Sus responsabilidades como DBA (o DBCC CHECKDB . Puede llegar a la mitad creando un plan de mantenimiento simple con una "Tarea de verificación de integridad de la base de datos"; sin embargo, en mi opinión, esto es solo marcar una casilla de verificación.
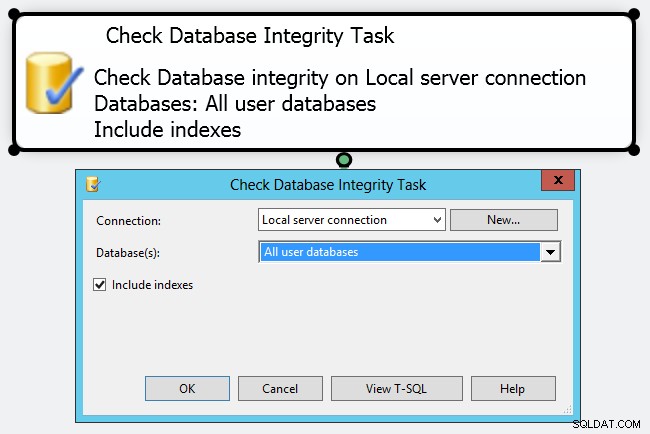
Si mira más de cerca, es muy poco lo que puede hacer para controlar cómo funciona la tarea. Incluso el amplio panel de Propiedades expone una gran cantidad de configuraciones para el subplan de mantenimiento, pero prácticamente nada sobre el DBCC comandos que ejecutará. Personalmente, creo que debería adoptar un enfoque mucho más proactivo y controlado sobre cómo realiza su CHECKDB operaciones en entornos de producción, creando sus propios trabajos y elaborando manualmente su DBCC comandos Puede adaptar su programación o los propios comandos a diferentes bases de datos; por ejemplo, la base de datos de membresía de ASP.NET probablemente no sea tan crucial como su base de datos de ventas y podría tolerar controles menos frecuentes y/o menos exhaustivos.
Pero para sus bases de datos cruciales, pensé en preparar una publicación para detallar algunas de las cosas que investigaría para minimizar la interrupción DBCC pueden causar los comandos, y de qué mitos y alboroto de marketing debe tener cuidado. Y quiero agradecer a Paul "Mr. DBCC" Randal (@PaulRandal) por su valioso aporte, no solo para esta publicación específica, sino también por los interminables consejos que brinda en su blog, #sqlhelp y en la capacitación de inmersión en habilidades SQL.
Tome todas estas ideas con pinzas y haga todo lo posible para realizar pruebas adecuadas en su entorno; no todas estas sugerencias producirán un mejor rendimiento en todos los entornos. Pero se lo debe a usted mismo, a sus usuarios y a sus partes interesadas al menos considerar el impacto que su CHECKDB operaciones podrían tener, y tome medidas para mitigar esos efectos cuando sea factible, sin introducir riesgos innecesarios al no verificar las cosas correctas.
Reduce el ruido y consume todos los errores
No importa dónde esté ejecutando CHECKDB , utilice siempre el WITH NO_INFOMSGS opción. Esto simplemente suprime toda la salida irrelevante que solo le dice cuántas filas hay en cada tabla; si está interesado en esa información, puede obtenerla mediante consultas simples contra los DMV y no mientras DBCC Esta corriendo. Suprimir la salida hace que sea mucho menos probable que te pierdas un mensaje crítico enterrado en toda esa salida feliz.
Del mismo modo, siempre debe usar WITH ALL_ERRORMSGS opción, pero especialmente si está ejecutando SQL Server 2008 RTM o SQL Server 2005 (en esos casos, puede ver la lista de errores por objeto truncada a 200). Para cualquier CHECKDB operaciones que no sean verificaciones rápidas ad-hoc, debería considerar dirigir la salida a un archivo. Management Studio está limitado a 1000 líneas de salida de DBCC CHECKDB , por lo que es posible que se pierda algunos errores si supera esta cifra.
Si bien no es estrictamente un problema de rendimiento, el uso de estas opciones evitará que tenga que ejecutar el proceso nuevamente. Esto es especialmente crítico si se encuentra en medio de una recuperación ante desastres.
