Los planes de ejecución proporcionan una rica fuente de información que puede ayudarnos a identificar formas de mejorar el rendimiento de consultas importantes. Las personas a menudo buscan cosas como escaneos grandes y búsquedas como una forma de identificar posibles optimizaciones de rutas de acceso a datos. Estos problemas a menudo se pueden resolver rápidamente creando un nuevo índice o ampliando uno existente con más columnas incluidas.
También podemos usar planes posteriores a la ejecución para comparar los recuentos de filas reales con los esperados entre los operadores del plan. Cuando se encuentre que estos difieren significativamente, podemos intentar proporcionar una mejor información estadística al optimizador actualizando las estadísticas existentes, creando nuevos objetos de estadísticas, utilizando estadísticas en columnas calculadas o quizás dividiendo una consulta compleja en un componente menos complejo. partes.
Más allá de eso, también podemos observar operaciones costosas en el plan, en particular las que consumen memoria, como la clasificación y el hash. La clasificación a veces se puede evitar mediante cambios de indexación. Otras veces, es posible que tengamos que refactorizar la consulta usando una sintaxis que favorezca un plan que conserve un orden deseado en particular.
A veces, el rendimiento seguirá sin ser lo suficientemente bueno incluso después de aplicar todas estas técnicas de ajuste del rendimiento. Un posible próximo paso es pensar un poco más sobre el plan como un todo . Esto significa dar un paso atrás, tratando de comprender la estrategia general elegida por el optimizador de consultas, para ver si podemos identificar una mejora algorítmica.
Este artículo explora este último tipo de análisis, utilizando un problema de ejemplo simple de encontrar valores de columna únicos en un conjunto de datos moderadamente grande. Como suele ser el caso en problemas análogos del mundo real, la columna de interés tendrá relativamente pocos valores únicos, en comparación con el número de filas de la tabla. Hay dos partes en este análisis:crear los datos de muestra y escribir la consulta de valores distintos.
Creación de los datos de muestra
Para proporcionar el ejemplo más simple posible, nuestra tabla de prueba tiene solo una columna con un índice agrupado (esta columna contendrá valores duplicados, por lo que el índice no se puede declarar único):
CREATE TABLE dbo.Test
(
data integer NOT NULL,
);
GO
CREATE CLUSTERED INDEX cx
ON dbo.Test (data);
Para elegir algunos números del aire, elegiremos cargar diez millones de filas en total, con una distribución uniforme sobre un mil valores distintos . Una técnica común para generar datos como este es unir algunas tablas del sistema y aplicar el ROW_NUMBER función. También usaremos el operador módulo para limitar los números generados a los distintos valores deseados:
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
(ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000) + 1
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED); El plan de ejecución estimado para esa consulta es el siguiente (haga clic en la imagen para ampliarla si es necesario):

Esto toma alrededor de 30 segundos para crear los datos de muestra en mi computadora portátil. Eso no es mucho tiempo de ninguna manera, pero aún así es interesante considerar qué podríamos hacer para que este proceso sea más eficiente...
Análisis del plan
Comenzaremos por comprender para qué sirve cada operación del plan.
La sección del plan de ejecución a la derecha del operador Segmento se ocupa de la fabricación de filas mediante tablas del sistema de unión cruzada:

El operador Segmento está ahí en caso de que la función de ventana tuviera una PARTITION BY cláusula. Ese no es el caso aquí, pero de todos modos aparece en el plan de consulta. El operador Sequence Project genera los números de fila y Top limita la salida del plan a diez millones de filas:

Compute Scalar define la expresión que aplica la función de módulo y suma uno al resultado:

Podemos ver cómo se relacionan las etiquetas de las expresiones Sequence Project y Compute Scalar usando la pestaña Expresiones del Plan Explorer:

Esto nos da una idea más completa del flujo de este plan:el Proyecto de Secuencia numera las filas y etiqueta la expresión Expr1050; Compute Scalar etiqueta el resultado del cálculo de módulo y más uno como Expr1052 . Observe también la conversión implícita en la expresión Calcular escalar. La columna de la tabla de destino es de tipo entero, mientras que el ROW_NUMBER La función produce un bigint, por lo que es necesaria una conversión de restricción.
El siguiente operador en el plan es Sort. Según las estimaciones de costos del optimizador de consultas, se espera que esta sea la operación más costosa (88,1 % estimado ):

Puede que no sea inmediatamente obvio por qué este plan presenta la clasificación, ya que no hay un requisito de orden explícito en la consulta. Ordenar se agrega al plan para garantizar que las filas lleguen al operador Insertar índice agrupado en el orden del índice agrupado. Esto promueve escrituras secuenciales, evita la división de páginas y es uno de los requisitos previos para INSERT mínimamente registrado operaciones.
Todas estas son cosas potencialmente buenas, pero el Sort en sí es bastante caro. De hecho, verificar el plan de ejecución posterior a la ejecución ("real") revela que Sort también se quedó sin memoria en el momento de la ejecución y tuvo que pasar a tempdb físico. disco:

El derrame de clasificación ocurre a pesar de que el número estimado de filas es exactamente correcto, y a pesar de que a la consulta se le otorgó toda la memoria que solicitó (como se ve en las propiedades del plan para la raíz INSERT nodo):

Los derrames de clasificación también se indican por la presencia de IO_COMPLETION esperas en la pestaña de estadísticas de espera de Plan Explorer PRO:

Finalmente, para esta sección de análisis del plan, observe la DML Request Sort La propiedad del operador Insertar índice agrupado se establece como verdadera:

Esta bandera indica que el optimizador requiere que el subárbol debajo de Insertar proporcione filas en el orden de clasificación de la clave de índice (de ahí la necesidad del operador de clasificación problemático).
Evitar la ordenación
Ahora que sabemos por qué Aparece el Sort, podemos probar a ver que pasa si lo quitamos. Hay formas en que podríamos reescribir la consulta para "engañar" al optimizador haciéndole creer que se insertarían menos filas (por lo que no valdría la pena ordenar), pero una forma rápida de evitar la ordenación directamente (solo con fines experimentales) es usar un indicador de seguimiento no documentado 8795. Esto establece el DML Request Sort propiedad a false, por lo que ya no es necesario que las filas lleguen a la inserción de índice agrupado en orden de clave agrupada:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT TOP (10000000)
ROW_NUMBER() OVER (ORDER BY (SELECT 0)) % 1000
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
OPTION (QUERYTRACEON 8795); El nuevo plan de consulta posterior a la ejecución es el siguiente (haga clic en la imagen para ampliar):

El operador Ordenar desapareció, pero la nueva consulta se ejecuta durante más de 50 segundos (en comparación con 30 segundos antes de). Hay un par de razones para esto. Primero, perdemos cualquier posibilidad de inserciones mínimamente registradas porque requieren datos ordenados (DML Request Sort =true). En segundo lugar, se producirá una gran cantidad de divisiones de página "incorrectas" durante la inserción. En caso de que parezca contrario a la intuición, recuerda que aunque el ROW_NUMBER la función numera filas secuencialmente, el efecto del operador módulo es presentar una secuencia repetitiva de números 1…1000 a la inserción de índice agrupado.
El mismo problema fundamental ocurre si usamos trucos de T-SQL para reducir el recuento de filas esperado para evitar la ordenación en lugar de usar el indicador de seguimiento no admitido.
Evitar el Tipo II
Mirando el plan como un todo, parece claro que nos gustaría generar filas de una manera que evite una ordenación explícita, pero que aún obtenga los beneficios de un registro mínimo y la evitación de divisiones de páginas incorrectas. En pocas palabras:queremos un plan que presente filas en orden de clave agrupada, pero sin clasificar.
Armados con esta nueva percepción, podemos expresar nuestra consulta de una manera diferente. La siguiente consulta genera cada número del 1 al 1000 y cruza las uniones que se establecen con 10 000 filas para producir el grado requerido de duplicación. La idea es generar un conjunto de inserción que presente 10 000 filas numeradas como '1', luego 10 000 numeradas como '2'... y así sucesivamente.
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C; Desafortunadamente, el optimizador todavía produce un plan con un tipo:

No hay mucho que decir en defensa del optimizador aquí, esto es solo un plan tonto. Ha optado por generar 10.000 filas y luego unirlas con números del 1 al 1000. Esto no permite conservar el orden natural de los números, por lo que no se puede evitar la ordenación.
Evitar el Sort – ¡Finalmente!
La estrategia que el optimizador omitió es tomar los números 1…1000 primero , y cruce cada número con 10,000 filas (haciendo 10,000 copias de cada número en secuencia). El plan esperado evitaría una ordenación mediante el uso de una combinación cruzada de bucles anidados que preserva el orden de las filas en la entrada exterior.
Podemos lograr este resultado forzando al optimizador a acceder a las tablas derivadas en el orden especificado en la consulta, usando FORCE ORDER sugerencia de consulta:
TRUNCATE TABLE dbo.Test;
GO
INSERT dbo.Test WITH (TABLOCK)
(data)
SELECT
N.number
FROM
(
SELECT SV.number
FROM master.dbo.spt_values AS SV WITH (READUNCOMMITTED)
WHERE SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 1000
) AS N
CROSS JOIN
(
SELECT TOP (10000)
Dummy = NULL
FROM master.sys.columns AS C1 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns AS C2 WITH (READUNCOMMITTED)
CROSS JOIN master.sys.columns C3 WITH (READUNCOMMITTED)
) AS C
OPTION (FORCE ORDER); Finalmente, obtenemos el plan que buscábamos:
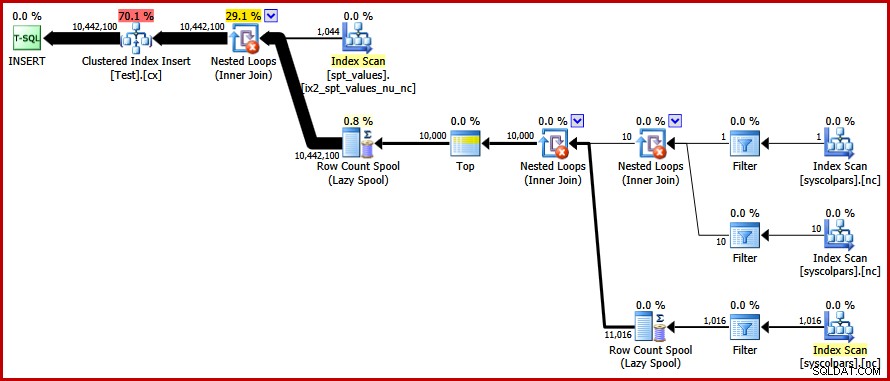
Este plan evita una ordenación explícita al mismo tiempo que evita divisiones de página "incorrectas" y permite inserciones mínimamente registradas en el índice agrupado (suponiendo que la base de datos no esté usando el FULL modelo de recuperación). Carga los diez millones de filas en aproximadamente 9 segundos en mi computadora portátil (con un solo disco giratorio SATA de 7200 rpm). Esto representa una notable ganancia de eficiencia en los 30-50 segundos tiempo transcurrido visto antes de la reescritura.
Encontrar los valores distintos
Ahora que hemos creado los datos de muestra, podemos centrar nuestra atención en escribir una consulta para encontrar los distintos valores en la tabla. Una forma natural de expresar este requisito en T-SQL es la siguiente:
SELECT DISTINCT data FROM dbo.Test WITH (TABLOCK) OPTION (MAXDOP 1);
El plan de ejecución es muy simple, como era de esperar:

Esto toma alrededor de 2900 ms para ejecutarse en mi máquina y requiere 43,406 lecturas lógicas:

Eliminando el MAXDOP (1) sugerencia de consulta genera un plan paralelo:

Esto se completa en alrededor de 1500 ms (pero con 8764 ms de tiempo de CPU consumido) y 43 804 lecturas lógicas:

Los mismos planes y resultados de rendimiento si usamos GROUP BY en lugar de DISTINCT .
Un algoritmo mejor
Los planes de consulta que se muestran arriba leen todos los valores de la tabla base y los procesan a través de Stream Aggregate. Pensando en la tarea como un todo, parece ineficiente escanear los 10 millones de filas cuando sabemos que hay relativamente pocos valores distintos.
Una mejor estrategia podría ser encontrar el valor único más bajo en la tabla, luego encontrar el siguiente más alto, y así sucesivamente hasta que nos quedemos sin valores. Fundamentalmente, este enfoque se presta a la búsqueda de singleton en el índice en lugar de escanear cada fila.
Podemos implementar esta idea en una sola consulta usando un CTE recursivo, donde la parte ancla encuentra el más bajo valor distinto, entonces la parte recursiva encuentra el siguiente valor distinto y así sucesivamente. Un primer intento de escribir esta consulta es:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT data = MIN(T.data)
FROM dbo.Test AS T
UNION ALL
-- Recursive
SELECT MIN(T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
)
SELECT data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Desafortunadamente, esa sintaxis no se compila:

Ok, entonces las funciones agregadas no están permitidas. En lugar de usar MIN , podemos escribir la misma lógica usando TOP (1) con un ORDER BY :
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
T.data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT TOP (1)
T.data
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
ORDER BY T.data
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0);

Todavía no hay alegría.
Resulta que podemos eludir estas restricciones reescribiendo la parte recursiva para numerar las filas candidatas en el orden requerido, luego filtrar la fila que está numerada como 'uno'. Esto puede parecer un poco tortuoso, pero la lógica es exactamente la misma:
WITH RecursiveCTE
AS
(
-- Anchor
SELECT TOP (1)
data
FROM dbo.Test AS T
ORDER BY
T.data
UNION ALL
-- Recursive
SELECT R.data
FROM
(
-- Number the rows
SELECT
T.data,
rn = ROW_NUMBER() OVER (
ORDER BY T.data)
FROM dbo.Test AS T
JOIN RecursiveCTE AS R
ON R.data < T.data
) AS R
WHERE
-- Only the row that sorts lowest
R.rn = 1
)
SELECT
data
FROM RecursiveCTE
OPTION (MAXRECURSION 0); Esta consulta sí compile y produzca el siguiente plan posterior a la ejecución:

Observe el operador Top en la parte recursiva del plan de ejecución (resaltado). No podemos escribir un T-SQL TOP en la parte recursiva de una expresión de tabla común recursiva, ¡pero eso no significa que el optimizador no pueda usar una! El optimizador introduce la parte superior basándose en el razonamiento sobre el número de filas que necesitará comprobar para encontrar el número '1'.
El rendimiento de este plan (no paralelo) es mucho mejor que el enfoque de Stream Aggregate. Se completa en alrededor de 50 ms , con 3007 lecturas lógicas contra la tabla de origen (y 6001 filas leídas de la mesa de trabajo de la cola), en comparación con el mejor anterior de 1500 ms (8764 ms de tiempo de CPU en DOP 8) y 43 804 lecturas lógicas:


Conclusión
No siempre es posible lograr avances en el rendimiento de las consultas al considerar los elementos del plan de consultas individuales por sí solos. A veces, necesitamos analizar la estrategia detrás de todo el plan de ejecución y luego pensar lateralmente para encontrar un algoritmo y una implementación más eficientes.