Los grupos de disponibilidad, introducidos en SQL Server 2012, representan un cambio fundamental en la forma en que pensamos acerca de la alta disponibilidad y la recuperación ante desastres para nuestras bases de datos. Una de las mejores cosas que se hacen posibles aquí es descargar las operaciones de solo lectura a una réplica secundaria, de modo que la instancia principal de lectura/escritura no se vea afectada por cosas molestas como los informes del usuario final. Configurar esto no es simple, pero es mucho más fácil y fácil de mantener que las soluciones anteriores (que levante la mano si le gustó configurar la duplicación y las instantáneas, y todo el mantenimiento perpetuo que implica).
La gente se emociona mucho cuando oye hablar de los grupos de disponibilidad. Luego, la realidad golpea:la característica requiere la edición Enterprise de SQL Server (a partir de SQL Server 2014, de todos modos). Enterprise Edition es costosa, especialmente si tiene muchos núcleos, y especialmente desde la eliminación de las licencias basadas en CAL (a menos que tenga derechos adquiridos a partir de 2008 R2, en cuyo caso está limitado a los primeros 20 núcleos). También requiere Windows Server Failover Clustering (WSFC), una complicación no solo para demostrar la tecnología en una computadora portátil, sino que también requiere la edición Enterprise de Windows, un controlador de dominio y una gran cantidad de configuraciones para admitir la agrupación. Y también hay nuevos requisitos en torno a Software Assurance; un costo adicional si desea que sus instancias en espera sean compatibles.
Algunos clientes no pueden justificar el precio. Otros ven el valor, pero simplemente no pueden pagarlo. Entonces, ¿qué deben hacer estos usuarios?
Tu nuevo héroe:envío de registros
El envío de registros ha existido durante años. Es simple y simplemente funciona. Casi siempre. Además de evitar los costos de licencia y los obstáculos de configuración que presentan los grupos de disponibilidad, también puede evitar la penalización de 14 bytes de la que habló Paul Randal (@PaulRandal) en el boletín SQLskills Insider de esta semana (13 de octubre de 2014).
Sin embargo, uno de los desafíos que tienen las personas al usar la copia enviada del registro como una copia secundaria legible es que debe expulsar a todos los usuarios actuales para aplicar cualquier registro nuevo, por lo que los usuarios se enojan porque son interrumpidos repetidamente. de ejecutar consultas, o tiene usuarios molestos porque sus datos están obsoletos. Esto se debe a que las personas se limitan a una única secundaria legible.
No tiene que ser así; Creo que hay una solución elegante aquí, y si bien puede requerir mucho más trabajo inicial que, por ejemplo, activar los grupos de disponibilidad, seguramente será una opción atractiva para algunos.
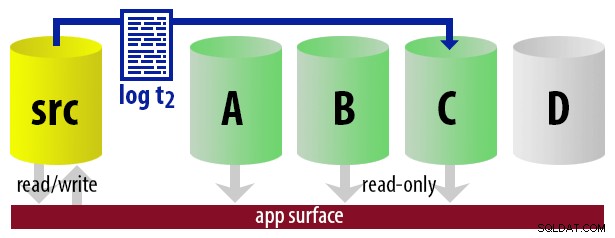
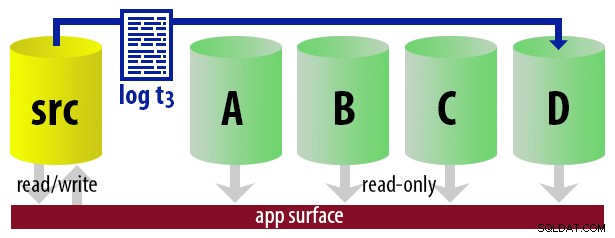
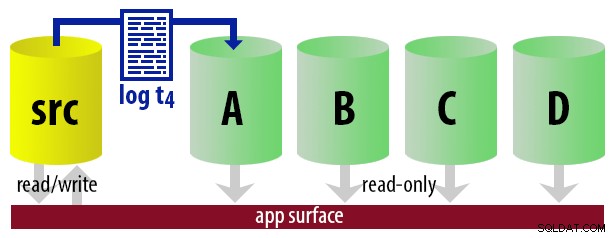
Básicamente, podemos configurar varios secundarios, donde iniciaremos sesión y convertiremos solo uno de ellos en el secundario "activo", utilizando un enfoque de turno rotativo. El trabajo que envía los registros sabe cuál está actualmente activo, por lo que solo restaura nuevos registros al "siguiente" servidor usando WITH STANDBY opción. La aplicación de generación de informes utiliza la misma información para determinar en tiempo de ejecución cuál debe ser la cadena de conexión para el próximo informe que ejecute el usuario. Cuando la próxima copia de seguridad del registro esté lista, todo cambiará en uno y la instancia que ahora se convertirá en la nueva secundaria legible se restaurará usando WITH STANDBY .
