Hace unas semanas, el equipo de SQLskills estuvo en Tampa para nuestro evento de inmersión de ajuste de rendimiento (IE2) y yo estaba cubriendo las líneas de base. Las líneas de base son un tema cercano y querido para mí, porque son muy valiosas por muchas razones. Dos de esos motivos, que siempre menciono, ya sea para enseñar o para trabajar con clientes, son el uso de líneas de base para solucionar problemas de rendimiento y, luego, también el uso de tendencias y la provisión de estimaciones de planificación de la capacidad. Pero también son esenciales cuando realiza pruebas o ajustes de rendimiento, tanto si piensa en sus métricas de rendimiento existentes como líneas de base como si no.
Durante el módulo, revisé diferentes fuentes de datos como Performance Monitor, los DMV y datos de seguimiento o XE, y surgió una pregunta relacionada con las cargas de datos. Específicamente, la pregunta era si es mejor cargar datos en una tabla sin índices y luego crearlos cuando termine, en lugar de tener los índices en su lugar durante la carga de datos. Mi respuesta fue:"Normalmente, sí". Mi experiencia personal ha sido que este es siempre el caso, pero nunca se sabe con qué advertencia o escenario único se puede encontrar alguien en el que el cambio de rendimiento no es el esperado, y como con todas las preguntas de rendimiento, no lo sabe con certeza hasta que lo prueba. Hasta que establezca una línea de base para un método y luego vea si el otro método mejora esa línea de base, solo está adivinando. Pensé que sería divertido probar este escenario, no solo para probar lo que espero que sea cierto, sino también para mostrar qué métricas examinaría, por qué y cómo capturarlas. Si ya ha realizado pruebas de rendimiento anteriormente, esto probablemente sea anticuado. Pero para esos Si eres nuevo en la práctica, explicaré paso a paso el proceso que sigo para ayudarte a comenzar. Date cuenta de que hay muchas maneras de derivar la respuesta a "¿Qué método es mejor?" Espero que tome este proceso, lo modifique y lo haga suyo con el tiempo.
¿Qué intenta probar?
El primer paso es decidir exactamente lo que está probando. En nuestro caso, es sencillo:¿es más rápido cargar datos en una tabla vacía y luego agregar los índices, o es más rápido tener los índices en la tabla durante la carga de datos? Pero, podemos agregar alguna variación aquí si queremos. Considere el tiempo que lleva cargar datos en un montón y luego crear los índices agrupados y no agrupados, en comparación con el tiempo que lleva cargar datos en un índice agrupado y luego crear los índices no agrupados. ¿Hay alguna diferencia en el rendimiento? ¿La clave de agrupamiento sería un factor? Espero que la carga de datos provoque la fragmentación de los índices no agrupados existentes, por lo que tal vez quiera ver qué impacto tiene la reconstrucción de los índices después de la carga en la duración total. Es importante abarcar este paso tanto como sea posible y ser muy específico sobre lo que desea medir, ya que esto determinará qué datos capturará. Para nuestro ejemplo, nuestras cuatro pruebas serán:
Prueba 1: Cargue datos en un montón, cree el índice agrupado, cree los índices no agrupados
Prueba 2: Cargue datos en un índice agrupado, cree los índices no agrupados
Prueba 3: Cree el índice agrupado y los índices no agrupados, cargue los datos
Prueba 4: Cree el índice agrupado y los índices no agrupados, cargue los datos, reconstruya los índices no agrupados
¿Qué necesita saber?
En nuestro escenario, nuestra pregunta principal es "¿qué método es el más rápido"? Por lo tanto, queremos medir la duración y para hacerlo necesitamos capturar una hora de inicio y una hora de finalización. Podríamos dejarlo así, pero es posible que queramos comprender cómo se ve la utilización de recursos para cada método, o tal vez queramos saber las esperas más altas, la cantidad de transacciones o la cantidad de interbloqueos. Los datos más interesantes y relevantes dependerán de los procesos que esté comparando. Capturar el número de transacciones no es tan interesante para nuestra carga de datos; pero para un cambio de código podría ser. Debido a que estamos creando índices y reconstruyéndolos, estoy interesado en la cantidad de IO que genera cada método. Si bien la duración general es probablemente el factor decisivo al final, mirar IO puede ser útil no solo para comprender qué opción genera la mayor cantidad de IO, sino también si el almacenamiento de la base de datos está funcionando como se esperaba.
¿Dónde están los datos que necesita?
