Alguien borró accidentalmente parte de la base de datos. Alguien olvidó incluir una cláusula WHERE en una consulta DELETE o eliminó la tabla incorrecta. Cosas así pueden pasar y pasarán, es inevitable y humano. Pero el impacto puede ser desastroso. ¿Qué puede hacer para protegerse contra tales situaciones y cómo puede recuperar sus datos? En esta publicación de blog, cubriremos algunos de los casos más típicos de pérdida de datos y cómo puede prepararse para recuperarse de ellos.
Preparativos
Hay cosas que debe hacer para garantizar una recuperación sin problemas. Vamos a repasarlos. Tenga en cuenta que no se trata de una situación de "elegir una"; idealmente, implementará todas las medidas que analizaremos a continuación.
Copia de seguridad
Tienes que tener una copia de seguridad, no hay escapatoria. Debe hacer que se prueben sus archivos de copia de seguridad; a menos que pruebe sus copias de seguridad, no puede estar seguro de si son buenas y si alguna vez podrá restaurarlas. Para la recuperación ante desastres, debe conservar una copia de su copia de seguridad en algún lugar fuera de su centro de datos, en caso de que todo el centro de datos no esté disponible. Para acelerar la recuperación, es muy útil mantener una copia de la copia de seguridad también en los nodos de la base de datos. Si su conjunto de datos es grande, copiarlo a través de la red desde un servidor de respaldo al nodo de la base de datos que desea restaurar puede llevar mucho tiempo. Mantener la copia de seguridad más reciente localmente puede mejorar significativamente los tiempos de recuperación.
Copia de seguridad lógica
Lo más probable es que su primera copia de seguridad sea una copia de seguridad física. Para MySQL o MariaDB, será algo como xtrabackup o algún tipo de instantánea del sistema de archivos. Tales copias de seguridad son excelentes para restaurar un conjunto de datos completo o para aprovisionar nuevos nodos. Sin embargo, en caso de eliminación de un subconjunto de datos, sufren una sobrecarga significativa. En primer lugar, no puede restaurar todos los datos o sobrescribirá todos los cambios que ocurrieron después de que se creó la copia de seguridad. Lo que está buscando es la capacidad de restaurar solo un subconjunto de datos, solo las filas que se eliminaron accidentalmente. Para hacer eso con una copia de seguridad física, tendría que restaurarla en un host separado, ubicar las