En nuestros blogs de nube híbrida anteriores, a menudo mencionamos que una de las opciones principales para aprovechar la configuración de topología de nube híbrida es usarla como su objetivo de recuperación ante desastres. Es común para una estructura organizacional que siempre se aborde un Plan de recuperación ante desastres (DRP) antes de la implementación arquitectónica de la configuración de su base de datos, ya sea en la nube o en las instalaciones. Puede pensar que todo fallará de manera impredecible y puede afectar trágicamente su negocio si no se aborda y comprende correctamente. Superar estos desafíos requiere un DRP (Plan de Recuperación de Desastres) efectivo, para el cual su sistema está bien configurado de acuerdo con su aplicación, infraestructura y requisitos comerciales. La clave del éxito en este tipo de situaciones es qué tan rápido podemos solucionar o recuperarnos del problema.
Si bien DRP aborda las circunstancias del desastre, Business Continuity se asegurará de que DRP esté probado y operativo en todo momento cuando sea necesario. Sus opciones de recuperación ante desastres para sus bases de datos deben garantizar operaciones continuas y límites a los límites de las expectativas. Tiene que estar en línea con su RTO y RPO deseados. Es imperativo garantizar que las bases de datos de producción estén disponibles para las aplicaciones incluso durante desastres; de lo contrario, podría terminar siendo un trato costoso. Los DBA, los arquitectos, deben asegurarse de que los entornos de base de datos puedan soportar desastres y cumplan con los SLA de recuperación ante desastres. Las implementaciones de bases de datos deben configurarse correctamente para garantizar que los desastres no afecten la disponibilidad de la base de datos y la continuidad del negocio.
Opciones de recuperación ante desastres
Su clúster de PostgreSQL debe configurarse con un enfoque sistemático que se comprometa con las mejores prácticas y sea aceptable para los estándares de la industria. Junto con los enfoques sistemáticos, los siguientes procesos o mecanismos lo ayudan a garantizar que su PostgreSQL implementado en una nube híbrida tenga estas presencias:
-
Failover/Switchover
-
Copia de seguridad automatizada
-
Alta disponibilidad
-
Equilibrio de carga
-
Entorno altamente distribuido
Conmutación por error/Conmutación
Failover es un proceso automatizado en caso de que su maestro falle; el servidor en espera en caliente o en espera en caliente se promociona al rol de primario/maestro. Es una práctica recomendada que permite un entorno de alta disponibilidad tener al menos un nodo secundario que actúe como candidato para un nodo de conmutación por error. Una vez que el servidor principal falla, el servidor en espera debe comenzar los procedimientos de conmutación por error, y luego el servidor secundario o en espera asumirá el rol de maestro. Un sistema de conmutación por error utiliza un mínimo de dos servidores en la práctica común, que sirve como principal y de reserva. Su comprobación de conectividad está asistida por un mecanismo de latido que realiza comprobaciones continuas y verifica si ambos están en buen estado y la comunicación está activa. Sin embargo, en algunos casos, la conectividad puede dar una falsa alarma. Por lo tanto, en algunas configuraciones y entornos, la presencia de un tercer sistema, como un nodo de monitoreo, se encuentra en una red o centro de datos separado. Esta es una opción infalible para evitar una conmutación por error inapropiada o no deseada. Un nodo de verificación infalible puede poseer funciones y controles adicionales, lo que agrega complejidad. Esta configuración requiere pruebas completas y rigurosas para garantizar que la conmutación por error se realice correctamente cuando haya un cambio en la implementación. Además, esto es importante para evitar cualquier deterioro de su PostgreSQL
Supongamos que tiene su clúster secundario o en espera en un centro de datos diferente con una configuración de hardware diferente; es posible que no desee realizar una conmutación por error abruptamente, especialmente si no es un caso ideal debido a un falso positivo. Sin embargo, en este escenario, su nodo o clúster de destino de recuperación de datos debe tener los mismos recursos y especificaciones que su nodo o clúster principal. Si su objetivo de recuperación de datos está en una nube pública y el principal está en las instalaciones, asegúrese de que ya se haya cubierto en su planificación de capacidad y que los recursos tengan casi las mismas especificaciones para evitar resultados no deseados.
