Los principales cambios realizados en la Estimación de cardinalidad a partir de la versión de SQL Server 2014 se describen en el documento técnico de Microsoft Optimización de sus planes de consulta con el Estimador de cardinalidad de SQL Server 2014 por Joe Sack, Yi Fang y Vassilis Papadimos.
Uno de esos cambios se refiere a la estimación de uniones simples con un solo predicado de igualdad o desigualdad utilizando histogramas estadísticos. En la sección titulada "Únete a los cambios del algoritmo de estimación", el documento introdujo el concepto de "alineación aproximada" utilizando límites de histograma mínimos y máximos:
Para uniones con un solo predicado de igualdad o desigualdad, el CE heredado une los histogramas en las columnas de unión alineando los dos histogramas paso a paso usando interpolación lineal. Este método podría resultar en estimaciones de cardinalidad inconsistentes. Por lo tanto, el nuevo CE ahora usa un algoritmo de estimación de combinación más simple que alinea los histogramas utilizando solo los límites de histograma mínimo y máximo.Aunque potencialmente menos consistente, el CE heredado puede producir estimaciones de condiciones de unión simple ligeramente mejores debido a la alineación del histograma paso a paso. El nuevo CE utiliza una alineación gruesa. Sin embargo, la diferencia en las estimaciones puede ser lo suficientemente pequeña como para que sea menos probable que cause un problema de calidad del plan.
Como uno de los revisores técnicos del documento, sentí que un poco más de detalles sobre este cambio habría sido útil, pero eso no se incluyó en la versión final. Este artículo agrega algunos de esos detalles.
Ejemplo de alineación de histograma grueso
La alineación aproximada El ejemplo del White Paper usa la versión Data Warehouse de la base de datos de muestra AdventureWorks. A pesar del nombre, la base de datos es bastante pequeña; la copia de seguridad tiene solo 22,3 MB y se expande a alrededor de 200 MB. Se puede descargar a través de enlaces en la página de documentación de instalación y configuración de AdventureWorks.
La consulta que nos interesa se une a FactResellerSales y FactCurrencyRate mesas.
SELECT
FRS.ProductKey,
FRS.OrderDateKey,
FRS.DueDateKey,
FRS.ShipDateKey,
FCR.DateKey,
FCR.AverageRate,
FCR.EndOfDayRate,
FCR.[Date]
FROM dbo.FactResellerSales AS FRS
JOIN dbo.FactCurrencyRate AS FCR
ON FCR.CurrencyKey = FRS.CurrencyKey; Esta es una unión igualitaria simple en una sola columna por lo que califica para la cardinalidad de unión y la estimación de selectividad utilizando la alineación aproximada del histograma.
Histogramas
Los histogramas que necesitamos están asociados con CurrencyKey columna en cada tabla unida. En una copia nueva de la base de datos AdventureWorksDW, las estadísticas preexistentes para las FactResellerSales más grandes tabla se basan en una muestra. Para maximizar la reproducibilidad y hacer que los cálculos detallados sean lo más simples posible de seguir (evitando la escala), lo primero que haremos será actualizar las estadísticas usando un escaneo completo:
UPDATE STATISTICS dbo.FactCurrencyRate WITH FULLSCAN; UPDATE STATISTICS dbo.FactResellerSales WITH FULLSCAN;
Estas tablas tienen el beneficio fácil de demostración de crear maxdiff pequeños y simples histogramas:
DBCC SHOW_STATISTICS
(FactResellerSales, CurrencyKey)
WITH HISTOGRAM;
DBCC SHOW_STATISTICS
(FactCurrencyRate, [PK_FactCurrencyRate_CurrencyKey_DateKey])
WITH HISTOGRAM;
Combinar pasos mínimos de histograma coincidentes
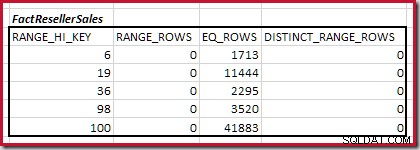
El primer paso en la alineación aproximada El cálculo consiste en encontrar la contribución a la cardinalidad de unión proporcionada por el paso de histograma coincidente más bajo. Para nuestros histogramas de ejemplo, el valor de paso mínimo coincidente está en RANGE_HI_KEY = 6 :
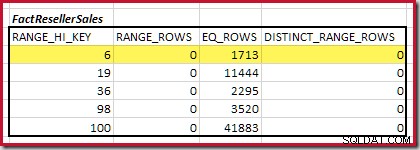
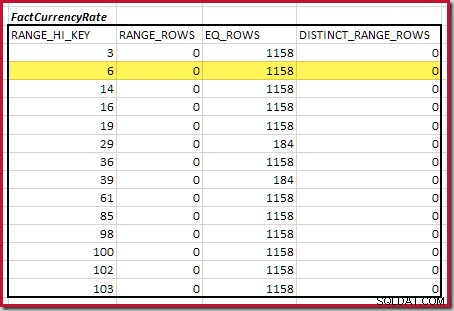
La cardinalidad de unión equitativa estimada solo para este paso resaltado es 1713 * 1158 =1 983 654 filas .
