Hace unas semanas, escribí sobre lo sorprendido que estaba por el rendimiento de una nueva función nativa en SQL Server 2016, STRING_SPLIT() :
- Sorpresas y suposiciones de rendimiento:STRING_SPLIT()
Después de que se publicó la publicación, recibí algunos comentarios (públicos y privados) con estas sugerencias (o preguntas que convertí en sugerencias):
- Especificar un tipo de datos de salida explícito para el enfoque JSON, de modo que ese método no sufra una posible sobrecarga de rendimiento debido al respaldo de
nvarchar(max). - Probar un enfoque ligeramente diferente, en el que realmente se hace algo con los datos, a saber,
SELECT INTO #temp. - Mostrar cómo se comparan los recuentos de filas estimados con los métodos existentes, especialmente cuando se anidan operaciones de división.
Respondí a algunas personas sin conexión, pero pensé que valdría la pena publicar un seguimiento aquí.
Ser más justos con JSON
La función JSON original se veía así, sin especificación para el tipo de datos de salida:
CREATE FUNCTION dbo.SplitStrings_JSON
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); Le cambié el nombre y creé dos más, con las siguientes definiciones:
CREATE FUNCTION dbo.SplitStrings_JSON_int
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] int '$'));
GO
CREATE FUNCTION dbo.SplitStrings_JSON_varchar
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] varchar(100) '$')); Pensé que esto mejoraría drásticamente el rendimiento, pero lamentablemente, este no fue el caso. Realicé las pruebas nuevamente y los resultados fueron los siguientes:
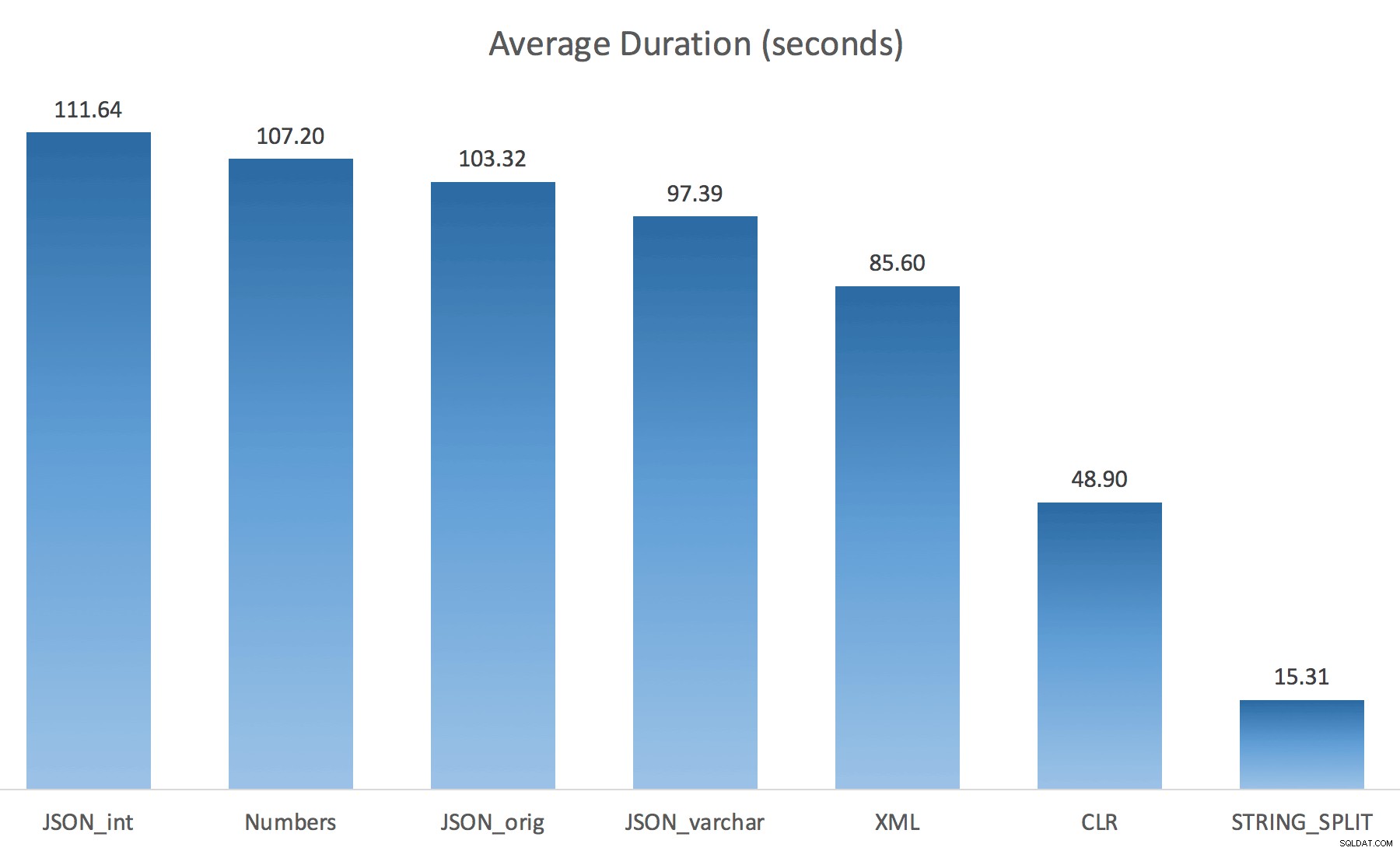
Las esperas observadas durante una instancia aleatoria de la prueba (filtradas a> 25):
| CLR | IO_COMPLETION | 1595 |
| SOS_SCHEDULER_YIELD | 76 | |
| RESERVADO_MEMORIA_ALLOCATION_EXT | 76 | |
| MEMORY_ALLOCATION_EXT | 28 | |
| JSON_int | MEMORY_ALLOCATION_EXT | 6294 |
| SOS_SCHEDULER_YIELD | 95 | |
| JSON_original | MEMORY_ALLOCATION_EXT | 4307 |
| SOS_SCHEDULER_YIELD | 83 | |
| JSON_varchar | MEMORY_ALLOCATION_EXT | 6110 |
| SOS_SCHEDULER_YIELD | 87 | |
| Números | SOS_SCHEDULER_YIELD | 96 |
| XML | MEMORY_ALLOCATION_EXT | 1917 |
| IO_COMPLETION | 1616 | |
| SOS_SCHEDULER_YIELD | 147 | |
| RESERVADO_MEMORIA_ALLOCATION_EXT | 73 |
Esperas observadas> 25 (tenga en cuenta que no hay ninguna entrada para STRING_SPLIT )
Al cambiar del valor predeterminado a varchar(100) mejoró un poco el rendimiento, la ganancia fue insignificante y cambió a int en realidad lo empeoró. Agregue a esto que probablemente necesite agregar STRING_ESCAPE() a la cadena entrante en algunos escenarios, en caso de que tengan caracteres que arruinen el análisis de JSON. Mi conclusión sigue siendo que esta es una buena manera de usar la nueva funcionalidad JSON, pero sobre todo una novedad inapropiada para una escala razonable.