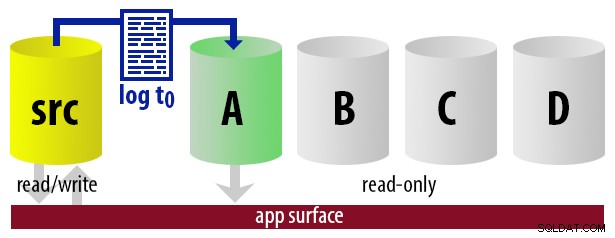
Para mantener el modelo sin complicaciones, digamos que tenemos cuatro instancias que funcionan como secundarias legibles y hacemos copias de seguridad de registros cada 15 minutos. En cualquier momento, tendremos un secundario activo en modo de espera, con datos que no tengan más de 15 minutos de antigüedad, y tres secundarios en modo de espera que no atienden nuevas consultas (pero que aún pueden arrojar resultados para consultas más antiguas).
Esto funcionará mejor si no se espera que las consultas duren más de 45 minutos. (Es posible que deba ajustar estos ciclos según la naturaleza de sus operaciones de solo lectura, cuántos usuarios simultáneos ejecutan consultas más largas y si es posible interrumpir a los usuarios expulsando a todos).
También funcionará mejor si las consultas consecutivas ejecutadas por el mismo usuario pueden cambiar su cadena de conexión (esta es la lógica que deberá estar en la aplicación, aunque podría usar sinónimos o vistas según la arquitectura) y contienen diferentes datos que tienen cambiado mientras tanto (como si estuvieran consultando la base de datos en vivo y en constante cambio).
Con todas estas suposiciones en mente, aquí hay una secuencia ilustrativa de eventos para los primeros 75 minutos de nuestra implementación:
| tiempo | eventos | visual |
|---|---|---|
| 12:00 (t0) |
|  |
| 12:15 (t1) |
| 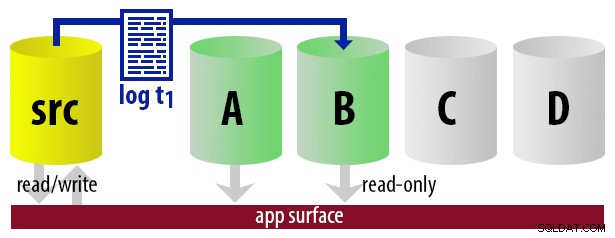 |
| 12:30 (t2) |
|  |
| 12:45 (t3) |
|  |
| 13:00 (t4) |
|  |
Eso puede parecer bastante simple; escribir el código para manejar todo eso es un poco más desalentador. Un bosquejo aproximado:
- En el servidor principal (lo llamaré
BOSS), crear una base de datos. Antes incluso de pensar en ir más allá, active Trace Flag 3226 para evitar que los mensajes de respaldo exitosos ensucien el registro de errores de SQL Server. - En
BOSS, agregue un servidor vinculado para cada secundario (los llamaréPEON1->PEON4). - En algún lugar accesible para todos los servidores, cree un recurso compartido de archivos para almacenar las copias de seguridad de la base de datos/registros y asegúrese de que las cuentas de servicio de cada instancia tengan acceso de lectura/escritura. Además, cada instancia secundaria debe tener una ubicación especificada para el archivo en espera.
- En una base de datos de utilidades separada (o MSDB, si lo prefiere), cree tablas que contengan información de configuración sobre la(s) base(s) de datos, todas las secundarias y registre el historial de copias de seguridad y restauración.
- Cree procedimientos almacenados que respaldarán la base de datos y restaurarán a los secundarios
WITH NORECOVERYy luego aplique un registroWITH STANDBYy marque una instancia como la instancia secundaria en espera actual. Estos procedimientos también se pueden usar para reinicializar toda la configuración del trasvase de registros en caso de que algo salga mal. - Cree un trabajo que se ejecutará cada 15 minutos para realizar las tareas descritas anteriormente:
- haga una copia de seguridad del registro
- determinar a qué secundaria aplicar las copias de seguridad de registros no aplicadas
- restaurar esos registros con la configuración adecuada
- Cree un procedimiento almacenado (¿y/o una vista?) que le indicará a la(s) aplicación(es) que llama(n) qué secundario deben usar para cualquier consulta nueva de solo lectura.
- Cree un procedimiento de limpieza para borrar el historial de copias de seguridad de los registros que se han aplicado a todos los archivos secundarios (y tal vez también para mover o purgar los propios archivos).
- Mejore la solución con notificaciones y manejo de errores sólidos.
