La replicación transaccional de SQL Server es una de las técnicas de replicación más comunes utilizadas para copiar o distribuir datos entre múltiples destinos.
En los artículos anteriores, discutimos la replicación de SQL Server, cómo funciona internamente y cómo configurar la replicación a través del asistente de replicación o el enfoque T-SQL. Ahora, nos enfocamos en los problemas de replicación de SQL y en solucionarlos correctamente.
Problemas de replicación de SQL
La mayoría de los clientes que utilizan la replicación transaccional de SQL Server se concentran principalmente en obtener datos casi en tiempo real disponibles en las instancias de la base de datos del suscriptor. Por lo tanto, el DBA que administra la replicación debe estar al tanto de varios posibles problemas relacionados con la replicación de SQL que pueden surgir. Además, el DBA debe poder resolver estos problemas en poco tiempo.
Podemos categorizar todos los problemas de replicación de SQL en las siguientes categorías (según mi experiencia):
Problemas de configuración
- Tamaño máximo de replicación de texto
- El servicio del Agente SQL Server no está configurado para iniciar el modo automático
- Las instancias de replicación no supervisadas entran en un estado de suscripciones no inicializadas
- Problemas conocidos dentro de SQL Server
Problemas de permisos
- Problemas de permisos de trabajo del Agente SQL Server
- La credencial de trabajo del agente de instantáneas no puede acceder a la ruta de la carpeta de instantáneas
- La credencial de trabajo del agente de registro de registros no se puede conectar a la base de datos de publicación/distribución
- La credencial de trabajo del agente de distribución no se puede conectar a la base de datos de distribución/suscriptor
Problemas de conectividad
- No se encontró o no se pudo acceder al servidor del editor
- No se encontró o no se pudo acceder al servidor de distribución
- No se encontró el servidor del suscriptor o no se pudo acceder a él
Problemas de integridad de datos
- Errores de infracción de clave principal o clave única
- Errores de fila no encontrada
- Errores de violación de clave externa u otras restricciones
Problemas de rendimiento
- Transacciones activas de ejecución prolongada en la base de datos de Publisher
- Operaciones masivas de INSERCIÓN/ACTUALIZACIÓN/ELIMINACIÓN en artículos
- Grandes cambios de datos en una sola transacción
- Bloqueos en la base de datos de distribución
Problemas relacionados con la corrupción
- Corrupciones en la base de datos del editor
- Corrupción del archivo de registro transaccional del editor
- Corrupciones en la base de datos de distribución
- Corrupciones en la base de datos de suscriptores
Preparación del entorno DEMO
Antes de profundizar en los detalles sobre los problemas de replicación de SQL, debemos preparar nuestro entorno para la demostración. Como se discutió en mis artículos anteriores, cualquier cambio de datos que ocurra en la base de datos del suscriptor en la replicación transaccional no será visible directamente en la base de datos del publicador. Por lo tanto, vamos a realizar ciertas modificaciones directamente en la base de datos de suscriptores con fines de aprendizaje.
Tenga mucho cuidado y no modifique nada en las bases de datos de producción. Afectará la integridad de los datos de las bases de datos del suscriptor. Tomaré los scripts de copia de seguridad para cada cambio realizado y los usaré para solucionar los problemas de replicación de SQL.
Cambio 1:insertar registros en la tabla Person.ContactType
Antes de insertar registros en Person.ContacType table, echemos un vistazo a la estructura de la tabla, algunas restricciones predeterminadas y propiedades extendidas redactadas en el siguiente script:
CREATE TABLE [Person].[ContactType](
[ContactTypeID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[Name] [dbo].[Name] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_ContactType_ContactTypeID] PRIMARY KEY CLUSTERED
(
[ContactTypeID] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
Elegí esta tabla porque tiene menos columnas. Es más conveniente para fines de prueba. Ahora, veamos lo que tenemos sobre su estructura:
- Identificación del tipo de contacto se define como una COLUMNA DE IDENTIDAD:generará automáticamente los valores de la clave principal y NO PARA LA REPLICACIÓN.
- NOT FOR REPLICATION es una propiedad especial que se puede usar en varios tipos de objetos como tablas, restricciones como restricciones de clave foránea, restricciones de verificación, activadores y columnas de identidad en el publicador o el suscriptor mientras se usa cualquiera de las metodologías de replicación únicamente. Permite que el DBA planifique o implemente la replicación para garantizar que ciertas funcionalidades se comporten de manera diferente en el publicador/suscriptor mientras se usa la replicación.
- En nuestro caso, le indicamos a SQL Server que use los valores de IDENTIDAD generados solo en la base de datos de Publisher. La propiedad IDENTITY no debe usarse sobre Person.ContactType tabla en la base de datos de suscriptores. De manera similar, podemos modificar las Restricciones o Activadores para que se comporten de manera diferente mientras se configura la Replicación usando esta opción.
- Hay otras 2 columnas NOT NULL disponibles en la tabla.
- La tabla tiene una clave principal definida en ContactTypeId . Solo para recordar, la clave principal es un requisito obligatorio para la replicación. Sin él en una tabla, no podríamos replicar un artículo de tabla.
Ahora, vamos a INSERTAR un registro de muestra en Persona .Tipo de contacto tabla en AdventureWorks_REPL base de datos:
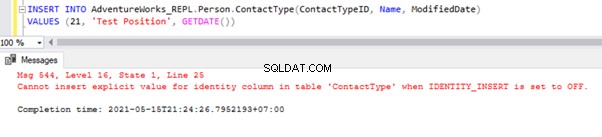
La inserción directa en la tabla fallará en la base de datos del suscriptor porque la propiedad de identidad está deshabilitada solo para la replicación por la opción NO PARA REPLICACIÓN. Cada vez que realizamos la operación INSERT manualmente, aún necesitamos usar la opción SET IDENTITY_INSERT de esta manera:
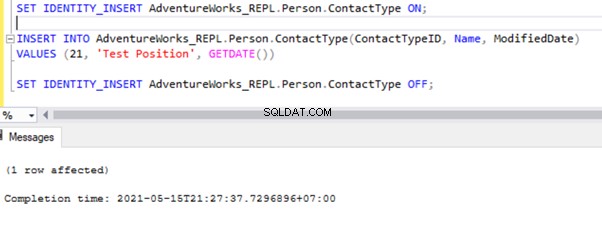
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType ON;
INSERT INTO AdventureWorks_REPL.Person.ContactType(ContactTypeID, Name, ModifiedDate)
VALUES (21, 'Test Position', GETDATE())
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType OFF;
Después de agregar la opción SET IDENTITY_INSERT, podemos INSERTAR el registro con éxito en Person.ContactType mesa.