Descargue comprobaciones lógicas cuando sea posible
En la mayoría de los casos, CHECKDB pasa la mayor parte de su tiempo realizando comprobaciones lógicas de los datos. Si tiene la capacidad de realizar estas comprobaciones en una copia fiel de los datos, puede centrar sus esfuerzos en la estructura física de sus sistemas de producción y utilizar el servidor secundario para gestionar todas las comprobaciones lógicas y aliviar esa carga del servidor principal. Por servidor secundario , me refiero solo a lo siguiente:
- El lugar donde prueba sus restauraciones completas, porque usted prueba sus restauraciones, ¿verdad?
Otras personas (sobre todo la gigantesca fuerza de marketing que es Microsoft) podrían haberlo convencido de que otras formas de servidores secundarios son adecuadas para DBCC cheques Por ejemplo:
- una secundaria legible del grupo de disponibilidad AlwaysOn;
- una instantánea de una base de datos duplicada;
- un registro enviado secundario;
- Duplicación de SAN;
- u otras variaciones…
Desafortunadamente, este no es el caso, y ninguno de estos secundarios son lugares válidos y confiables para realizar sus comprobaciones como alternativa al principal. Solo una copia de seguridad uno por uno puede servir como una copia fiel; cualquier otra cosa que dependa de cosas como la aplicación de copias de seguridad de registros para llegar a un estado consistente no reflejará de manera confiable los problemas de integridad en el primario.
Entonces, en lugar de intentar descargar sus controles lógicos a un secundario y nunca realizarlos en el primario, esto es lo que sugiero:
- Asegúrese de probar con frecuencia las restauraciones de sus copias de seguridad completas. Y no, esto no incluye
COPY_ONLYcopias de seguridad de un secundario de AG, por las mismas razones que las anteriores; eso solo sería válido en el caso de que acaba de iniciar el secundario con una restauración completa. - Ejecute
DBCC CHECKDBa menudo contra el completo restaurar, antes de hacer cualquier otra cosa. Nuevamente, reproducir los registros en este punto invalidará esta base de datos como una copia verdadera de la fuente - Ejecute
DBCC CHECKDBcontra su principal, tal vez divididas de la manera que sugiere Paul Randal, y/o en un horario menos frecuente, y/o usandoPHYSICAL_ONLYmás a menudo que no. Esto puede depender de la frecuencia y la fiabilidad con la que esté realizando (2). - Nunca asuma que las comprobaciones contra el secundario son suficientes. Incluso con una réplica exacta de su base de datos principal, aún existen problemas físicos que pueden ocurrir en el subsistema de E/S de su principal que nunca se propagarán a la secundaria.
- Analizar siempre
DBCCproducción. Simplemente ejecutarlo e ignorarlo, para marcarlo en alguna lista, es tan útil como ejecutar copias de seguridad y afirmar que tuvo éxito sin siquiera probar que realmente puede restaurar esa copia de seguridad cuando sea necesario.
Experimentar con marcas de seguimiento 2549, 2562 y 2566
Realicé algunas pruebas exhaustivas de dos marcas de seguimiento (2549 y 2562) y descubrí que pueden generar mejoras sustanciales en el rendimiento; sin embargo, Lonny informa que ya no son necesarias ni útiles. Si está en 2016 o más reciente, sáltese toda esta sección . Si tiene una versión anterior, estas dos marcas de rastreo se describen con mucho más detalle en KB #2634571, pero básicamente:
- Bandera de rastreo 2549
- Esto optimiza el proceso checkdb al tratar cada archivo de base de datos individual como si residiera en un disco subyacente único. Está bien usarlo si su base de datos tiene un solo archivo de datos, o si sabe que cada archivo de la base de datos está, de hecho, en una unidad separada. Si su base de datos tiene varios archivos y comparten un solo eje adjunto directo, debe tener cuidado con este indicador de rastreo, ya que puede causar más daño que bien.
IMPORTANTE :sql.sasquatch informa de una regresión en el comportamiento de este indicador de seguimiento en SQL Server 2014.
- Esto optimiza el proceso checkdb al tratar cada archivo de base de datos individual como si residiera en un disco subyacente único. Está bien usarlo si su base de datos tiene un solo archivo de datos, o si sabe que cada archivo de la base de datos está, de hecho, en una unidad separada. Si su base de datos tiene varios archivos y comparten un solo eje adjunto directo, debe tener cuidado con este indicador de rastreo, ya que puede causar más daño que bien.
