. No olvide OTORGAR acceso a su aplicación desde la IP HAProxy, ya que ahora el tráfico provendrá del proxy en lugar de los hosts de la aplicación. Además, recuerde apuntar la conexión de su aplicación al nodo HAProxy.
Ahora supongamos que la instancia de un servidor dejaría de funcionar, HAProxy lo notará en unos segundos y dejará de enviar tráfico a esta instancia:
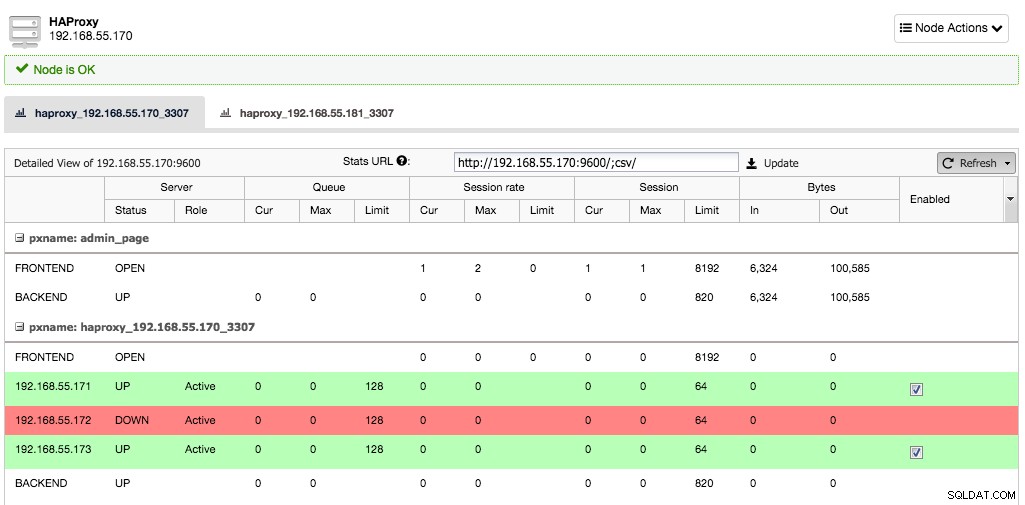
Los otros dos nodos todavía están bien y seguirán recibiendo tráfico. Esto mantiene el clúster altamente disponible sin que el cliente note la diferencia.
Implementación de un nodo HAProxy secundario
Ahora que hemos trasladado la responsabilidad de mantener la alta disponibilidad en las conexiones de la base de datos del cliente a HAProxy, ¿qué sucede si el nodo proxy muere? La respuesta es crear otra instancia HAProxy y usar una IP virtual controlada por Keepalived como se muestra en este diagrama:
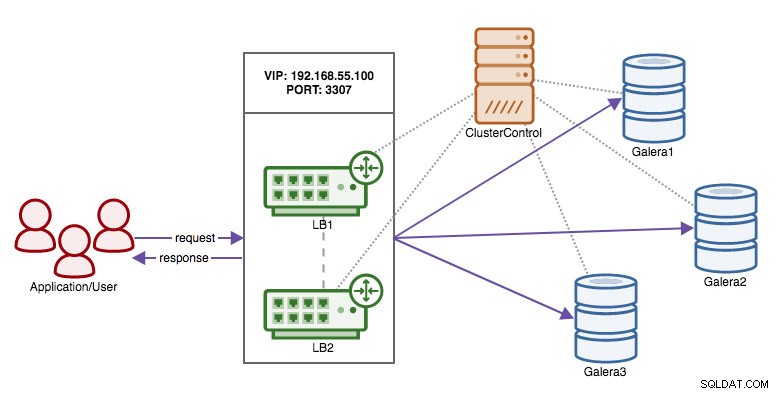
El beneficio en comparación con el uso de direcciones IP virtuales en los nodos de la base de datos es que la lógica de MySQL está en el nivel de proxy y la conmutación por error para los proxies es simple.