Pasos coincidentes restantes
A continuación, necesitamos identificar el rango del histograma RANGE_HI_KEY aumenta al máximo para posibles coincidencias de unión igualitaria. Esto implica avanzar desde el mínimo encontrado previamente hasta que una de las entradas del histograma se quede sin filas. Los rangos de unión igualitaria coincidentes para el ejemplo actual se resaltan a continuación:
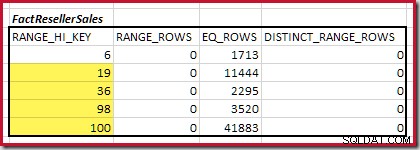
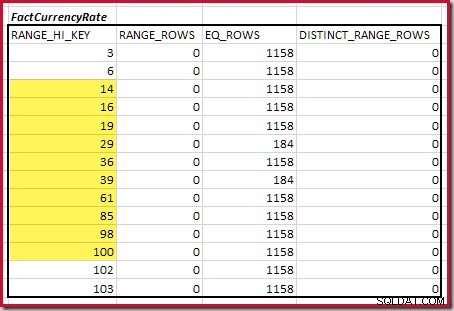
Estos dos rangos representan las filas restantes que se espera que contribuyan a la cardinalidad de unión igualitaria.
Estimación aproximada basada en frecuencia
La pregunta ahora es cómo realizar un grueso estimación de la cardinalidad equijoin de los pasos resaltados, utilizando la información disponible.
El estimador de cardinalidad original habría realizado una alineación detallada del histograma paso a paso mediante interpolación lineal, evaluado la contribución conjunta de cada paso (al igual que hicimos antes con el valor mínimo del paso) y sumado la contribución de cada paso para adquirir una estimación de unión completa. Si bien este procedimiento tiene mucho sentido intuitivo, la experiencia práctica fue que este enfoque detallado agregó una sobrecarga computacional y podría producir resultados de calidad variable.
El estimador original tenía otra forma de estimar la cardinalidad de unión cuando la información del histograma no estaba disponible o se evaluaba heurísticamente como inferior. Esto se conoce como estimación basada en la frecuencia y utiliza las siguientes definiciones:
- C:la cardinalidad (número de filas)
- D:el número de valores distintos
- F:la frecuencia (número de filas) para cada valor distinto
- Nota C =D * F por definición
El efecto de una unión equitativa de las relaciones R1 y R2 en cada una de estas propiedades se muestra a continuación:
- F' =F1 * F2
- D' =MIN(D1; D2) – asumiendo contención
- C' =D' * F' (de nuevo, por definición)
Estamos después de C', la cardinalidad de la unión igualitaria. Sustituyendo D' y F' en la fórmula y expandiendo:
- C' =D' * F'
- C' =MÍN.(D1; D2) * F1 * F2
- C' =MÍN.(D1 * F1 * F2; D2 * F1 * F2)
- ahora, dado que C1 =D1 * F1 y C2 =D2 * F2:
- C' =MÍN.(C1 * F2, C2 * F1)
- finalmente, dado que F =C/D (también por definición):
- C' =MÍN.(C1 * C2 / D2; C2 * C1 / D1)
Observando que C1 * C2 es el producto de las dos cardinalidades de entrada (unión cartesiana), es claro que la mínima de esas expresiones será la que tenga el mayor número de valores distintos:
- C' =(C1 * C2) / MÁX.(D1; D2)
En caso de que todo esto parezca un poco abstracto, una forma intuitiva de pensar en la estimación de unión igualitaria basada en la frecuencia es considerar que cada valor distinto de una relación se unirá con un número de filas (la frecuencia promedio) en la otra relación. Si tenemos 5 valores distintos en un lado, y cada valor distinto en el otro lado aparece 3 veces en promedio, una estimación equijoin sensata (pero aproximada) es 5 * 3 =15.