Al ejecutar SELECCIONAR en la tabla, se muestra el registro recién insertado:
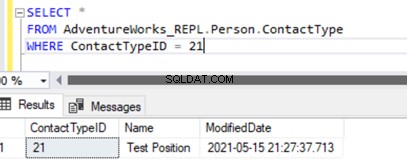
Hemos agregado un nuevo registro solo a la base de datos de suscriptores que no está disponible en la base de datos de editores en Person.ContactType mesa.
Ejecutar un SELECT en la misma tabla de la base de datos de Publisher no muestra ningún registro. Por lo tanto, los cambios realizados en la base de datos del suscriptor no se replican en la base de datos del publicador.
Cambio 2:Eliminación de 2 registros de la tabla Person.ContactType
Nos ceñimos a nuestro familiar Person.ContactType mesa. Antes de eliminar registros de la base de datos del Suscriptor, debemos verificar si esos registros existen tanto en el Publicador como en el Suscriptor. Ver a continuación:
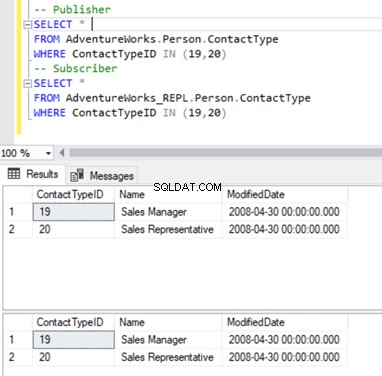
Ahora, podemos eliminar estos 2 ContactTypeId usando la siguiente declaración:
DELETE FROM AdventureWorks_REPL.Person.ContactType
WHERE ContactTypeID IN (19,20)
El script anterior nos permite eliminar 2 registros de Person.ContactType tabla en la base de datos de suscriptores:
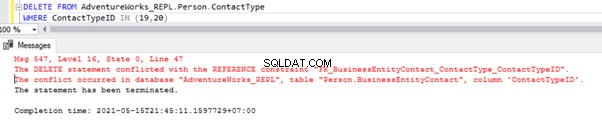
Tenemos la referencia de clave externa que evita la eliminación de estos 2 registros del Person.ContactType mesa. Podemos manejar este escenario desactivando temporalmente la restricción de clave externa en la tabla secundaria. El guión está a continuación:
ALTER TABLE [Person].[BusinessEntityContact] NOCHECK CONSTRAINT [FK_BusinessEntityContact_ContactType_ContactTypeID];
Una vez que las claves foráneas están deshabilitadas, podemos eliminar registros con éxito de Person.ContactType tabla:
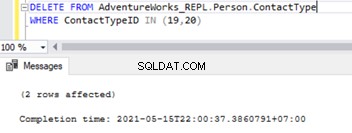
Esto también ha modificado la restricción Referencial de clave externa en las 2 tablas. Podemos intentar simular problemas de replicación de SQL basados en este escenario.
En nuestro escenario actual, sabemos que Person.ContactType la tabla no tenía datos sincronizados entre el publicador y el suscriptor.
Créame, en algunos entornos de producción, los desarrolladores o DBA realizan algunas correcciones de datos en la base de datos del suscriptor. como todos los cambios que realizamos anteriormente, causaron problemas de integridad de datos en las bases de datos del publicador y del suscriptor en la misma tabla. Como DBA, necesito un mecanismo más simple para verificar este tipo de discrepancias. De lo contrario, la vida del DBA sería patética.
Aquí viene la solución de Microsoft que nos permite verificar las discrepancias de datos entre las tablas en el Publicador y el Suscriptor. Sí, lo has adivinado bien. Es la utilidad TableDiff de la que hablamos en artículos anteriores.
Utilidad TableDiff
La utilidad TableDiff se utiliza principalmente en entornos de replicación. También podemos usarlo para otros casos en los que necesitamos comparar 2 tablas de SQL Server para la no convergencia. Podemos compararlos e identificar las diferencias entre estas 2 tablas. Luego, la utilidad ayuda a sincronizar el Destino mesa a la Fuente mesa generando los scripts INSERT/UPDATE/DELETE necesarios.
TableDiff es un programa independiente tablediff.exe instalado de forma predeterminada en C:\Program Files\Microsoft SQL Server\130\COM una vez que hayamos instalado los componentes de replicación. Tenga en cuenta que la ruta predeterminada puede variar según los parámetros de instalación de SQL Server. El número 130 en la ruta indica la versión de SQL Server (SQL Server 2016). Por lo tanto, variará para cada versión diferente de la instalación de SQL Server.
Puede acceder a la utilidad TableDiff a través del símbolo del sistema o solo desde archivos por lotes. La utilidad no tiene un asistente elegante o una GUI para usar. La sintaxis detallada de la utilidad TableDiff se encuentra en el artículo de MSDN. Nuestro artículo actual se centra solo en algunas opciones necesarias.
Para comparar 2 tablas con la utilidad TableDiff, debemos proporcionar detalles obligatorios para las tablas de origen y destino, como el nombre del servidor de origen, el nombre de la base de datos de origen, el nombre del esquema de origen, el nombre de la tabla de origen, el nombre del servidor de destino, el nombre de la base de datos de destino, el destino Nombre del esquema y Nombre de la tabla de destino.
Intentemos probar TableDiff con Person.ContactType tabla que tiene diferencias entre el publicador y el suscriptor.
Abra el símbolo del sistema y navegue hasta la ruta de la utilidad TableDiff (si esa ruta no se agrega a las variables de entorno).