Entonces, implementemos un nodo HAProxy secundario:
Después de implementar un nodo HAProxy secundario, debemos agregar Keepalived:
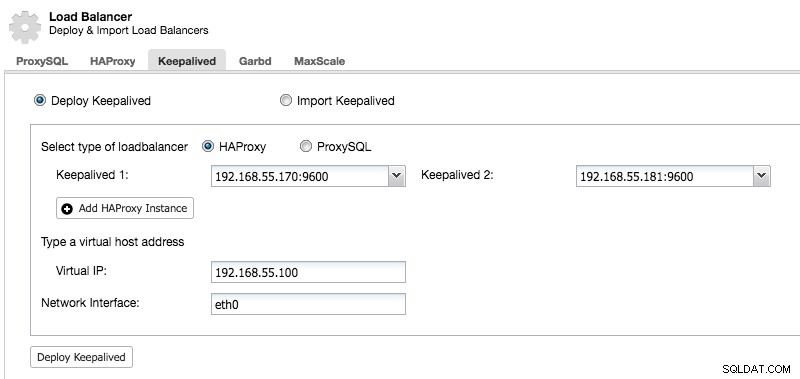
Y después de que se haya agregado Keepalived, la descripción general de sus nodos se verá así:
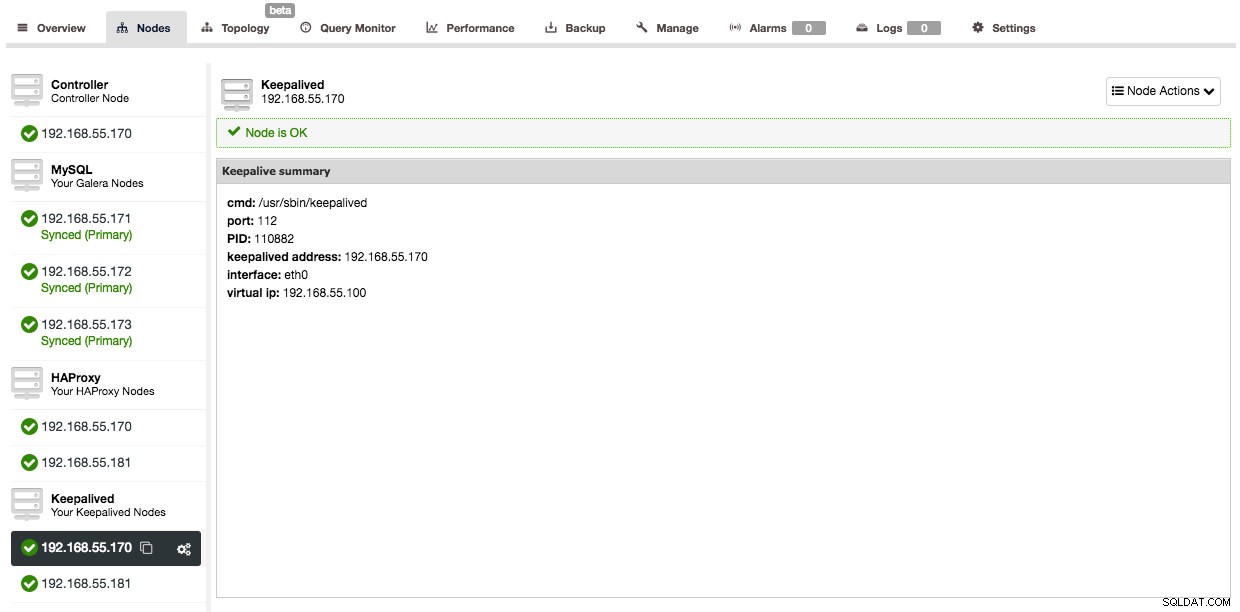
Así que ahora, en lugar de apuntar las conexiones de su aplicación al nodo HAProxy directamente, debe apuntarlas a la IP virtual.
En el ejemplo aquí, usamos hosts separados para ejecutar HAProxy, pero también podría agregarlos fácilmente a instancias de servidor existentes. HAProxy no genera muchos gastos generales, aunque debe tener en cuenta que, en caso de falla del servidor, perderá tanto el nodo de la base de datos como el proxy.
Implementación de ProxySQL
La implementación de ProxySQL en su clúster se realiza de forma similar a HAProxy:"Agregar Load Balancer" en la lista de clústeres en la pestaña ProxySQL.