Esta no es una brocha tan amplia como podría parecer. Recuerde que los números de cardinalidad y valores distintos anteriores no provienen de la relación completa, sino solo de los pasos coincidentes por encima del mínimo. Por lo tanto, estimación aproximada entre valores mínimos y máximos.
Cálculo de frecuencia
Podemos obtener cada uno de estos parámetros de los pasos del histograma resaltados.
- La cardinalidad C es la suma de
EQ_ROWSyRANGE_ROWS. - El número de valores distintos D es la suma de
DISTINCT_RANGE_ROWSmás uno para cada paso.
La cardinalidad C1 de coincidencia FactResellerSales pasos es la suma de las celdas resaltadas:
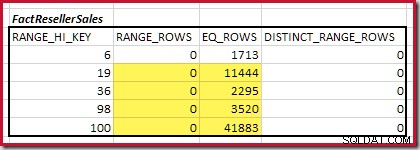
Esto da C1 =59,142 filas.
No hay filas de rango distintas, por lo que los únicos valores distintos provienen de los límites de los cuatro pasos, dando D1 =4 .
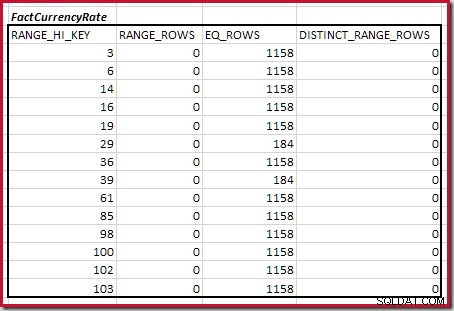
Para la segunda tabla:
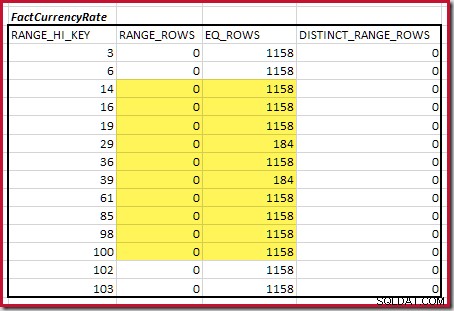
Esto da C2 =9632 . De nuevo, no hay filas de rango distintas, por lo que los valores distintos provienen de los límites de diez pasos, D2 =10.
Completar la estimación de combinación equitativa
Ahora tenemos todos los números que necesitamos para la fórmula de unión igualitaria:
- C' =(C1 * C2) / MÁX.(D1; D2)
- C' =(59142 * 9632) / MÁX.(4; 10)
- C' =569655744 / 10
- C' =56.965.574,4
Recuerde, esta es la contribución de los pasos del histograma por encima del límite mínimo coincidente. Para completar la estimación de la cardinalidad de combinación, debemos agregar la contribución de los valores de paso de coincidencia mínimos, que fue 1713 * 1158 =1 983 654 filas.
Por lo tanto, la estimación de unión equitativa final es 56 965 574,4 + 1 983 654 =58 949 228,4 filas o 58 949 200 a seis cifras significativas.
Este resultado se confirma en el plan de ejecución estimado para la consulta de origen:
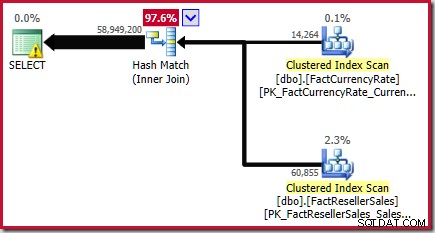
Como se señala en el Libro Blanco, esta no es una gran estimación. El número real de filas devueltas por esta consulta es 70 470 090 . La estimación producida por el estimador de cardinalidad original ("heredado"), utilizando la alineación de histograma paso a paso, es de 70 470 100 filas.
A menudo, se pueden obtener mejores resultados con el método más fino, pero solo si las estadísticas son una muy buena representación de la distribución de datos subyacente. Esto no es simplemente una cuestión de mantener las estadísticas actualizadas o utilizar la población de exploración completa. El algoritmo utilizado para empaquetar la información en un máximo de 201 pasos de histograma no es perfecto y, en cualquier caso, muchas distribuciones de datos del mundo real simplemente no son capaces de lograr tal fidelidad de histograma. En promedio, las personas deberían encontrar que el método más grueso proporciona estimaciones perfectamente adecuadas y una mayor estabilidad con el nuevo CE.
