SQL Server nos proporciona una serie de funciones de ventana que nos ayudan a realizar cálculos en un conjunto de filas, sin necesidad de repetir las llamadas a la base de datos. A diferencia de las funciones de agregado estándar, las funciones de ventana no agruparán las filas en una sola fila de salida, devolverán un solo valor agregado para cada fila, manteniendo las identidades separadas para esas filas. El término Ventana aquí no está relacionado con el sistema operativo Microsoft Windows, describe el conjunto de filas que procesará la función.
Uno de los tipos de funciones de ventana más útiles son las funciones de ventana de clasificación que se utilizan para clasificar valores de campo específicos y categorizarlos según la clasificación de cada fila, lo que da como resultado un único valor agregado para cada fila participada. Hay cuatro funciones de ventana de clasificación admitidas en SQL Server; ROW_NUMBER(), RANK(), DENSE_RANK() y NTILE(). Todas estas funciones se utilizan para calcular ROWID para la ventana de filas proporcionada a su manera.
Cuatro funciones de ventana de clasificación utilizan la cláusula OVER() que define un conjunto de filas especificado por el usuario dentro de un conjunto de resultados de consulta. Al definir la cláusula OVER(), también puede incluir la cláusula PARTITION BY que determina el conjunto de filas que procesará la función de ventana, proporcionando columnas o columnas separadas por comas para definir la partición. Además, se puede incluir la cláusula ORDER BY, que define los criterios de clasificación dentro de las particiones por las que la función pasará por las filas mientras procesa.
En este artículo, discutiremos cómo usar cuatro funciones de ventana de clasificación:ROW_NUMBER(), RANK(), DENSE_RANK() y NTILE() prácticamente, y la diferencia entre ellas.
Para servir nuestra demostración, crearemos una nueva tabla simple e insertaremos algunos registros en la tabla usando el script T-SQL a continuación:
CREATE TABLE StudentScore
(
Student_ID INT PRIMARY KEY,
Student_Name NVARCHAR (50),
Student_Score INT
)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978)
INSERT INTO StudentScore VALUES (2,'Zaid', 770)
INSERT INTO StudentScore VALUES (3,'Mohd', 1140)
INSERT INTO StudentScore VALUES (4,'Jack', 770)
INSERT INTO StudentScore VALUES (5,'John', 1240)
INSERT INTO StudentScore VALUES (6,'Mike', 1140)
INSERT INTO StudentScore VALUES (7,'Goerge', 885)
Puede comprobar que los datos se han insertado correctamente mediante la siguiente sentencia SELECT:
SELECT * FROM StudentScore ORDER BY Student_ScoreCon el resultado ordenado aplicado, el conjunto de resultados es el siguiente:

ROW_NUMBER()
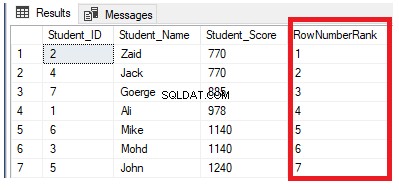
La función de ventana de clasificación ROW_NUMBER() devuelve un número secuencial único para cada fila dentro de la partición de la ventana especificada, comenzando en 1 para la primera fila de cada partición y sin repetir ni omitir números en el resultado de la clasificación de cada partición. Si hay valores duplicados dentro del conjunto de filas, los números de ID de clasificación se asignarán arbitrariamente. Si se especifica la cláusula PARTITION BY, el número de fila de clasificación se restablecerá para cada partición. En la tabla creada anteriormente, la siguiente consulta muestra cómo usar la función de ventana de clasificación ROW_NUMBER para clasificar las filas de la tabla StudentScore según la puntuación de cada alumno:
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Está claro del conjunto de resultados a continuación que la función de ventana ROW_NUMBER clasifica las filas de la tabla de acuerdo con los valores de la columna Student_Score para cada fila, al generar un número único de cada fila que refleja su ranking Student_Score comenzando desde el número 1 sin duplicados ni espacios y tratar todas las filas como una partición. También puede ver que las puntuaciones duplicadas se asignan a diferentes rangos al azar:
Si modificamos la consulta anterior al incluir la cláusula PARTITION BY para tener más de una partición, como se muestra en la consulta T-SQL a continuación:
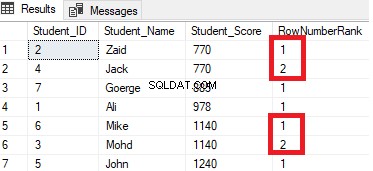
SELECT *, ROW_NUMBER() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
El resultado mostrará que la función de ventana ROW_NUMBER clasificará las filas de la tabla de acuerdo con los valores de la columna Student_Score para cada fila, pero se ocupará de las filas que tienen el mismo valor Student_Score como una partición. Verá que se generará un número único para cada fila que refleja su clasificación de Student_Score, comenzando desde el número 1 sin duplicados ni espacios dentro de la misma partición, restableciendo el número de clasificación cuando se mueve a un valor diferente de Student_Score.
