Las claves primarias y externas son características fundamentales de las bases de datos relacionales, como se señaló originalmente en el artículo de E. F. Codd, "Un modelo relacional de datos para grandes bancos de datos compartidos", publicado en 1970. La cita que se repite a menudo es:"La clave, la clave completa, y nada más que la llave, así que ayúdame, Codd".
Antecedentes:Claves primarias
Una clave principal es una restricción en SQL Server, que actúa para identificar de manera única cada fila en una tabla. La clave se puede definir como una sola columna no NULL o una combinación de columnas no NULL que genera un valor único y se usa para imponer la integridad de la entidad para una tabla. Una tabla solo puede tener una clave principal, y cuando se define una restricción de clave principal para una tabla, se crea un índice único. Ese índice será un índice agrupado de forma predeterminada, a menos que se especifique como un índice no agrupado cuando se define la restricción de clave principal.
Considere el Sales.SalesOrderHeader tabla en AdventureWorks2012 base de datos. Esta tabla contiene información básica sobre un pedido de ventas, incluida la fecha del pedido y el ID del cliente, y cada venta se identifica de forma única mediante un SalesOrderID. , que es la clave principal de la tabla. Cada vez que se agrega una nueva fila a la tabla, la restricción de clave principal (llamada PK_SalesOrderHeader_SalesOrderID ) se verifica para garantizar que no exista ninguna fila con el mismo valor para SalesOrderID .
Claves foráneas
Separadas de las claves primarias, pero muy relacionadas, están las claves foráneas. Una clave externa es una columna o combinación de columnas que es igual a la clave principal, pero en una tabla diferente. Las claves foráneas se utilizan para definir una relación y hacer cumplir la integridad entre dos tablas.
Para continuar usando el ejemplo anterior, el SalesOrderID la columna existe como clave externa en Sales.SalesOrderDetail tabla, donde se almacena información adicional sobre la venta, como la identificación del producto y el precio. Cuando se agrega una nueva venta al SalesOrderHeader tabla, no es necesario agregar una fila para esa venta a SalesOrderDetail tabla Sin embargo, al agregar una fila a SalesOrderDetail tabla, una fila correspondiente para el SalesOrderID debe existe en el SalesOrderHeader mesa.
Por el contrario, al eliminar datos, una fila para un SalesOrderID específico se puede eliminar en cualquier momento desde el SalesOrderDetail tabla, pero para que se elimine una fila del SalesOrderHeader tabla, filas asociadas de SalesOrderDetail tendrá que eliminarse primero.
A diferencia de las restricciones de clave principal, cuando se define una restricción de clave externa para una tabla, SQL Server no crea un índice de forma predeterminada. Sin embargo, no es raro que los desarrolladores y administradores de bases de datos los agreguen manualmente. La clave externa puede ser parte de una clave primaria compuesta para la tabla, en cuyo caso existiría un índice agrupado con la clave externa como parte de la clave de agrupación. Alternativamente, las consultas pueden requerir un índice que incluya la clave externa y una o más columnas adicionales en la tabla, por lo que se crearía un índice no agrupado para admitir esas consultas. Además, los índices en claves externas pueden proporcionar beneficios de rendimiento para las uniones de tablas que involucran la clave principal y externa, y pueden afectar el rendimiento cuando se actualiza el valor de la clave principal o si se elimina la fila.
En el AdventureWorks2012 base de datos, hay una tabla, SalesOrderDetail , con SalesOrderID como clave foránea. Para el SalesOrderDetail tabla, SalesOrderID y SalesOrderDetailID se combinan para formar la clave principal, respaldada por un índice agrupado. Si el SalesOrderDetail la tabla no tenía un índice en el SalesOrderID columna, luego, cuando se elimina una fila de SalesOrderHeader , SQL Server tendría que verificar que no haya filas para el mismo SalesOrderID valor existe. Sin ningún índice que contenga el SalesOrderID columna, SQL Server necesitaría realizar una exploración completa de la tabla de SalesOrderDetail . Como puede imaginar, cuanto más grande sea la tabla a la que se hace referencia, más tardará la eliminación.