Segundo Ejemplo
Esto se basa un poco en el ejemplo anterior y no requiere una descarga de base de datos de muestra.
DROP TABLE IF EXISTS
dbo.R1,
dbo.R2;
CREATE TABLE dbo.R1 (n integer NOT NULL);
CREATE TABLE dbo.R2 (n integer NOT NULL);
INSERT dbo.R1
(n)
VALUES
(1), (2), (3), (4), (5), (6), (7), (8), (9), (10),
(6), (6), (6), (6), (6), (6), (6), (6), (6), (6),
(6), (6), (6), (6), (6), (6), (6), (6), (6);
INSERT dbo.R2
(n)
VALUES
(5), (6), (7), (8), (9), (10), (11), (12), (13), (14), (15),
(10), (10);
CREATE STATISTICS stats_n ON dbo.R1 (n) WITH FULLSCAN;
CREATE STATISTICS stats_n ON dbo.R2 (n) WITH FULLSCAN; Los histogramas que muestran los pasos mínimos coincidentes son:
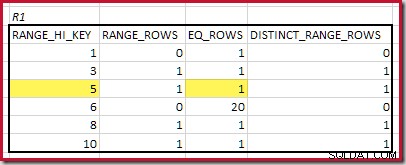
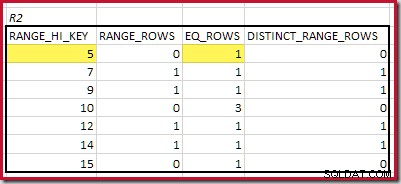
La RANGE_HI_KEY más baja que coincide es 5. El valor de EQ_ROWS es 1 en ambos, por lo que la cardinalidad equijoin estimada es 1 * 1 =1 fila .
La coincidencia más alta RANGE_HI_KEY es 10. Resaltar las filas del histograma R1 para una estimación aproximada basada en la frecuencia:
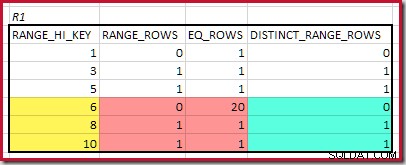
Sumando EQ_ROWS y RANGE_ROWS da C1 =24 . El número de filas distintas es 2 DISTINCT_RANGE_ROWS (valores distintos entre pasos) más 3 para los valores distintos asociados con cada límite de paso, dando D1 =5 .
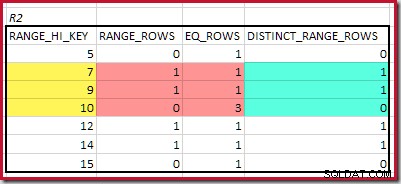
Para R2, sumando EQ_ROWS y RANGE_ROWS da C2 =7 . El número de filas distintas es 2 DISTINCT_RANGE_ROWS (valores distintos entre pasos) más 3 para los valores distintos asociados con cada límite de paso, dando D2 =5 .
La estimación de unión igualitaria C' es:
- C' =(C1 * C2) / MÁX.(D1; D2)
- C' =(24 * 7) / 5
- C' =33,6
Agregar en la 1 fila de la coincidencia de pasos mínimos da una estimación total de 34,6 filas para la unión igualitaria:
SELECT
R1.n,
R2.n
FROM dbo.R1 AS R1
JOIN dbo.R2 AS R2
ON R2.n = R1.n; El plan de ejecución estimado muestra una estimación que coincide con nuestro cálculo:

Esto no es exactamente correcto, pero el estimador de cardinalidad "heredado" no lo hace mejor, estimando 15,25 filas frente a 27 reales:

Para un tratamiento completo, también tendríamos que agregar una contribución final de los pasos nulos del histograma coincidente, pero esto es poco común para las uniones igualitarias (que generalmente se escriben para rechazar nulos) y una extensión relativamente sencilla para el lector interesado.
Reflexiones finales
Con suerte, los detalles del artículo llenarán algunos vacíos para cualquiera que alguna vez se haya preguntado acerca de la "alineación aproximada". Tenga en cuenta que este es solo un pequeño componente en el estimador de cardinalidad. Hay varios otros conceptos y algoritmos importantes que se utilizan para la estimación de combinaciones, en particular, la forma en que se evalúan los predicados que no son de combinación y cómo se manejan las combinaciones más complejas. Muchas de las partes realmente importantes están bastante bien cubiertas en el White Paper.