- Bandera de rastreo 2562
- Esta marca trata todo el proceso de checkdb como un solo lote, a costa de una mayor utilización de tempdb (hasta un 5 % del tamaño de la base de datos).
- Utiliza un algoritmo mejor para determinar cómo leer páginas de la base de datos, lo que reduce la contención de pestillos (específicamente para
DBCC_MULTIOBJECT_SCANNER). Tenga en cuenta que esta mejora específica se encuentra en la ruta del código de SQL Server 2012, por lo que se beneficiará incluso sin el indicador de seguimiento. Esto puede evitar errores como:
Se agotó el tiempo de espera mientras se esperaba el pestillo:clase 'DBCC_MULTIOBJECT_SCANNER'.
- Los dos indicadores de seguimiento anteriores están disponibles en las siguientes versiones:
- SQL Server 2008 Service Pack 2 Actualización acumulativa 9+
(10.00.4330 -> 10.00.5499)SQL Server 2008 Service Pack 3 Actualización acumulativa 4+
(10.00.5775+)Actualización acumulativa de SQL Server 2008 R2 RTM 11+
(10.50.1809 -> 10.50.2424)SQL Server 2008 R2 Service Pack 1 Actualización acumulativa 4+
(10.50.2796 -> 10.50.3999)SQL Server 2008 R2 Service Pack 2
(10.50.4000+)SQL Server 2012, todas las versiones
(11.00.2100+) - Bandera de seguimiento 2566
- Si aún utiliza SQL Server 2005, esta marca de rastreo, introducida en 2005 SP2 CU#9 (9.00.3282) (aunque no está documentada en el artículo de la base de conocimiento de esa actualización acumulativa, KB #953752), intenta corregir el rendimiento deficiente de
DATA_PURITYcomprobaciones en sistemas basados en x64. En un momento, podía ver más detalles en KB #945770, pero parece que ese artículo se eliminó tanto del sitio de soporte de Microsoft como de la máquina WayBack. Este indicador de seguimiento no debería ser necesario en versiones más modernas de SQL Server, ya que se solucionó el problema en el procesador de consultas.
- Si aún utiliza SQL Server 2005, esta marca de rastreo, introducida en 2005 SP2 CU#9 (9.00.3282) (aunque no está documentada en el artículo de la base de conocimiento de esa actualización acumulativa, KB #953752), intenta corregir el rendimiento deficiente de
Si va a utilizar alguno de estos indicadores de seguimiento, le recomiendo configurarlos en el nivel de sesión mediante DBCC TRACEON en lugar de como un indicador de seguimiento de inicio. No solo le permite desactivarlos sin tener que ejecutar un ciclo de SQL Server, sino que también le permite implementarlos solo cuando realiza ciertos CHECKDB comandos, a diferencia de las operaciones que utilizan cualquier tipo de reparación.
Reduzca el impacto de E/S:optimice tempdb
DBCC CHECKDB puede hacer un uso intensivo de tempdb, así que asegúrese de planificar la utilización de recursos allí. Esto suele ser una buena cosa que hacer en cualquier caso. Para CHECKDB querrá asignar adecuadamente el espacio a tempdb; lo último que quieres es CHECKDB progreso (y cualquier otra operación concurrente) para tener que esperar un crecimiento automático. Puedes hacerte una idea de los requisitos usando WITH ESTIMATEONLY , como Pablo explica aquí. Solo tenga en cuenta que la estimación puede ser bastante baja debido a un error en SQL Server 2008 R2. Además, si utiliza la marca de rastreo 2562, asegúrese de adaptarse a los requisitos de espacio adicional.
