Esta publicación es parte de una serie de artículos sobre objetivos de fila. Puedes encontrar la primera parte aquí:
- Parte 1:Establecer e identificar objetivos de fila
Es relativamente conocido que usar TOP o un FAST n la sugerencia de consulta puede establecer un objetivo de fila en un plan de ejecución (consulte Establecimiento e identificación de objetivos de fila en planes de ejecución si necesita un repaso sobre los objetivos de fila y sus causas). Es bastante menos apreciado que las semi-uniones (y las anti-uniones) también puedan introducir un objetivo de fila, aunque esto es algo menos probable que en el caso de TOP , FAST y SET ROWCOUNT .
Este artículo lo ayudará a comprender cuándo y por qué una combinación semi invoca la lógica de objetivo de fila del optimizador.
Semiuniones
Una combinación semi devuelve una fila de una entrada de combinación (A) si hay al menos una fila coincidente en la otra entrada de unión (B).
Las diferencias esenciales entre una unión semi y una unión regular son:
- La semiunión devuelve cada fila de la entrada A o no lo hace. No se puede producir ninguna duplicación de filas.
- La unión normal duplica filas si hay varias coincidencias en el predicado de unión.
- La semiunión está definida para devolver solo columnas de la entrada A.
- La combinación normal puede devolver columnas de cualquiera de las entradas de combinación (o de ambas).
T-SQL actualmente carece de soporte para sintaxis directa como FROM A SEMI JOIN B ON A.x = B.y , por lo que necesitamos usar formas indirectas como EXISTS , SOME/ANY (incluida la abreviatura equivalente IN para comparaciones de igualdad) y establecer INTERSECT .
La descripción anterior de una semiunión sugiere naturalmente la aplicación de un objetivo de fila, ya que estamos interesados en encontrar cualquier fila coincidente en B, no todas esas filas . Sin embargo, una semiunión lógica expresada en T-SQL podría no dar lugar a un plan de ejecución que utilice un objetivo de fila por varios motivos, que desglosaremos a continuación.
Transformación y simplificación
Una semiunión lógica puede simplificarse o reemplazarse por otra cosa durante la compilación y optimización de consultas. El siguiente ejemplo de AdventureWorks muestra una semiunión que se elimina por completo debido a una relación de clave externa de confianza:
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID IN
(
SELECT P.ProductID
FROM Production.Product AS P
);
La clave externa asegura que Product siempre existirán filas para cada fila del historial. Como resultado, el plan de ejecución solo accede al TransactionHistory tabla:
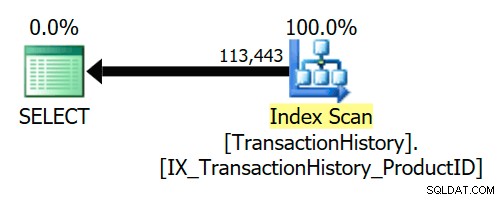
Se ve un ejemplo más común cuando la unión semi se puede transformar en una unión interna. Por ejemplo:
SELECT P.ProductID
FROM Production.Product AS P
WHERE EXISTS
(
SELECT *
FROM Production.ProductInventory AS INV
WHERE INV.ProductID = P.ProductID
);
El plan de ejecución muestra que el optimizador introdujo un agregado (agrupación en INV.ProductID ) para garantizar que la unión interna solo pueda devolver Product filas una vez, o ninguna (según sea necesario para preservar la semántica de semiunión):
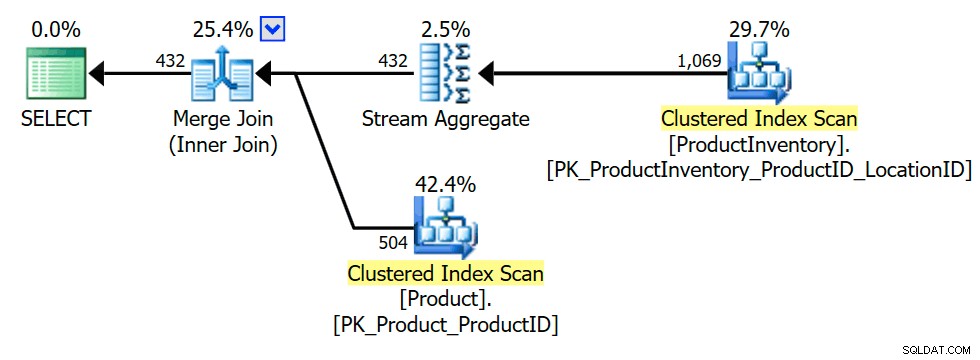
La transformación a unión interna se explora temprano porque el optimizador conoce más trucos para las uniones igualitarias internas que para las semiuniones, lo que puede conducir a más oportunidades de optimización. Naturalmente, la elección del plan final sigue siendo una decisión basada en el costo entre las alternativas exploradas.