Al utilizar y prepararse para su mecanismo de conmutación por error en su clúster de PostgreSQL dentro de una nube híbrida, debe asegurarse de que su herramienta sea la opción perfecta para llevar a cabo el trabajo que se supone debe realizar. Hay herramientas de terceros que no están incluidas en PostgreSQL con respecto a la conmutación por error avanzada. Por ejemplo, está ClusterControl, pg_auto_failover de CitusData (c/o Microsoft), Pgpool-II, Bucardo y otros. Estas herramientas de utilidades avanzadas proporcionan cercado de nodos o conocido como STONITH (disparar al otro nodo en la cabeza). Esto garantiza que su nodo principal o maestro fallido evite aceptar escrituras o volver a estar en línea como su estado anterior para atender transacciones normales. Este problema se conoce comúnmente como escenario de cerebro dividido. Pierde la sincronización de datos debido a una falla (hardware o nivel de recursos), pero aún así sus servidores primarios, que supuestamente es solo un servidor primario, actúan como si fueran destinatarios normales de solicitudes de escritura de datos, lo que provoca corrupción de datos en todo el clúster.
Copia de seguridad automatizada
Las copias de seguridad siempre brindan una alta seguridad y protección contra la pérdida de datos. La copia de seguridad maximiza su RPO ya que ayuda a minimizar la pérdida de datos cuando ocurre un desastre. Las cosas que debe considerar y preparar para su copia de seguridad automatizada cubren su dispositivo/hardware de copia de seguridad, redundancia de datos de copia de seguridad, seguridad, rendimiento, velocidad y almacenamiento de datos.
Dispositivo de copia de seguridad
Debe tener aquí la mejor opción para su dispositivo de copia de seguridad. La velocidad, el volumen de almacenamiento significativo y la alta disponibilidad pueden ser su elección deseada. Algunos confían en el almacenamiento SAN o NAS o distribuyen sus datos a otros proveedores de almacenamiento de respaldo de terceros. Es esencial que su dispositivo de respaldo ofrezca velocidad para escribir y leer datos, especialmente si aplica compresión y encriptación para sus datos en reposo. La descompresión y el descifrado requieren recursos, por lo que debe considerar cuándo debe utilizar la recuperación de datos. Durante este estado, debe determinar que debe alcanzar su RPO máximo y comprometerse con el SLA (acuerdo de nivel de servicio) alcanzable con sus clientes. También es ideal que tenga que aislar su copia de seguridad de su red local o almacenarla en una ubicación remota. Un enfoque alternativo es comprometerse con proveedores externos. Por ejemplo, almacenar su copia de seguridad en la nube puede ser una opción, y su instalación es muy sofisticada y satisface sus requisitos.
Redundancia de datos de respaldo
Difundir sus datos en varias ubicaciones es una solución ideal. Esto fortalece sus posibilidades de recuperación de datos, por ejemplo, un error humano o un error de lógica de software que le hace eliminar copias antiguas de la copia de seguridad pero elimina por error todas las copias de seguridad cruciales. En algunos entornos sofisticados, como el almacenamiento en un entorno de nube como Amazon S3, Cloud Storage de Google o Azure Blob Storage ofrece la replicación de su archivo almacenado. Esto proporciona más redundancia y se puede configurar de una manera flexible que se ajuste a sus requisitos.
Altamente disponible
Un clúster de PostgreSQL de alta disponibilidad en una nube híbrida siempre asegura que la comunicación de su base de datos garantice el tiempo de actividad. El caso ideal de alta disponibilidad depende de la medida de su disponibilidad. En este caso, una configuración común para un PostgreSQL implementado en una nube híbrida puede ser que su base de datos alojada en una nube pública sea su clúster secundario que actúe como su clúster de recuperación de datos en caso de que el clúster principal falle o sufra un desastre en la red y pueda tomar mucho tiempo de inactividad. En alguna configuración, es posible que el clúster secundario que se encuentra en la nube pública no sea exactamente tan sofisticado como el principal, digamos que esta es su nube local o privada. Su aplicación puede jugar para limitar los visitantes o el tráfico que puede conectarse a su base de datos. Este tipo de escenario puede reducir su costo de configuración, pero por supuesto, esto solo depende de sus requisitos. Si su tipo de aplicación es masiva y tiene que recibir situaciones de tráfico de normal a intensa sin parar, asegúrese de que los recursos de su clúster secundario tengan la misma potencia que el principal para garantizar una alta disponibilidad, es decir, 99,9999999 %.