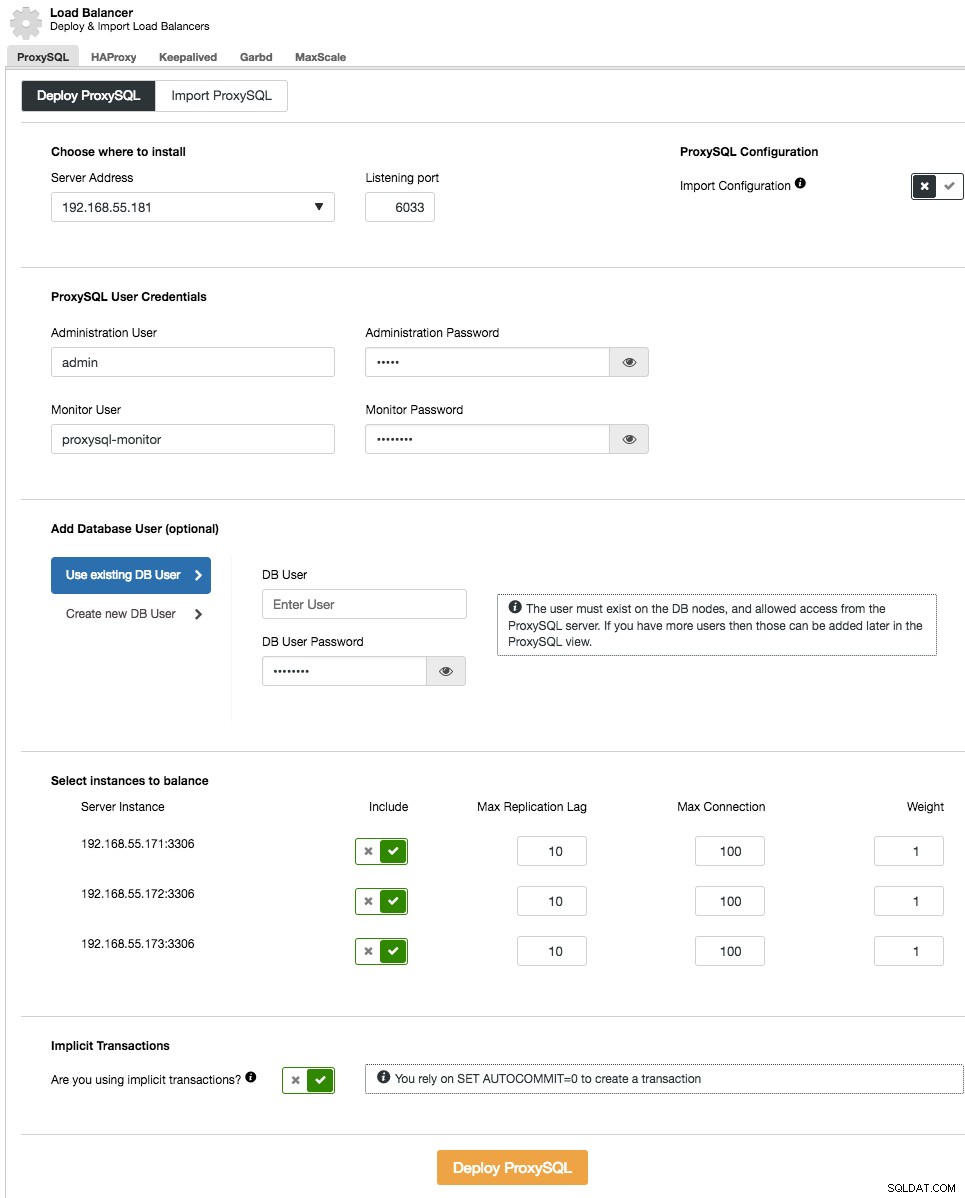
En el asistente de implementación, especifique dónde se instalará ProxySQL, el usuario/contraseña de administración, el usuario/contraseña de supervisión para conectarse a los backends de MySQL. Desde ClusterControl, puede crear un nuevo usuario para que lo use la aplicación (el usuario se creará tanto en MySQL como en ProxySQL) o usar los usuarios de la base de datos existente (el usuario se creará solo en ProxySQL). Establezca si está utilizando transacciones implícitas o no. Básicamente, si no usa SET autocommit=0 para crear una nueva transacción, ClusterControl configurará la división de lectura/escritura.