Paso 1:crea una base de datos
Mi instancia principal es Standard Edition, llamada .\BOSS . En esa instancia, creo una base de datos simple con una tabla:
USE [master]; GO CREATE DATABASE UserData; GO ALTER DATABASE UserData SET RECOVERY FULL; GO USE UserData; GO CREATE TABLE dbo.LastUpdate(EventTime DATETIME2); INSERT dbo.LastUpdate(EventTime) SELECT SYSDATETIME();
Luego creo un trabajo del Agente SQL Server que simplemente actualiza esa marca de tiempo cada minuto:
UPDATE UserData.dbo.LastUpdate SET EventTime = SYSDATETIME();
Eso solo crea la base de datos inicial y simula la actividad, lo que nos permite validar cómo la tarea de envío de registros rota a través de cada uno de los secundarios legibles. Quiero afirmar explícitamente que el objetivo de este ejercicio no es hacer una prueba de estrés del envío de registros o demostrar cuánto volumen podemos atravesar; ese es un ejercicio completamente diferente.
Paso 2:agregar servidores vinculados
Tengo cuatro instancias secundarias de Express Edition llamadas .\PEON1 , .\PEON2 , .\PEON3 y .\PEON4 . Así que ejecuté este código cuatro veces, cambiando @s cada vez:
USE [master];
GO
DECLARE @s NVARCHAR(128) = N'.\PEON1', -- repeat for .\PEON2, .\PEON3, .\PEON4
@t NVARCHAR(128) = N'true';
EXEC [master].dbo.sp_addlinkedserver @server = @s, @srvproduct = N'SQL Server';
EXEC [master].dbo.sp_addlinkedsrvlogin @rmtsrvname = @s, @useself = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'collation compatible', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'data access', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'rpc', @optvalue = @t;
EXEC [master].dbo.sp_serveroption @server = @s, @optname = N'rpc out', @optvalue = @t; Paso 3:validar archivos compartidos
En mi caso, las 5 instancias están en el mismo servidor, así que creé una carpeta para cada instancia:C:\temp\Peon1\ , C:\temp\Peon2\ , y así. Recuerde que si sus servidores secundarios están en diferentes servidores, la ubicación debe ser relativa a ese servidor, pero aún así ser accesible desde el servidor principal (por lo que normalmente se usaría una ruta UNC). Debe validar que cada instancia pueda escribir en ese recurso compartido y también debe validar que cada instancia pueda escribir en la ubicación especificada para el archivo en espera (utilicé las mismas carpetas para el modo en espera). Puede validar esto haciendo una copia de seguridad de una pequeña base de datos de cada instancia en cada una de sus ubicaciones especificadas; no continúe hasta que esto funcione.
Paso 4:crear tablas
Decidí colocar estos datos en msdb , pero realmente no tengo ningún sentimiento fuerte a favor o en contra de crear una base de datos separada. La primera tabla que necesito es la que contiene información sobre la(s) base(s) de datos que voy a enviar de registro:
CREATE TABLE dbo.PMAG_Databases ( DatabaseName SYSNAME, LogBackupFrequency_Minutes SMALLINT NOT NULL DEFAULT (15), CONSTRAINT PK_DBS PRIMARY KEY(DatabaseName) ); GO INSERT dbo.PMAG_Databases(DatabaseName) SELECT N'UserData';
(Si tiene curiosidad sobre el esquema de nombres, PMAG significa "Grupos de disponibilidad de pobres")
Otra tabla necesaria es la que contiene información sobre los archivos secundarios, incluidas sus carpetas individuales y su estado actual en la secuencia de envío de registros.
CREATE TABLE dbo.PMAG_Secondaries
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
CommonFolder VARCHAR(512) NOT NULL,
DataFolder VARCHAR(512) NOT NULL,
LogFolder VARCHAR(512) NOT NULL,
StandByLocation VARCHAR(512) NOT NULL,
IsCurrentStandby BIT NOT NULL DEFAULT 0,
CONSTRAINT PK_Sec PRIMARY KEY(DatabaseName, ServerInstance),
CONSTRAINT FK_Sec_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName)
);
Si desea realizar una copia de seguridad desde el servidor de origen localmente y hacer que los secundarios se restauren de forma remota, o viceversa, puede dividir CommonFolder en dos columnas (BackupFolder y RestoreFolder ), y realice cambios relevantes en el código (no habrá tantos).