Y, por supuesto, todos los consejos típicos para optimizar tempdb en casi cualquier sistema también son apropiados aquí:asegúrese de que tempdb esté en su propio conjunto de rápido ejes, asegúrese de que tenga el tamaño adecuado para adaptarse a todas las demás actividades concurrentes sin tener que crecer, asegúrese de que está utilizando una cantidad óptima de archivos de datos, etc. Algunos otros recursos que podría considerar:
- Optimización del rendimiento de tempdb (MSDN)
- Planificación de capacidad para tempdb (MSDN)
- Un mito diario del DBA de SQL Server:(30/12) tempdb siempre debe tener un archivo de datos por núcleo de procesador
Reduzca el impacto de E/S:controle la instantánea
Para ejecutar CHECKDB , las versiones modernas de SQL Server intentarán crear una instantánea oculta de su base de datos en la misma unidad (o en todas las unidades si sus archivos de datos abarcan varias unidades). No puede controlar este mecanismo, pero si desea controlar dónde CHECKDB funciona, primero cree su propia instantánea (se requiere Enterprise Edition) en la unidad que desee y ejecute DBCC comando contra la instantánea. En cualquier caso, querrá ejecutar esta operación durante un tiempo de inactividad relativo, para minimizar la actividad de copia en escritura que pasará por la instantánea. Y no querrá que esta programación entre en conflicto con ninguna operación de escritura pesada, como el mantenimiento de índices o ETL.
Es posible que haya visto sugerencias para forzar CHECKDB para ejecutar en modo fuera de línea usando el WITH TABLOCK opción. Recomiendo fuertemente en contra de este enfoque. Si su base de datos se está utilizando activamente, elegir esta opción solo frustrará a los usuarios. Y si la base de datos no se está utilizando activamente, no está ahorrando espacio en disco al evitar una instantánea, ya que no habrá actividad de copia en escritura para almacenar.
Reduzca el impacto de E/S:evite los errores 665/1450/1452
En algunos casos, es posible que vea uno de los siguientes errores:
El sistema operativo devolvió el error 1450 (Existen recursos de sistema insuficientes para completar el servicio solicitado) a SQL Server durante una escritura en el desplazamiento 0x[…] en el archivo con identificador 0x[…]. Esta suele ser una condición temporal y SQL Server seguirá intentando la operación. Si la condición persiste, se deben tomar medidas inmediatas para corregirla.
El sistema operativo devolvió el error 665 (La operación solicitada no se pudo completar debido a una limitación del sistema de archivos) a SQL Server durante una escritura en el desplazamiento 0x[…] en el archivo '[archivo]'
Aquí hay algunos consejos para reducir el riesgo de estos errores durante CHECKDB operaciones y reducir su impacto en general, con varias correcciones disponibles, según su sistema operativo y la versión de SQL Server:
- Errores de archivos dispersos:1450 o 665 debido a la fragmentación de archivos:correcciones y soluciones alternativas
- SQL Server informa del error del sistema operativo 1450 o 1452 o 665 (reintentos)
Reducir el impacto de la CPU
DBCC CHECKDB es de subprocesos múltiples de forma predeterminada (pero solo en Enterprise Edition). Si su sistema está vinculado a la CPU, o simplemente desea CHECKDB para usar menos CPU a costa de ejecutar más tiempo, puede considerar reducir el paralelismo de dos maneras diferentes:
DBCC CHECKDB (así como CHECKFILEGROUP y CHECKTABLE ). El indicador de seguimiento 2528 se describe aquí. Por supuesto esto solo es válido en Enterprise Edition, porque a pesar de lo que actualmente dice Books Online, lo cierto es que CHECKDB no va en paralelo en la Edición Estándar. DBCC el comando en sí no es compatible con MAXDOP (al menos antes de SQL Server 2014 SP2), respeta la configuración global max degree of parallelism . Probablemente no sea algo que haría en producción a menos que no tuviera otras opciones, pero esta es una forma general de controlar ciertos DBCC comandos si no puede apuntarlos más explícitamente.
Habíamos pedido un mejor control sobre la cantidad de CPU que DBCC CHECKDB usos, pero se habían negado repetidamente hasta SQL Server 2014 SP2. Entonces ahora puede agregar WITH MAXDOP = n al comando.