filas eliminadas, volcarlas y luego restaurarlas en el clúster de producción. Copiar y restaurar cientos de gigabytes de datos solo para recuperar un puñado de filas es algo que definitivamente llamaríamos una sobrecarga significativa. Para evitarlo, puede usar copias de seguridad lógicas:en lugar de almacenar datos físicos, dichas copias de seguridad almacenan datos en formato de texto. Esto facilita la localización de los datos exactos que se eliminaron, que luego se pueden restaurar directamente en el clúster de producción. Para hacerlo aún más fácil, también puede dividir dicha copia de seguridad lógica en partes y hacer una copia de seguridad de todas y cada una de las tablas en un archivo separado. Si su conjunto de datos es grande, tendrá sentido dividir un archivo de texto enorme tanto como sea posible. Esto hará que la copia de seguridad sea inconsistente, pero para la mayoría de los casos, esto no es un problema:si necesita restaurar todo el conjunto de datos a un estado consistente, utilizará la copia de seguridad física, que es mucho más rápida en este sentido. Si necesita restaurar solo un subconjunto de datos, los requisitos de coherencia son menos estrictos.
Recuperación de un punto en el tiempo
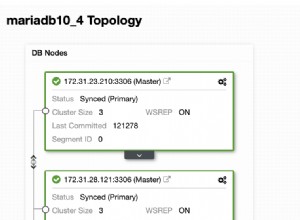
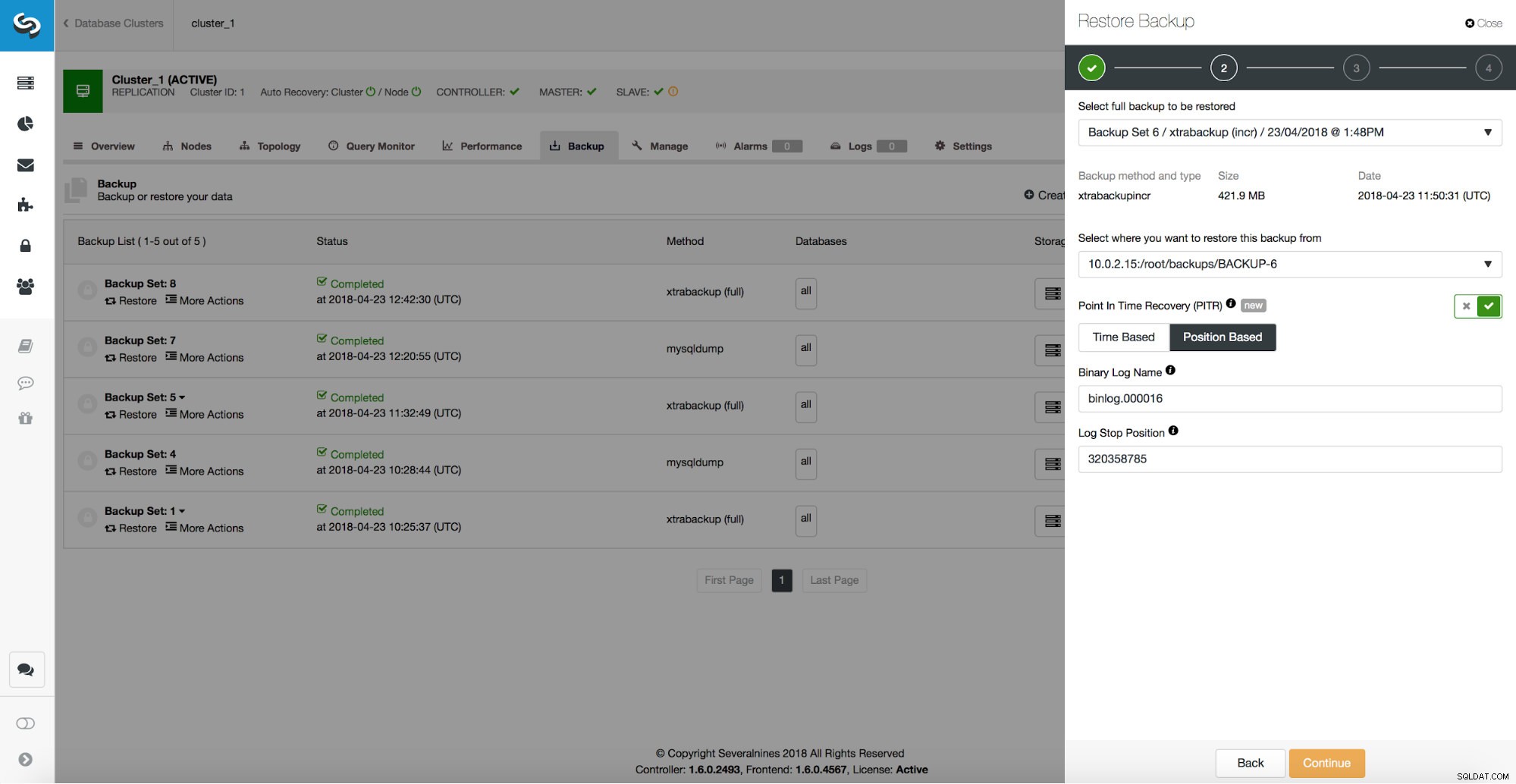
La copia de seguridad es solo el comienzo:podrá restaurar sus datos hasta el punto en que se realizó la copia de seguridad pero, lo más probable, los datos se eliminaron después de ese tiempo. Con solo restaurar los datos faltantes de la última copia de seguridad, puede perder los datos que se cambiaron después de la copia de seguridad. Para evitarlo, debe implementar la recuperación en un momento dado. Para MySQL, básicamente significa que tendrá que usar registros binarios para reproducir todos los cambios que ocurrieron entre el momento de la copia de seguridad y el evento de pérdida de datos. La siguiente captura de pantalla muestra cómo ClusterControl puede ayudar con eso.
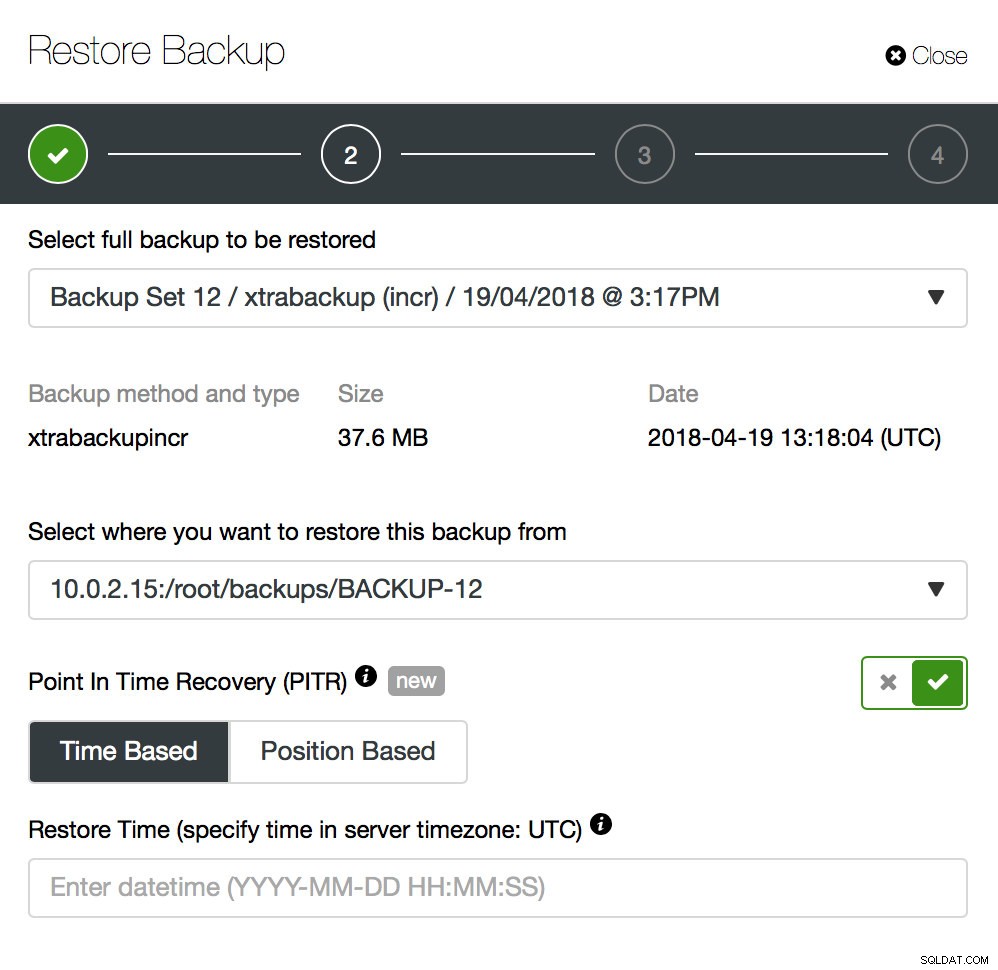
Lo que tendrás que hacer es restaurar esta copia de seguridad hasta el momento justo antes de la pérdida de datos. Tendrá que restaurarlo en un host separado para no realizar cambios en el clúster de producción. Una vez que haya restaurado la copia de seguridad, puede iniciar sesión en ese host, encontrar los datos que faltan, volcarlos y restaurarlos en el clúster de producción.