Dado que puedo completar esta tabla basándome al menos parcialmente en la información de sys.servers – aprovechando el hecho de que los datos/registro y otras carpetas llevan el nombre de los nombres de las instancias:
INSERT dbo.PMAG_Secondaries
(
DatabaseName,
ServerInstance,
CommonFolder,
DataFolder,
LogFolder,
StandByLocation
)
SELECT
DatabaseName = N'UserData',
ServerInstance = name,
CommonFolder = 'C:\temp\Peon' + RIGHT(name, 1) + '\',
DataFolder = 'C:\Program Files\Microsoft SQL Server\MSSQL12.PEON'
+ RIGHT(name, 1) + '\MSSQL\DATA\',
LogFolder = 'C:\Program Files\Microsoft SQL Server\MSSQL12.PEON'
+ RIGHT(name, 1) + '\MSSQL\DATA\',
StandByLocation = 'C:\temp\Peon' + RIGHT(name, 1) + '\'
FROM sys.servers
WHERE name LIKE N'.\PEON[1-4]';
También necesito una tabla para realizar un seguimiento de las copias de seguridad de registros individuales (no solo la última), porque en muchos casos tendré que restaurar varios archivos de registro en una secuencia. Puedo obtener esta información de msdb.dbo.backupset , pero es mucho más complicado obtener cosas como la ubicación, y es posible que no tenga control sobre otros trabajos que pueden limpiar el historial de copias de seguridad.
CREATE TABLE dbo.PMAG_LogBackupHistory
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
BackupSetID INT NOT NULL,
Location VARCHAR(2000) NOT NULL,
BackupTime DATETIME NOT NULL DEFAULT SYSDATETIME(),
CONSTRAINT PK_LBH PRIMARY KEY(DatabaseName, ServerInstance, BackupSetID),
CONSTRAINT FK_LBH_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName),
CONSTRAINT FK_LBH_Sec FOREIGN KEY(DatabaseName, ServerInstance)
REFERENCES dbo.PMAG_Secondaries(DatabaseName, ServerInstance)
); Puede pensar que es un desperdicio almacenar una fila para cada secundario y almacenar la ubicación de cada copia de seguridad, pero esto es a prueba de futuro:para manejar el caso en el que mueve CommonFolder para cualquier secundario.
Y finalmente, un historial de restauraciones de registros para que, en cualquier momento, pueda ver qué registros se han restaurado y dónde, y el trabajo de restauración puede estar seguro de restaurar solo los registros que aún no se han restaurado:
CREATE TABLE dbo.PMAG_LogRestoreHistory
(
DatabaseName SYSNAME,
ServerInstance SYSNAME,
BackupSetID INT,
RestoreTime DATETIME,
CONSTRAINT PK_LRH PRIMARY KEY(DatabaseName, ServerInstance, BackupSetID),
CONSTRAINT FK_LRH_DBs FOREIGN KEY(DatabaseName)
REFERENCES dbo.PMAG_Databases(DatabaseName),
CONSTRAINT FK_LRH_Sec FOREIGN KEY(DatabaseName, ServerInstance)
REFERENCES dbo.PMAG_Secondaries(DatabaseName, ServerInstance)
); Paso 5:inicializar los secundarios
Necesitamos un procedimiento almacenado que genere un archivo de respaldo (y lo refleje en las ubicaciones requeridas por diferentes instancias), y también restauraremos un registro en cada secundario para ponerlos a todos en espera. En este punto, todos estarán disponibles para consultas de solo lectura, pero solo uno estará en espera "actual" en cualquier momento. Este es el procedimiento almacenado que manejará las copias de seguridad completas y del registro de transacciones; cuando se solicita una copia de seguridad completa y @init se establece en 1, reinicializa automáticamente el trasvase de registros.
CREATE PROCEDURE [dbo].[PMAG_Backup]
@dbname SYSNAME,
@type CHAR(3) = 'bak', -- or 'trn'
@init BIT = 0 -- only used with 'bak'
AS
BEGIN
SET NOCOUNT ON;
-- generate a filename pattern
DECLARE @now DATETIME = SYSDATETIME();
DECLARE @fn NVARCHAR(256) = @dbname + N'_' + CONVERT(CHAR(8), @now, 112)
+ RIGHT(REPLICATE('0',6) + CONVERT(VARCHAR(32), DATEDIFF(SECOND,
CONVERT(DATE, @now), @now)), 6) + N'.' + @type;
-- generate a backup command with MIRROR TO for each distinct CommonFolder
DECLARE @sql NVARCHAR(MAX) = N'BACKUP'
+ CASE @type WHEN 'bak' THEN N' DATABASE ' ELSE N' LOG ' END
+ QUOTENAME(@dbname) + '
' + STUFF(