Por ejemplo, los estudiantes con una puntuación de 770 se clasificarán dentro de esa puntuación asignándoles un número de clasificación. Sin embargo, cuando se mueve al estudiante con una puntuación de 885, el número inicial de la clasificación se restablecerá para comenzar de nuevo en 1, como se muestra a continuación:
RANGO()
La función de ventana de clasificación RANK() devuelve un número de clasificación único para cada fila distinta dentro de la partición de acuerdo con un valor de columna específico, comenzando en 1 para la primera fila en cada partición, con la misma clasificación para valores duplicados y dejando espacios entre las clasificaciones.; este espacio aparece en la secuencia después de los valores duplicados. En otras palabras, la función de ventana de clasificación RANK() se comporta como la función ROW_NUMBER() excepto para las filas con valores iguales, donde se clasificará con el mismo ID de clasificación y generará una brecha después. Si modificamos la consulta de clasificación anterior para usar la función de clasificación RANK():
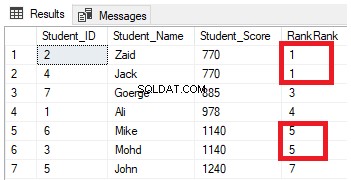
SELECT *, RANK () OVER( ORDER BY Student_Score) AS RankRank
FROM StudentScoreVerá en el resultado que la función de ventana CLASIFICACIÓN clasificará las filas de la tabla de acuerdo con los valores de la columna Student_Score para cada fila, con un valor de clasificación que refleja su Student_Score comenzando desde el número 1, y clasificando las filas que tienen el mismo Student_Score con el mismo valor de rango. También puede ver que dos filas que tienen Student_Score igual a 770 se clasifican con el mismo valor, dejando un espacio, que es el número 2 perdido, después de la segunda fila clasificada. Lo mismo sucede con las filas donde Student_Score es igual a 1140 que se clasifican con el mismo valor, dejando un espacio, que es el número 6 que falta, después de la segunda fila, como se muestra a continuación:
Modificando la consulta anterior al incluir la cláusula PARTITION BY para tener más de una partición, como se muestra en la consulta T-SQL a continuación:
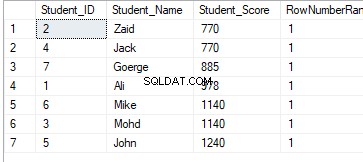
SELECT *, RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreEl resultado de la clasificación no tendrá ningún significado, ya que la clasificación se realizará de acuerdo con los valores de Student_Score para cada partición, y los datos se dividirán de acuerdo con los valores de Student_Score. Y debido al hecho de que cada partición tendrá filas con los mismos valores de Student_Score, las filas con los mismos valores de Student_Score en la misma partición se clasificarán con un valor igual a 1. Por lo tanto, al pasar a la segunda partición, la clasificación será ser reiniciado, comenzando de nuevo con el número 1, teniendo todos los valores de clasificación igual a 1 como se muestra a continuación:
RANGO_DENSO()
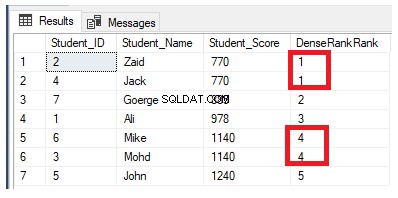
La función de ventana de clasificación DENSE_RANK() es similar a la función RANK() al generar un número de clasificación único para cada fila distinta dentro de la partición de acuerdo con un valor de columna específico, comenzando en 1 para la primera fila en cada partición, clasificando las filas con valores iguales con el mismo número de rango, excepto que no se salta ningún rango y no deja espacios entre los rangos.