Esclavo retrasado
Todos los métodos que discutimos anteriormente tienen un punto débil común:se necesita tiempo para restaurar los datos. Puede tomar más tiempo cuando restaura todos los datos y luego intenta volcar solo la parte interesante. Puede tomar menos tiempo si tiene una copia de seguridad lógica y puede profundizar rápidamente en los datos que desea restaurar, pero de ninguna manera es una tarea rápida. Todavía tiene que encontrar un par de filas en un archivo de texto grande. Cuanto más grande es, más complicada se vuelve la tarea; a veces, el gran tamaño del archivo ralentiza todas las acciones. Un método para evitar esos problemas es tener un esclavo retrasado. Los esclavos generalmente intentan mantenerse al día con el maestro, pero también es posible configurarlos para que se mantengan alejados de su maestro. En la siguiente captura de pantalla, puede ver cómo usar ClusterControl para implementar un esclavo de este tipo:
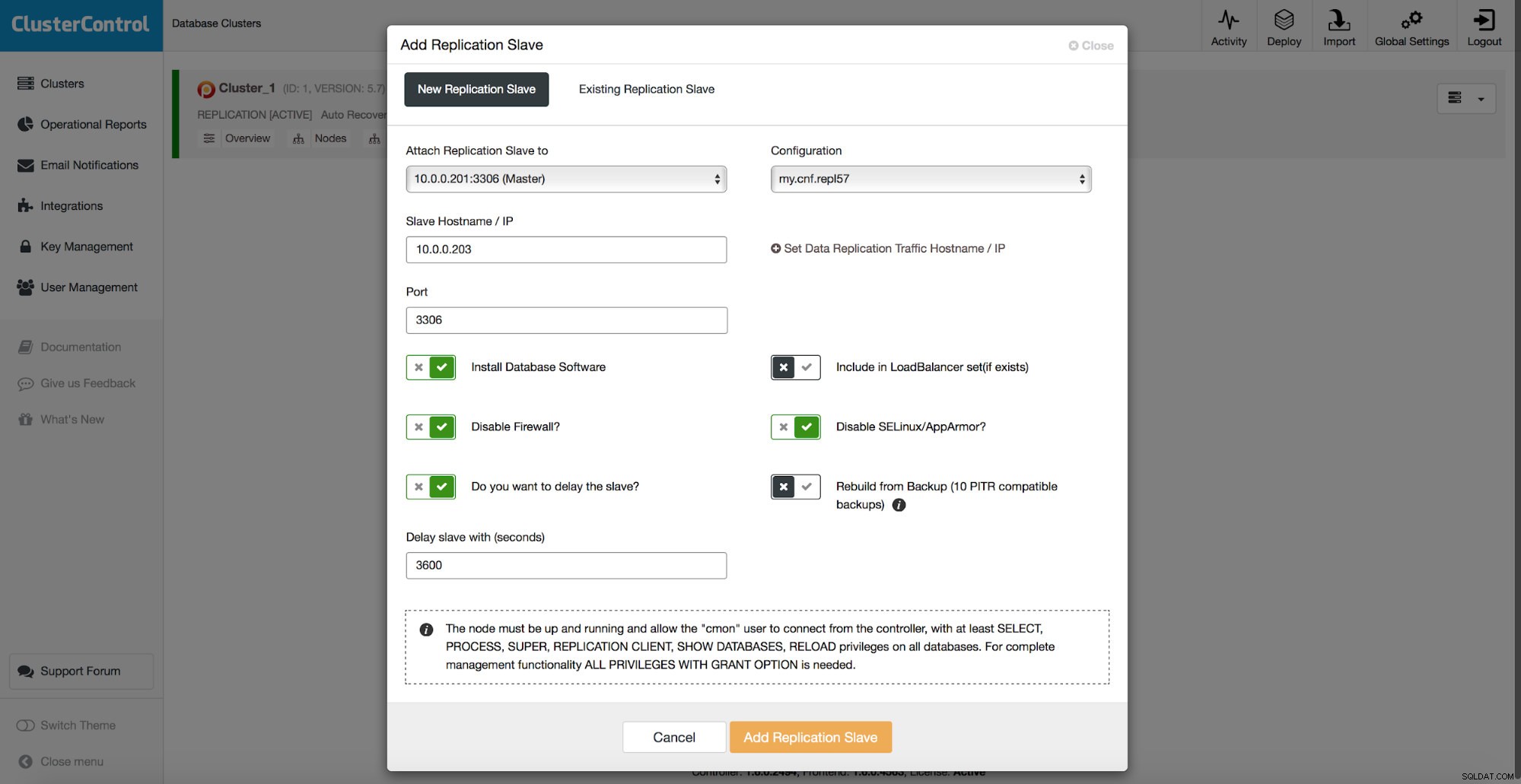
En resumen, aquí tenemos una opción para agregar un esclavo de replicación a la configuración de la base de datos y configurarlo para que se retrase. En la captura de pantalla anterior, el esclavo se retrasará 3600 segundos, que es una hora. Esto le permite usar ese esclavo para recuperar los datos eliminados hasta una hora después de la eliminación de datos. No tendrá que restaurar una copia de seguridad, bastará con ejecutar mysqldump o SELECT ... INTO OUTFILE para los datos que faltan y obtendrá los datos para restaurar en su clúster de producción.
