Hace más de tres años, publiqué una serie de tres partes sobre cómo dividir hilos:
- Dividir cadenas de la manera correcta, o de la siguiente mejor manera
- Dividiendo hilos:un seguimiento
- Dividir cadenas:ahora con menos T-SQL
Luego, en enero, asumí un problema un poco más elaborado:
- Comparación de métodos de división/concatenación de cadenas
En todo momento, mi conclusión ha sido:DEJA DE HACER ESTO EN T-SQL . Use CLR o, mejor aún, pase parámetros estructurados como DataTables desde su aplicación a parámetros con valores de tabla (TVP) en sus procedimientos, evitando toda la construcción y deconstrucción de cadenas por completo, que es realmente la parte de la solución que causa problemas de rendimiento.
Y luego apareció SQL Server 2016...
Cuando se lanzó RC0, se documentó una nueva función sin mucha fanfarria:STRING_SPLIT . Un ejemplo rápido:
SELECT * FROM STRING_SPLIT('a,b,cd', ',');
/* result:
value
--------
a
b
cd
*/ Atrajo la atención de algunos colegas, incluido Dave Ballantyne, quien escribió sobre las características principales, pero tuvo la amabilidad de ofrecerme el derecho de preferencia en una comparación de rendimiento.
Este es principalmente un ejercicio académico, porque con un gran conjunto de limitaciones en la primera iteración de la función, probablemente no sea factible para una gran cantidad de casos de uso. Aquí está la lista de las observaciones que Dave y yo hicimos, algunas de las cuales pueden ser motivo de ruptura en ciertos escenarios:
- la función requiere que la base de datos esté en el nivel de compatibilidad 130;
- solo acepta delimitadores de un solo carácter;
- no hay forma de agregar columnas de salida (como una columna que indica la posición ordinal dentro de la cadena);
- relacionado, no hay forma de controlar la ordenación:las únicas opciones son arbitrarias y alfabéticas
ORDER BY value;
- relacionado, no hay forma de controlar la ordenación:las únicas opciones son arbitrarias y alfabéticas
- hasta ahora, siempre estima 50 filas de salida;
- al usarlo para DML, en muchos casos obtendrá un carrete de mesa (para la protección de Halloween);
NULLla entrada conduce a un resultado vacío;- no hay forma de reducir predicados, como eliminar duplicados o cadenas vacías debido a delimitadores consecutivos;
- no hay forma de realizar operaciones contra los valores de salida hasta después del hecho (por ejemplo, muchas funciones de división realizan
LTRIM/RTRIMo conversiones explícitas para usted:STRING_SPLITescupe todo lo feo, como los espacios iniciales).
Entonces, con esas limitaciones a la vista, podemos pasar a algunas pruebas de rendimiento. Dada la trayectoria de Microsoft con funciones integradas que aprovechan CLR bajo las sábanas (tos FORMAT() tos ), era escéptico acerca de si esta nueva función podría acercarse a los métodos más rápidos que había probado hasta la fecha.
Usemos divisores de cadenas para separar cadenas de números separados por comas, de esta manera nuestro nuevo amigo JSON también puede venir y jugar. Y diremos que ninguna lista puede superar los 8000 caracteres, por lo que no hay MAX se requieren tipos, y dado que son números, no tenemos que lidiar con nada exótico como Unicode.
Primero, creemos nuestras funciones, varias de las cuales adapté del primer artículo anterior. Dejé fuera un par que no sentí que pudieran competir; Lo dejaré como ejercicio para que el lector los pruebe.