Para lograr un clúster PostgreSQL de alta disponibilidad en un entorno de nube híbrida, debe tener un mecanismo de conmutación por error. En caso de falla y un clúster primario o un servidor primario deja de funcionar, un servidor secundario o en espera puede asumir el rol de maestro, cualquiera que sea su ubicación. Lo más importante es la funcionalidad y el rendimiento, especialmente desde el punto de vista de la aplicación o del cliente, no se ve afectado en absoluto o al menos es mínimo.
Equilibrio de carga
El mecanismo de equilibrio de carga para su clúster de PostgreSQL ayuda a su configuración de nube híbrida, que es más manejable y menos riesgosa, especialmente cuando se produce una alta carga de tráfico. En muchas situaciones, un servidor recibe una carga muy alta que hace que el servidor entre en pánico. Esto conduce a un estado inutilizable del servidor debido a los recursos ocupados consumidos por muchos subprocesos que se ejecutan en segundo plano. Esta situación se puede mejorar arreglando las consultas incorrectas y la arquitectura de diseño de su base de datos. Esto debe incluir cómo distribuye la lectura contra la carga de escritura y una comprensión profunda de los requisitos de su aplicación, como la configuración maestro-maestro o solo un maestro, pero escalando verticalmente para proporcionar mayores recursos informáticos y de memoria. También hay una gran selección de herramientas de terceros, como pgbouncer y Pgpool II, para ayudarlo con su implementación de PostgreSQL en un entorno de nube híbrida.
Entorno altamente distribuido
En cuanto a la escalabilidad, estar altamente distribuido en múltiples ubicaciones o diferentes proveedores de nube (en las instalaciones o en la nube privada y pública) brinda más flexibilidad y tolerabilidad en un entorno de nube híbrida y esto es excelente para la recuperación ante desastres. Es flexible cuando necesita conmutación por error en una ubicación de nube particular favorable a un desastre natural o una catástrofe, especialmente si su región designada donde reside su clúster principal está actualmente devastada o afectada por una causa natural. Esta es una causa inevitable que debe comprender y ser confiable de la situación actual. Su aplicación y sus clientes deben ser atendidos continuamente sin parar. Esto tiene el propósito de estar disponible públicamente en la nube y, al mismo tiempo, servir en un entorno privado o local. Esta configuración agrega una mayor complejidad y requiere conocimientos avanzados en el lado de la base de datos y la seguridad y las redes. La optimización y el ajuste son cruciales para el éxito aquí, ya que es muy importante que, si bien brinda una seguridad más estricta para encapsular sus datos mientras viaja por Internet, se debe demostrar que el rendimiento se estabiliza y no se ve afectado por la configuración implementada.
Debido a la complejidad de la configuración, tener una herramienta es ideal para administrar la implementación y facilitar el estado general de sus bases de datos, supervisando un aspecto de su clúster pero en todo el nivel desde la nube privada local, y en el aspecto de la nube pública. Todas las configuraciones deben mantenerse en un nivel manejable y sencillo para que, en caso de alarmas y alertas, sea fácil solucionar y abordar el problema de manera adecuada y oportuna.
ClusterControl para recuperación ante desastres en un entorno de nube híbrida
ClusterControl permite que la organización o las empresas administren la base de datos con flexibilidad y reduzcan la complejidad general de la configuración. ClusterControl ofrece conmutación por error, respaldo automatizado, proporciona una configuración de alta disponibilidad, equilibrio de carga y admite una implementación de entorno distribuido, lo que facilita agregar nodos en una nube pública o privada o local.