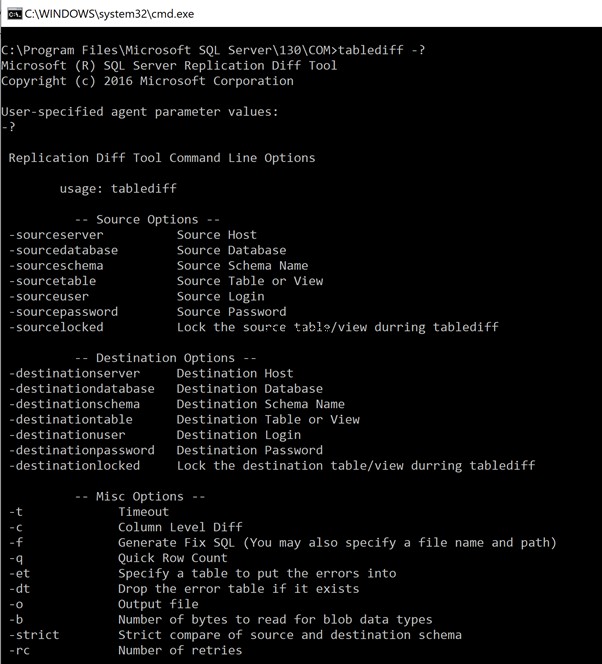
Para ver la lista de todos los parámetros disponibles, escriba el comando "tablediff-?" para enumerar todas las opciones y parámetros disponibles. Los resultados están a continuación:
Verifiquemos la Persona.Tipo de contacto tabla en nuestras bases de datos de editores y suscriptores ejecutando el siguiente comando:
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactTypeTenga en cuenta que no he proporcionado el sourceuser , contraseña de origen , usuario de destino y contraseña de destino ya que mi inicio de sesión de Windows tiene acceso a las tablas. Si desea utilizar las credenciales de SQL en lugar de la autenticación de Windows, los parámetros anteriores son obligatorios para acceder a las tablas de comparación . De lo contrario, recibirá errores.
Los resultados de la correcta ejecución del comando:
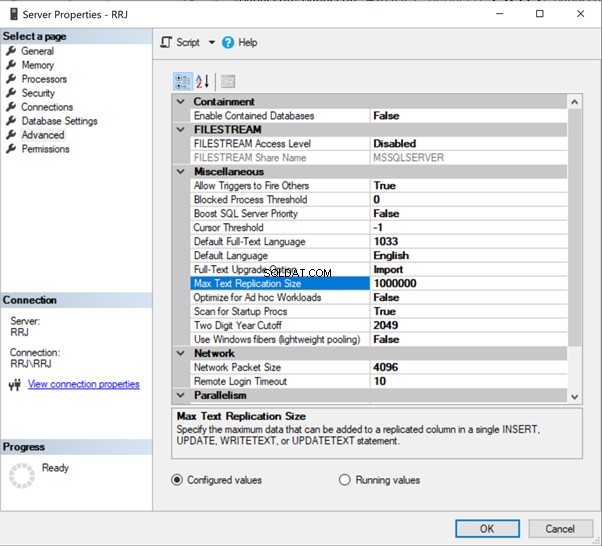
Muestra que tenemos 3 discrepancias. Uno es un registro nuevo en la base de datos de destino y dos registros no están disponibles en la base de datos de destino.
Ahora, echemos un vistazo rápido a los Varios opciones disponibles para la utilidad TableDiff.
- -et – registra el resumen de resultados en la tabla de destino
- -dt – elimina la tabla de destino de resultados si ya existe
- -f – genera un script DML de T-SQL con instrucciones INSERT/UPDATE/DELETE para que la tabla de destino converja con la tabla de origen.
- -o – nombre del archivo de salida si la opción -f se utiliza para generar el archivo de convergencia.
Crearemos un archivo de convergencia con -f y -o opciones a nuestro comando anterior:
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactType -f -o C:\PersonContactType.sqlEl archivo de convergencia se crea correctamente:
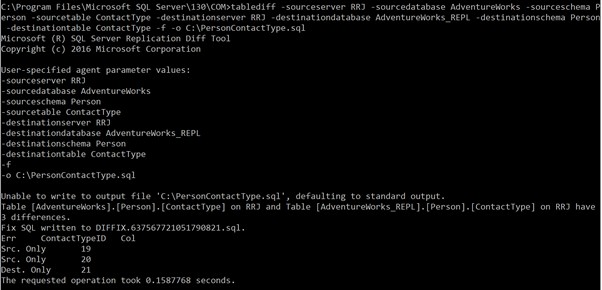
Como puede ver, la creación de un nuevo archivo en la carpeta raíz de la unidad C:no está permitida por razones de seguridad. Por lo tanto, muestra un mensaje de error y crea el archivo de salida Archivo DIFFIX.*.sql en la carpeta de la utilidad TableDiff. Cuando abrimos ese archivo, podemos ver los siguientes detalles:

Los scripts INSERT se crearon para los 2 registros eliminados y los scripts DELETE se crearon para los registros recién insertados en la base de datos del Suscriptor. La herramienta también se preocupa por usar las opciones IDENTITY_INSERT según sea necesario para el Destino mesa. Por lo tanto, esta herramienta será de gran utilidad cuando un DBA necesite sincronizar dos tablas.
En nuestro caso, no ejecutaré los scripts, ya que necesitamos estas variaciones para simular nuestros problemas de replicación de SQL.
Ventajas de la utilidad TableDiff
- TableDiff es una utilidad gratuita que se incluye como parte de la instalación de los componentes de replicación de SQL Server para utilizarse en la comparación o convergencia de tablas.
- Los scripts de creación de convergencia se pueden crear sin intervención manual.
Limitaciones de la utilidad TableDiff
- La utilidad TableDiff solo se puede ejecutar desde el símbolo del sistema o el archivo por lotes.
- Desde el símbolo del sistema, solo puede realizar una comparación de tablas a la vez, a menos que tenga varios símbolos del sistema abiertos en paralelo para comparar varias tablas.
- La tabla de origen que necesita comparar con la utilidad TableDiff requiere una clave principal o una columna de identidad definida, o la columna ROWGUID disponible para realizar la comparación fila por fila. Si el -estricto se utiliza la opción, la tabla de destino también requiere una clave principal, una columna de identidad o la columna ROWGUID disponible.
- Si la tabla de origen o de destino contiene la sql_variant columna de tipo de datos, no puede usar la utilidad TableDiff para compararla.