Si reescribimos la consulta de clasificación anterior para usar la función de clasificación DENSE_RANK():
De nuevo, modifique la consulta anterior incluyendo la cláusula PARTITION BY para tener más de una partición, como se muestra en la consulta T-SQL a continuación:
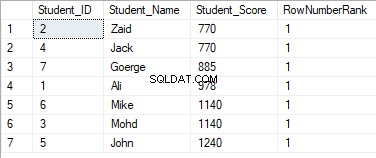
SELECT *, DENSE_RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Los valores de clasificación no tendrán ningún significado, donde todas las filas se clasificarán con el valor 1, debido a la asignación de los valores duplicados al mismo valor de clasificación y el restablecimiento de la identificación de inicio de clasificación al procesar una nueva partición, como se muestra a continuación:
NTILE(N)
La función de ventana de clasificación NTILE(N) se usa para distribuir las filas del conjunto de filas en un número específico de grupos, proporcionando a cada fila del conjunto de filas un número de grupo único, comenzando con el número 1 que muestra el grupo al que pertenece esta fila. a, donde N es un número positivo, que define el número de grupos en los que necesita distribuir las filas establecidas.
En otras palabras, si necesita dividir filas de datos específicos de la tabla en 3 grupos, en función de valores de columnas particulares, la función de ventana de clasificación NTILE(3) lo ayudará a lograrlo fácilmente.
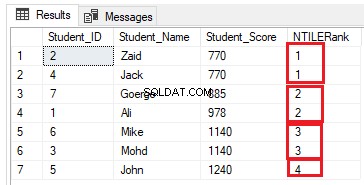
El número de filas en cada grupo se puede calcular dividiendo el número de filas entre el número requerido de grupos. Si modificamos la consulta de clasificación anterior para usar la función de ventana de clasificación NTILE(4) para clasificar siete filas de la tabla en cuatro grupos como la consulta T-SQL a continuación:
SELECT *, NTILE(4) OVER( ORDER BY Student_Score) AS NTILERank
FROM StudentScore
El número de filas debe ser (7/4 =1,75) filas en cada grupo. Usando la función NTILE(), SQL Server Engine asignará 2 filas a los primeros tres grupos y una fila al último grupo, para tener todas las filas incluidas en los grupos, como se muestra en el conjunto de resultados a continuación:
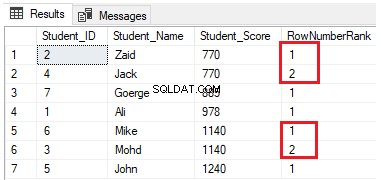
Modificando la consulta anterior al incluir la cláusula PARTITION BY para tener más de una partición, como se muestra en la consulta T-SQL a continuación:
SELECT *, NTILE(4) OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreLas filas se distribuirán en cuatro grupos en cada partición. Por ejemplo, las dos primeras filas con Student_Score igual a 770 estarán en la misma partición y se distribuirán dentro de los grupos clasificando cada uno con un número único, como se muestra en el conjunto de resultados a continuación:
Poniendo todo junto
Para tener un escenario de comparación más claro, trunquemos la tabla anterior, agreguemos otro criterio de clasificación, que es la clase de los estudiantes, y finalmente insertemos nuevas siete filas usando el script T-SQL a continuación:
TRUNCATE TABLE StudentScore
GO
ALTER TABLE StudentScore ADD CLASS CHAR(1)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978,'A')
INSERT INTO StudentScore VALUES (2,'Zaid', 770,'B')
INSERT INTO StudentScore VALUES (3,'Mohd', 1140,'A')
INSERT INTO StudentScore VALUES (4,'Jack', 879,'B')
INSERT INTO StudentScore VALUES (5,'John', 1240,'C')
INSERT INTO StudentScore VALUES (6,'Mike', 1100,'B')
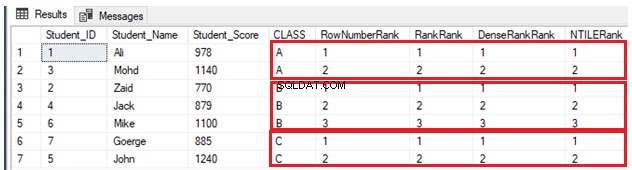
INSERT INTO StudentScore VALUES (7,'Goerge', 885,'C')Después de eso, clasificaremos siete filas de acuerdo con la puntuación de cada estudiante, dividiendo a los estudiantes según su clase. En otras palabras, cada partición incluirá una clase, y cada clase de estudiantes se clasificará de acuerdo con sus puntajes dentro de la misma clase, utilizando cuatro funciones de ventana de clasificación descritas anteriormente, como se muestra en el script T-SQL a continuación:
SELECT *, ROW_NUMBER() OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RowNumberRank,
RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RankRank,
DENSE_RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS DenseRankRank,
NTILE(7) OVER(PARTITION BY CLASS ORDER BY Student_Score) AS NTILERank
FROM StudentScore
GODebido al hecho de que no hay valores duplicados, cuatro funciones de la ventana de clasificación funcionarán de la misma manera y devolverán el mismo resultado, como se muestra en el conjunto de resultados a continuación:
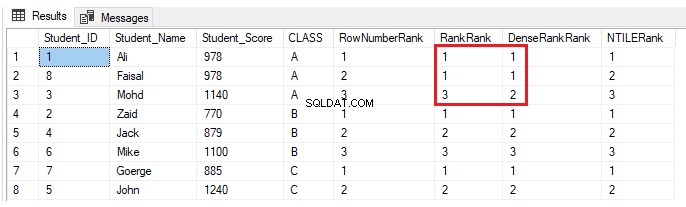
Si se incluye a otro alumno en la clase A con una puntuación que ya tiene otro alumno de la misma clase, utilice la declaración INSERT a continuación:
INSERT INTO StudentScore VALUES (8,'Faisal', 978,'A')Nada cambiará para las funciones de ventana de clasificación ROW_NUMBER() y NTILE(). Las funciones RANK y DENSE_RANK() asignarán el mismo rango a los estudiantes con la misma puntuación, con una brecha en los rangos después de los rangos duplicados cuando se usa la función RANK y sin brecha en los rangos después de los rangos duplicados cuando se usa DENSE_RANK( ), como se muestra en el siguiente resultado:
Escenario práctico
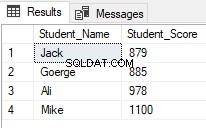
Los desarrolladores de SQL Server utilizan ampliamente las funciones de la ventana de clasificación. Uno de los escenarios comunes para el uso de funciones de clasificación, cuando desea buscar filas específicas y omitir otras, usa la función de ventana de clasificación ROW_NUMBER(,) dentro de un CTE, como en el script T-SQL a continuación que devuelve a los estudiantes con rangos entre 2 y 5 y omita los demás:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
WHERE RowNumberRank >= 2 and RowNumberRank <=5
ORDER BY RowNumberRank
El resultado mostrará que solo se devolverán los estudiantes con rangos entre 2 y 5:
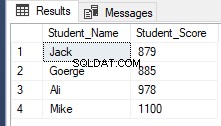
A partir de SQL Server 2012, un nuevo comando útil, OFFSET FETCH se introdujo que se puede usar para realizar la misma tarea anterior obteniendo registros específicos y omitiendo los demás, usando el script T-SQL a continuación:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
ORDER BY
RowNumberRank OFFSET 1 ROWS FETCH NEXT 4 ROWS ONLY;Recuperando el mismo resultado anterior como se muestra a continuación:
Conclusión
SQL Server nos proporciona cuatro funciones de ventana de clasificación que nos ayudan a clasificar el conjunto de filas proporcionadas de acuerdo con valores de columna específicos. Estas funciones son:ROW_NUMBER(), RANK(), DENSE_RANK() y NTILE(). Todas estas funciones de clasificación realizan la tarea de clasificación a su manera, devolviendo el mismo resultado cuando no hay valores duplicados en las filas. Si hay un valor duplicado dentro del conjunto de filas, la función RANK asignará el mismo ID de clasificación para todas las filas con el mismo valor, dejando espacios entre las clasificaciones después de los duplicados. La función DENSE_RANK también asignará el mismo ID de clasificación para todas las filas con el mismo valor, pero no dejará ningún espacio entre las clasificaciones después de los duplicados. Revisamos diferentes escenarios dentro de este artículo para cubrir todos los casos posibles que lo ayuden a comprender las funciones de la ventana de clasificación de manera práctica.
Referencias:
- ROW_NUMBER (Transact-SQL)
- RANGO (Transact-SQL)
- RANGO_DENSO (Transact-SQL)
- NTILE (Transact-SQL)
- Cláusula OFFSET FETCH (SQL Server Compact)