Recuperación automática de ClusterControl
La recuperación automática de ClusterControl representa toneladas de mecanismo de conmutación por error y características de recuperación, especialmente cuando un nodo deja de funcionar o un clúster entra en un estado degradado. Esto se puede hacer fácilmente como se muestra en la siguiente captura de pantalla:
Copia de seguridad y restauración
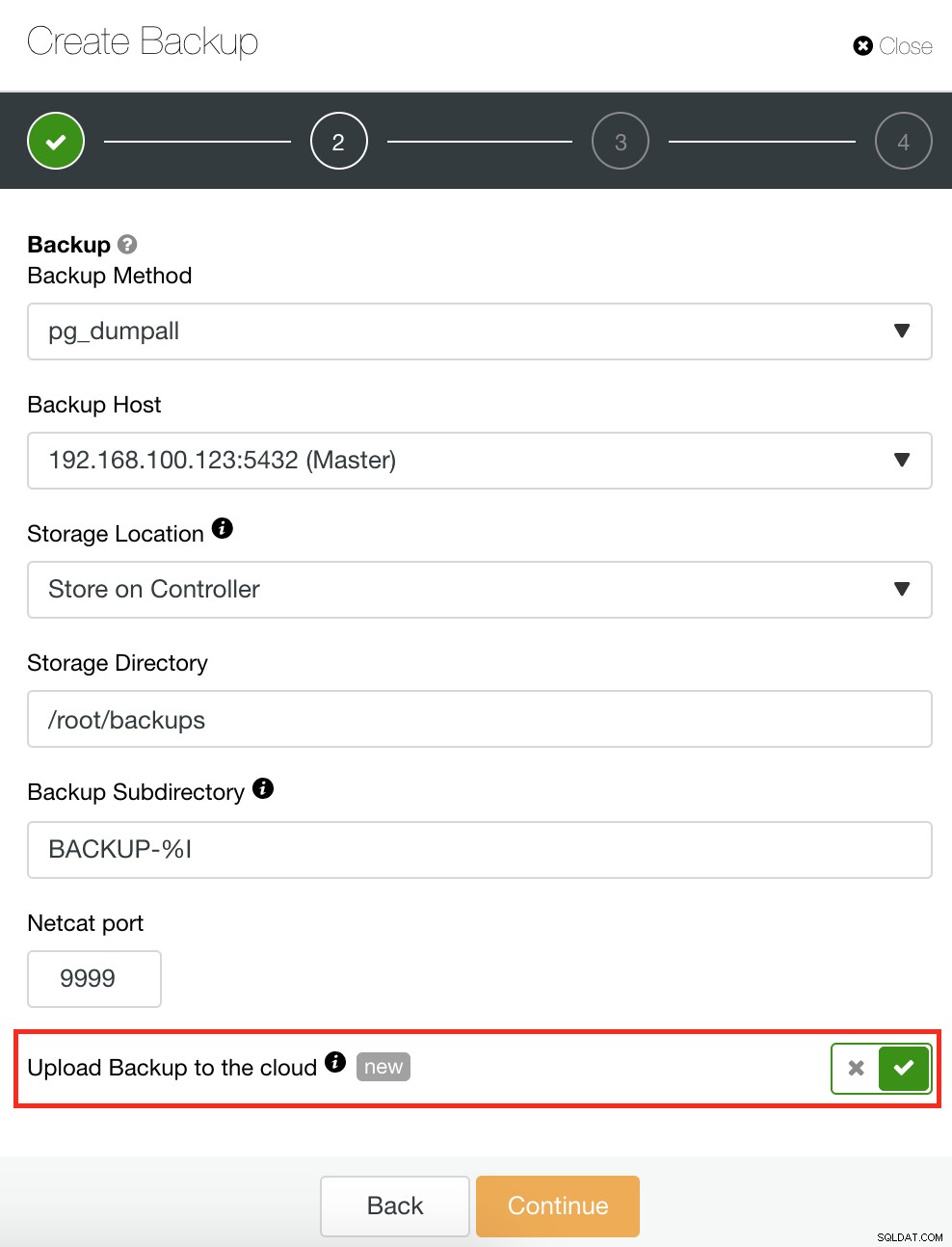
ClusterControl también tiene una función de copia de seguridad y restauración que le permite administrar su copia de seguridad, crear una copia de seguridad, programar una copia de seguridad y restaurar una copia de seguridad. Administrar