- Se pueden notar problemas de rendimiento al ejecutar la utilidad TableDiff en tablas que contienen registros grandes, ya que realizará la comparación fila por fila en estas tablas.
- Los scripts de convergencia creados por la utilidad TableDiff no incluyen las columnas de tipo de datos de caracteres BLOB, como varchar(max) , nvarchar(máximo) , varbinario(máximo) , texto , ntext , o imagen columnas y xml o marca de tiempo columnas Por lo tanto, necesita enfoques alternativos para manejar las tablas con estas columnas de tipos de datos.
Sin embargo, incluso con estas limitaciones, la utilidad TableDiff se puede usar en cualquier tabla de SQL Server para una verificación rápida de datos o verificación de convergencia. Sin embargo, también puede comprar una buena herramienta de terceros.
Ahora, consideremos los diversos problemas de replicación de SQL en detalle.
Problemas de configuración
Según mi experiencia, he categorizado las opciones de configuración de replicación que se pasan por alto con frecuencia y que pueden generar problemas críticos de replicación de SQL como Configuración cuestiones. Algunos de ellos están a continuación.
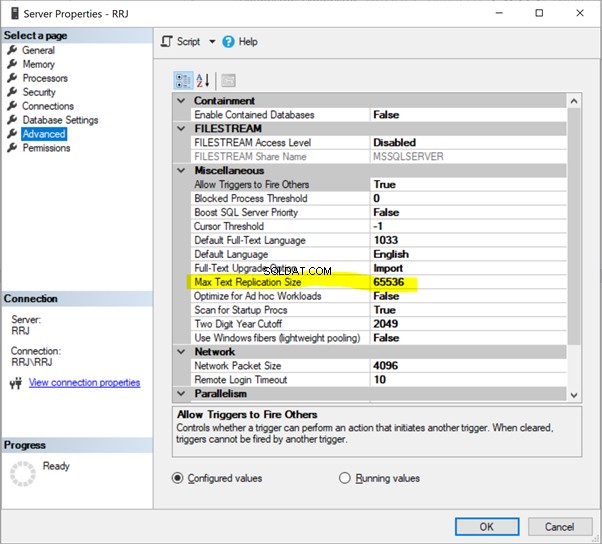
Tamaño máximo de replicación de texto
Tamaño máximo de respuesta de texto hace referencia al tamaño máximo de replicación de texto en bytes . Se aplica a todos los tipos de datos como char(max), nvarchar(max), varbinary(max), text, ntext, varbinary, xml, y imagen .
SQL Server tiene una opción predeterminada para limitar la longitud máxima de la columna del tipo de datos de cadena (en bytes) para que se replique como 65536 bytes.
Necesitamos evaluar el Tamaño máximo de réplica de texto con cuidado siempre que se configure la replicación para una base de datos. Para eso, debemos verificar todas las columnas de tipos de datos anteriores e identificar el máximo de bytes posibles que se transferirán a través de la replicación.
Cambiar el valor a -1 indica que no hay límites. Sin embargo, le recomendamos que evalúe la longitud máxima de la cadena y configure ese valor.
Podemos configurar Max Text Repl Size usando SSMS o T-SQL.
En SSMS, haga clic derecho en el nombre del servidor> Propiedades > Avanzado :
Simplemente haga clic en 65536 para modificarlo. Para las pruebas, cambié 65536 a 1000000 y hice clic en Aceptar :
Para configurar la opción Tamaño máximo de respuesta de texto a través de T-SQL, abra una nueva ventana de consulta y ejecute el siguiente script en la base de datos principal:
EXEC sys.sp_configure N'max text repl size (B)', N'-1'
GO
RECONFIGURE WITH OVERRIDE
GO
Esta consulta permitirá que la replicación no restrinja el tamaño de las columnas de tipos de datos anteriores.
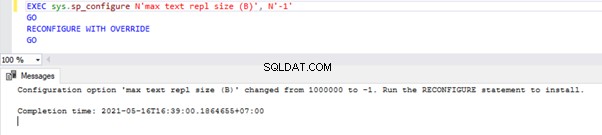
Para verificar, podemos realizar una SELECCIÓN en sys.configurations DMV y verifique el value_in_use columna de la siguiente manera:

El servicio del Agente SQL Server no está configurado para iniciar el modo automático
La replicación se basa en agentes de replicación que se ejecutan como trabajos del Agente SQL Server. Por lo tanto, cualquier problema con algún servicio del Agente SQL Server tendrá un impacto directo en la funcionalidad de replicación.
Necesitamos asegurarnos de que el Modo de inicio de SQL Server y los Servicios del Agente SQL Server estén configurados en Automático. Si se establece en Manual, deberíamos configurar algunas alertas. Notificarían al DBA o a los administradores del servidor para que inicien el servicio del Agente SQL Server cuando el servidor reinicie los planificados o no planificados.
Si no se hace, es posible que la replicación no se ejecute durante mucho tiempo, lo que también afecta a otros trabajos del Agente SQL Server.
Las instancias de replicación no supervisadas entran en un estado de suscripciones no inicializadas
De manera similar a la supervisión del Servicio del Agente SQL Server, la configuración del Servicio de correo electrónico de la base de datos en cualquier instancia de SQL Server desempeña un papel vital para alertar al DBA o a la persona configurada de manera oportuna. Para cualquier error o problema en el trabajo, los trabajos del Agente SQL Server, como el Agente de lectura del registro o el Agente de distribución, se pueden configurar para enviar alertas al DBA o al miembro del equipo respectivo por correo electrónico. La falla en la ejecución del trabajo del Agente de replicación puede dar lugar a los siguientes escenarios:
No ejecución del trabajo del agente de lectura de registros . El archivo de registro de transacciones de la base de datos de Publisher se reutilizará solo después de que el comando marcado para replicación es leído por el Log Reader Agent y enviado correctamente a la base de datos de distribución. De lo contrario, log_reuse_wait_desc columna de sys.databases mostrará el valor como Replicación, lo que indica que el registro de la base de datos no se puede reutilizar hasta que transfiera correctamente los cambios a la base de datos de distribución. Por lo tanto, la no ejecución del agente Log Reader seguirá aumentando el tamaño del archivo de registro transaccional de la base de datos del publicador y encontraremos problemas de rendimiento durante la copia de seguridad completa o problemas de espacio en disco en la instancia de la base de datos del publicador.