Mis hallazgos
Quería demostrar algunas de estas técnicas en un entorno que pudiera controlar. Instalé AdventureWorks2012, luego lo expandí usando el script ampliador AW escrito por Jonathan Kehayias (blog | @SQLPoolBoy), que aumentó la base de datos a unos 7 GB. Luego ejecuté una serie de CHECKDB órdenes contra él, y los cronometró. Usé un simple DBCC CHECKDB de vainilla por sí solo, todos los demás comandos usaron WITH NO_INFOMSGS, ALL_ERRORMSGS . Luego, cuatro pruebas con (a) sin marcas de seguimiento, (b) 2549, (c) 2562 y (d) 2549 y 2562. Luego repetí esas cuatro pruebas, pero agregué PHYSICAL_ONLY opción, que pasa por alto todas las comprobaciones lógicas. Los resultados (un promedio de 10 ejecuciones de prueba) son reveladores:
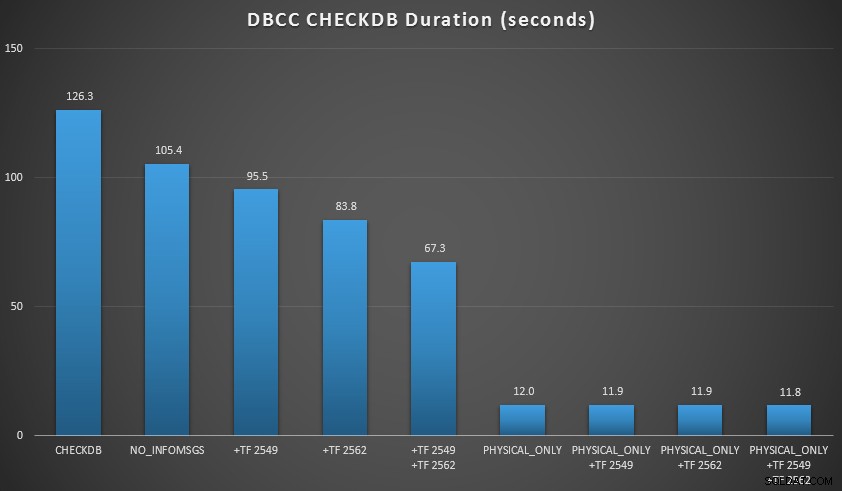
Resultados de CHECKDB contra una base de datos de 7 GB
Luego amplié la base de datos un poco más, haciendo muchas copias de las dos tablas ampliadas, lo que llevó a un tamaño de base de datos de apenas 70 GB y ejecuté las pruebas nuevamente. Los resultados, nuevamente promediados en 10 ejecuciones de prueba:
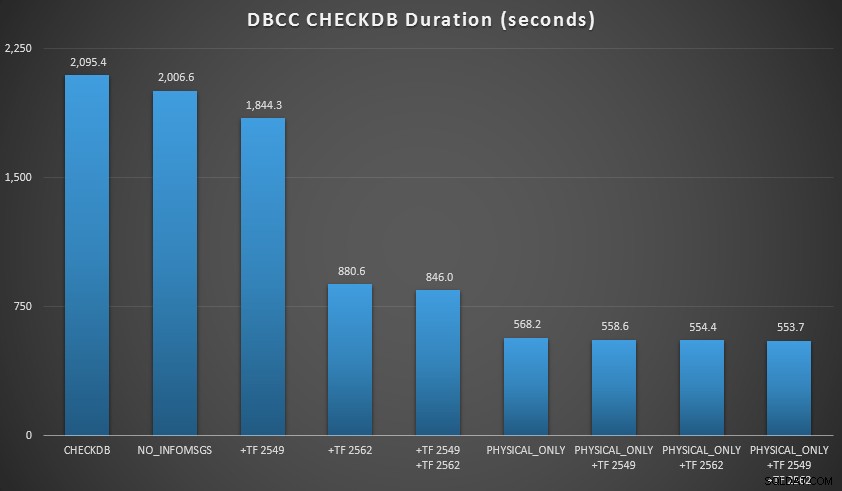
Resultados de CHECKDB contra una base de datos de 70 GB
En estos dos escenarios, aprendí lo siguiente (nuevamente, teniendo en cuenta que su millaje puede variar y que deberá realizar sus propias pruebas para sacar conclusiones significativas):
- En tamaños de base de datos pequeños,
NO_INFOMSGSLa opción puede reducir significativamente el tiempo de procesamiento cuando las comprobaciones se ejecutan en SSMS. Sin embargo, en bases de datos más grandes, este beneficio disminuye, ya que el tiempo y el trabajo dedicados a transmitir la información se convierten en una parte tan insignificante de la duración total. 21 segundos de 2 minutos es sustancial; 88 segundos de 35 minutos, no tanto. - Las dos marcas de seguimiento que probé tuvieron un impacto significativo en el rendimiento, lo que representa una reducción del tiempo de ejecución del 40-60 % cuando se usaron ambas juntas.