Después de implementar ProxySQL, estará disponible en la pestaña Nodos:
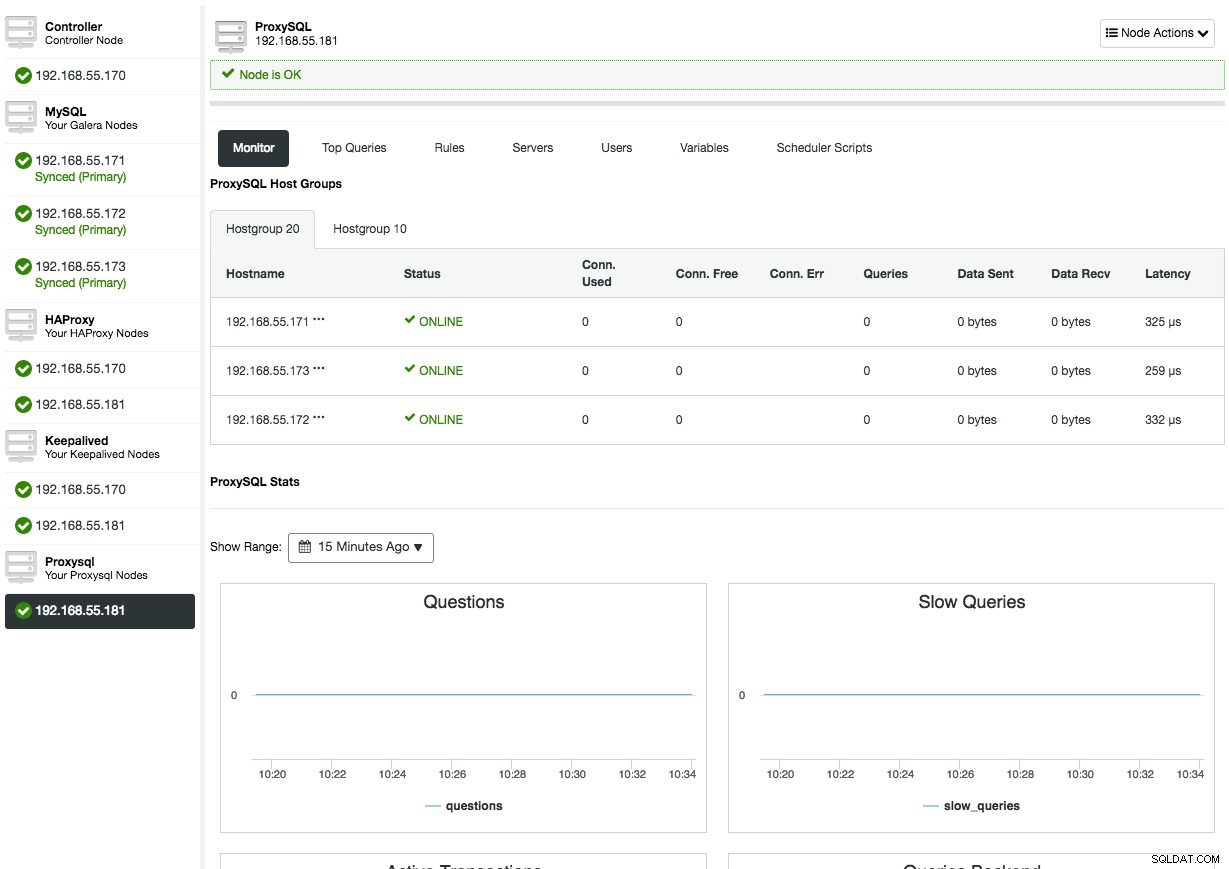
Al abrir la descripción general del nodo de ProxySQL, se le presentará la interfaz de administración y monitoreo de ProxySQL, por lo que ya no hay razón para iniciar sesión en ProxySQL en el nodo. ClusterControl cubre la mayoría de las estadísticas importantes de ProxySQL, como la utilización de la memoria, la caché de consultas, el procesador de consultas, etc., así como otras métricas, como grupos de host, servidores backend, aciertos de reglas de consulta, consultas principales y variables de ProxySQL. En el aspecto de administración de ProxySQL, puede administrar las reglas de consulta, los servidores backend, los usuarios, la configuración y el programador directamente desde la interfaz de usuario.
Consulte nuestra página de tutoriales de ProxySQL que cubre ampliamente cómo realizar el equilibrio de carga de la base de datos para MySQL y MariaDB con ProxySQL.
Implementación de Garbd
Galera implementa un algoritmo basado en quórum para seleccionar un componente principal a través del cual impone coherencia. El componente principal debe tener una mayoría de votos (50 % + 1 nodo), por lo que en un sistema de 2 nodos, no habría mayoría que resulte en un cerebro dividido. Afortunadamente, es posible agregar un garbd (Galera Arbitrator Daemon), que es un demonio liviano sin estado que puede actuar como un nodo impar. El beneficio adicional al agregar Galera Arbitrator es que ahora puede hacerlo con solo dos nodos en su clúster.