Materializar el resultado
Jonathan Magnan hizo esta astuta observación en mi publicación anterior:
STRING_SPLIT es realmente muy rápido, sin embargo, también es muy lento cuando se trabaja con una tabla temporal (a menos que se arregle en una compilación futura).SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY string_split(s.StringValue, ',') AS f
Será MUCHO más lento que la solución SQL CLR (¡15 veces y más!).
Entonces, profundicé. Creé un código que llamaría a cada una de mis funciones y volcaría los resultados en una tabla #temp, y los cronometraría:
SET NOCOUNT ON; SELECT N'SET NOCOUNT ON; TRUNCATE TABLE dbo.Timings; GO '; SELECT N'DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = ''' + name + ''', point = ''Start'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f; GO DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, '''+name+''', ''End'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; DROP TABLE #test; GO' FROM sys.objects WHERE name LIKE '%split%';
Solo ejecuté cada prueba una vez (en lugar de hacer un bucle 100 veces), porque no quería destrozar por completo la E/S de mi sistema. Aún así, después de promediar tres ejecuciones de prueba, Jonathan estaba absolutamente en lo correcto al 100%. Estas fueron las duraciones de llenar una tabla #temp con ~500,000 filas usando cada método:
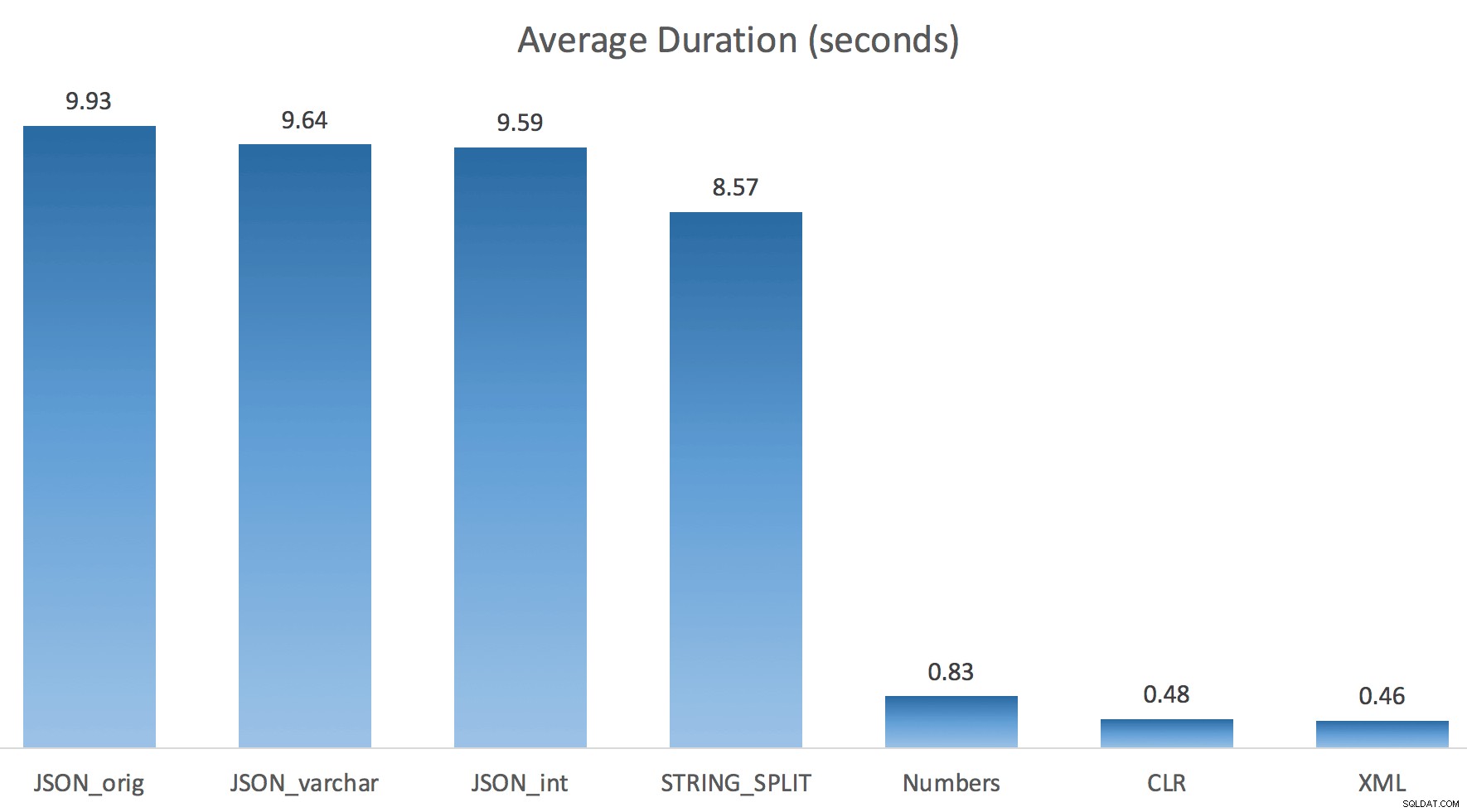
Así que aquí, el JSON y STRING_SPLIT los métodos tardaron unos 10 segundos cada uno, mientras que los enfoques de tabla de números, CLR y XML tardaron menos de un segundo. Perplejo, investigué las esperas y, efectivamente, los cuatro métodos de la izquierda incurrieron en LATCH_EX significativos. esperas (alrededor de 25 segundos) que no se ven en los otros tres, y no hubo otras esperas significativas de las que hablar.