- Puedo reducir el tiempo de procesamiento en mi instancia principal en un 70-90 % en comparación con un
CHECKDBestándar llamar sin opciones. - En mi escenario, las marcas de seguimiento tuvieron muy poco impacto en la duración al realizar
PHYSICAL_ONLYcheques.
Por supuesto, y no puedo enfatizar esto lo suficiente, estas son bases de datos relativamente pequeñas y solo se usan para poder realizar pruebas repetidas y medidas en una cantidad de tiempo razonable. Este servidor tenía 80 CPU lógicas y 128 GB de RAM, y yo era el único usuario. La duración y la interacción con otras cargas de trabajo en el sistema pueden sesgar un poco estos resultados. Aquí hay un vistazo rápido del uso típico de la CPU, usando SQL Sentry, durante uno de los CHECKDB operaciones (y ninguna de las opciones realmente cambió el impacto general en la CPU, solo la duración):
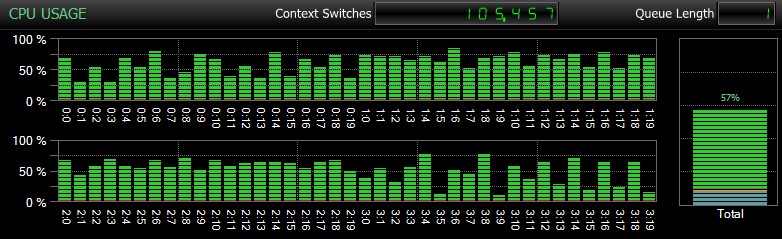
Impacto en la CPU durante CHECKDB:modo de muestra
Y aquí hay otra vista, que muestra perfiles de CPU similares para tres ejemplos diferentes CHECKDB operaciones en modo histórico (he superpuesto una descripción de las tres pruebas muestreadas en este rango):
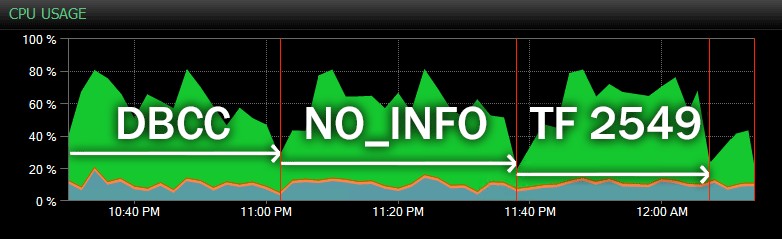
Impacto en la CPU durante CHECKDB:modo histórico
En bases de datos aún más grandes, alojadas en servidores más ocupados, puede ver diferentes efectos y es muy probable que su kilometraje varíe. Por lo tanto, realice su debida diligencia y pruebe estas opciones y rastree los indicadores durante una carga de trabajo concurrente típica antes de decidir cómo desea abordar CHECKDB .
Conclusión
DBCC CHECKDB es una parte muy importante pero a menudo infravalorada de su responsabilidad como DBA o arquitecto, y crucial para la protección de los datos de su empresa. No tome esta responsabilidad a la ligera y haga todo lo posible para asegurarse de no sacrificar nada en aras de reducir el impacto en sus instancias de producción. Lo que es más importante:mire más allá de las hojas de datos de marketing para asegurarse de que comprende completamente cuán válidas son esas promesas y si está dispuesto a apostar los datos de su empresa por ellas. Escatimar en algunos cheques o descargarlos en ubicaciones secundarias no válidas podría ser un desastre a punto de ocurrir.
También debería considerar leer estos artículos de PSS:
- Un CHECKDB más rápido - Parte I
- Un CHECKDB más rápido - Parte II
- Un CHECKDB más rápido - Parte III
- Un CHECKDB más rápido:Parte IV (UDT SQL CLR)
Y esta publicación de Brent Ozar:
- 3 formas de ejecutar DBCC CHECKDB más rápido
Finalmente, si tiene una pregunta sin resolver sobre DBCC CHECKDB , publíquelo en la etiqueta hash #sqlhelp en Twitter. Paul revisa esa etiqueta con frecuencia y, dado que su imagen debe aparecer en el artículo principal de Books Online, es probable que si alguien puede responderla, él pueda hacerlo. Si es demasiado complejo para 140 caracteres, puede preguntar aquí (y me aseguraré de que Paul lo vea en algún momento) o publicarlo en un sitio de foro como Database Administrators Stack Exchange.