Optimizaciones iniciales
Aunque T-SQL carece de SEMI JOIN directo sintaxis, el optimizador sabe todo acerca de las semiuniones de forma nativa y puede manipularlas directamente. Las sintaxis de semiunión de solución alternativa común se transforman en una semiunión interna "real" al principio del proceso de compilación de la consulta (mucho antes incluso de que se considere un plan trivial).
Los dos principales grupos de sintaxis de solución alternativa son EXISTS/INTERSECT y ANY/SOME/IN . El EXISTS y INTERSECT los casos difieren solo en que este último viene con un implícito DISTINCT (agrupación en todas las columnas proyectadas). Ambos EXISTS y INTERSECT se analizan como un EXISTS con subconsulta correlacionada. El ANY/SOME/IN todas las representaciones se interpretan como ALGUNA operación. Podemos explorar temprano esta actividad de optimización con algunas marcas de seguimiento no documentadas, que envían información sobre la actividad del optimizador a la pestaña de mensajes de SSMS.
Por ejemplo, la unión semi que hemos estado usando hasta ahora también se puede escribir usando IN :
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.ProductID IN /* or = ANY/SOME */
(
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621); El árbol de entrada del optimizador es el siguiente:

El operador escalar ScaOp_SomeComp es el SOME comparación mencionada anteriormente. El 2 es el código para una prueba de igualdad, ya que IN es equivalente a = SOME . Si está interesado, hay códigos del 1 al 6 que representan (<, =, <=,>, !=,>=) operadores de comparación respectivamente.
Volviendo a EXISTS sintaxis que prefiero usar más a menudo para expresar una semi unión indirectamente:
SELECT P.ProductID
FROM Production.Product AS P
WHERE EXISTS
(
SELECT *
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621); El árbol de entrada del optimizador es:

Ese árbol es una traducción bastante directa del texto de consulta; aunque tenga en cuenta que SELECT * ya ha sido reemplazada por una proyección del valor entero constante 1 (ver la penúltima línea de texto).
Lo siguiente que hace el optimizador es anular la subconsulta en la selección relacional (=filtro) usando la regla RemoveSubqInSel . El optimizador siempre hace esto, ya que no puede operar en las subconsultas directamente. El resultado es una aplicación (también conocido como unión correlacionada o lateral):

(La misma regla de eliminación de subconsultas produce el mismo resultado para SOME árbol de entrada también).
El siguiente paso es reescribir la aplicación como una unión regular usando el ApplyHandler familia de reglas. Esto es algo que el optimizador siempre intenta hacer, porque tiene más reglas de exploración para combinaciones que para aplicar. No todas las aplicaciones se pueden reescribir como una combinación, pero el ejemplo actual es sencillo y tiene éxito:

Tenga en cuenta que el tipo de unión se deja semi. De hecho, este es exactamente el mismo árbol que obtendríamos inmediatamente si T-SQL admitiera una sintaxis como:
SELECT P.ProductID
FROM Production.Product AS P
LEFT SEMI JOIN Production.TransactionHistory AS TH
ON TH.ProductID = P.ProductID; Sería bueno poder expresar consultas más directamente como esta. De todos modos, se alienta al lector interesado a explorar las actividades de simplificación anteriores con otras formas lógicamente equivalentes de escribir esta semiunión en T-SQL.
Lo importante en esta etapa es que el optimizador siempre elimina las subconsultas , reemplazándolos con una aplicación. Luego intenta reescribir la aplicación como una combinación normal para maximizar las posibilidades de encontrar un buen plan. Recuerde que todo lo anterior tiene lugar incluso antes de que se considere un plan trivial. Durante la optimización basada en costos, el optimizador también puede considerar unir la transformación de nuevo a una aplicación.
