Los índices hash son una parte integral de las bases de datos. Si alguna vez ha utilizado una base de datos, es probable que las haya visto en acción sin siquiera darse cuenta.
Los índices hash difieren en el trabajo de otros tipos de índices porque almacenan valores en lugar de punteros a registros ubicados en un disco. Esto asegura una búsqueda e inserción más rápida en el índice. Es por eso que los índices hash a menudo se usan como claves principales o identificadores únicos.
Comprensión de los índices hash
Un índice hash es un tipo de índice que se usa más comúnmente en la gestión de datos. Por lo general, se crea en una columna que contiene valores únicos, como una clave principal o una dirección de correo electrónico. El principal beneficio de usar índices hash es su rápido rendimiento.
El concepto detrás de estos índices puede ser complicado de entender para alguien que nunca antes ha oído hablar de ellos. Sin embargo, comprender los índices hash es importante si necesita comprender cómo funcionan las bases de datos. Es necesario para resolver problemas comunes relacionados con las bases de datos y su velocidad.
La buena noticia es que con un poco de paciencia y un teléfono móvil apagado, ¡seguro que puedes dominar los índices hash! Entonces, echemos un vistazo mejor.
Rápido y Fácil
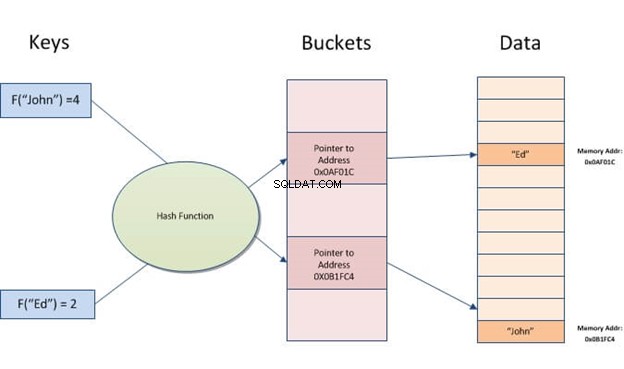
Un índice hash es una estructura de datos que se puede utilizar para acelerar las consultas de la base de datos. Funciona convirtiendo registros de entrada en una matriz de cubos. Cada cubo tiene el mismo número de registros que todos los demás cubos de la tabla. Por lo tanto, no importa cuántos valores diferentes tenga para una columna en particular, cada fila siempre se asignará a un depósito.
Los índices hash permiten búsquedas rápidas de datos almacenados en tablas. Funcionan creando una clave de índice a partir del valor y luego localizándola en función del hash resultante. Es útil cuando hay muchas entradas con valores similares o duplicados, ya que solo necesita comparar claves en lugar de buscar en todos los registros.
¿No fue esto rápido ni fácil? Para comprender cómo funcionan los índices hash y por qué son tan poderosos, debe comprender qué se entiende por hash.
Hashing toma una pieza de información (una cadena) y la convierte en una dirección o puntero para un acceso rápido más adelante.
La idea con el hashing es que a los datos se les asigna un número pequeño. Cuando está buscando los datos, no tiene que tamizar a través de las masas. En su lugar, solo busca ese número. El ejemplo más simple es Ctrl+F-ing la palabra que está buscando en un texto en lugar de leer docenas de páginas usted mismo.
¿Para qué sirven los índices hash?
Un índice hash es una forma de acelerar el proceso de búsqueda. Con los índices tradicionales, debe escanear cada fila para asegurarse de que su consulta sea exitosa. ¡Pero con los índices hash, este no es el caso!
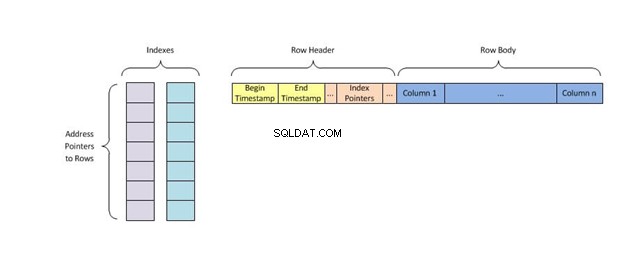
Cada clave del índice contiene solo una fila de los datos de la tabla y utiliza el algoritmo de indexación llamado hashing que les asigna una ubicación única en la memoria, eliminando todas las demás claves con valores duplicados antes de encontrar lo que está buscando.
Los índices hash son una de las muchas formas de organizar los datos en una base de datos. Funcionan tomando entradas y usándolas como una clave para el almacenamiento en un disco. Estas claves o valores hash , puede ser cualquier cosa, desde longitudes de cadena hasta caracteres en la entrada.