(SELECT DISTINCT CHAR(13) + CHAR(10) + N' MIRROR TO DISK = '''
+ s.CommonFolder + @fn + ''''
FROM dbo.PMAG_Secondaries AS s
WHERE s.DatabaseName = @dbname
FOR XML PATH(''), TYPE).value(N'.[1]',N'nvarchar(max)'),1,9,N'') + N'
WITH NAME = N''' + @dbname + CASE @type
WHEN 'bak' THEN N'_PMAGFull' ELSE N'_PMAGLog' END
+ ''', INIT, FORMAT' + CASE WHEN LEFT(CONVERT(NVARCHAR(128),
SERVERPROPERTY(N'Edition')), 3) IN (N'Dev', N'Ent')
THEN N', COMPRESSION;' ELSE N';' END;
EXEC [master].sys.sp_executesql @sql;
IF @type = 'bak' AND @init = 1 -- initialize log shipping
BEGIN
EXEC dbo.PMAG_InitializeSecondaries @dbname = @dbname, @fn = @fn;
END
IF @type = 'trn'
BEGIN
-- record the fact that we backed up a log
INSERT dbo.PMAG_LogBackupHistory
(
DatabaseName,
ServerInstance,
BackupSetID,
Location
)
SELECT
DatabaseName = @dbname,
ServerInstance = s.ServerInstance,
BackupSetID = MAX(b.backup_set_id),
Location = s.CommonFolder + @fn
FROM msdb.dbo.backupset AS b
CROSS JOIN dbo.PMAG_Secondaries AS s
WHERE b.name = @dbname + N'_PMAGLog'
AND s.DatabaseName = @dbname
GROUP BY s.ServerInstance, s.CommonFolder + @fn;
-- once we've backed up logs,
-- restore them on the next secondary
EXEC dbo.PMAG_RestoreLogs @dbname = @dbname;
END
END Esto, a su vez, llama a dos procedimientos que podría llamar por separado (pero lo más probable es que no). Primero, el procedimiento que inicializará los secundarios en la primera ejecución:
ALTER PROCEDURE dbo.PMAG_InitializeSecondaries
@dbname SYSNAME,
@fn VARCHAR(512)
AS
BEGIN
SET NOCOUNT ON;
-- clear out existing history/settings (since this may be a re-init)
DELETE dbo.PMAG_LogBackupHistory WHERE DatabaseName = @dbname;
DELETE dbo.PMAG_LogRestoreHistory WHERE DatabaseName = @dbname;
UPDATE dbo.PMAG_Secondaries SET IsCurrentStandby = 0
WHERE DatabaseName = @dbname;
DECLARE @sql NVARCHAR(MAX) = N'',
@files NVARCHAR(MAX) = N'';
-- need to know the logical file names - may be more than two
SET @sql = N'SELECT @files = (SELECT N'', MOVE N'''''' + name
+ '''''' TO N''''$'' + CASE [type] WHEN 0 THEN N''df''
WHEN 1 THEN N''lf'' END + ''$''''''
FROM ' + QUOTENAME(@dbname) + '.sys.database_files
WHERE [type] IN (0,1)
FOR XML PATH, TYPE).value(N''.[1]'',N''nvarchar(max)'');';
EXEC master.sys.sp_executesql @sql,
N'@files NVARCHAR(MAX) OUTPUT',
@files = @files OUTPUT;
SET @sql = N'';
-- restore - need physical paths of data/log files for WITH MOVE
-- this can fail, obviously, if those path+names already exist for another db
SELECT @sql += N'EXEC ' + QUOTENAME(ServerInstance)
+ N'.master.sys.sp_executesql N''RESTORE DATABASE ' + QUOTENAME(@dbname)
+ N' FROM DISK = N''''' + CommonFolder + @fn + N'''''' + N' WITH REPLACE,
NORECOVERY' + REPLACE(REPLACE(REPLACE(@files, N'$df$', DataFolder
+ @dbname + N'.mdf'), N'$lf$', LogFolder + @dbname + N'.ldf'), N'''', N'''''')
+ N';'';' + CHAR(13) + CHAR(10)
FROM dbo.PMAG_Secondaries
WHERE DatabaseName = @dbname;
EXEC [master].sys.sp_executesql @sql;
-- backup a log for this database
EXEC dbo.PMAG_Backup @dbname = @dbname, @type = 'trn';
-- restore logs
EXEC dbo.PMAG_RestoreLogs @dbname = @dbname, @PrepareAll = 1;
END Y luego el procedimiento que restaurará los registros:
CREATE PROCEDURE dbo.PMAG_RestoreLogs
@dbname SYSNAME,
@PrepareAll BIT = 0
AS
BEGIN
SET NOCOUNT ON;
DECLARE @StandbyInstance SYSNAME,
@CurrentInstance SYSNAME,
@BackupSetID INT,
@Location VARCHAR(512),
@StandByLocation VARCHAR(512),
@sql NVARCHAR(MAX),
@rn INT;
-- get the "next" standby instance
SELECT @StandbyInstance = MIN(ServerInstance)
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandby = 0
AND ServerInstance > (SELECT ServerInstance
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandBy = 1);
IF @StandbyInstance IS NULL -- either it was last or a re-init
BEGIN
SELECT @StandbyInstance = MIN(ServerInstance)
FROM dbo.PMAG_Secondaries;
END
-- get that instance up and into STANDBY