Restauración de datos
En esta sección, veremos un par de ejemplos de eliminación accidental de datos y cómo puede recuperarse de ellos. Recorreremos la recuperación de una pérdida total de datos, también mostraremos cómo recuperarse de una pérdida parcial de datos cuando se utilizan copias de seguridad físicas y lógicas. Finalmente, le mostraremos cómo restaurar las filas eliminadas accidentalmente si tiene un esclavo retrasado en su configuración.
Pérdida total de datos
Accidental “rm -rf” o “DROP SCHEMA myonlyschema;” se ha ejecutado y terminó sin datos en absoluto. Si también eliminó archivos que no fueran del directorio de datos de MySQL, es posible que deba reaprovisionar el host. Para simplificar las cosas, supondremos que solo MySQL se ha visto afectado. Consideremos dos casos, con un esclavo retrasado y sin uno.
Sin esclavo retrasado
En este caso lo único que podemos hacer es restaurar la última copia de seguridad física. Como todos nuestros datos han sido eliminados, no necesitamos preocuparnos por la actividad que ocurrió después de la pérdida de datos porque sin datos, no hay actividad. Deberíamos estar preocupados por la actividad que ocurrió después de que se realizó la copia de seguridad. Esto significa que tenemos que hacer una restauración a un punto en el tiempo. Por supuesto, tomará más tiempo que simplemente restaurar los datos de la copia de seguridad. Si recuperar su base de datos rápidamente es más crucial que restaurar todos los datos, también puede restaurar una copia de seguridad y estar de acuerdo.
En primer lugar, si aún tiene acceso a los registros binarios en el servidor que desea restaurar, puede usarlos para PITR. Primero, queremos convertir la parte relevante de los registros binarios en un archivo de texto para una mayor investigación. Sabemos que la pérdida de datos ocurrió después de las 13:00:00. Primero, verifiquemos qué archivo binlog debemos investigar:
example@sqldat.com:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:32 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:33 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:35 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:38 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:39 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:41 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:43 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:45 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:47 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:49 /var/lib/mysql/binlog.000010
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:51 /var/lib/mysql/binlog.000011
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:53 /var/lib/mysql/binlog.000012
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:55 /var/lib/mysql/binlog.000013
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:57 /var/lib/mysql/binlog.000014
-rw-r----- 1 mysql mysql 1.1G Apr 23 10:59 /var/lib/mysql/binlog.000015
-rw-r----- 1 mysql mysql 306M Apr 23 13:18 /var/lib/mysql/binlog.000016Como puede verse, estamos interesados en el último archivo binlog.
example@sqldat.com:~# mysqlbinlog --start-datetime='2018-04-23 13:00:00' --verbose /var/lib/mysql/binlog.000016 > sql.outUna vez hecho esto, echemos un vistazo al contenido de este archivo. Buscaremos 'drop schema' en vim. Aquí hay una parte relevante del archivo:
# at 320358785
#180423 13:18:58 server id 1 end_log_pos 320358850 CRC32 0x0893ac86 GTID last_committed=307804 sequence_number=307805 rbr_only=no
SET @@SESSION.GTID_NEXT= '52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415'/*!*/;
# at 320358850
#180423 13:18:58 server id 1 end_log_pos 320358946 CRC32 0x487ab38e Query thread_id=55 exec_time=1 error_code=0
SET TIMESTAMP=1524489538/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
drop schema sbtest
/*!*/;Como podemos ver, queremos restaurar hasta la posición 320358785. Podemos pasar estos datos a la interfaz de usuario de ClusterControl:
Esclavo retrasado
Si tenemos un esclavo retrasado y ese host es suficiente para manejar todo el tráfico, podemos usarlo y promoverlo a maestro. Sin embargo, primero debemos asegurarnos de que se haya puesto al día con el antiguo maestro hasta el punto de la pérdida de datos. Usaremos algo de CLI aquí para que esto suceda. Primero, necesitamos averiguar en qué posición ocurrió la pérdida de datos. Luego, detendremos el esclavo y lo dejaremos correr hasta el evento de pérdida de datos. Mostramos cómo obtener la posición correcta en la sección anterior, examinando registros binarios. Podemos usar esa posición (binlog.000016, posición 320358785) o, si usamos un esclavo multiproceso, debemos usar el GTID del evento de pérdida de datos (52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415) y reproducir consultas hasta ese GTID.