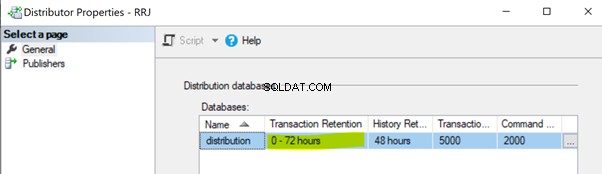
No ejecución del trabajo del agente de distribución. El trabajo del Agente de distribución lee los datos de la base de datos de distribución y los envía a la base de datos del Suscriptor. Luego marca esos registros para su eliminación en la base de datos de distribución. Si el trabajo del Agente de distribución no se está ejecutando, aumentará el tamaño de la base de datos de distribución, lo que provocará problemas de rendimiento en el rendimiento general de la replicación. De manera predeterminada, la base de datos de distribución está configurada para retener registros hasta un máximo de 0 a 72 horas, como se muestra en la propiedad Retención de transacciones a continuación. Si la replicación falla durante más de 72 horas, la suscripción correspondiente se marcará como no inicializada, lo que nos obligará a reconfigurar la suscripción o generar una nueva instantánea para que la replicación vuelva a funcionar.
No ejecución de la limpieza de Distribución:trabajo de distribución . El trabajo de limpieza de distribución es responsable de eliminar todos los registros replicados de la base de datos de distribución para mantener el tamaño de la base de datos de distribución bajo control. La no ejecución de este trabajo conduce al aumento del tamaño de la base de datos de distribución, lo que genera problemas de rendimiento de replicación.
Para garantizar que no nos encontremos con ninguno de estos problemas no supervisados, el correo electrónico de la base de datos debe configurarse para informar todos los errores de trabajo o reintentos a los miembros respectivos del equipo para una acción inmediata.
Problemas conocidos dentro de SQL Server
Ciertas versiones de SQL Server tenían problemas de replicación conocidos en la versión RTM o versiones anteriores. Estos problemas se solucionaron en los paquetes de servicio o paquetes de CU posteriores. Por lo tanto, se recomienda aplicar los Service Packs o CU Packs más recientes una vez que estén disponibles para todos los SQL Server después de probarlos en el entorno de control de calidad. Aunque esta es una recomendación general para servidores que ejecutan SQL Server, también se aplica a la replicación.
Problemas de permisos
En un entorno con la replicación transaccional de SQL Server configurada, podemos observar los problemas de permisos con frecuencia. Es posible que los enfrentemos durante el tiempo de configuración de la replicación o cualquier actividad de mantenimiento en las instancias de la base de datos del publicador, del distribuidor o del suscriptor. Da como resultado la pérdida de credenciales o permisos. Ahora observemos algunos problemas de permisos frecuentes relacionados con la replicación.
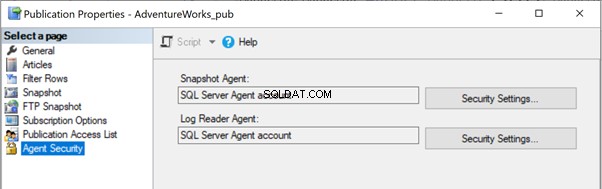
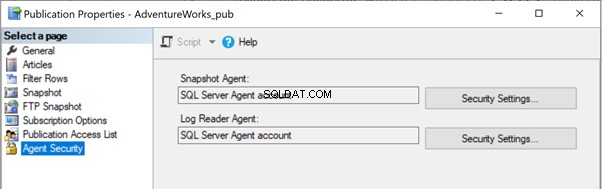
Problemas de permisos de trabajo del Agente SQL Server
Todos los agentes de replicación utilizan trabajos del Agente SQL Server. Cada trabajo del Agente SQL Server relacionado con la Instantánea o el Agente de lectura del registro, o la Distribución se ejecuta con algunas credenciales de inicio de sesión de Windows o SQL, como se muestra a continuación:
Para iniciar un trabajo del Agente SQL Server, debe poseer el SQLAgentOperatorRole para iniciar todos los trabajos o SQLAgentUserRole o el SQLAgentReaderRole para iniciar trabajos de su propiedad. Si algún trabajo no pudo iniciarse correctamente, verifique si el propietario del trabajo tiene los derechos necesarios para ejecutar ese trabajo.
La credencial de trabajo del agente de instantáneas no puede acceder a la ruta de la carpeta de instantáneas
En nuestros artículos anteriores, notamos que la ejecución del agente de instantáneas crearía la instantánea de los artículos en la ruta de la carpeta local o compartida para que se propague a la base de datos del suscriptor a través del agente de distribución. La ubicación de la ruta de la instantánea se puede identificar en Propiedades de la publicación > Instantánea :
Si el agente de instantáneas no tiene acceso a esta ubicación de archivos de instantáneas, es posible que recibamos el error:
Acceso denegado a la ruta 'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\XXXX\YYYYMMDDHHMISS\'.
Para resolver el problema, es mejor otorgar acceso completo a la ruta de la carpeta C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\ para la cuenta en la que se ejecuta el Agente de instantáneas. En nuestra configuración, usamos la cuenta del Agente SQL Server y el Servicio del Agente SQL Server se ejecuta bajo la cuenta RRJ\RRJ.
La credencial de trabajo del agente de lectura de registros no se puede conectar a la base de datos de publicación/distribución
Log Reader Agent se conecta a la base de datos de Publisher para ejecutar sp_replcmds procedimiento para escanear las transacciones que están marcadas para replicación desde los registros de transacciones de la base de datos de Publisher.
Si el propietario de la base de datos de Publisher no está configurado correctamente, es posible que recibamos los siguientes errores:
El proceso no pudo ejecutar 'sp_replcmds' en 'RRJ.
O
No se puede ejecutar como principal de la base de datos porque el principal "dbo" no existe, este tipo de principal no se puede suplantar o no tiene permiso.
Para resolver este problema, asegúrese de que la propiedad del propietario de la base de datos de la base de datos del publicador esté establecida en sa. u otra cuenta válida (ver más abajo).