Un ejemplo
Podemos ver esto en el siguiente ejemplo, que usa copias de las tablas mencionadas del AdventureWorks2012 base de datos que se ha ampliado mediante un script que se puede encontrar aquí. El script fue desarrollado por Jonathan Kehayias (blog | @SQLPoolBoy) y crea un SalesOrderHeaderEnlarged tabla con 1 258 600 filas y un SalesOrderDetailEnlarged tabla con 4.852.680 filas. Después de ejecutar la secuencia de comandos, se agregó la restricción de clave externa utilizando las siguientes declaraciones. Tenga en cuenta que la restricción se crea con ON DELETE CASCADE opción. Con esta opción, cuando se emite una actualización o eliminación contra el SalesOrderHeaderEnlarged tabla, filas en las tablas correspondientes; en este caso, solo SalesOrderDetailEnlarged – se actualizan o eliminan.
Además, el índice agrupado predeterminado para SalesOrderDetailEnglarged se eliminó y se volvió a crear para tener solo SalesOrderDetailID como clave principal, ya que representa un diseño típico.
USE [AdventureWorks2012];
GO
/* remove original clustered index */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
DROP CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID];
GO
/* re-create clustered index with SalesOrderDetailID only */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
ADD CONSTRAINT [PK_SalesOrderDetailEnlarged_SalesOrderDetailID] PRIMARY KEY CLUSTERED
(
[SalesOrderDetailID] ASC
)
WITH
(
PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON
) ON [PRIMARY];
GO
/* add foreign key constraint for SalesOrderID */
ALTER TABLE [Sales].[SalesOrderDetailEnlarged] WITH CHECK
ADD CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID]
FOREIGN KEY([SalesOrderID])
REFERENCES [Sales].[SalesOrderHeaderEnlarged] ([SalesOrderID])
ON DELETE CASCADE;
GO
ALTER TABLE [Sales].[SalesOrderDetailEnlarged]
CHECK CONSTRAINT [FK_SalesOrderDetailEnlarged_SalesOrderHeaderEnlarged_SalesOrderID];
GO
Con la restricción de clave externa y sin índice de soporte, se emitió una sola eliminación contra SalesOrderHeaderEnlarged tabla, lo que resultó en la eliminación de una fila de SalesOrderHeaderEnlarged y 72 filas de SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 292104;
Las estadísticas de E/S y la información de tiempo mostraron lo siguiente:
Tiempo de análisis y compilación de SQL Server:Tiempo de CPU =8 ms, tiempo transcurrido =8 ms.
Tabla 'SalesOrderDetailEnlarged'. Recuento de escaneo 1, lecturas lógicas 50647, lecturas físicas 8, lecturas anticipadas 50667, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tabla 'Worktable'. Recuento de escaneo 2, lecturas lógicas 7, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tabla 'SalesOrderHeaderEnlarged'. Recuento de escaneo 0, lecturas lógicas 15, lecturas físicas 14, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tiempos de ejecución de SQL Server:
Tiempo de CPU =1045 ms, tiempo transcurrido =1898 ms.
Usando SQL Sentry Plan Explorer, el plan de ejecución muestra un escaneo de índice agrupado contra SalesOrderDetailEnlarged ya que no hay índice en SalesOrderID :
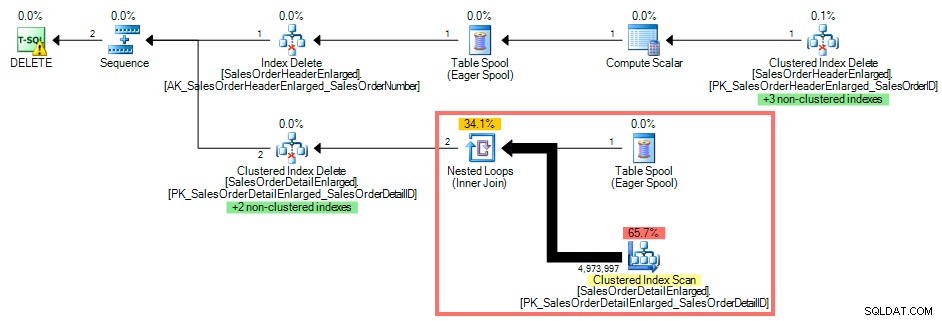
Plan de consulta sin índice en la clave externa
El índice no agrupado para admitir SalesOrderDetailEnlarged luego se creó usando la siguiente declaración:
USE [AdventureWorks2012]; GO /* create nonclustered index */ CREATE NONCLUSTERED INDEX [IX_SalesOrderDetailEnlarged_SalesOrderID] ON [Sales].[SalesOrderDetailEnlarged] ( [SalesOrderID] ASC ) WITH ( PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY]; GO
Se ejecutó otra eliminación para un SalesOrderID que afectó una fila en SalesOrderHeaderEnlarged y 72 filas en SalesOrderDetailEnlarged :
SET STATISTICS IO ON; SET STATISTICS TIME ON; DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; USE [AdventureWorks2012]; GO DELETE FROM [Sales].[SalesOrderHeaderEnlarged] WHERE [SalesOrderID] = 697505;
Las estadísticas de E/S y la información de tiempo mostraron una mejora espectacular:
Tiempo de análisis y compilación de SQL Server:Tiempo de CPU =0 ms, tiempo transcurrido =7 ms.