-- for each log in logbackuphistory not in logrestorehistory:
-- restore, and insert it into logrestorehistory
-- mark the last one as STANDBY
-- if @prepareAll is true, mark all others as NORECOVERY
-- in this case there should be only one, but just in case
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT bh.BackupSetID, s.ServerInstance, bh.Location, s.StandbyLocation,
rn = ROW_NUMBER() OVER (PARTITION BY s.ServerInstance ORDER BY bh.BackupSetID DESC)
FROM dbo.PMAG_LogBackupHistory AS bh
INNER JOIN dbo.PMAG_Secondaries AS s
ON bh.DatabaseName = s.DatabaseName
AND bh.ServerInstance = s.ServerInstance
WHERE s.DatabaseName = @dbname
AND s.ServerInstance = CASE @PrepareAll
WHEN 1 THEN s.ServerInstance ELSE @StandbyInstance END
AND NOT EXISTS
(
SELECT 1 FROM dbo.PMAG_LogRestoreHistory AS rh
WHERE DatabaseName = @dbname
AND ServerInstance = s.ServerInstance
AND BackupSetID = bh.BackupSetID
)
ORDER BY CASE s.ServerInstance
WHEN @StandbyInstance THEN 1 ELSE 2 END, bh.BackupSetID;
OPEN c;
FETCH c INTO @BackupSetID, @CurrentInstance, @Location, @StandbyLocation, @rn;
WHILE @@FETCH_STATUS -1
BEGIN
-- kick users out - set to single_user then back to multi
SET @sql = N'EXEC ' + QUOTENAME(@CurrentInstance) + N'.[master].sys.sp_executesql '
+ 'N''IF EXISTS (SELECT 1 FROM sys.databases WHERE name = N'''''
+ @dbname + ''''' AND [state] 1)
BEGIN
ALTER DATABASE ' + QUOTENAME(@dbname) + N' SET SINGLE_USER '
+ N'WITH ROLLBACK IMMEDIATE;
ALTER DATABASE ' + QUOTENAME(@dbname) + N' SET MULTI_USER;
END;'';';
EXEC [master].sys.sp_executesql @sql;
-- restore the log (in STANDBY if it's the last one):
SET @sql = N'EXEC ' + QUOTENAME(@CurrentInstance)
+ N'.[master].sys.sp_executesql ' + N'N''RESTORE LOG ' + QUOTENAME(@dbname)
+ N' FROM DISK = N''''' + @Location + N''''' WITH ' + CASE WHEN @rn = 1
AND (@CurrentInstance = @StandbyInstance OR @PrepareAll = 1) THEN
N'STANDBY = N''''' + @StandbyLocation + @dbname + N'.standby''''' ELSE
N'NORECOVERY' END + N';'';';
EXEC [master].sys.sp_executesql @sql;
-- record the fact that we've restored logs
INSERT dbo.PMAG_LogRestoreHistory
(DatabaseName, ServerInstance, BackupSetID, RestoreTime)
SELECT @dbname, @CurrentInstance, @BackupSetID, SYSDATETIME();
-- mark the new standby
IF @rn = 1 AND @CurrentInstance = @StandbyInstance -- this is the new STANDBY
BEGIN
UPDATE dbo.PMAG_Secondaries
SET IsCurrentStandby = CASE ServerInstance
WHEN @StandbyInstance THEN 1 ELSE 0 END
WHERE DatabaseName = @dbname;
END
FETCH c INTO @BackupSetID, @CurrentInstance, @Location, @StandbyLocation, @rn;
END
CLOSE c; DEALLOCATE c;
END (Sé que es mucho código y mucho SQL dinámico críptico. Traté de ser muy liberal con los comentarios; si hay alguna parte con la que tenga problemas, hágamelo saber).
Así que ahora, todo lo que tiene que hacer para poner en marcha el sistema es realizar dos llamadas de procedimiento:
EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'bak', @init = 1; EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'trn';
Ahora debería ver cada instancia con una copia en espera de la base de datos:
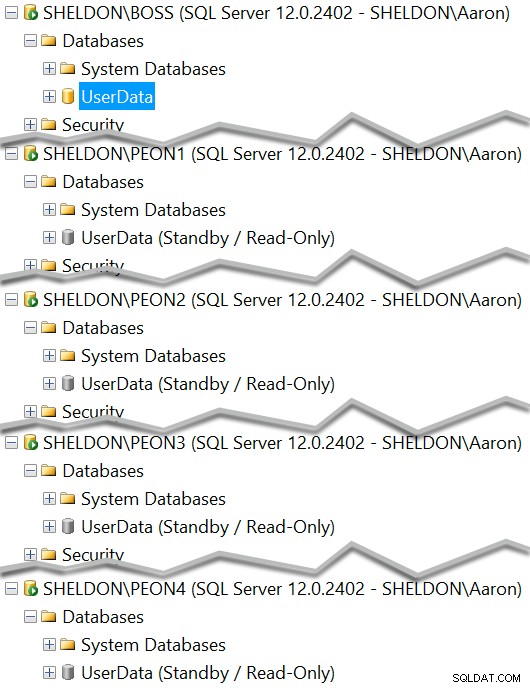
Y puede ver cuál debería servir actualmente como modo de espera de solo lectura:
SELECT ServerInstance, IsCurrentStandby FROM dbo.PMAG_Secondaries WHERE DatabaseName = N'UserData';
Paso 6:cree un trabajo que respalde o restaure registros
Puede poner este comando en un trabajo que programe cada 15 minutos:
EXEC dbo.PMAG_Backup @dbname = N'UserData', @type = 'trn';
Esto cambiará el secundario activo cada 15 minutos, y sus datos serán 15 minutos más recientes que el secundario activo anterior. Si tiene varias bases de datos en diferentes horarios, puede crear varios trabajos o programar el trabajo con más frecuencia y verificar dbo.PMAG_Databases tabla para cada LogBackupFrequency_Minutes individual valor para determinar si debe ejecutar la copia de seguridad/restauración para esa base de datos.