Haga clic derecho en el Editor base de datos (AdventureWorks )> Propiedades > Archivos . Asegúrese de que el Propietario el campo está establecido en sa o cualquier inicio de sesión válido y no en blanco .
Si se produce algún problema de permisos cuando nos conectamos a la base de datos de distribución o del publicador, verifique las credenciales utilizadas para el agente de lectura del registro y concédales permisos para acceder a esas bases de datos.
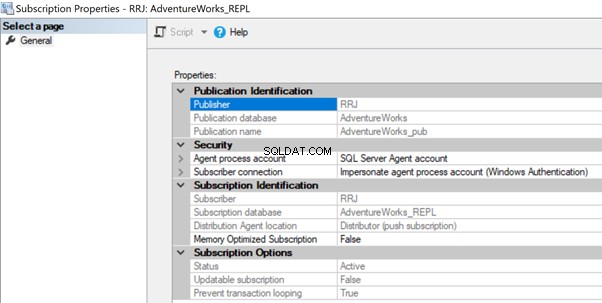
La credencial de trabajo del agente de distribución no se puede conectar a la base de datos de distribución/suscriptor
El agente de distribución puede tener problemas de permisos si la cuenta no puede acceder a la base de datos de distribución o conectarse a la base de datos del suscriptor. En este caso, podemos obtener los siguientes errores:
No se pudo iniciar la ejecución del paso 2 (motivo:error al autenticar el proxy RRJ\RRJ, error del sistema:el nombre de usuario o la contraseña son incorrectos).
El proceso no pudo conectarse al suscriptor 'RRJ.
Error de inicio de sesión para el usuario 'RRJ\RRJ'.
Para resolverlo, verifique la cuenta utilizada en las Propiedades de Suscripción y asegúrese de que tenga los permisos necesarios para conectarse a la base de datos de Distribución o Suscriptor.
Problemas de conectividad
Por lo general, configuramos la replicación transaccional en servidores dentro de la misma red o en ubicaciones distribuidas geográficamente. Si la base de datos de distribución está ubicada en un servidor dedicado aparte del publicador o suscriptor, se vuelve susceptible a pérdidas de paquetes de red:problemas de conectividad.
En caso de tales problemas, los agentes de replicación (lector de registros o agente de distribución) pueden informar los siguientes errores:
No se encontró o no se pudo acceder al servidor del editor
No se encontró o no se pudo acceder al servidor de distribución
No se encontró o no se pudo acceder al servidor del suscriptor
Para solucionar estos problemas, podríamos intentar conectarnos a la base de datos del publicador, el distribuidor o el suscriptor en SSMS para verificar si podemos conectarnos a estas instancias de SQL Server sin problemas o no.
Si los problemas de conectividad ocurren con frecuencia, podemos intentar hacer ping al servidor continuamente para identificar cualquier pérdida de paquetes. Además, tenemos que trabajar con los miembros del equipo necesarios para resolver esos problemas y poner el servidor en funcionamiento para que la replicación reanude la transferencia de datos.
Problemas de integridad de datos
Dado que la replicación transaccional es un mecanismo unidireccional, cualquier cambio de datos que ocurra en el suscriptor (manualmente o desde la aplicación) no se reflejará en el publicador. Podría dar lugar a variaciones de datos entre el publicador y el suscriptor.
Revisemos esos problemas relacionados con la integridad de los datos y veamos cómo resolverlos. Tenga en cuenta que hemos insertado un registro en Person.ContactType tabla y eliminó 2 registros de Person.ContactType tabla en la base de datos de suscriptores. Vamos a usar estos 3 registros para encontrar errores.
Errores de infracción de clave principal o clave única
Voy a probar el registro INSERT en Person.ContactType mesa. Insertemos ese registro en la base de datos de Publisher y veamos qué sucede:
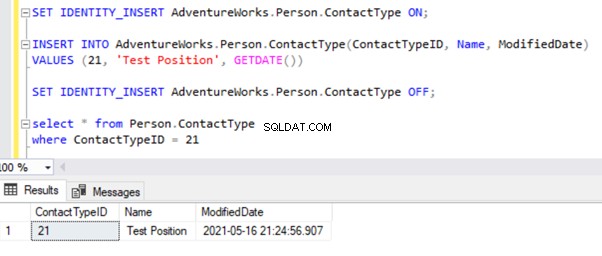
Inicie el Monitor de replicación para ver cómo funciona. Obtenemos el error:
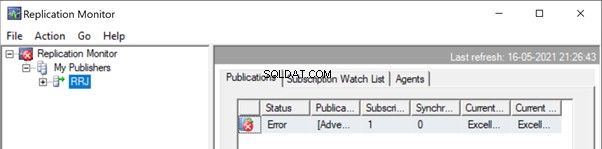
Expansión de Editor y Publicación , obtenemos los siguientes detalles:
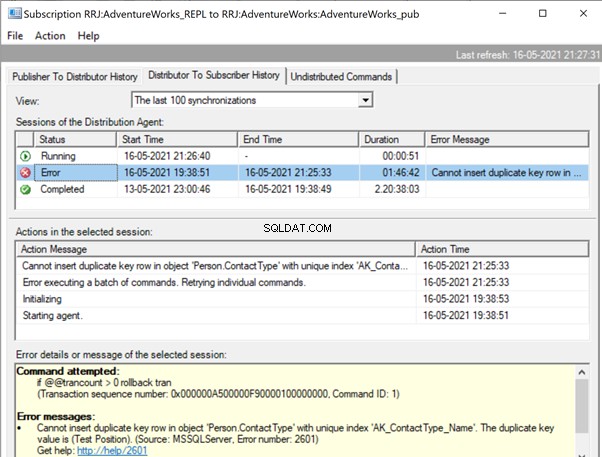
Si configuramos las Alertas de replicación y asignamos a las personas respectivas para que reciban su alerta por correo, recibiremos las notificaciones por correo electrónico correspondientes con el mensaje de error:No se puede insertar una fila de clave duplicada en el objeto 'Person.ContactType' con índice único 'AK_ContactType_Name ' . El valor de la clave duplicada es (Posición de prueba). (Fuente:MSSQLServer, Número de error:2601)
Para resolver el problema relacionado con violaciones de clave única o problemas de clave principal, tenemos varias opciones:
- Analice por qué ocurrió este error, cómo estuvo disponible el registro en la base de datos de suscriptores y quién lo insertó y por qué motivos. Identifique si era necesario o no.