Y dado que las esperas del pestillo fueron mayores que la duración total, me dio una pista de que esto tenía que ver con el paralelismo (esta máquina en particular tiene 4 núcleos). Así que generé código de prueba nuevamente, cambiando solo una línea para ver qué pasaría sin paralelismo:
CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f OPTION (MAXDOP 1);
Ahora STRING_SPLIT le fue mucho mejor (al igual que los métodos JSON), pero al menos duplicó el tiempo que tomó CLR:
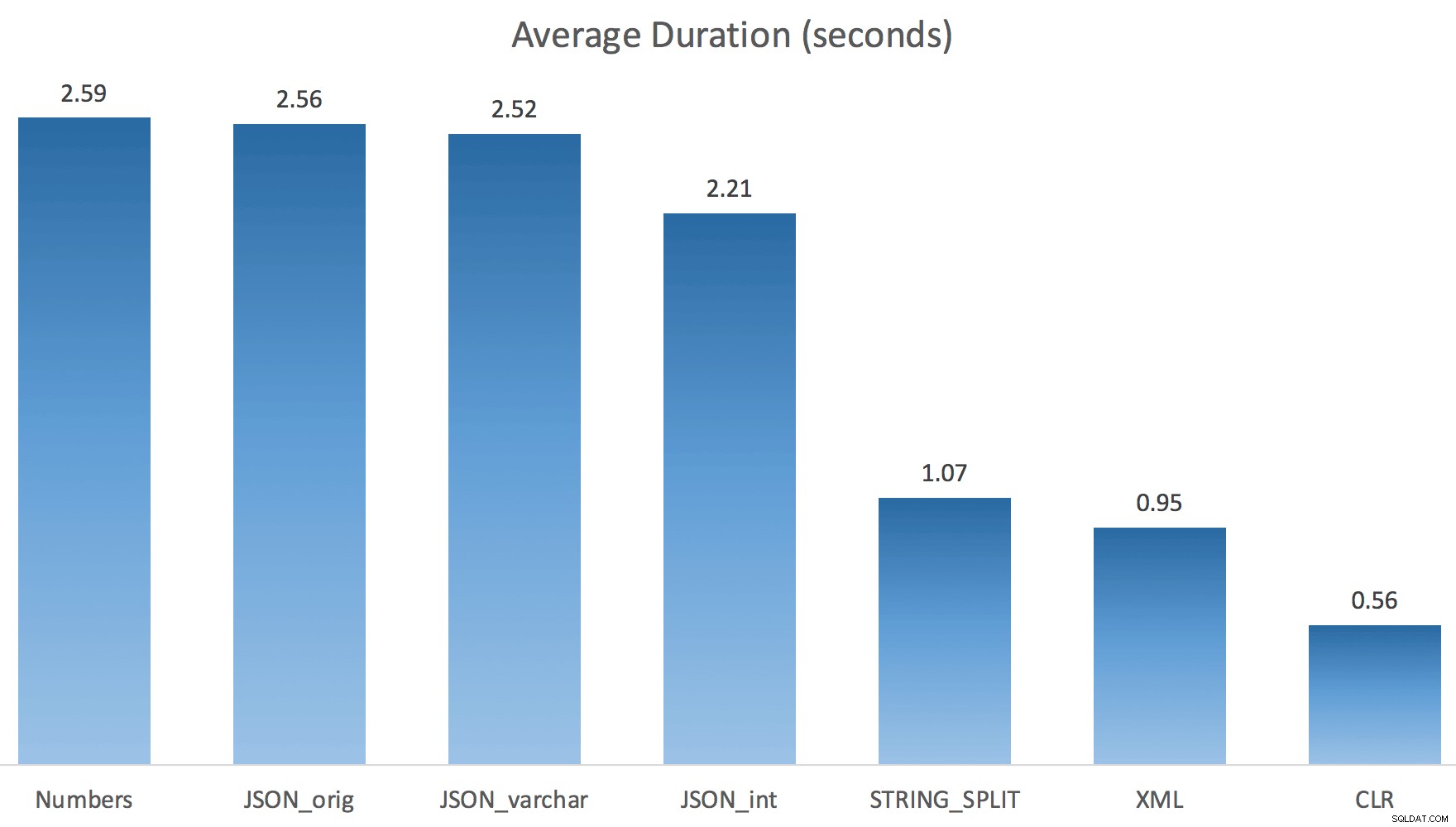
Por lo tanto, podría haber un problema pendiente en estos nuevos métodos cuando se trata de paralelismo. No fue un problema de distribución de subprocesos (lo