Hash y Merge Semi Join
SQL Server tiene tres opciones principales de implementaciones físicas disponibles para una semiunión lógica. Mientras esté presente un predicado equijoin, las combinaciones hash y merge están disponibles; ambos pueden operar en modos de unión semi izquierda y derecha. La unión de bucles anidados solo admite la semiunión izquierda (no la derecha), pero no requiere un predicado de unión igualitaria. Veamos las opciones físicas hash y merge para nuestra consulta de ejemplo (escrita como un conjunto de intersección esta vez):
SELECT P.ProductID FROM Production.Product AS P INTERSECT SELECT TH.ProductID FROM Production.TransactionHistory AS TH;
El optimizador puede encontrar un plan para las cuatro combinaciones de semiunión (izquierda/derecha) y (hash/fusión) para esta consulta:
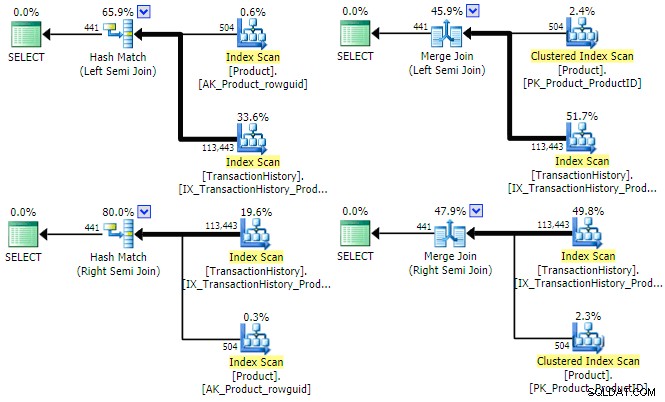
Vale la pena mencionar brevemente por qué el optimizador podría considerar semiuniones izquierda y derecha para cada tipo de combinación. Para la semiunión hash, una consideración de costo importante es el tamaño estimado de la tabla hash, que inicialmente siempre es la entrada izquierda (superior). Para la semiunión de fusión, las propiedades de cada entrada determinan si se utilizará una fusión de uno a muchos o de muchos a muchos menos eficiente con la tabla de trabajo.
Puede ser evidente a partir de los planes de ejecución anteriores que ni el hash ni la semiunión fusionada se beneficiarían al establecer un objetivo de fila . Ambos tipos de combinación siempre prueban el predicado de combinación en la propia combinación y tienen como objetivo consumir todas las filas de ambas entradas para devolver un conjunto de resultados completo. Eso no quiere decir que no existan optimizaciones de rendimiento para hash y merge join en general; por ejemplo, ambos pueden utilizar mapas de bits para reducir la cantidad de filas que llegan a la unión. Más bien, el punto es que un objetivo de fila en cualquiera de las entradas no haría que un hash o merge semi join sea más eficiente.
Bucles anidados y aplicar semiunión
El tipo de unión física restante son los bucles anidados, que vienen en dos tipos:bucles anidados regulares (no correlacionados) y aplicar bucles anidados (a veces también denominados bucles correlacionados) o lateral unirse).
La combinación de bucles anidados regulares es similar a la combinación hash y merge en que el predicado de la combinación se evalúa en la combinación. Como antes, esto significa que no tiene valor establecer un objetivo de fila en ninguna de las entradas. La entrada izquierda (superior) siempre se consumirá por completo con el tiempo, y la entrada interna no tiene forma de determinar qué fila(s) debe(n) priorizarse, ya que no podemos saber si una fila se unirá o no hasta que se pruebe el predicado en la unión. .
Por el contrario, una combinación de aplicación de bucles anidados tiene una o más referencias externas (parámetros correlacionados) en la unión, con el predicado de unión empujado hacia abajo el lado interior (inferior) de la unión. Esto crea una oportunidad para la aplicación útil de un objetivo de fila. Recuerde que una semiunión solo requiere que verifiquemos la existencia de una fila en la entrada de unión B que coincida con la fila actual en la entrada de unión A (pensando ahora solo en estrategias de unión de bucles anidados).
En otras palabras, en cada iteración de una aplicación, podemos dejar de buscar en la entrada B tan pronto como se encuentre la primera coincidencia, utilizando el predicado de combinación empujado hacia abajo. Este es exactamente el tipo de cosas para las que es bueno un objetivo de fila:generar parte de un plan optimizado para devolver rápidamente las primeras n filas coincidentes (donde n = 1 aquí).