Tabla de números
Esta nuevamente necesita algo de configuración, pero puede ser una mesa bastante pequeña debido a las limitaciones artificiales que estamos poniendo:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 8000;
;WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number); Entonces la función:
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
SELECT [Value] = SUBSTRING(@List, [Number],
CHARINDEX(@Delimiter, @List + @Delimiter, [Number]) - [Number])
FROM dbo.Numbers WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter
); JSON
Basado en un enfoque revelado por primera vez por el equipo del motor de almacenamiento, creé un contenedor similar alrededor de OPENJSON , solo tenga en cuenta que el delimitador tiene que ser una coma en este caso, o tiene que hacer una sustitución de cadena de trabajo pesado antes de pasar el valor a la función nativa:
CREATE FUNCTION dbo.SplitStrings_JSON
(
@List varchar(8000),
@Delimiter char(1) -- ignored but made automated testing easier
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); El CHAR(91)/CHAR(93) solo está reemplazando [ y ] respectivamente debido a problemas de formato.
XML
CREATE FUNCTION dbo.SplitStrings_XML
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT [value] = y.i.value('(./text())[1]', 'varchar(8000)')
FROM (SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)); CLR
Una vez más tomé prestado el confiable código de división de Adam Machanic de hace casi siete años, aunque es compatible con Unicode, MAX tipos y delimitadores de varios caracteres (y, de hecho, como no quiero meterme con el código de la función, esto limita nuestras cadenas de entrada a 4000 caracteres en lugar de 8000):
CREATE FUNCTION dbo.SplitStrings_CLR ( @List nvarchar(MAX), @Delimiter nvarchar(255) ) RETURNS TABLE ( value nvarchar(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi;
STRING_SPLIT
Solo por consistencia, puse un envoltorio alrededor de STRING_SPLIT :
CREATE FUNCTION dbo.SplitStrings_Native
(
@List varchar(8000),
@Delimiter char(1)
)
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN (SELECT value FROM STRING_SPLIT(@List, @Delimiter));
Datos de origen y verificación de integridad
Creé esta tabla para que sirviera como fuente de cadenas de entrada para las funciones:
CREATE TABLE dbo.SourceTable
(
RowNum int IDENTITY(1,1) PRIMARY KEY,
StringValue varchar(8000)
);
;WITH x AS
(
SELECT TOP (60000) x = STUFF((SELECT TOP (ABS(o.[object_id] % 20))
',' + CONVERT(varchar(12), c.[object_id]) FROM sys.all_columns AS c
WHERE c.[object_id] < o.[object_id] ORDER BY NEWID() FOR XML PATH(''),
TYPE).value(N'(./text())[1]', N'varchar(8000)'),1,1,'')
FROM sys.all_objects AS o CROSS JOIN sys.all_objects AS o2
ORDER BY NEWID()
)
INSERT dbo.SourceTable(StringValue)
SELECT TOP (50000) x
FROM x WHERE x IS NOT NULL
ORDER BY NEWID(); Solo como referencia, validemos que 50,000 filas llegaron a la tabla y verifiquemos la longitud promedio de la cadena y el número promedio de elementos por cadena:
SELECT
[Values] = COUNT(*),
AvgStringLength = AVG(1.0*LEN(StringValue)),
AvgElementCount = AVG(1.0*LEN(StringValue)-LEN(REPLACE(StringValue, ',','')))
FROM dbo.SourceTable;
/* result:
Values AvgStringLength AbgElementCount
------ --------------- ---------------
50000 108.476380 8.911840
*/
Y finalmente, asegurémonos de que cada función devuelva los datos correctos para cualquier RowNum dado. , así que elegiremos uno al azar y compararemos los valores obtenidos a través de cada método. Por supuesto, sus resultados variarán.