verifiqué), y CLR en realidad tenía peores estimaciones (100x real frente a solo 5x para STRING_SPLIT ); solo algún problema subyacente con la coordinación de pestillos entre hilos, supongo. Por ahora, podría valer la pena usar MAXDOP 1 si sabe que está escribiendo el resultado en nuevas páginas.
He incluido los planes gráficos que comparan el enfoque CLR con el nativo, tanto para la ejecución en paralelo como en serie (también he subido un archivo de análisis de consulta que puede abrir en SQL Sentry Plan Explorer para husmear por su cuenta):
STRING_SPLIT
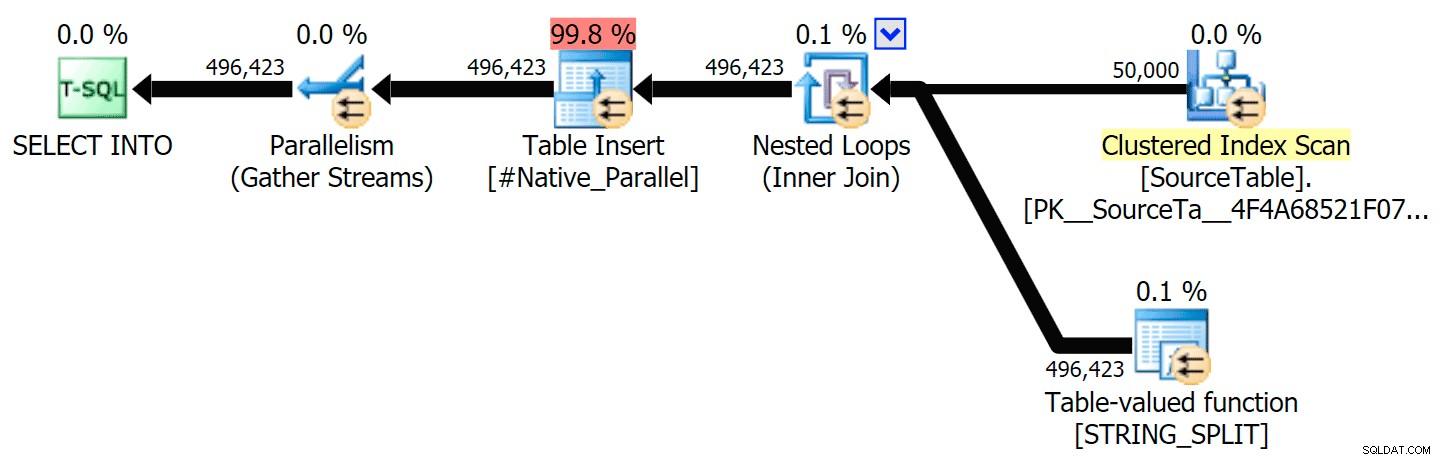
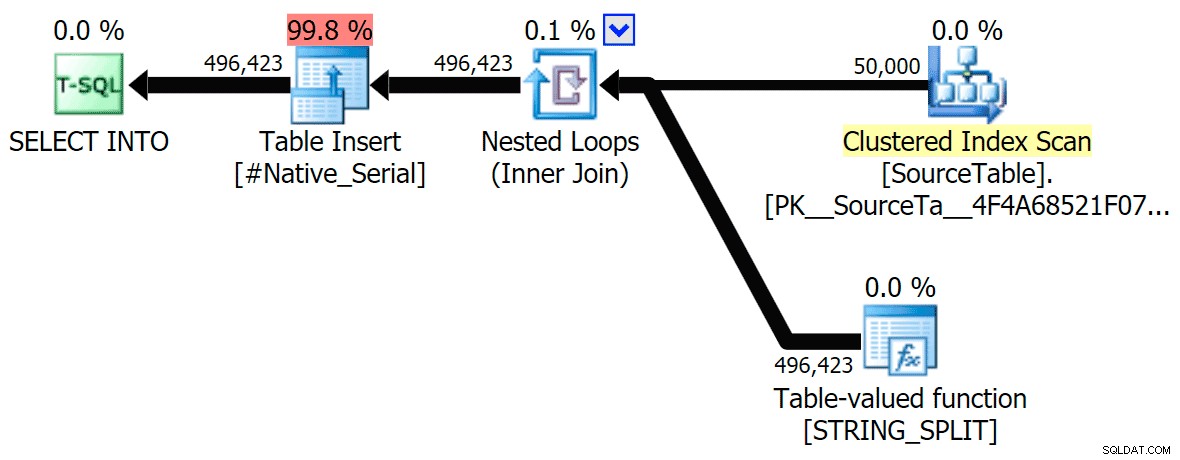
CLR
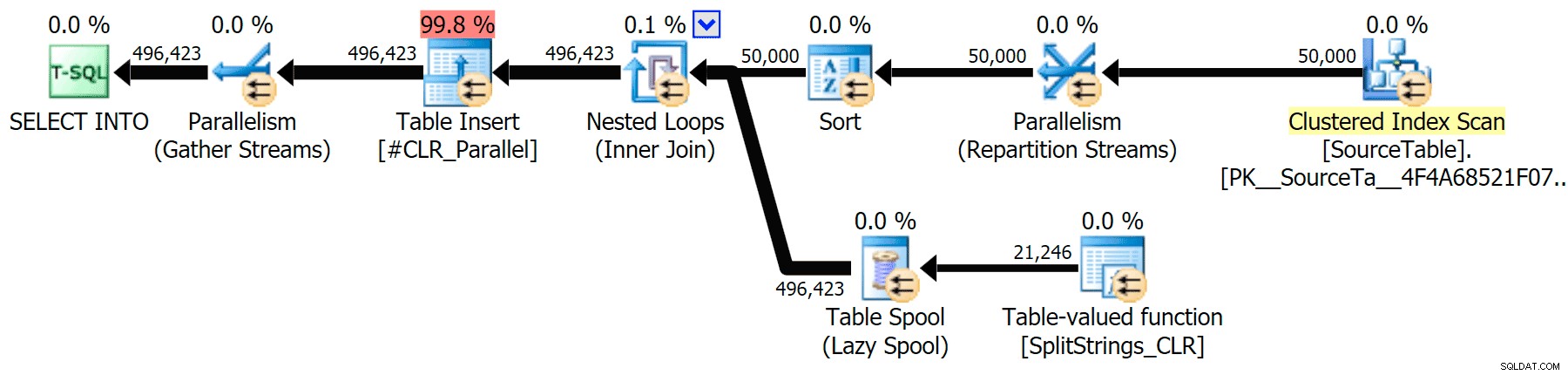