Los índices hash se usan más comúnmente cuando se consultan entradas específicas con atributos específicos. Por ejemplo, puede encontrar todas las letras A que miden más de 10 cm. Puede hacerlo rápidamente creando una función de índice hash.
Los índices hash son parte del sistema de base de datos PostgreSQL. Este sistema fue desarrollado para aumentar la velocidad y el rendimiento. Los índices hash se pueden usar junto con otros tipos de índices, como B-tree o GiST.
Un índice hash almacena claves dividiéndolas en fragmentos más pequeños llamados cubos, donde a cada cubo se le asigna un número de identificación entero para recuperarlo rápidamente al buscar la ubicación de una clave en la tabla hash. Los cubos se almacenan secuencialmente en un disco para que se pueda acceder rápidamente a los datos que contienen.
Se pueden encontrar más explicaciones técnicas en esta página (haga clic con el botón derecho del mouse y elija "Traducir al inglés").
Ventajas
La principal ventaja de usar índices hash es que permiten un acceso rápido al recuperar el registro por el valor de la clave. Suele ser útil para consultas con una condición de igualdad. Además, el uso de puntos de referencia hash no requerirá mucho espacio de almacenamiento. Por lo tanto, es una herramienta eficaz, pero no exenta de inconvenientes.
Desventajas
Los índices hash son una estructura de indexación relativamente nueva con el potencial de proporcionar importantes beneficios de rendimiento. Puede pensar en ellos como una extensión de los árboles de búsqueda binarios (BST).
Los índices hash funcionan almacenando datos en depósitos en función de sus valores hash, lo que permite una recuperación rápida y eficiente de los datos. Están garantizados para estar en orden.
Sin embargo, es imposible almacenar claves duplicadas dentro de un depósito. Por lo tanto, siempre habrá algunos gastos generales. Pero hasta ahora, las ventajas de usar índices hash superan las desventajas.
¿Cómo funciona todo con un poco más de profundidad?
Hagamos una demostración aviasales base de datos para obtener una comprensión más profunda de cómo funcionan los índices hash.
demo=# create index on flights using hash(flight_no);
WARNING: hash indexes are not WAL-logged and their use is discouraged
CREATE INDEX
demo=# explain (costs off) select * from flights where flight_no = 'PG0001';
QUERY PLAN
----------------------------------------------------
Bitmap Heap Scan on flights
Recheck Cond: (flight_no = 'PG0001'::bpchar)
-> Bitmap Index Scan on flights_flight_no_idx
Index Cond: (flight_no = 'PG0001'::bpchar)
(4 rows)
Aquí puede ver cómo estamos implementando índices hash compilando datos en conjuntos.
Este es un ejemplo fácil, pero tenga en cuenta que las limitaciones vienen con menos infraestructura de código. Puede haber una falta de acceso al registro WAL o una incapacidad para recuperar índices (¿índices?) Después de un bloqueo. Además, es posible que los índices no participen en la replicación; se debe a que PostgreSQL está desactualizado. Sin embargo, al igual que con Python, recibe advertencias que a menudo le permiten evitar errores.
Puede echar un vistazo más profundo dentro de estos índices si está lo suficientemente intrigado. Para eso, estamos creando una inspección de página instancia de extensión.
demo=# create extension pageinspect;
CREATE EXTENSION
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',0));
hash_page_type
----------------
metapage
(1 row)
demo=# select ntuples, maxbucket from hash_metapage_info(get_raw_page('flights_flight_no_idx',0));
ntuples | maxbucket
---------+-----------
33121 | 127
(1 row)
demo=# select hash_page_type(get_raw_page('flights_flight_no_idx',1));
hash_page_type
----------------
bucket
(1 row)
demo=# select live_items, dead_items from hash_page_stats(get_raw_page('flights_flight_no_idx',1));
live_items | dead_items
------------+------------
407 | 0
(1 row)
Si desea inspeccionar completamente el código, comience con LÉAME.
Resumen
Los índices hash son una estructura de datos que acelera el proceso de búsqueda de información en grandes bases de datos. Funcionan dividiendo los datos en fragmentos más pequeños y luego clasificándolos. Así, cuando buscas algo, puedes encontrarlo mucho más rápido.
Si desea buscar más cosas, hay recursos para DYOR. Además, esté atento a nuestros nuevos artículos, que están saliendo más rápido de lo que puede presionar Ctrl+F la palabra "hash" en esta página. ¡Espero que esto ayude!