Primero, detengamos el esclavo y deshabilitemos el retraso:
mysql> STOP SLAVE;
Query OK, 0 rows affected (0.01 sec)
mysql> CHANGE MASTER TO MASTER_DELAY = 0;
Query OK, 0 rows affected (0.02 sec)Luego podemos iniciarlo en una posición de registro binario determinada.
mysql> START SLAVE UNTIL MASTER_LOG_FILE='binlog.000016', MASTER_LOG_POS=320358785;
Query OK, 0 rows affected (0.01 sec)Si quisiéramos usar GTID, el comando se verá diferente:
mysql> START SLAVE UNTIL SQL_BEFORE_GTIDS = ‘52d08e9d-46d2-11e8-aa17-080027e8bf1b:443415’;
Query OK, 0 rows affected (0.01 sec)Una vez que se detuvo la replicación (lo que significa que se ejecutaron todos los eventos que solicitamos), debemos verificar que el host contenga los datos que faltan. Si es así, puede promoverlo a maestro y luego reconstruir otros hosts utilizando el nuevo maestro como fuente de datos.
Esta no siempre es la mejor opción. Todo depende de qué tan retrasado esté su esclavo:si se retrasa un par de horas, puede que no tenga sentido esperar a que se ponga al día, especialmente si el tráfico de escritura es pesado en su entorno. En tal caso, lo más probable es que sea más rápido reconstruir hosts usando una copia de seguridad física. Por otro lado, si tiene un volumen de tráfico bastante pequeño, esta podría ser una buena manera de solucionar el problema rápidamente, promocionar un nuevo maestro y seguir sirviendo el tráfico, mientras que el resto de los nodos se reconstruyen en segundo plano. .
Pérdida parcial de datos:copia de seguridad física
En caso de pérdida parcial de datos, las copias de seguridad físicas pueden ser ineficientes pero, dado que son el tipo más común de copia de seguridad, es muy importante saber cómo usarlas para una restauración parcial. El primer paso siempre será restaurar una copia de seguridad hasta un punto en el tiempo antes del evento de pérdida de datos. También es muy importante restaurarlo en un host separado. ClusterControl usa xtrabackup para copias de seguridad físicas, por lo que le mostraremos cómo usarlo. Supongamos que ejecutamos la siguiente consulta incorrecta:
DELETE FROM sbtest1 WHERE id < 23146;
Queríamos eliminar solo una fila ('=' en la cláusula WHERE), en lugar de eso, eliminamos un montón de ellas (
Ahora, echemos un vistazo al archivo de salida y veamos qué podemos encontrar allí. Estamos utilizando la replicación basada en filas, por lo tanto, no veremos el SQL exacto que se ejecutó. En su lugar (siempre que usemos la marca --verbose para mysqlbinlog) veremos eventos como los siguientes:
Como se puede ver, MySQL identifica las filas para eliminar usando una condición WHERE muy precisa. Signos misteriosos en el comentario legible por humanos, "@1", "@2", significan "primera columna", "segunda columna". Sabemos que la primera columna es 'id', que es algo que nos interesa. Necesitamos encontrar un evento DELETE grande en una tabla 'sbtest1'. Los comentarios que seguirán deben mencionar la identificación de 1, luego la identificación de '2', luego '3' y así sucesivamente, todo hasta la identificación de '23145'. Todo debe ejecutarse en una sola transacción (evento único en un registro binario). Después de analizar la salida usando 'menos', encontramos:
El evento, al que se adjuntan esos comentarios, comenzó en:
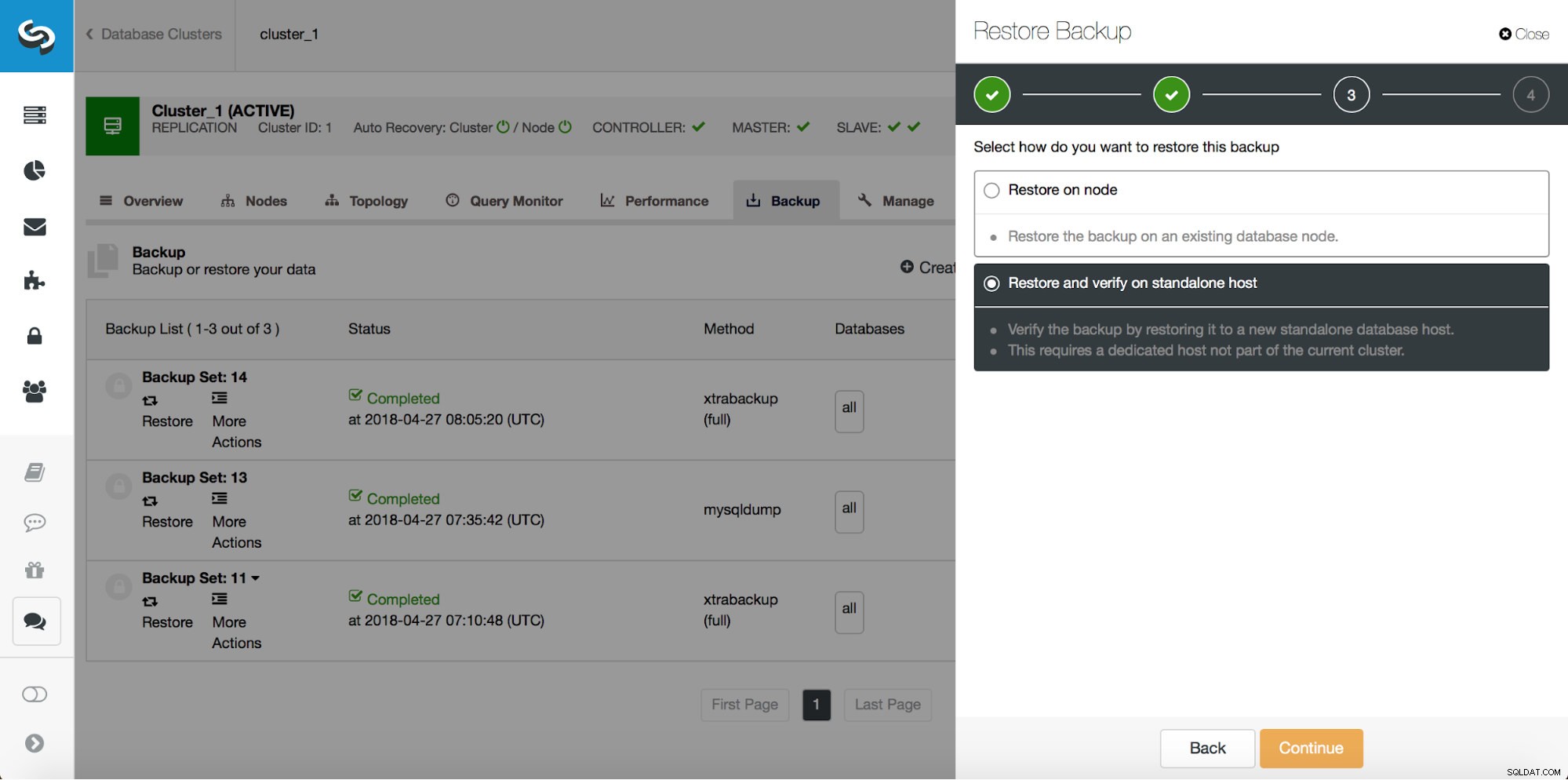
Entonces, queremos restaurar la copia de seguridad hasta la confirmación anterior en la posición 29600687. Hagámoslo ahora. Usaremos un servidor externo para eso. Restauraremos la copia de seguridad hasta esa posición y mantendremos el servidor de restauración en funcionamiento para que luego podamos extraer los datos que faltan.
Una vez que se complete la restauración, asegurémonos de que nuestros datos se hayan recuperado:
Se ve bien. Ahora podemos extraer estos datos en un archivo que volveremos a cargar en el maestro.
Algo no está bien, esto se debe a que el servidor está configurado para poder escribir archivos solo en una ubicación en particular. Se trata de seguridad, no queremos permitir que los usuarios guarden contenido donde quieran. Veamos dónde podemos guardar nuestro archivo:
Bien, intentemos una vez más:
Ahora se ve mucho mejor. Copiemos los datos al maestro:
Ahora es el momento de cargar las filas que faltan en el maestro y probar si tuvo éxito:
Eso es todo, restauramos nuestros datos faltantes.
En la sección anterior, restauramos los datos perdidos mediante una copia de seguridad física y un servidor externo. ¿Qué pasaría si tuviéramos una copia de seguridad lógica creada? Vamos a ver. Primero, verifiquemos que tenemos una copia de seguridad lógica:
Sí, está ahí. Ahora es el momento de descomprimirlo.
Cuando lo mire, verá que los datos se almacenan en formato INSERT de valores múltiples. Por ejemplo:
Todo lo que tenemos que hacer ahora es señalar dónde se encuentra nuestra tabla y luego dónde se almacenan las filas que nos interesan. Primero, conociendo los patrones de mysqldump (eliminar tabla, crear una nueva, deshabilitar índices, insertar datos), averigüemos qué línea contiene la instrucción CREATE TABLE para la tabla 'sbtest1':
Ahora, usando un método de prueba y error, necesitamos averiguar dónde buscar nuestras filas. Le mostraremos el comando final que se nos ocurrió. Todo el truco es intentar imprimir diferentes rangos de líneas usando sed y luego verificar si la última línea contiene filas cercanas, pero posteriores a lo que estamos buscando. En el siguiente comando buscamos líneas entre 971 (CREATE TABLE) y 993. También le pedimos a sed que salga una vez que llegue a la línea 994 ya que el resto del archivo no nos interesa:
El resultado se ve a continuación:
Esto significa que nuestro rango de filas (hasta la fila con id de 23145) está cerca. A continuación, se trata de la limpieza manual del archivo. Queremos que comience con la primera fila que necesitamos restaurar:
Y termine con la última fila para restaurar:
Tuvimos que recortar algunos de los datos innecesarios (es una inserción de varias líneas), pero después de todo esto, tenemos un archivo que podemos volver a cargar en el maestro.