Una vez que haya determinado qué datos necesita, decida desde dónde se capturarán. Estamos interesados en la duración, por lo que queremos registrar la hora en que comienza cada prueba de carga de datos y cuándo finaliza. También estamos interesados en IO, y podemos extraer estos datos de varias ubicaciones:los contadores del Monitor de rendimiento y el DMV sys.dm_io_virtual_file_stats vienen a la mente.
Comprenda que podríamos obtener estos datos manualmente. Antes de ejecutar una prueba, podemos seleccionar contra sys.dm_io_virtual_file_stats y guardar los valores actuales en un archivo. Podemos anotar el tiempo y luego comenzar la prueba. Cuando termina, anotamos la hora nuevamente, consultamos sys.dm_io_virtual_file_stats nuevamente y calculamos las diferencias entre los valores para medir IO.
Existen numerosas fallas en esta metodología, a saber, que deja un margen significativo para el error; ¿Qué sucede si olvida anotar la hora de inicio u olvida capturar las estadísticas del archivo antes de comenzar? Una solución mucho mejor es automatizar no solo la ejecución del script, sino también la captura de datos. Por ejemplo, podemos crear una tabla que contenga la información de nuestra prueba:una descripción de qué es la prueba, a qué hora comenzó y a qué hora se completó. Podemos incluir las estadísticas del archivo en la misma tabla. Si estamos recopilando otras métricas, podemos agregarlas a la tabla. O bien, puede ser más fácil crear una tabla separada para cada conjunto de datos que capturamos. Por ejemplo, si almacenamos datos de estadísticas de archivos en una tabla diferente, debemos otorgar a cada prueba una identificación única, para que podamos hacer coincidir nuestra prueba con los datos de estadísticas de archivos correctos. Al capturar estadísticas de archivos, tenemos que capturar los valores de nuestra base de datos antes de comenzar, y luego después, y calcular la diferencia. Luego podemos almacenar esa información en su propia tabla, junto con la ID de prueba única.
Un ejercicio de muestra
Para esta prueba, creé una copia vacía de la tabla Sales.SalesOrderHeader llamada Sales.Big_SalesOrderHeader, y usé una variación de un script que usé en mi publicación de partición para cargar datos en la tabla en lotes de aproximadamente 25 000 filas. Puede descargar el script para la carga de datos aquí. Lo ejecuté cuatro veces para cada variación y también varié el número total de filas insertadas. Para el primer conjunto de pruebas inserté 20 millones de filas y para el segundo conjunto inserté 60 millones de filas. Los datos de duración no sorprenden:
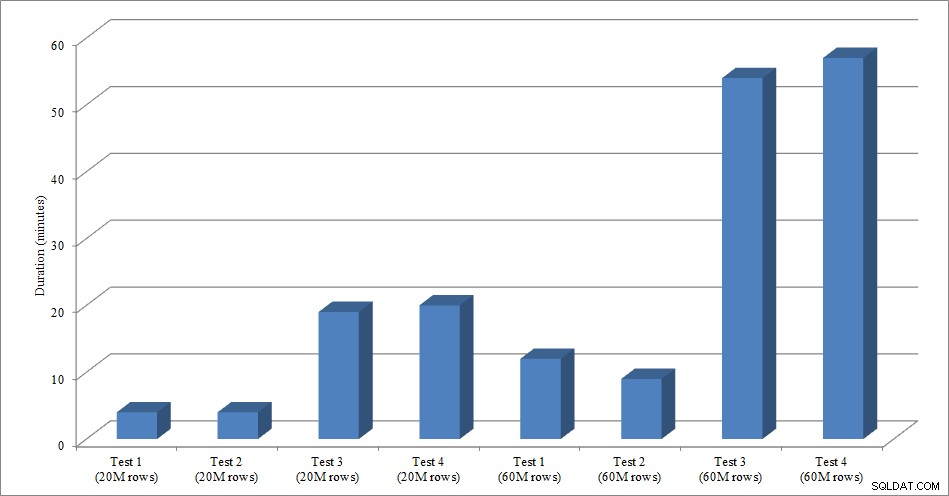
Duración de carga de datos
Cargar datos, sin los índices no agrupados, es mucho más rápido que cargarlos con los índices no agrupados ya implementados. Lo que encontré interesante es que para la carga de 20 millones de filas, la duración total fue casi la misma entre la Prueba 1 y la Prueba 2, pero la Prueba 2 fue más rápida cuando se cargaron 60 millones de filas. En nuestra prueba, nuestra clave de agrupación fue SalesOrderID, que es una identidad y, por lo tanto, una buena clave de agrupación para nuestra carga, ya que es ascendente. Si tuviéramos una clave de agrupación que fuera un GUID, el tiempo de carga podría ser mayor debido a las inserciones aleatorias y las divisiones de página (otra variación que podríamos probar).