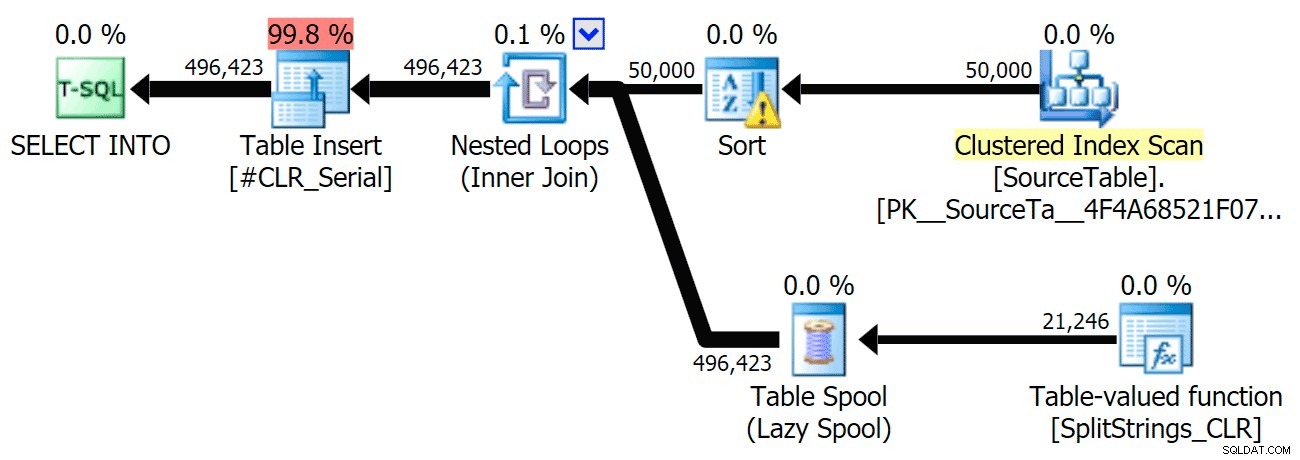
La advertencia de clasificación, FYI, no fue demasiado impactante y, obviamente, no tuvo un efecto tangible en la duración de la consulta:

- StringSplit.queryanalysis.zip (25kb)
Se prepara para el verano
Cuando miré un poco más de cerca esos planes, noté que en el plan CLR, hay un carrete perezoso. Esto se introduce para asegurarse de que los duplicados se procesen juntos (para ahorrar trabajo al hacer menos divisiones reales), pero este carrete no siempre es posible en todas las formas del plan, y puede brindar cierta ventaja a aquellos que pueden usarlo ( por ejemplo, el plan CLR), dependiendo de las estimaciones. Para