Por supuesto, un gol en fila puede ser algo bueno o no, según las circunstancias. No hay nada especial en el objetivo de fila de semi unión en ese sentido. Considere una situación en la que el lado interior de la semiunión es más complejo que un único acceso a una tabla simple, tal vez una unión de varias tablas. Establecer un objetivo de fila puede ayudar al optimizador a seleccionar una estrategia de navegación eficiente solo para ese subárbol en particular , encontrando la primera fila coincidente para satisfacer la unión semi a través de uniones de bucles anidados y búsquedas de índice. Sin el objetivo de la fila, el optimizador podría elegir naturalmente hash o fusionar uniones con ordenaciones para minimizar el costo esperado de devolver todas las filas posibles. Tenga en cuenta que hay una suposición aquí, a saber, que las personas normalmente escriben semiuniones con la expectativa de que, de hecho, exista una fila que coincida con la condición de búsqueda. Esto me parece una suposición bastante justa.
Independientemente, el punto importante en esta etapa es:Solo solicitar la unión de bucles anidados tiene un objetivo de fila aplicado por el optimizador (recuerde, sin embargo, un objetivo de fila para aplicar la combinación de bucles anidados solo se agrega si el objetivo de fila es menor que la estimación sin él). Veremos un par de ejemplos prácticos para aclarar todo esto a continuación.
Ejemplos de semi unión de bucles anidados
El siguiente script crea dos tablas temporales de montón. El primero tiene números del 1 al 20 inclusive; el otro tiene 10 copias de cada número de la primera tabla:
DROP TABLE IF EXISTS #E1, #E2;
CREATE TABLE #E1 (c1 integer NULL);
CREATE TABLE #E2 (c1 integer NULL);
INSERT #E1 (c1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 20;
INSERT #E2 (c1)
SELECT
(SV.number % 20) + 1
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 200; Sin índices y con un número relativamente pequeño de filas, el optimizador elige una implementación de bucles anidados (en lugar de hash o combinación) para la siguiente consulta de semiunión). Las marcas de seguimiento no documentadas nos permiten ver el árbol de salida del optimizador y la información del objetivo de la fila:
SELECT E1.c1
FROM #E1 AS E1
WHERE E1.c1 IN
(SELECT E2.c1 FROM #E2 AS E2)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);