Finalmente, último control:
Todo está bien, los datos han sido restaurados.
En este caso, no pasaremos por todo el proceso. Ya describimos cómo identificar la posición de un evento de pérdida de datos en los registros binarios. También describimos cómo detener un esclavo retrasado y comenzar la replicación nuevamente, hasta un punto antes del evento de pérdida de datos. También explicamos cómo usar SELECT INTO OUTFILE y LOAD DATA INFILE para exportar datos desde un servidor externo y cargarlos en el maestro. Eso es todo lo que necesitas. Siempre que los datos aún estén en el esclavo retrasado, debe detenerlo. Luego, debe ubicar la posición antes del evento de pérdida de datos, iniciar el esclavo hasta ese punto y, una vez hecho esto, usar el esclavo retrasado para extraer los datos que se eliminaron, copiar el archivo al maestro y cargarlo para restaurar los datos. .
Restaurar datos perdidos no es divertido, pero si sigue los pasos que vimos en este blog, tendrá buenas posibilidades de recuperar lo que perdió.mysqlbinlog --verbose /var/lib/mysql/binlog.000003 > bin.out### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=999296
### @2=1009782
### @3='96260841950-70557543083-97211136584-70982238821-52320653831-03705501677-77169427072-31113899105-45148058587-70555151875'
### @4='84527471555-75554439500-82168020167-12926542460-82869925404'### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=1
### @2=1006036
### @3='123'
### @4='43683718329-48150560094-43449649167-51455516141-06448225399'
### DELETE FROM `sbtest`.`sbtest1`
### WHERE
### @1=2
### @2=1008980
### @3='123'
### @4='05603373460-16140454933-50476449060-04937808333-32421752305'#180427 8:09:21 server id 1 end_log_pos 29600687 CRC32 0x8cfdd6ae Xid = 307686
COMMIT/*!*/;
# at 29600687
#180427 8:09:21 server id 1 end_log_pos 29600752 CRC32 0xb5aa18ba GTID last_committed=42844 sequence_number=42845 rbr_only=yes
/*!50718 SET TRANSACTION ISOLATION LEVEL READ COMMITTED*//*!*/;
SET @@SESSION.GTID_NEXT= '0c695e13-4931-11e8-9f2f-080027e8bf1b:55893'/*!*/;
# at 29600752
#180427 8:09:21 server id 1 end_log_pos 29600826 CRC32 0xc7b71da5 Query thread_id=44 exec_time=0 error_code=0
SET TIMESTAMP=1524816561/*!*/;
/*!\C utf8 *//*!*/;
SET @@session.character_set_client=33,@@session.collation_connection=33,@@session.collation_server=8/*!*/;
BEGIN
/*!*/;
# at 29600826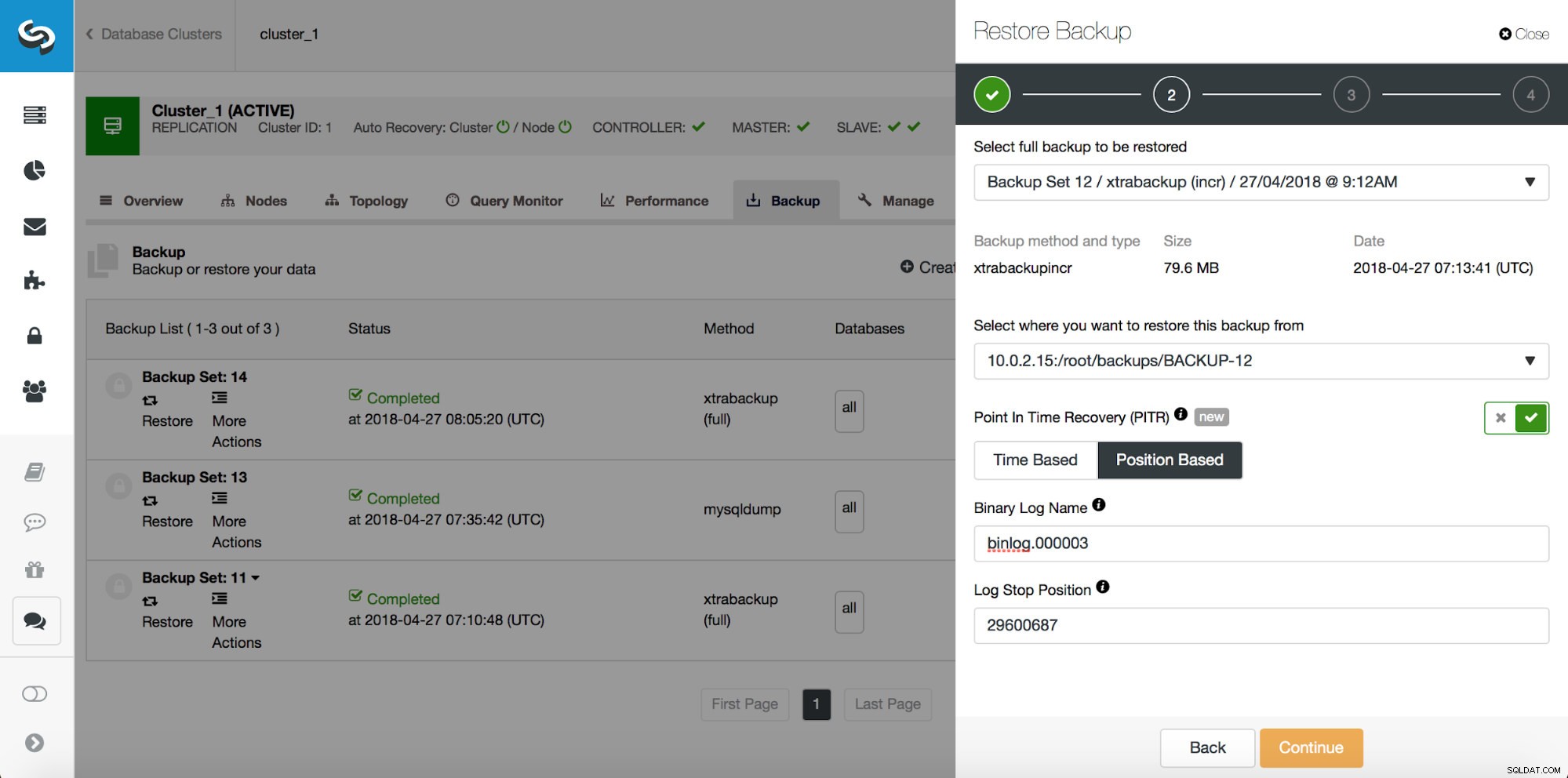
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.03 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE 'missing.sql';
ERROR 1290 (HY000): The MySQL server is running with the --secure-file-priv option so it cannot execute this statementmysql> SHOW VARIABLES LIKE "secure_file_priv";
+------------------+-----------------------+