Paso 7:vista y procedimiento para indicar a la aplicación qué modo de espera está activo
CREATE VIEW dbo.PMAG_ActiveSecondaries
AS
SELECT DatabaseName, ServerInstance
FROM dbo.PMAG_Secondaries
WHERE IsCurrentStandby = 1;
GO
CREATE PROCEDURE dbo.PMAG_GetActiveSecondary
@dbname SYSNAME
AS
BEGIN
SET NOCOUNT ON;
SELECT ServerInstance
FROM dbo.PMAG_ActiveSecondaries
WHERE DatabaseName = @dbname;
END
GO
En mi caso, también creé manualmente una vista que unía todos los UserData bases de datos para poder comparar la actualidad de los datos en el principal con cada secundario.
CREATE VIEW dbo.PMAG_CompareRecency_UserData
AS
WITH x(ServerInstance, EventTime)
AS
(
SELECT @@SERVERNAME, EventTime FROM UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON1', EventTime FROM [.\PEON1].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON2', EventTime FROM [.\PEON2].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON3', EventTime FROM [.\PEON3].UserData.dbo.LastUpdate
UNION ALL SELECT N'.\PEON4', EventTime FROM [.\PEON4].UserData.dbo.LastUpdate
)
SELECT x.ServerInstance, s.IsCurrentStandby, x.EventTime,
Age_Minutes = DATEDIFF(MINUTE, x.EventTime, SYSDATETIME()),
Age_Seconds = DATEDIFF(SECOND, x.EventTime, SYSDATETIME())
FROM x LEFT OUTER JOIN dbo.PMAG_Secondaries AS s
ON s.ServerInstance = x.ServerInstance
AND s.DatabaseName = N'UserData';
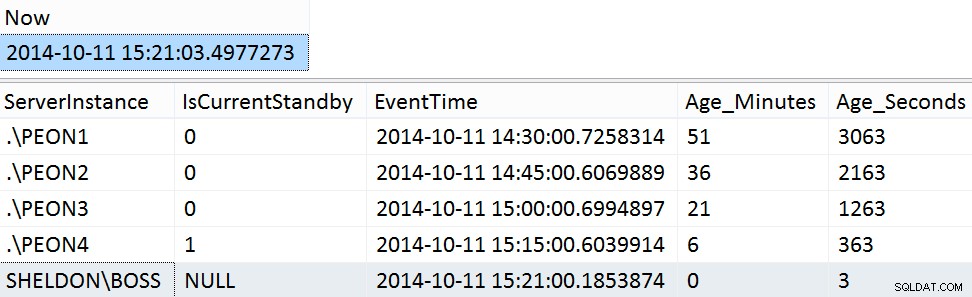
GO Resultados de muestra del fin de semana:
SELECT [Now] = SYSDATETIME(); SELECT ServerInstance, IsCurrentStandby, EventTime, Age_Minutes, Age_Seconds FROM dbo.PMAG_CompareRecency_UserData ORDER BY Age_Seconds DESC;
Paso 8:procedimiento de limpieza
Limpiar la copia de seguridad del registro y el historial de restauración es bastante fácil.
CREATE PROCEDURE dbo.PMAG_CleanupHistory
@dbname SYSNAME,
@DaysOld INT = 7
AS
BEGIN
SET NOCOUNT ON;
DECLARE @cutoff INT;
-- this assumes that a log backup either
-- succeeded or failed on all secondaries
SELECT @cutoff = MAX(BackupSetID)
FROM dbo.PMAG_LogBackupHistory AS bh
WHERE DatabaseName = @dbname
AND BackupTime < DATEADD(DAY, -@DaysOld, SYSDATETIME())
AND EXISTS
(
SELECT 1
FROM dbo.PMAG_LogRestoreHistory AS rh
WHERE BackupSetID = bh.BackupSetID
AND DatabaseName = @dbname
AND ServerInstance = bh.ServerInstance
);
DELETE dbo.PMAG_LogRestoreHistory
WHERE DatabaseName = @dbname
AND BackupSetID <= @cutoff;
DELETE dbo.PMAG_LogBackupHistory
WHERE DatabaseName = @dbname
AND BackupSetID <= @cutoff;
END
GO Ahora, puede agregarlo como un paso en el trabajo existente, o puede programarlo completamente por separado o como parte de otras rutinas de limpieza.