El plan de ejecución estimado presenta una unión de bucles anidados de semiunión, con 200 filas por escaneo completo de la tabla #E2 . Las 20 iteraciones del bucle dan una estimación total de 4000 filas:
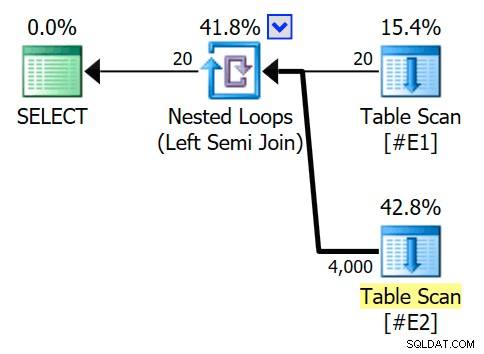
Las propiedades del operador de bucles anidados muestran que el predicado se aplica en la combinación lo que significa que se trata de una unión de bucles anidados no correlacionados :
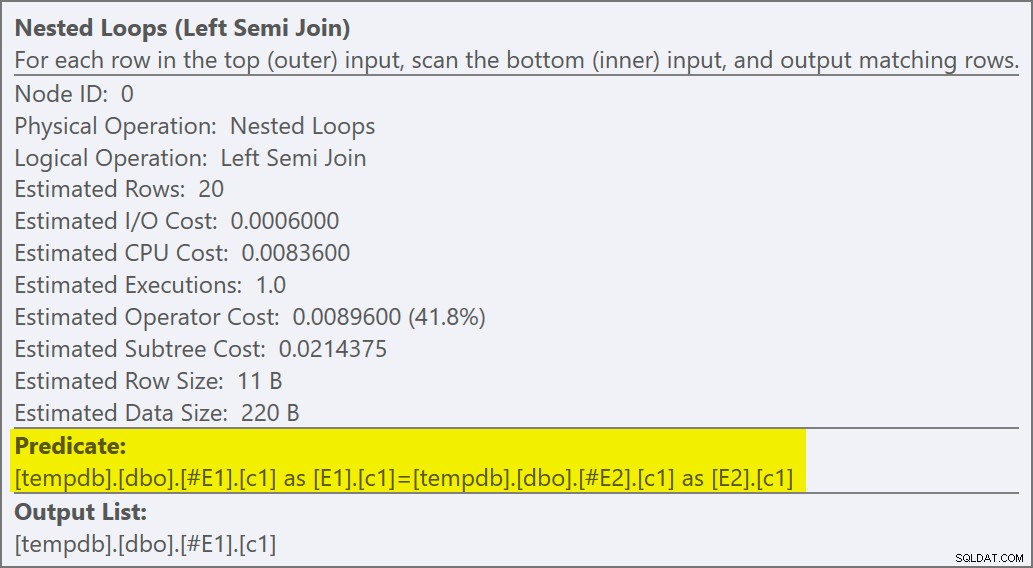
La salida del indicador de seguimiento (en la pestaña de mensajes de SSMS) muestra una semiunión de bucles anidados y ningún objetivo de fila (RowGoal 0):

Tenga en cuenta que el plan posterior a la ejecución para esta consulta de juguete no mostrará 4000 filas leídas de la tabla #E2 en total. La semiunión de bucles anidados (correlacionados o no) dejará de buscar más filas en el lado interno (por iteración) tan pronto como se encuentre la primera coincidencia para la fila externa actual. Ahora, el orden de las filas encontradas en el análisis del montón de #E2 en cada iteración no es determinista (y puede ser diferente en cada iteración), por lo que en principio casi todas las filas podrían probarse en cada iteración, en el caso de que la fila coincidente se encuentre lo más tarde posible (o, de hecho, en el caso de que no haya ninguna fila coincidente, en absoluto).
Por ejemplo, si asumimos una implementación en tiempo de ejecución donde las filas se escanean en el mismo orden (por ejemplo, "orden de inserción") cada vez, el número total de filas escaneadas en este ejemplo de juguete sería 20 filas en la primera iteración, 1 fila en la segunda iteración, 2 filas en la tercera iteración, y así sucesivamente hasta un total de 20 + 1 + 2 + (…) + 19 =210 filas. De hecho, es muy probable que observe este total, que dice más sobre las limitaciones del código de demostración simple que sobre cualquier otra cosa. No se puede confiar en el orden de las filas devueltas por un método de acceso no ordenado más de lo que se puede confiar en la salida aparentemente ordenada de una consulta sin un ORDER BY de nivel superior cláusula.
Aplicar unión semi
Ahora creamos un índice no agrupado en la tabla más grande (para animar al optimizador a elegir aplicar una combinación semi) y ejecutamos la consulta nuevamente:
CREATE NONCLUSTERED INDEX nc1 ON #E2 (c1);
SELECT E1.c1
FROM #E1 AS E1
WHERE E1.c1 IN
(SELECT E2.c1 FROM #E2 AS E2)
OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612); El plan de ejecución ahora presenta una combinación semi aplicada, con 1 fila por búsqueda de índice (y 20 iteraciones como antes):
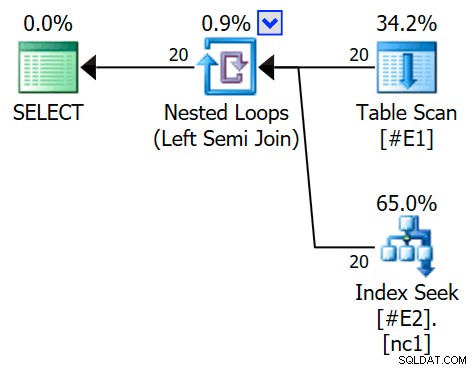
Podemos decir que es una aplicación de unión semi porque las propiedades de unión muestran una referencia externa en lugar de un predicado de unión:
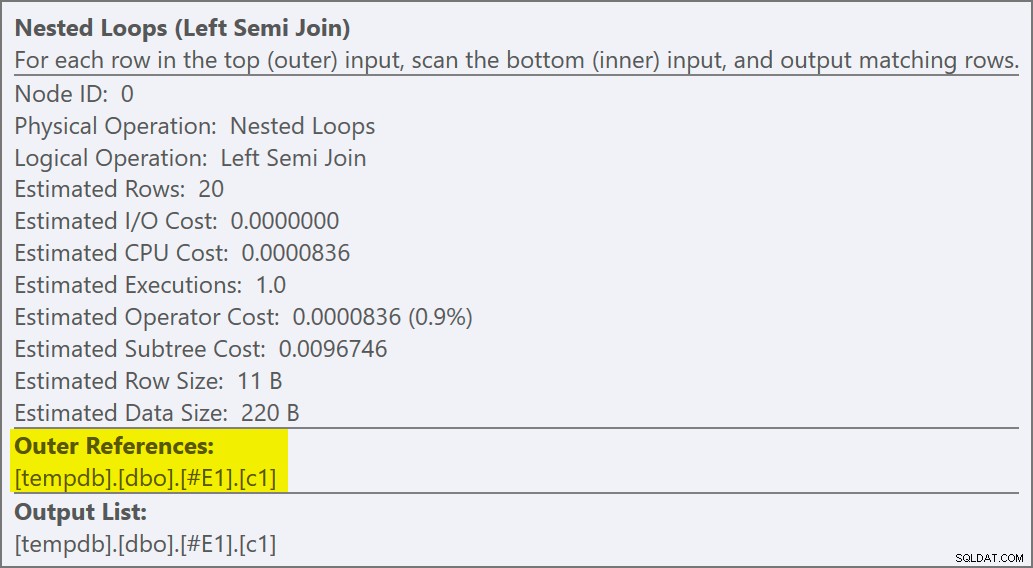
El predicado de unión ha sido reducido el lado interno de la aplicación, y emparejado con el nuevo índice:
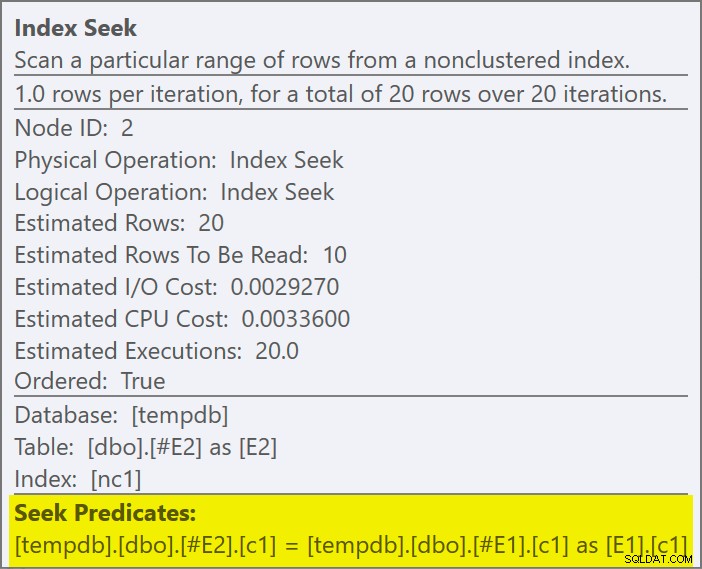
Se espera que cada búsqueda devuelva 1 fila, a pesar de que cada valor se duplica 10 veces en esa tabla; este es un efecto del objetivo de fila . El objetivo de la fila será más fácil de identificar en las compilaciones de SQL Server que exponen el EstimateRowsWithoutRowGoal atributo del plan (SQL Server 2017 CU3 en el momento de la redacción). En una próxima versión de Plan Explorer, esto también se expondrá en la información sobre herramientas para los operadores relevantes:

La salida de la marca de rastreo es:
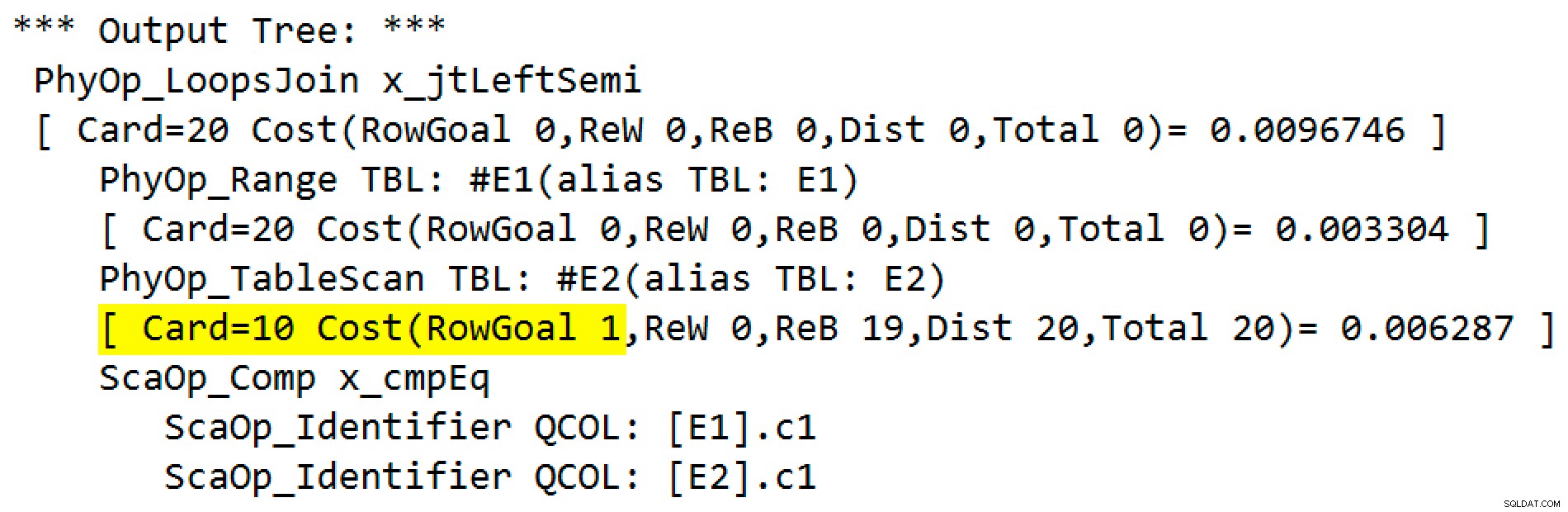
El operador físico ha cambiado de una unión de bucles a una aplicación que se ejecuta en el modo semiunión izquierdo. Acceso a la tabla #E2 ha adquirido un objetivo de fila de 1 (la cardinalidad sin el objetivo de fila se muestra como 10). El objetivo de la fila no es un gran problema en este caso porque el costo de recuperar unas diez filas estimadas por búsqueda no es mucho mayor que el de una fila. Deshabilitar objetivos de fila para esta consulta (usando el indicador de seguimiento 4138 o DISABLE_OPTIMIZER_ROWGOAL sugerencia de consulta) no cambiaría la forma del plan.
Sin embargo, en consultas más realistas, la reducción de costos debida al objetivo de la fila del lado interno puede marcar la diferencia entre las opciones de implementación de la competencia. Por ejemplo, deshabilitar el objetivo de la fila puede hacer que el optimizador elija un hash o una semiunión de fusión en su lugar, o cualquiera de las muchas otras opciones consideradas para la consulta. Por lo menos, el objetivo de la fila aquí refleja con precisión el hecho de que una semiunión de aplicación dejará de buscar en el lado interior tan pronto como se encuentre la primera coincidencia, y pasará a la siguiente fila del lado exterior.