SELECT f.value FROM dbo.SourceTable AS s CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue, ',') AS f WHERE s.RowNum = 37219 ORDER BY f.value;
Efectivamente, todas las funciones funcionan como se esperaba (la ordenación no es numérica; recuerde, las funciones generan cadenas):
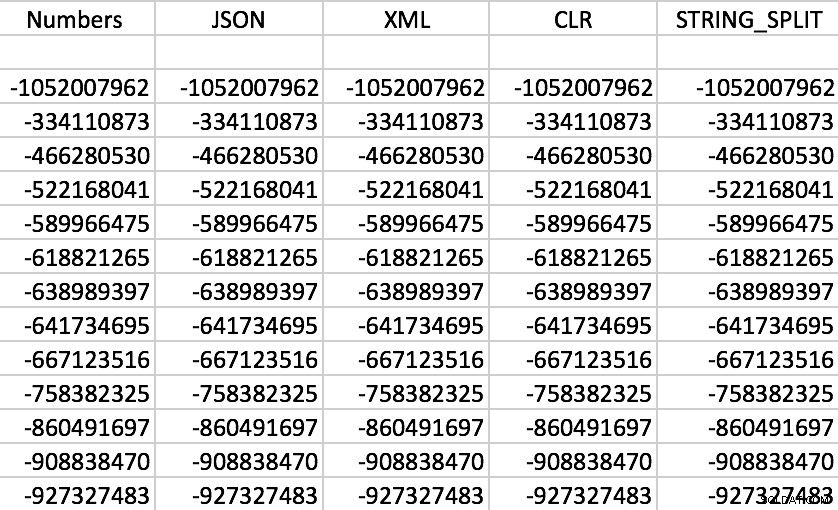 Conjunto de salida de muestra de cada una de las funciones
Conjunto de salida de muestra de cada una de las funciones
Pruebas de rendimiento
SELECT SYSDATETIME(); GO DECLARE @x VARCHAR(8000); SELECT @x = f.value FROM dbo.SourceTable AS s CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue,',') AS f; GO 100 SELECT SYSDATETIME();
Ejecuté el código anterior 10 veces para cada método y promedié los tiempos para cada uno. Y aquí es donde vino la sorpresa para mí. Dadas las limitaciones en el STRING_SPLIT nativo función, mi suposición era que se armó rápidamente, y que el rendimiento daría crédito a eso. Chico, el resultado fue diferente de lo que esperaba:
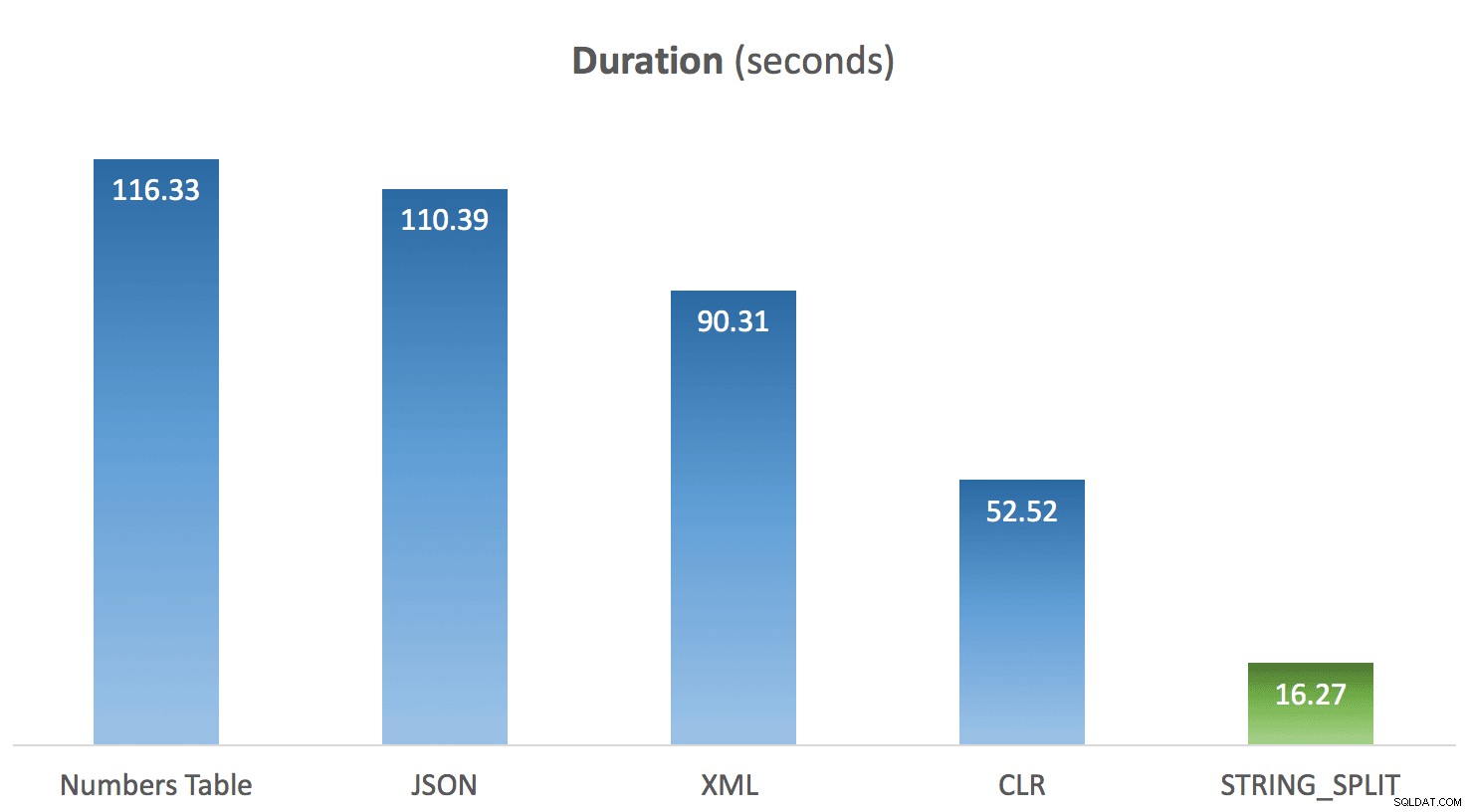 Duración promedio de STRING_SPLIT en comparación con otros métodos
Duración promedio de STRING_SPLIT en comparación con otros métodos
Actualización 2016-03-20
Según la siguiente pregunta de Lars, realicé las pruebas nuevamente con algunos cambios:
- Supervisé mi instancia con SQL Sentry Performance Advisor para capturar el perfil de la CPU durante la prueba;
- Capturé estadísticas de espera a nivel de sesión entre cada lote;
- Inserté un retraso entre lotes para que la actividad se distinguiera visualmente en el panel de Performance Advisor.