- Agregue los errores de omisión parámetro al perfil del Agente de distribución para omitir Número de error 2601 o Número de error 2627 en caso de violación de la clave principal.
En nuestro caso, insertamos datos a propósito para recibir este error. Para manejar este problema, elimine ese registro insertado manualmente para continuar replicando los cambios recibidos del publicador.
DELETE from Person.ContactType
where ContactTypeID = 21
Para estudiar otras opciones y comparar las diferencias entre estos dos enfoques, me salteo la primera opción (que es eficiente y recomendada) y paso a la segunda opción agregando los -skipererrors parámetro al trabajo del Agente de distribución.
Podemos implementarlo editando el trabajo del agente de distribución > Pasos > haga clic en 2 pasos de trabajo llamados Ejecutar agente > haz clic en Editar para ver el comando disponible:
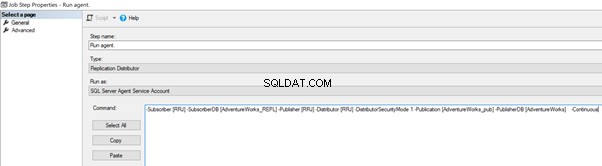
Ahora, agregue -SkipErrors 2601 palabra clave al final (2601 es el número de error; podemos omitir cualquier número de error recibido como parte de la replicación) y haga clic en Aceptar .
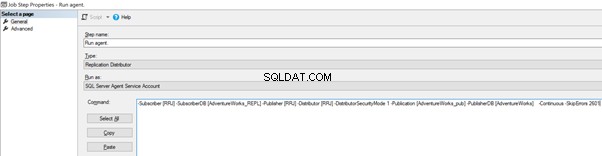
To make sure that the Distribution job is aware of this configuration change, we need to restart the Distribution agent job. For that, stop it and start again from Step 1 as shown below:
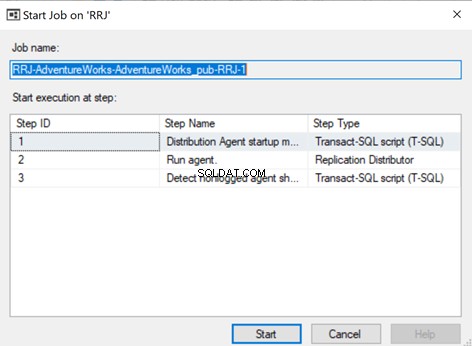
The Replication Monitor displays that one of the error records is skipped from the Replication, that started working fine.
Since the Replication issue is resolved successfully, we’d recommend removing the -SkipErrors parameter from the Distribution Agent job. Then, restart the job to get the changes reflected.
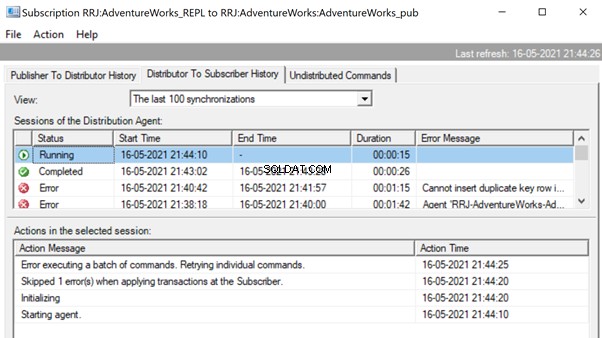
Thus, we’ve fixed the replication issue, but let’s compare the data across the same Person.ContactType in the Publisher and Subscriber databases. The results show the data variance, or the data integrity issue :
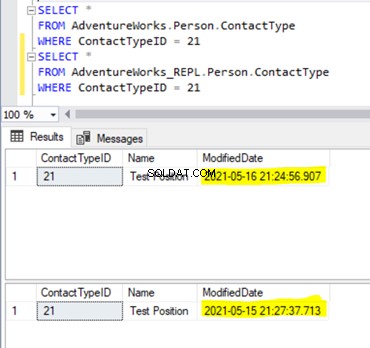
ModifiedDate is different across the Publisher and Subscriber databases. It happens because the data in the Subscriber database was inserted earlier (when we were preparing the test data), and the data in the Publisher database has just been inserted.
If we deleted the record from the Subscriber database, the record from the Publisher would have been inserted to match the data across the Publisher and the Subscriber databases.
Most of the newbie DBAs simply add the -SkipErrors option to get the replication working immediately without detailed investigations of the issue. Hence, it is recommended not to use the -SkipErrors option as a primary solution without proper examination of the problem. The Person.ContactType table had only 3 columns. Assume that the table has over 20 columns. Then, we have just screwed up the Data integrity of this table with that -SkipErrors comando.
We used this approach just to illustrate the usage of that option. The best way is to examine and clarify the reason for variance and then perform the appropriate DELETE statements on the Subscriber database to maintain the Data Integrity across the Publisher and Subscriber databases.
Row Not Found Errors
Let’s try to perform an UPDATE on one of the records that were deleted from the Subscriber database:
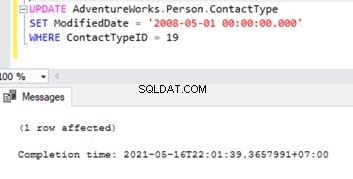
Let’s check the Replication Monitor to see the performance. We have the following error:
The row was not found at the Subscriber when applying the replicated UPDATE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =19 (Source:MSSQLServer, Error number:20598).