comparar sin carretes, habilité el indicador de seguimiento 8690 y ejecuté las pruebas nuevamente. Primero, aquí está el plan CLR paralelo sin el carrete:
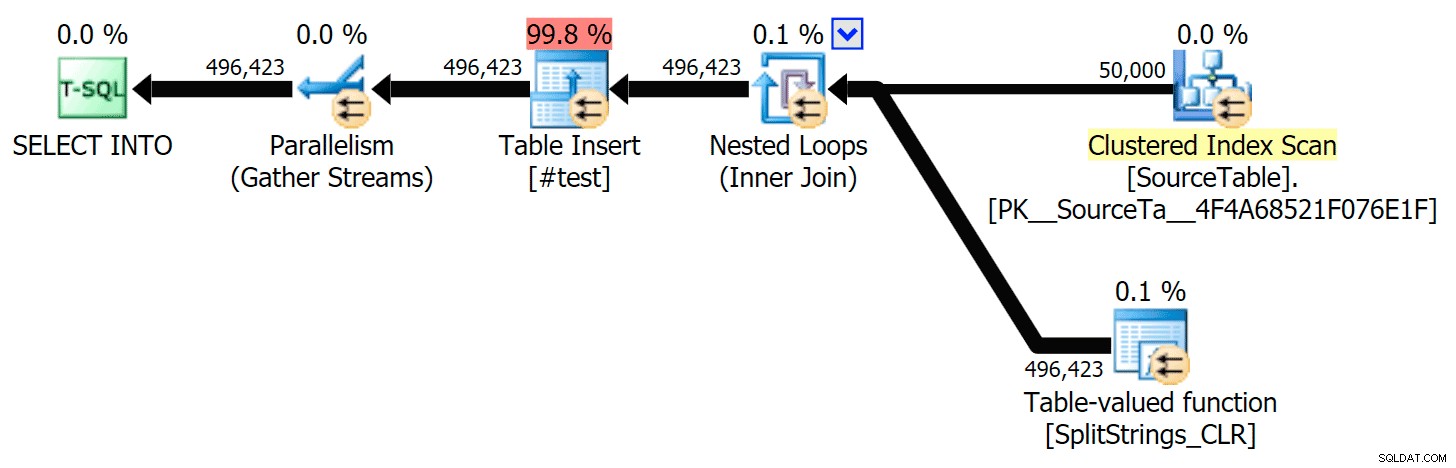
Y aquí estaban las nuevas duraciones para todas las consultas paralelas con TF 8690 habilitado:
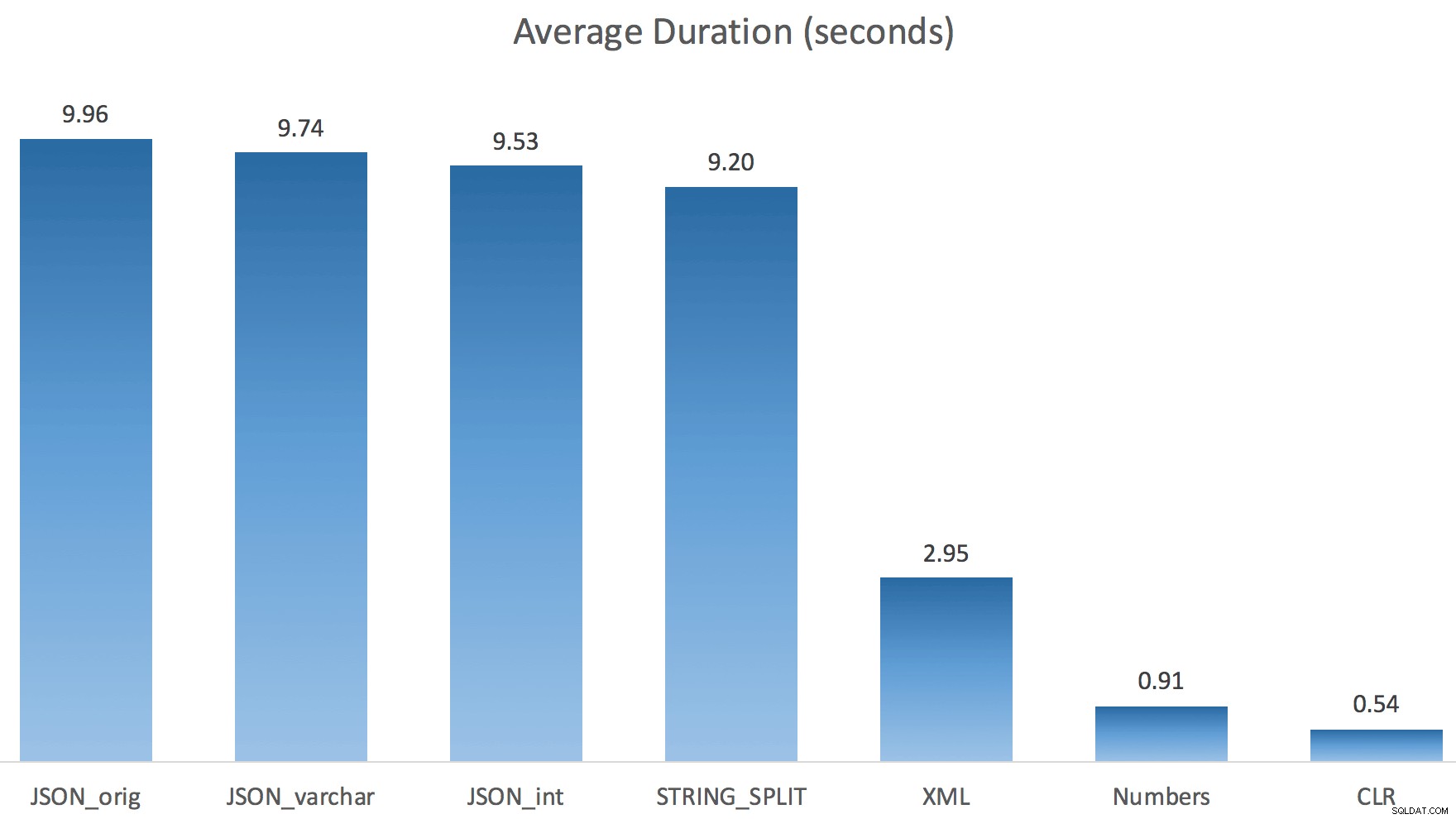
Ahora, aquí está el plan CLR serial sin el carrete:
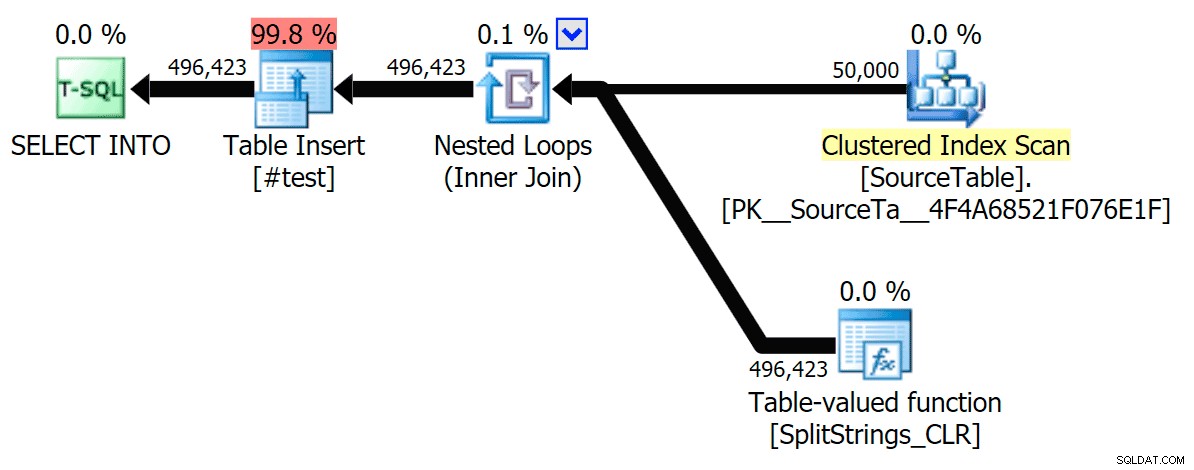
Y estos fueron los resultados de tiempo para las consultas que utilizan TF 8690 y MAXDOP 1 :
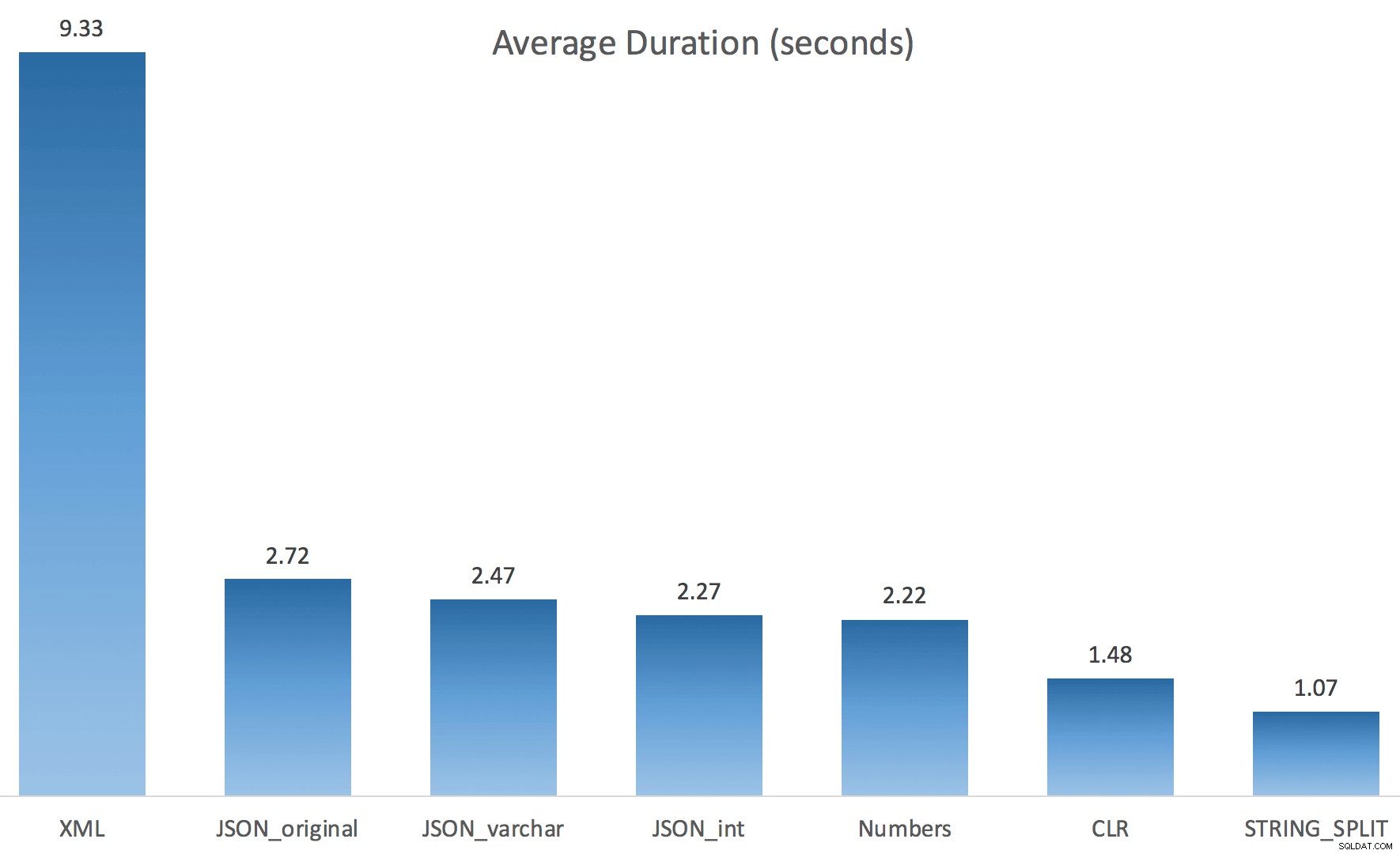
(Tenga en cuenta que, además del plan XML, la mayoría de los demás no cambiaron en absoluto, con o sin la marca de rastreo).