¿Los datos de IO imitan la tendencia en los datos de duración? Sí, con las diferencias teniendo los índices ya puestos, o no, aún más exagerados:
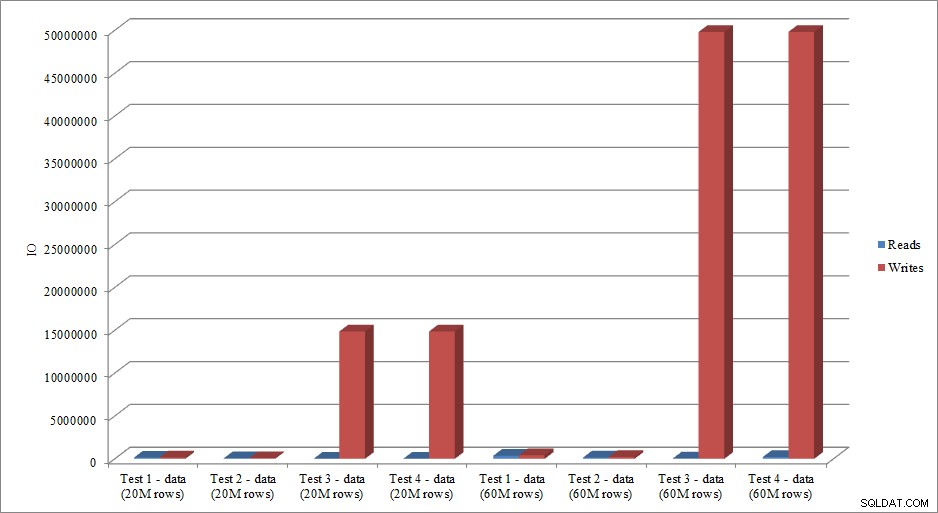
Lecturas y escrituras de carga de datos
El método que he presentado aquí para las pruebas de rendimiento, o para medir los cambios en el rendimiento en función de las modificaciones del código, el diseño, etc., es solo una opción para capturar información de referencia. En algunos escenarios, esto puede ser excesivo. Si tiene una consulta que está tratando de ajustar, configurar este proceso para capturar datos puede llevar más tiempo que hacer ajustes a la consulta. Si ha realizado algún ajuste de consulta, probablemente tenga la costumbre de capturar datos de STATISTICS IO y STATISTICS TIME, junto con el plan de consulta, y luego comparar el resultado a medida que realiza los cambios. He estado haciendo esto durante años, pero recientemente descubrí una mejor manera... SQL Sentry Plan Explorer PRO. De hecho, después de completar todas las pruebas de carga que describí anteriormente, realicé y volví a ejecutar mis pruebas a través de PE y descubrí que podía capturar la información que quería, sin tener que configurar mis tablas de recopilación de datos.
Dentro de Plan Explorer PRO, tiene la opción de obtener el plan real:PE ejecutará la consulta en la instancia y la base de datos seleccionadas, y devolverá el plan. Y con él, obtiene todos los demás datos excelentes que proporciona PE (estadísticas de tiempo, lecturas y escrituras, IO por tabla), así como las estadísticas de espera, lo cual es un buen beneficio. Usando nuestro ejemplo, comencé con la primera prueba:crear el montón, cargar datos y luego agregar el índice agrupado y los índices no agrupados, y luego ejecuté la opción Obtener plan real. Cuando se completó, modifiqué mi prueba de script 2, ejecuté la opción Obtener plan real nuevamente. Repetí esto para la tercera y cuarta prueba, y cuando terminé, tenía esto:
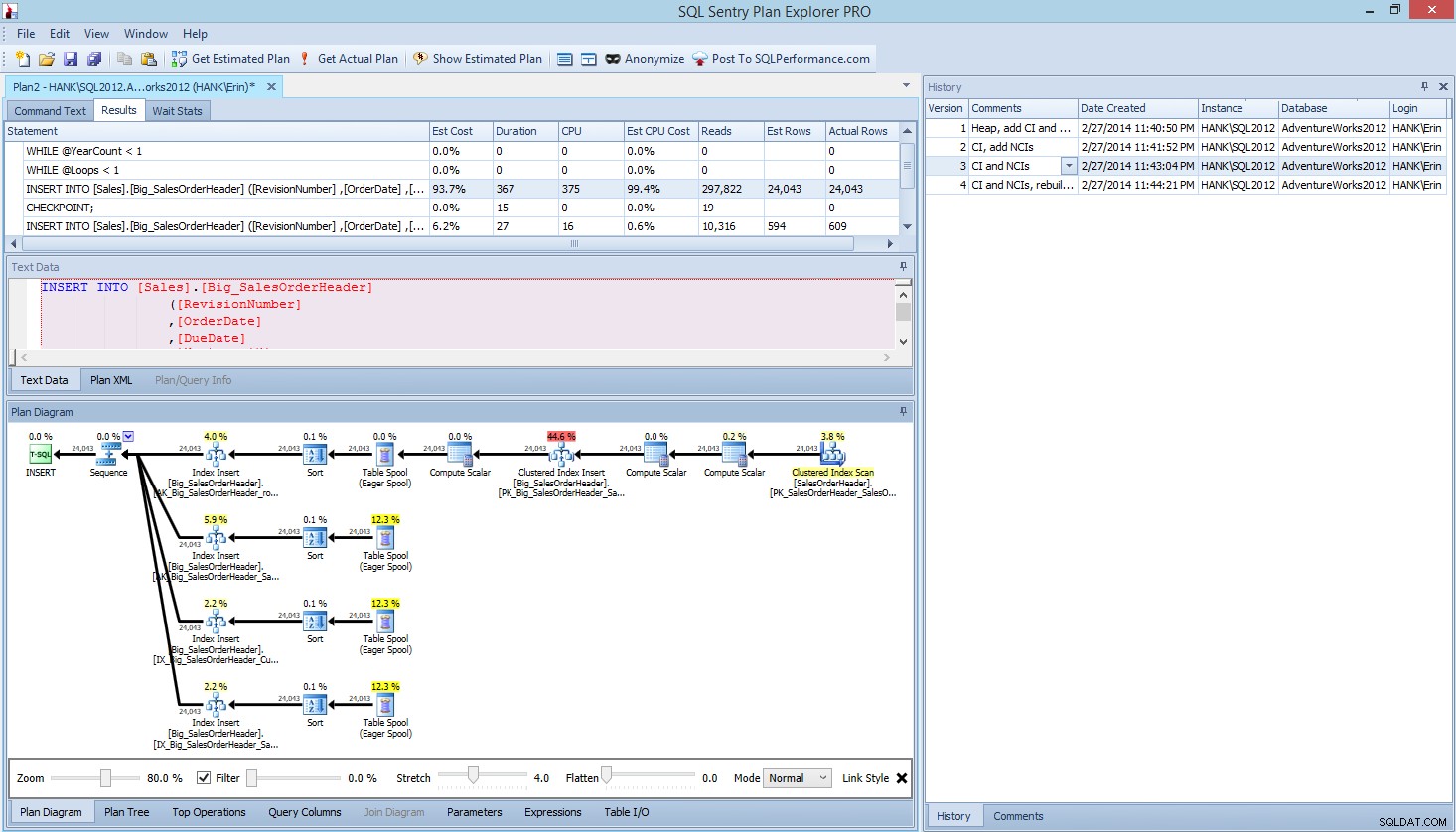
Vista de Plan Explorer PRO después de ejecutar 4 pruebas
¿Ves el panel de historial en el lado derecho? Cada vez que modificaba mi código y recuperaba el plan real, guardaba un nuevo conjunto de información. Tengo la capacidad de guardar estos datos como un archivo .pesession para compartir con otro miembro de mi equipo, o volver más tarde y desplazarme por las diferentes pruebas, y profundizar en diferentes declaraciones dentro del lote según sea necesario, observando diferentes métricas como como duración, CPU y IO. En la captura de pantalla anterior, resalté INSERTAR de la prueba 3 y el plan de consulta muestra las actualizaciones de los cuatro índices no agrupados.
Resumen
Al igual que con tantas tareas en SQL Server, hay muchas formas de capturar y revisar datos cuando ejecuta pruebas de rendimiento o realiza ajustes. Cuanto menos esfuerzo manual tenga que realizar, mejor, ya que deja más tiempo para realizar cambios, comprender el impacto y luego pasar a la siguiente tarea. Ya sea que personalice un script para capturar datos o deje que una utilidad de terceros lo haga por usted, los pasos que describí siguen siendo válidos:
- Define lo que quieres mejorar
- Alcance de sus pruebas
- Determinar qué datos se pueden usar para medir la mejora
- Decida cómo capturar los datos
- Configure un método automatizado, siempre que sea posible, para probar y capturar
- Pruebe, evalúe y repita según sea necesario
¡Feliz prueba!