Si ClusterControl detecta que su clúster de Galera consta de un número par de nodos, ClusterControl le dará la advertencia/consejo para extender el clúster a un número impar de nodos:
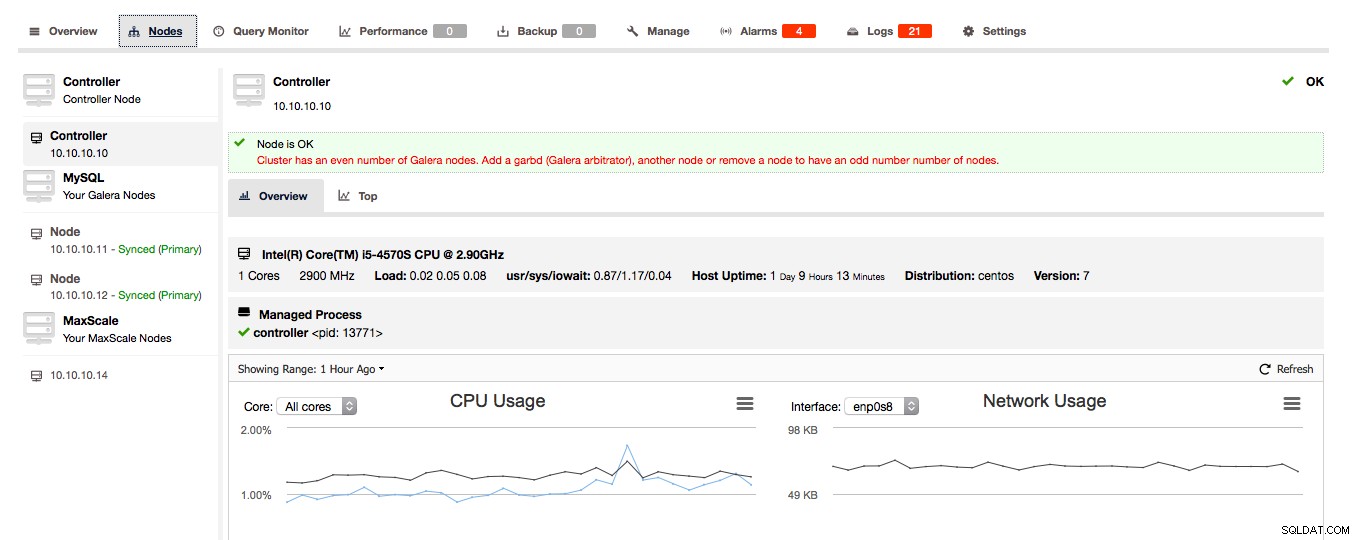
Elija sabiamente el host para implementar garbd, ya que recibirá todos los datos replicados. Asegúrese de que la red pueda manejar el tráfico y sea lo suficientemente segura. Puede elegir uno de los hosts HAProxy o ProxySQL para implementar garbd, como en el siguiente ejemplo:
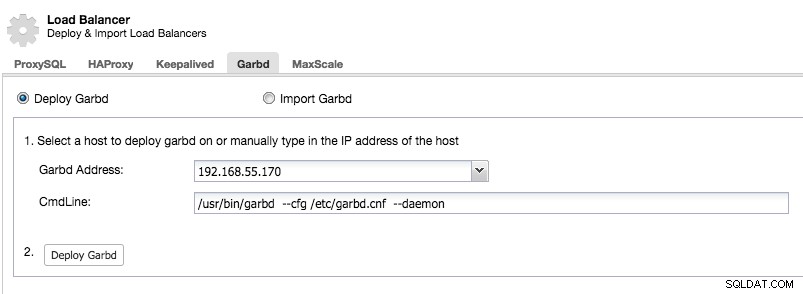
Tenga en cuenta que a partir de ClusterControl 1.5.1, garbd no se puede instalar en el mismo host que ClusterControl debido al riesgo de conflictos de paquetes.
Después de instalar garbd, verá que aparece junto a sus dos nodos de Galera:

Reflexiones finales
Le mostramos cómo hacer que sus configuraciones de clúster MySQL maestro-esclavo y Galera sean más sólidas y mantengan una alta disponibilidad usando HAProxy y ProxySQL. Además, garbd es un buen demonio que puede guardar el tercer nodo adicional en su clúster de Galera.
Esto finaliza el lado de implementación de ClusterControl. En nuestro próximo blog, le mostraremos cómo integrar ClusterControl dentro de su organización mediante el uso de grupos y la asignación de ciertos roles a los usuarios.