Creé una nueva tabla para capturar información de estadísticas de espera:
CREATE TABLE dbo.Timings ( dt datetime, test varchar(64), point varchar(64), session_id smallint, wait_type nvarchar(60), wait_time_ms bigint, );
Luego, el código de cada prueba cambió a esto:
WAITFOR DELAY '00:00:30'; DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = /* 'method' */, point = 'Start', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO DECLARE @x VARCHAR(8000); SELECT @x = f.value FROM dbo.SourceTable AS s CROSS APPLY dbo.SplitStrings_/* method */(s.StringValue, ',') AS f GO 100 DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, /* 'method' */, 'End', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID;
Ejecuté la prueba y luego ejecuté las siguientes consultas:
-- validate that timings were in same ballpark as previous tests
SELECT test, DATEDIFF(SECOND, MIN(dt), MAX(dt))
FROM dbo.Timings WITH (NOLOCK)
GROUP BY test ORDER BY 2 DESC;
-- determine window to apply to Performance Advisor dashboard
SELECT MIN(dt), MAX(dt) FROM dbo.Timings;
-- get wait stats registered for each session
SELECT test, wait_type, delta FROM
(
SELECT f.test, rn = RANK() OVER (PARTITION BY f.point ORDER BY f.dt),
f.wait_type, delta = f.wait_time_ms - COALESCE(s.wait_time_ms, 0)
FROM dbo.Timings AS f
LEFT OUTER JOIN dbo.Timings AS s
ON s.test = f.test
AND s.wait_type = f.wait_type
AND s.point = 'Start'
WHERE f.point = 'End'
) AS x
WHERE delta > 0
ORDER BY rn, delta DESC; Desde la primera consulta, los tiempos se mantuvieron consistentes con las pruebas anteriores (los graficaría nuevamente pero eso no revelaría nada nuevo).