Comparación de recuentos de filas estimados
Dan Holmes hizo la siguiente pregunta:
¿Cómo estima el tamaño de los datos cuando se une a otra función dividida (o múltiple)? El siguiente enlace es una redacción de una implementación dividida basada en CLR. ¿El 2016 hace un trabajo 'mejor' con las estimaciones de datos? (lamentablemente, todavía no tengo la capacidad de instalar RC).https://sql.dnhlms.com/2016/02/sql-clr-based-string-splitting-and. html
Entonces, deslicé el código de la publicación de Dan, lo cambié para usar mis funciones y lo ejecuté a través de Plan Explorer:
DECLARE @s VARCHAR(MAX); SELECT * FROM dbo.SplitStrings_CLR(@s, ',') s CROSS APPLY dbo.SplitStrings_CLR(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_CLR(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_CLR(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Numbers(@s, ',') s CROSS APPLY dbo.SplitStrings_Numbers(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Numbers(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Numbers(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Native(@s, ',') s CROSS APPLY dbo.SplitStrings_Native(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Native(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Native(s2.value, '#') s3;
El SPLIT_STRING El enfoque ciertamente genera estimaciones *mejores* que CLR, pero aún así muy por encima (en este caso, cuando la cadena está vacía; este podría no ser siempre el caso). La función tiene un valor predeterminado incorporado que estima que la cadena entrante tendrá 50 elementos, por lo que cuando los anida obtiene 50 x 50 (2500); si los anida de nuevo, 50 x 2500 (125 000); y finalmente, 50 x 125 000 (6 250 000):
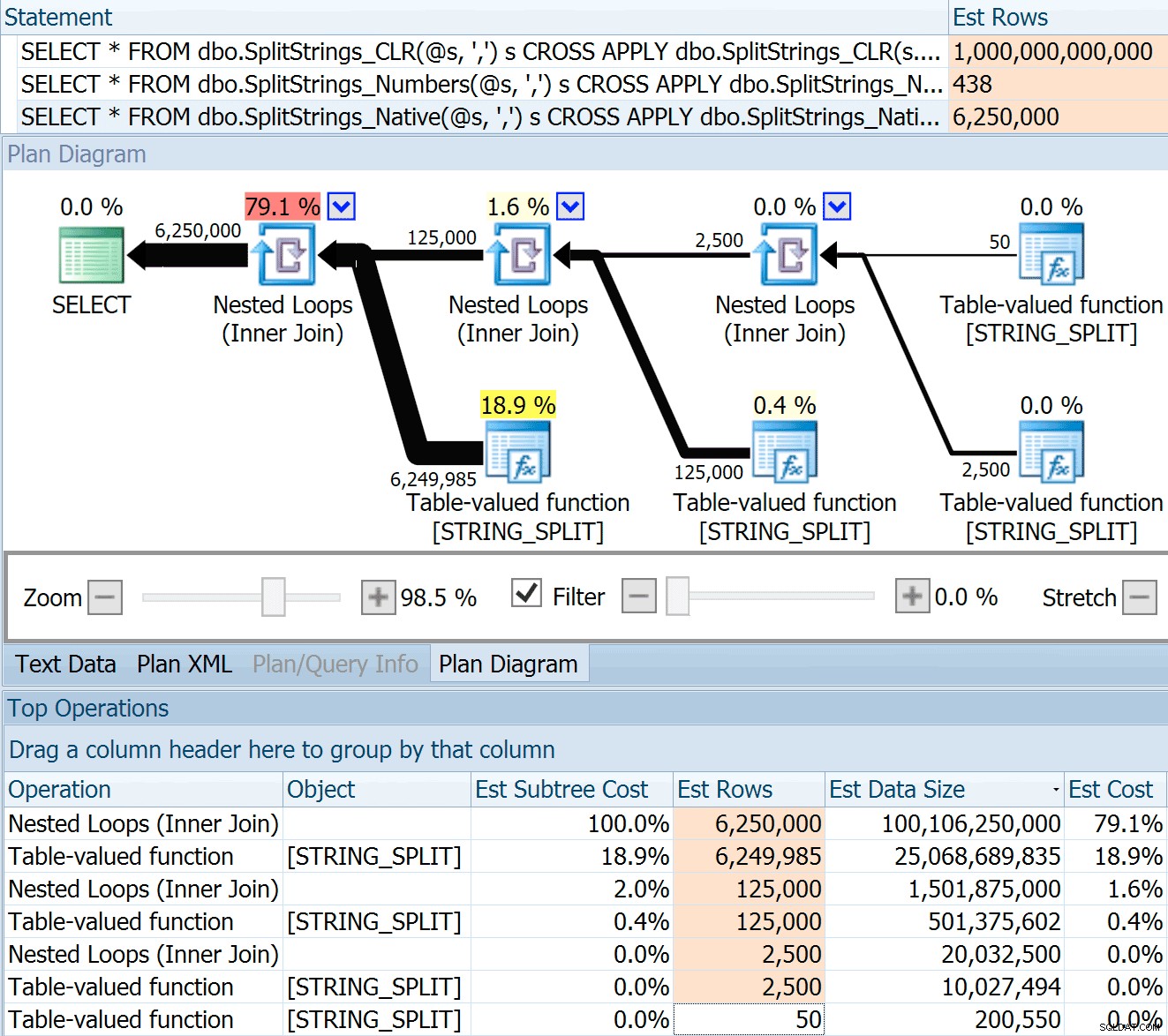
Nota:OPENJSON() se comporta exactamente de la misma manera que STRING_SPLIT – también asume que saldrán 50 filas de cualquier operación de división dada. Estoy pensando que podría ser útil tener una forma de insinuar cardinalidad para funciones como esta, además de marcas de seguimiento como 4137 (anterior a 2014), 9471 y 9472 (2014+) y, por supuesto, 9481...
Esta estimación de 6,25 millones de filas no es excelente, pero es mucho mejor que el enfoque CLR del que hablaba Dan, que estima UN TRILLÓN DE FILAS , y perdí la cuenta de las comas para determinar el tamaño de los datos:¿16 petabytes? exabytes?