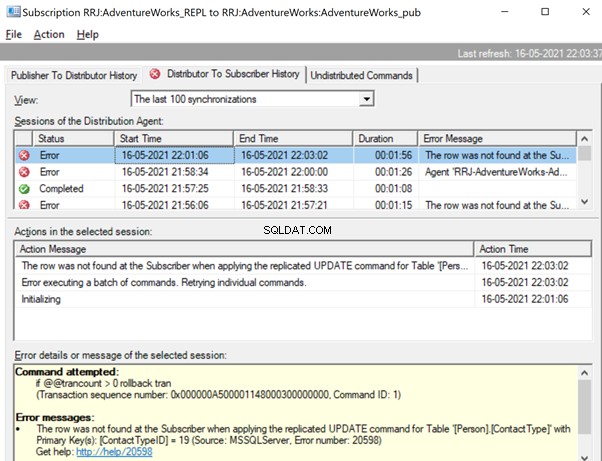
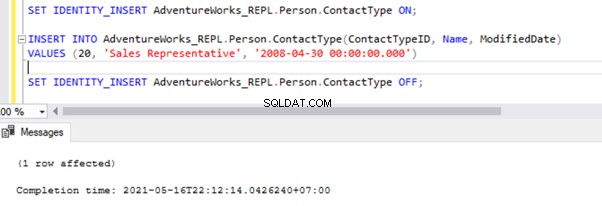
There are two ways to resolve this error. First, we can use -SkipErrors for Error Number 20598 . Or, we can INSERT the record with ContactTypeID =19 (shown in the error message) to get the data changes reflected.
If we skip this error, we’ll lose the record with ContactTypeId =19 from the Subscriber database permanently. It can cause data inconsistency issues. Hence, we aren’t going to use the -SkipErrors opción. Instead, we’ll apply the INSERT approach.
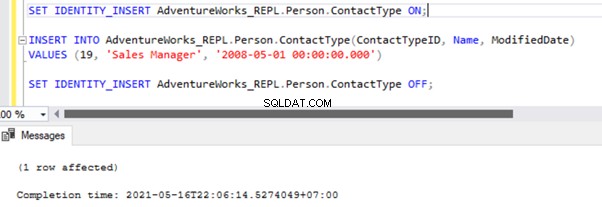
The Replication resumes correctly by sending the UPDATE to the Subscriber database.
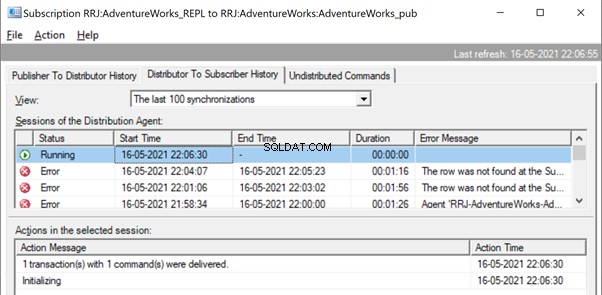
It is the same when we try to delete the ContactTypeId =20 from the Publisher database and see the error popping up in the Replication Monitor.
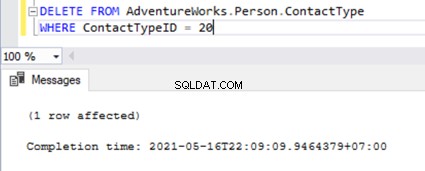
The Replication Monitor shows us a message similar to the one we already noticed:
The row was not found at the Subscriber when applying the replicated DELETE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =20 (Source:MSSQLServer, Error number:20598)
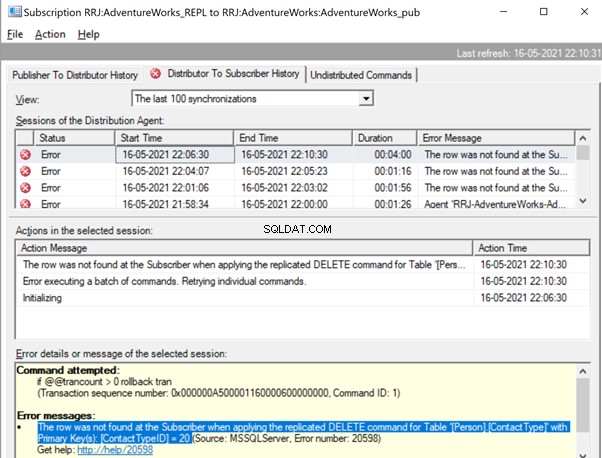
Similar to the previous error, we need to identify the missing record and insert it back to the Subscriber database for the DELETE statement to get replicated properly. For DELETE scenario, using -SkipErrors doesn’t have any issues but can’t be considered as a safe option, as both missing UPDATE or missing DELETE record are captured with the same error number 20598 and adding -SkipErrors 20598 will skip applying all records from the Subscriber database.
We can also get more details about the problematic command by using the sp_browsereplcmds stored procedure which we have discussed earlier as well. Let’s try to use sp_browsereplcmds stored procedure for the previous error we have received out as shown below.

exec sp_browsereplcmds @xact_seqno_start = '0x000000A500001160000600000000'
, @xact_seqno_end = '0x000000A500001160000600000000'
, @publisher_database_id = 1
, @command_id = 1
@xact_seqno_start and @xact_seqno_end will be the same value. We can fetch that value from the Transaction Sequence number in the Replication Monitor along with Command ID.
@publisher_database_id can be fetched from the id column of the distribution..MSPublisher_databases DMV.
select * from MSpublisher_databases Foreign Key or Other Constraint Violation Errors
The error messages related to Foreign keys or any other data issues are slightly different. Microsoft has made these error messages detailed and self-explanatory for anyone to understand what the issue is about.
To identify the exact command that was executed on the Publisher and resolve it efficiently, we can use the sp_browsereplcmds procedure explained above and identify the root cause of the issue.
Once the commands are identified as INSERT/UPDATE/DELETE which caused the errors, we can take corresponding actions to resolve the problems correctly which is more efficient compared to simply adding -SkipErrors approach. Once corrective measures are taken, Replication will start resuming fine immediately.
Word of Caution Using -SkipErrors Option
Those who are comfortable using -SkipErrors option to resolve error quickly should remember that -SkipErrors option is added at the Distribution agent level and applies to all Published articles in that Publication. Command -SkipErrors will result in skipping any number of commands related to that particular error across all published articles any number of times resulting in discrepancies we have seen in demo resulting in data discrepancies across Publisher and Subscriber without knowing how many tables are having discrepancies and would require efforts to compare the tables and fix it out.
Conclusión
Thanks for going through another robust article. I hope it was helpful for you to understand the SQL Server Transactional Replication issues and methods of troubleshooting them. In our next article, we’ll continue the discussion about the SQL Transaction Replication issues, examine other types, such as Corruption-related issues, and learn the best methods of handling them.