| Variable_name | Value |
+------------------+-----------------------+
| secure_file_priv | /var/lib/mysql-files/ |
+------------------+-----------------------+
1 row in set (0.13 sec)mysql> SELECT * FROM sbtest.sbtest1 WHERE id < 23146 INTO OUTFILE '/var/lib/mysql-files/missing.sql';
Query OK, 23145 rows affected (0.05 sec)example@sqldat.com:~# scp /var/lib/mysql-files/missing.sql 10.0.0.101:/var/lib/mysql-files/
missing.sql 100% 1744KB 1.7MB/s 00:00mysql> LOAD DATA INFILE '/var/lib/mysql-files/missing.sql' INTO TABLE sbtest.sbtest1;
Query OK, 23145 rows affected (2.22 sec)
Records: 23145 Deleted: 0 Skipped: 0 Warnings: 0
mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Pérdida parcial de datos:copia de seguridad lógica
example@sqldat.com:~# ls -alh /root/backups/BACKUP-13/
total 5.8G
drwx------ 2 root root 4.0K Apr 27 07:35 .
drwxr-x--- 5 root root 4.0K Apr 27 07:14 ..
-rw-r--r-- 1 root root 2.4K Apr 27 07:35 cmon_backup.metadata
-rw------- 1 root root 5.8G Apr 27 07:35 mysqldump_2018-04-27_071434_complete.sql.gzexample@sqldat.com:~# mkdir /root/restore
example@sqldat.com:~# zcat /root/backups/BACKUP-13/mysqldump_2018-04-27_071434_complete.sql.gz > /root/restore/backup.sqlINSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399'),(2,1008980,'69708345057-48265944193-91002879830-11554672482-35576538285-03657113365-90301319612-18462263634-56608104414-27254248188','05603373460-16140454933-50476449060-04937808333-32421752305')example@sqldat.com:~/restore# grep -n "CREATE TABLE \`sbtest1\`" backup.sql > out
example@sqldat.com:~/restore# cat out
971:CREATE TABLE `sbtest1` (example@sqldat.com:~/restore# sed -n '971,993p; 994q' backup.sql > 1.sql
example@sqldat.com:~/restore# tail -n 1 1.sql | lessINSERT INTO `sbtest1` VALUES (31351,1007187,'23938390896-69688180281-37975364313-05234865797-89299459691-74476188805-03642252162-40036598389-45190639324-97494758464','60596247401-06173974673-08009930825-94560626453-54686757363'),INSERT INTO `sbtest1` VALUES (1,1006036,'18034632456-32298647298-82351096178-60420120042-90070228681-93395382793-96740777141-18710455882-88896678134-41810932745','43683718329-48150560094-43449649167-51455516141-06448225399')(23145,1001595,'37250617862-83193638873-99290491872-89366212365-12327992016-32030298805-08821519929-92162259650-88126148247-75122945670','60801103752-29862888956-47063830789-71811451101-27773551230');example@sqldat.com:~/restore# cat 1.sql | mysql -usbtest -psbtest -h10.0.0.101 sbtest
mysql: [Warning] Using a password on the command line interface can be insecure.mysql> SELECT COUNT(*) FROM sbtest.sbtest1 WHERE id < 23146;
+----------+
| COUNT(*) |
+----------+
| 23145 |
+----------+
1 row in set (0.00 sec)Pérdida parcial de datos, esclavo retrasado
Conclusión