Tabla 'SalesOrderDetailEnlarged'. Recuento de escaneo 1, lecturas lógicas 48, lecturas físicas 13, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tabla 'Worktable'. Recuento de escaneo 2, lecturas lógicas 7, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tabla 'SalesOrderHeaderEnlarged'. Recuento de escaneo 0, lecturas lógicas 15, lecturas físicas 15, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tiempos de ejecución de SQL Server:
Tiempo de CPU =0 ms, tiempo transcurrido =27 ms.
Y el plan de consulta mostró una búsqueda de índice del índice no agrupado en SalesOrderID , como se esperaba:
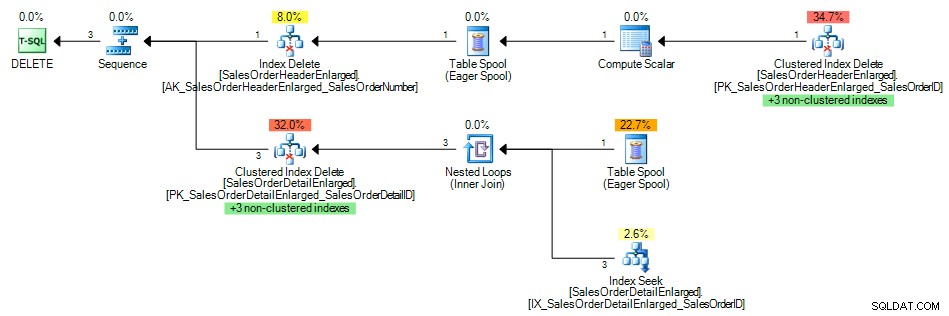
Plan de consulta con índice en la clave externa
El tiempo de ejecución de la consulta se redujo de 1898 ms a 27 ms, una reducción del 98,58 %, y lecturas para SalesOrderDetailEnlarged la tabla disminuyó de 50647 a 48, una mejora del 99,9 %. Aparte de los porcentajes, considere solo la E/S generada por la eliminación. El SalesOrderDetailEnlarged la tabla tiene solo 500 MB en este ejemplo, y para un sistema con 256 GB de memoria disponible, una tabla que ocupa 500 MB en el caché del búfer no parece una situación terrible. Pero una tabla de 5 millones de filas es relativamente pequeña; la mayoría de los grandes sistemas OLTP tienen tablas con cientos de millones de filas. Además, no es raro que existan varias referencias de clave externa para una clave principal, donde una eliminación de la clave principal requiere eliminaciones de varias tablas relacionadas. En ese caso, es posible ver duraciones extendidas para las eliminaciones, lo que no solo es un problema de rendimiento, sino también un problema de bloqueo, según el nivel de aislamiento.
Conclusión
Por lo general, se recomienda crear un índice que conduzca a la(s) columna(s) de la clave externa, para admitir no solo las uniones entre las claves principal y externa, sino también las actualizaciones y las eliminaciones. Tenga en cuenta que esta es una recomendación general, ya que hay escenarios de casos extremos en los que no se usó el índice adicional en la clave externa debido al tamaño de tabla extremadamente pequeño, y las actualizaciones de índice adicionales en realidad afectaron negativamente el rendimiento. Al igual que con cualquier modificación de esquema, las adiciones de índice deben probarse y monitorearse después de la implementación. Es importante asegurarse de que los índices adicionales produzcan los efectos deseados y no afecten negativamente el rendimiento de la solución. También vale la pena señalar cuánto espacio adicional requieren los índices para las claves externas. Es esencial tener esto en cuenta antes de crear los índices y, si brindan un beneficio, debe tenerse en cuenta para la planificación de la capacidad en el futuro.