Dejaré la limpieza del sistema de archivos para otra publicación (y probablemente un mecanismo completamente separado, como PowerShell o C#; este no suele ser el tipo de cosas que desea que haga T-SQL).
Paso 9:aumente la solución
Es cierto que podría haber un mejor manejo de errores y otras sutilezas aquí para hacer que esta solución sea más completa. Por ahora dejaré eso como un ejercicio para el lector, pero planeo mirar las publicaciones de seguimiento para detallar las mejoras y refinamientos de esta solución.
Variables y limitaciones
Tenga en cuenta que, en mi caso, utilicé la Edición estándar como principal y la Edición exprés para todas las secundarias. Podría ir un paso más allá en la escala de presupuesto e incluso usar Express Edition como el principal; mucha gente piensa que Express Edition no admite el envío de registros, cuando en realidad es simplemente el asistente que no estaba presente en las versiones de Management Studio. Express antes de SQL Server 2012 Service Pack 1. Dicho esto, dado que Express Edition no es compatible con SQL Server Agent, sería difícil convertirlo en un editor en este escenario:tendría que configurar su propio programador para llamar a los procedimientos almacenados (C# aplicación de línea de comandos ejecutada por el Programador de tareas de Windows, trabajos de PowerShell o trabajos del Agente SQL Server en otra instancia más). Para usar Express en cualquiera de los extremos, también debe estar seguro de que su archivo de datos no excederá los 10 GB, y sus consultas funcionarán bien con las limitaciones de memoria, CPU y funciones de esa edición. De ninguna manera estoy sugiriendo que Express sea ideal; Simplemente lo usé para demostrar que es posible tener secundarios legibles muy flexibles de forma gratuita (o muy cerca).
Además, estas instancias separadas en mi escenario viven todas en la misma VM, pero no tiene que funcionar de esa manera en absoluto:puede distribuir las instancias en varios servidores; o bien, podría ir por el otro lado y restaurar en diferentes copias de la base de datos, con diferentes nombres, en la misma instancia. Estas configuraciones requerirían cambios mínimos a lo que he expuesto anteriormente. Y la cantidad de bases de datos a las que restaure y con qué frecuencia depende completamente de usted, aunque habrá un límite superior práctico (donde [average query time] > [number of secondaries] x [log backup interval] ).
Finalmente, definitivamente hay algunas limitaciones con este enfoque. Una lista no exhaustiva:
- Si bien puede continuar realizando copias de seguridad completas según su propio programa, las copias de seguridad de registros deben servir como su único mecanismo de copia de seguridad de registros. Si necesita almacenar las copias de seguridad de registros para otros fines, no podrá realizar copias de seguridad de los registros por separado de esta solución, ya que interferirán con la cadena de registro. En su lugar, puede considerar agregar
MIRROR TOadicional argumentos a los scripts de copia de seguridad de registros existentes, si necesita tener copias de los registros utilizados en otro lugar. - While "Poor Man's Availability Groups" may seem like a clever name, it can also be a bit misleading. This solution certainly lacks many of the HA/DR features of Availability Groups, including failover, automatic page repair, and support in the UI, Extended Events and DMVs. This was only meant to provide the ability for non-Enterprise customers to have an infrastructure that supports multiple readable secondaries.
- I tested this on a very isolated VM system with no concurrency. This is not a complete solution and there are likely dozens of ways this code could be made tighter; as a first step, and to focus on the scaffolding and to show you what's possible, I did not build in bulletproof resiliency. You will need to test it at your scale and with your workload to discover your breaking points, and you will also potentially need to deal with transactions over linked servers (always fun) and automating the re-initialization in the event of a disaster.
The "Insurance Policy"
Log shipping also offers a distinct advantage over many other solutions, including Availability Groups, mirroring and replication:a delayed "insurance policy" as I like to call it. At my previous job, I did this with full backups, but you could easily use log shipping to accomplish the same thing:I simply delayed the restores to one of the secondary instances by 24 hours. This way, I was protected from any client "shooting themselves in the foot" going back to yesterday, and I could get to their data easily on the delayed copy, because it was 24 hours behind. (I implemented this the first time a customer ran a delete without a where clause, then called us in a panic, at which point we had to restore their database to a point in time before the delete – which was both tedious and time consuming.) You could easily adapt this solution to treat one of these instances not as a read-only secondary but rather as an insurance policy. More on that perhaps in another post.