A partir de la segunda consulta, pude resaltar este rango en el panel de Performance Advisor, y desde allí fue fácil identificar cada lote:
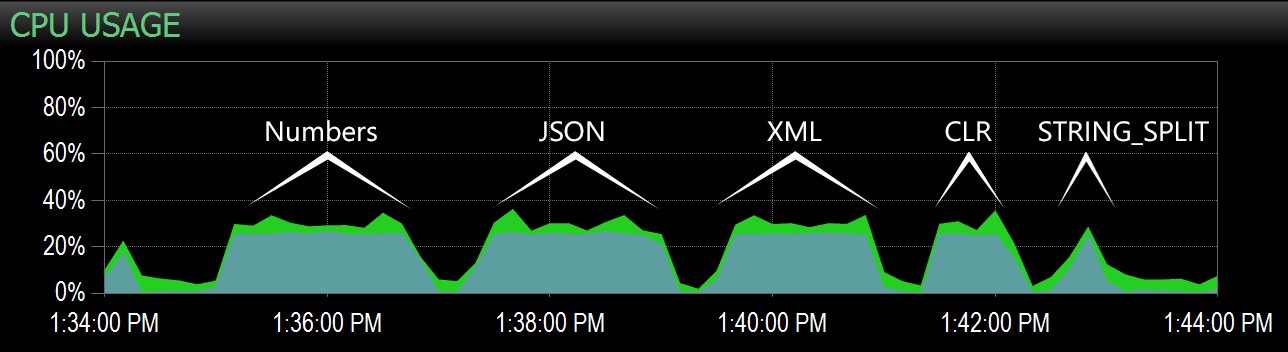 Lotes capturados en el gráfico de CPU en el panel de Performance Advisor
Lotes capturados en el gráfico de CPU en el panel de Performance Advisor
Claramente, todos los métodos *excepto* STRING_SPLIT fijó un solo núcleo durante la duración de la prueba (esta es una máquina de cuatro núcleos, y la CPU estaba constantemente en 25%). Es probable que Lars estuviera insinuando debajo de eso STRING_SPLIT es más rápido a costa de machacar la CPU, pero no parece que sea así.
Finalmente, a partir de la tercera consulta, pude ver las siguientes estadísticas de espera acumuladas después de cada lote:
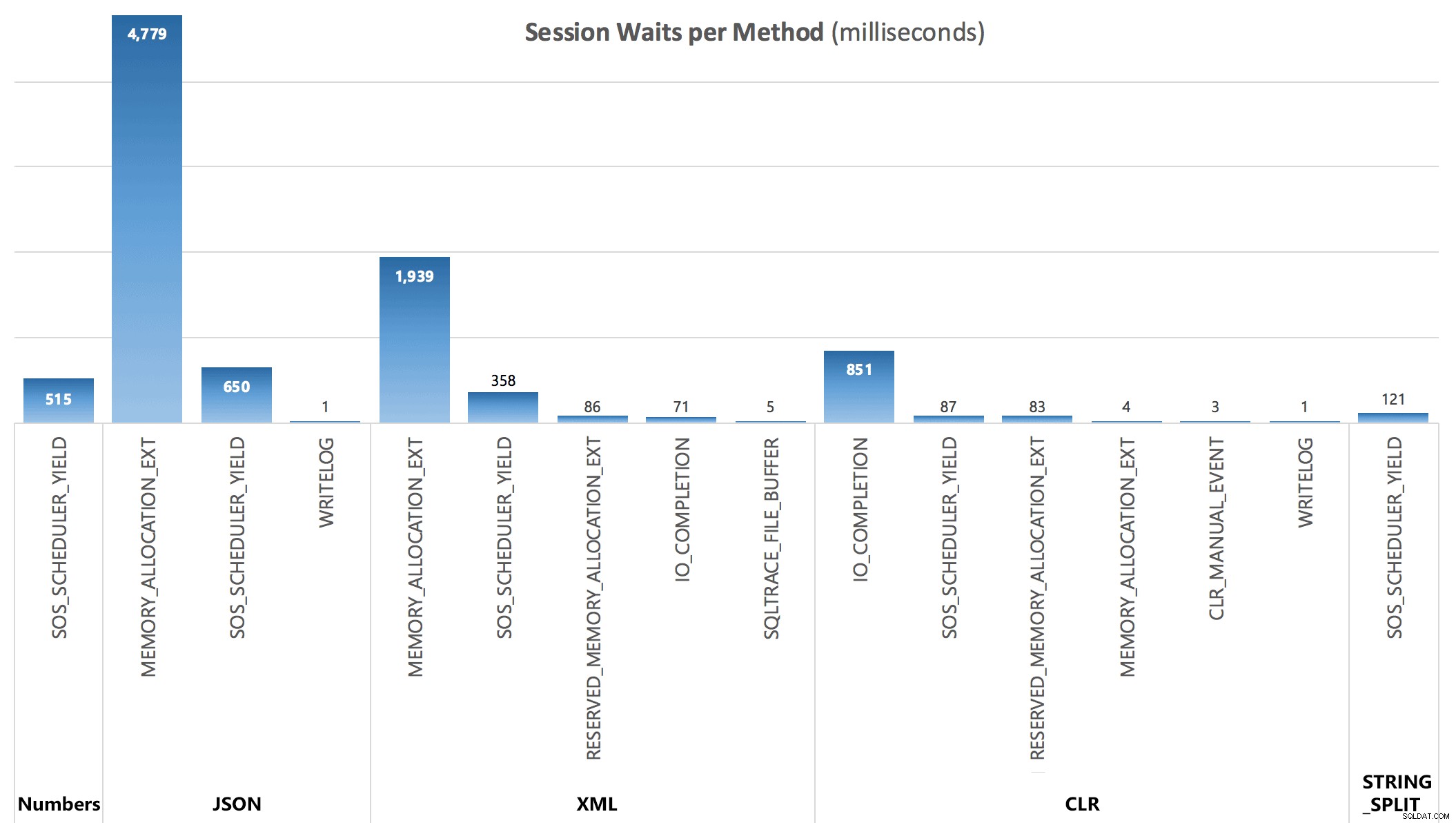 Esperas por sesión, en milisegundos
Esperas por sesión, en milisegundos
Las esperas capturadas por el DMV no explican completamente la duración de las consultas, pero sirven para mostrar dónde adicional se incurre en esperas.
Conclusión
Si bien CLR personalizado todavía muestra una gran ventaja sobre los enfoques T-SQL tradicionales, y el uso de JSON para esta funcionalidad parece ser nada más que una novedad, STRING_SPLIT fue el claro ganador, por una milla. Entonces, si solo necesita dividir una cadena y puede lidiar con todas sus limitaciones, parece que esta es una opción mucho más viable de lo que esperaba. Con suerte, en versiones futuras veremos funciones adicionales, como una columna de salida que indica la posición ordinal de cada elemento, la capacidad de filtrar duplicados y cadenas vacías, y delimitadores de varios caracteres.
Abordo varios comentarios a continuación en dos publicaciones de seguimiento:
- STRING_SPLIT() en SQL Server 2016:seguimiento n.º 1
- STRING_SPLIT() en SQL Server 2016:seguimiento n.º 2