Tenga en cuenta que se crearon duplicados en la tabla #E2 de modo que el objetivo de aplicación de la fila de semiunión (1) sería más bajo que la estimación normal (10, a partir de la información de densidad estadística). Si no hubo duplicados, la fila estimada para cada búsqueda en #E2 también sería 1 fila, por lo que no se aplicaría un objetivo de fila de 1 (¡recuerde la regla general sobre esto!)
Goles de fila frente a Top
Dado que los planes de ejecución no indican la presencia de un objetivo de fila antes de SQL Server 2017 CU3, uno podría pensar que habría sido más claro implementar esta optimización mediante un operador superior explícito, en lugar de una propiedad oculta como un objetivo de fila. La idea sería simplemente colocar un operador Superior (1) en el lado interior de una unión semi/anti de aplicación en lugar de establecer un objetivo de fila en la unión misma.
El uso de un operador Top de esta manera no habría sido del todo sin precedentes. Por ejemplo, ya existe una versión especial de Top conocida como top de recuento de filas que se ve en los planes de ejecución de modificación de datos cuando SET ROWCOUNT no es cero. está vigente (tenga en cuenta que este uso específico ha quedado obsoleto desde 2005, aunque todavía está permitido en SQL Server 2017). La implementación superior del recuento de filas es un poco torpe, ya que el operador superior siempre se muestra como Superior (0) en el plan de ejecución, independientemente del límite de recuento de filas real en vigor.
No hay ninguna razón de peso por la que el objetivo Aplicar fila de semiunión no se haya podido reemplazar con un operador Top (1) explícito. Dicho esto, hay algunas razones para preferir no hacer eso:
- Agregar un Top (1) explícito requiere más esfuerzo de codificación y pruebas del optimizador que agregar un objetivo de fila (que ya se usa para otras cosas).
- Top no es un operador relacional; el optimizador tiene poco apoyo para razonar al respecto. Esto podría tener un impacto negativo en la calidad del plan al limitar la capacidad del optimizador para transformar partes de un plan de consulta, p. moviendo agregados, uniones, filtros y uniones.