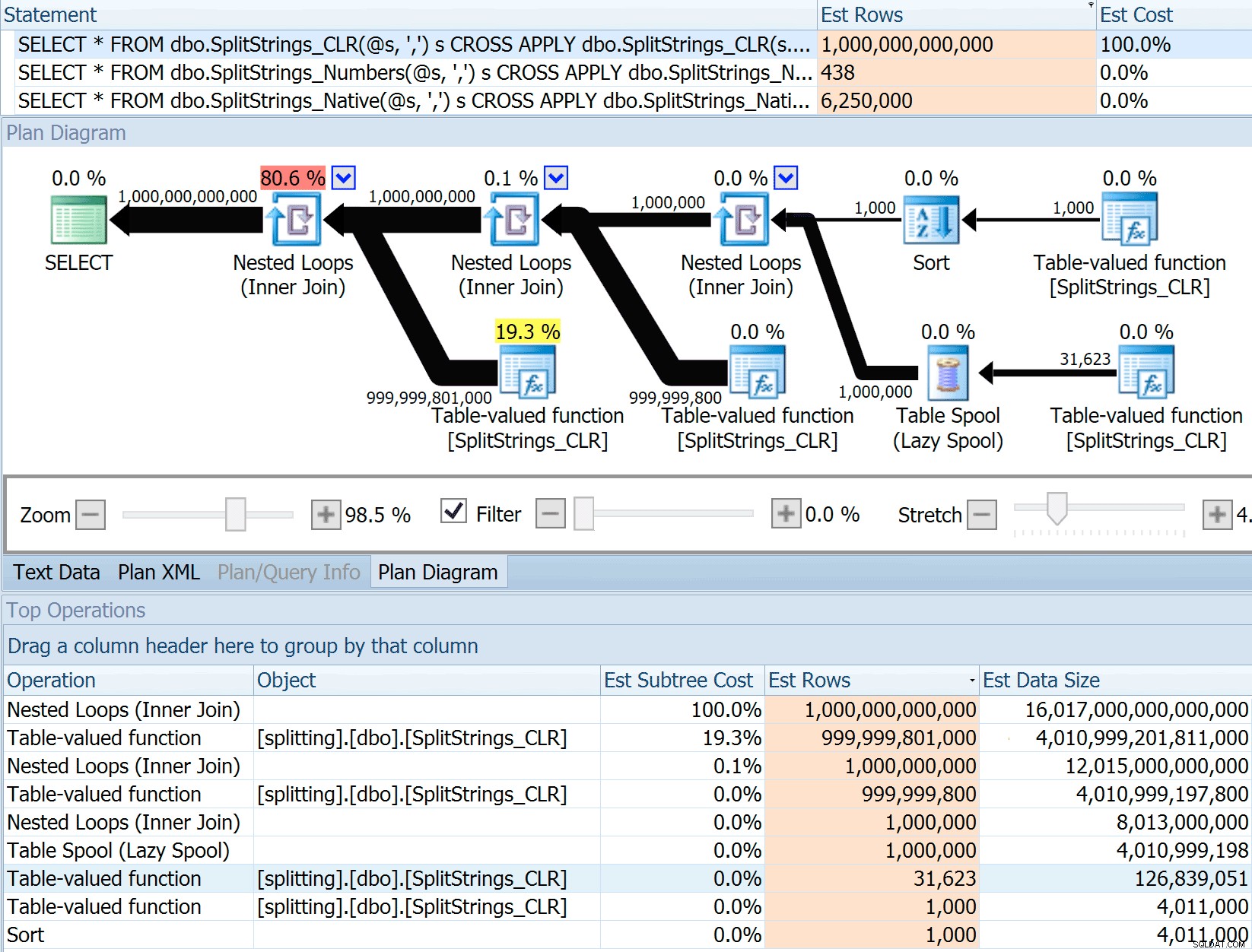
Obviamente, a algunos de los otros enfoques les va mejor en términos de estimaciones. La tabla Numbers, por ejemplo, estimó 438 filas mucho más razonables (en SQL Server 2016 RC2). ¿De dónde viene este número? Bueno, hay 8000 filas en la tabla, y si recuerdas, la función tiene un predicado de igualdad y desigualdad:
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter Entonces, SQL Server multiplica el número de filas en la tabla por 10% (como una conjetura) para el filtro de igualdad, luego la raíz cuadrada del 30% (de nuevo, una conjetura) para el filtro de desigualdad. La raíz cuadrada se debe al retroceso exponencial, que Paul White explica aquí. Esto nos da:
8000 * 0,1 * SQRT(0,3) =438,178La variación de XML se estimó en poco más de mil millones de filas (debido a un spool de tabla que se estima que se ejecutará 5,8 millones de veces), pero su plan era demasiado complejo para tratar de ilustrarlo aquí. En cualquier caso, recuerde que las estimaciones claramente no cuentan la historia completa:el hecho de que una consulta tenga estimaciones más precisas no significa que funcionará mejor.
Había algunas otras formas en las que podía modificar un poco las estimaciones:a saber, forzando el antiguo modelo de estimación de cardinalidad (que afectaba tanto a las variaciones de la tabla XML como a la de Numbers) y usando los TF 9471 y 9472 (que afectaban solo a la variación de la tabla de Numbers, ya que ambos controlan la cardinalidad en torno a múltiples predicados). Estas eran las formas en que podía cambiar las estimaciones solo un poco (o MUCHO , en el caso de volver al antiguo modelo CE):

El antiguo modelo CE redujo las estimaciones de XML en un orden de magnitud, pero para la tabla Numbers, la explotó por completo. Los indicadores de predicado alteraron las estimaciones de la tabla Números, pero esos cambios son mucho menos interesantes.
Ninguna de estas marcas de seguimiento tuvo ningún efecto en las estimaciones de CLR, JSON o STRING_SPLIT variaciones.
Conclusión
Entonces, ¿qué aprendí aquí? Un montón, en realidad:
- El paralelismo puede ayudar en algunos casos, pero cuando no ayuda, realmente no ayuda Los métodos JSON eran ~5 veces más rápidos sin paralelismo y
STRING_SPLITfue casi 10 veces más rápido. - El spool realmente ayudó a que el enfoque CLR funcionara mejor en este caso, pero TF 8690 podría ser útil para experimentar en otros casos en los que está viendo spools y está tratando de mejorar el rendimiento. Estoy seguro de que hay situaciones en las que eliminar el carrete terminará siendo mejor en general.
- Eliminar el spool realmente perjudicó el enfoque XML (pero solo drásticamente cuando se vio obligado a ser de un solo subproceso).
- Pueden suceder muchas cosas raras con las estimaciones según el enfoque, junto con las estadísticas, la distribución y las marcas de seguimiento habituales. Bueno, supongo que ya lo sabía, pero definitivamente hay un par de buenos ejemplos tangibles aquí.
Gracias a las personas que hicieron preguntas o me empujaron a incluir más información. Y como habrás adivinado por el título, abordé otra pregunta en una segunda continuación, esta sobre los TVP:
- STRING_SPLIT() en SQL Server 2016:seguimiento n.º 2