- Introduciría un acoplamiento estrecho entre la implementación de la semiunión y la parte superior. Los casos especiales y el acoplamiento estrecho son excelentes formas de introducir errores y hacer que los cambios futuros sean más difíciles y propensos a errores.
- La parte superior (1) sería lógicamente redundante y solo estaría presente por su efecto secundario de objetivo de fila.
Vale la pena ampliar ese último punto con un ejemplo:
SELECT
P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT TOP (1)
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE
TH.ProductID = P.ProductID
);
El TOP (1) en la subconsulta existe es simplificada por el optimizador, dando un plan de ejecución de semiunión simple:
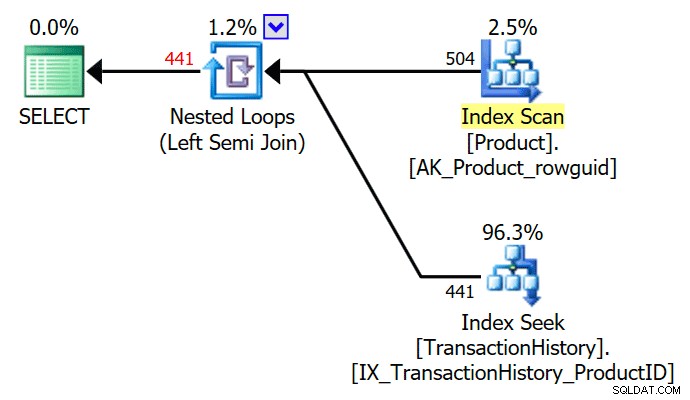
El optimizador también puede eliminar un DISTINCT redundante o GROUP BY en la subconsulta. Todos los siguientes producen el mismo plan que el anterior:
-- Redundant DISTINCT
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT DISTINCT
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
);
-- Redundant GROUP BY
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
GROUP BY TH.ProductID
);
-- Redundant DISTINCT TOP (1)
SELECT P.ProductID
FROM Production.Product AS P
WHERE
EXISTS
(
SELECT DISTINCT TOP (1)
TH.ProductID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); Resumen y pensamientos finales
Solo aplicar La semiunión de bucles anidados puede tener un objetivo de fila establecido por el optimizador. Este es el único tipo de unión que empuja los predicados de unión hacia abajo desde la unión, lo que permite probar la existencia de una coincidencia antes. . Semiunión de bucles anidados no correlacionados casi nunca* establece un objetivo de fila, y tampoco lo hace un hash o una semi combinación. La aplicación de bucles anidados se puede distinguir de la unión de bucles anidados no correlacionados por la presencia de referencias externas (en lugar de un predicado) en el operador de unión de bucles anidados para una aplicación.
Las posibilidades de ver una semi unión de aplicación en el plan de ejecución final dependen en cierta medida de la actividad de optimización inicial. Al carecer de sintaxis T-SQL directa, tenemos que expresar semiuniones en términos indirectos. Estos se analizan en un árbol lógico que contiene una subconsulta, que la actividad del optimizador temprano transforma en una aplicación, y luego en una semiunión no correlacionada cuando es posible.
Esta actividad de simplificación determina si una semiunión lógica se presenta al optimizador basado en costos como una semiunión de aplicación o regular. Cuando se presenta como una aplicación lógica semi unión, es casi seguro que la CBO producirá un plan de ejecución final con bucles anidados de aplicación física (y, por lo tanto, establecerá un objetivo de fila). Cuando se le presenta una semiunión no correlacionada, la CBO puede considere la transformación a una aplicación (o puede que no). La elección final del plan es una serie de decisiones basadas en costos, como de costumbre.
Al igual que todos los objetivos de fila, el objetivo de fila de semi unión puede ser bueno o malo para el rendimiento. Saber que una semiunión de aplicación establece un objetivo de fila al menos ayudará a las personas a reconocer y abordar la causa en caso de que ocurra un problema. La solución no siempre (ni siquiera por lo general) será deshabilitar los objetivos de fila para la consulta. A menudo se pueden realizar mejoras en la indexación (y/o la consulta) para proporcionar una forma eficiente de ubicar la primera fila coincidente.
Cubriré las uniones anti semi en un artículo separado, continuando con la serie de goles de fila.
* La excepción es una semiunión de bucles anidados no correlacionados sin predicado de unión (una vista poco común). Esto establece un objetivo de fila.