su copia de seguridad es muy sencillo y crear o programar una copia de seguridad es simple pero también ofrece opciones avanzadas. También ofrece opciones de respaldo en la nube que le permiten tener redundancia de datos de respaldo, fortaleciendo sus opciones de recuperación ante desastres. Ver a continuación:
Como se muestra a continuación, la administración de su copia de seguridad proporciona una interfaz de usuario simple para que pueda seleccionar qué copia de seguridad desea restaurar, o puede que tenga que descartarla. La copia de seguridad de ClusterControl le permite elegir un período de retención, por lo que, en caso de que tenga una lista larga, algunos de estos pueden eliminarse cuando alcance su período de retención. 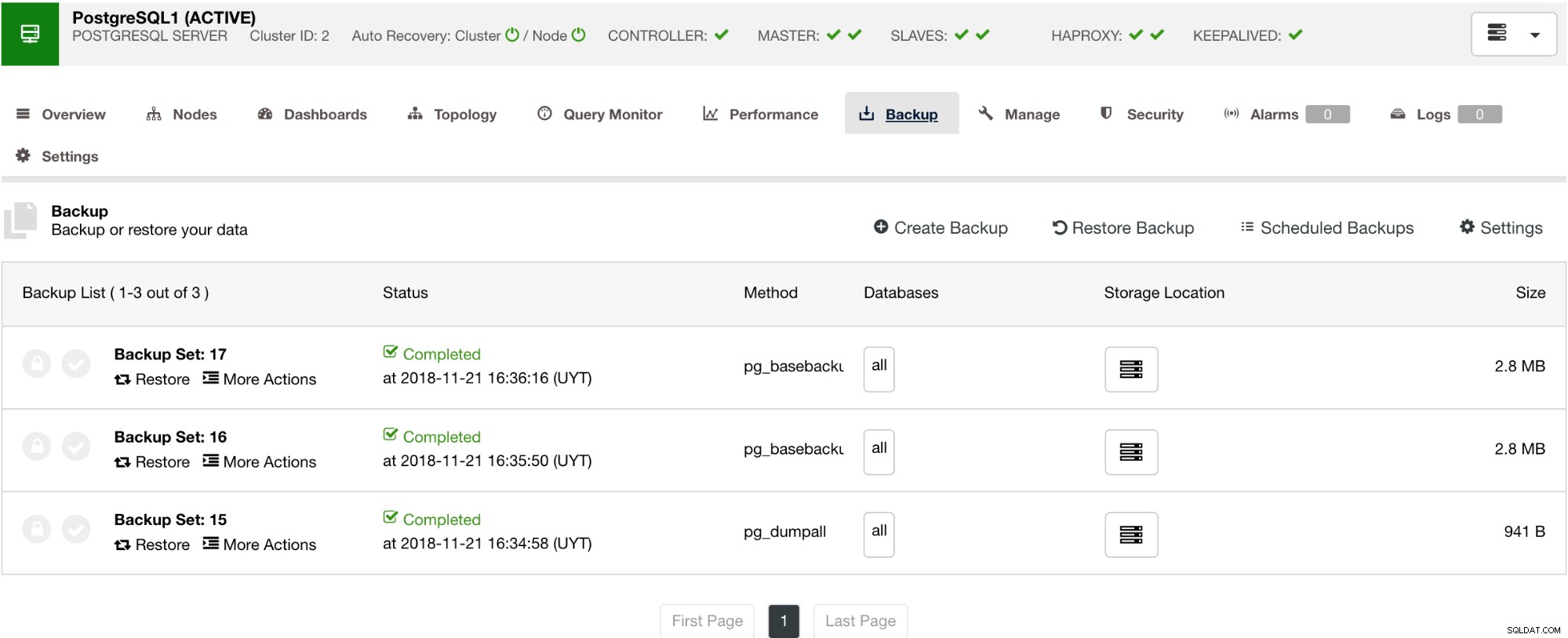
Admite mecanismos de alta disponibilidad (HA) y equilibrio de carga (LB)
No necesita configurar manualmente ni siquiera investigar algunas formas de agregar alta disponibilidad en su clúster de PostgreSQL. Hay una manera fácil y conveniente de hacer el trabajo con ClusterControl. Si puede ver la captura de pantalla de ejemplo, tiene una configuración HAProxy y Keepalived. Vea la captura de pantalla a continuación:
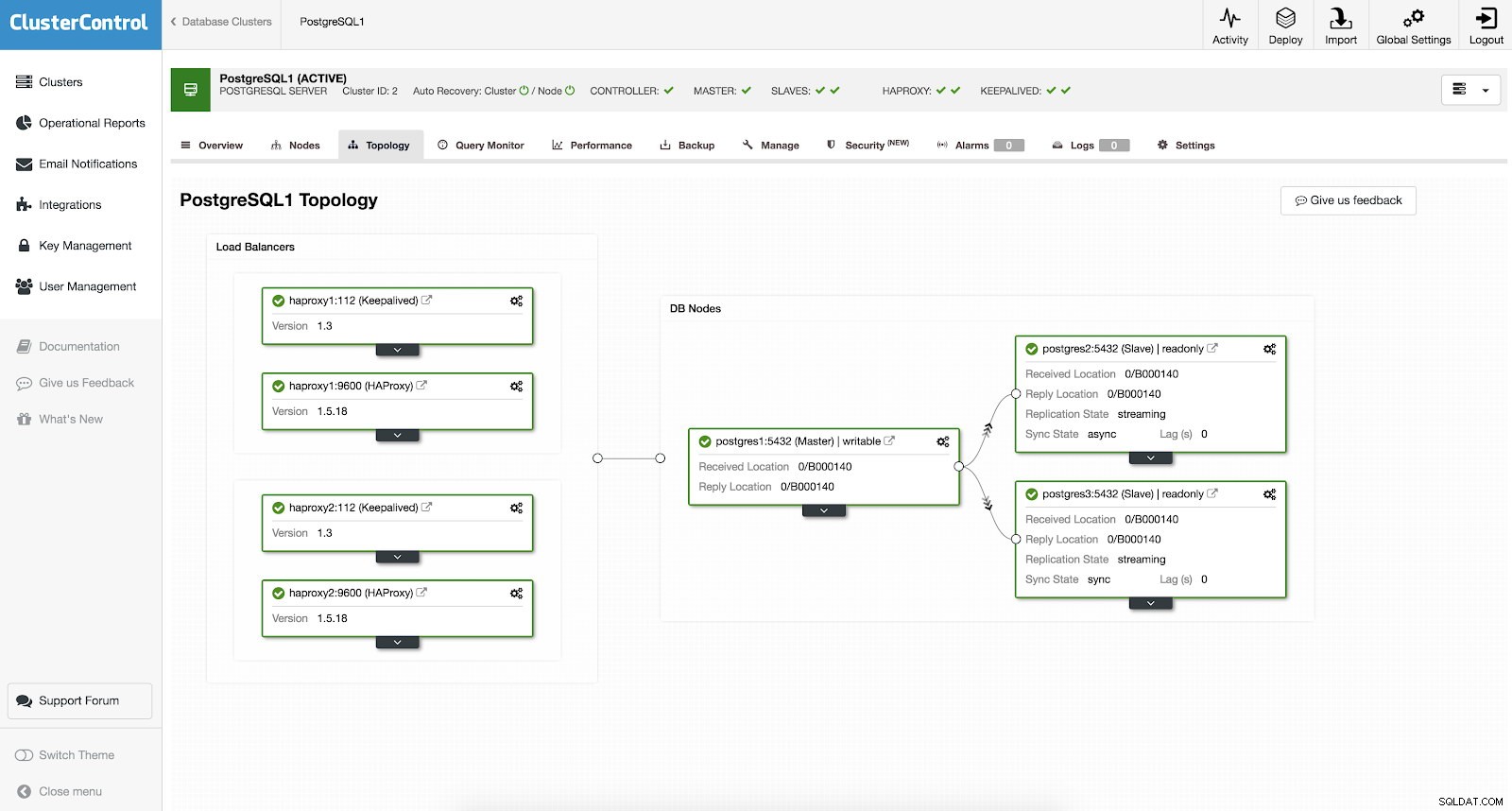
La configuración de una alta disponibilidad con ClusterControl se puede realizar accediendo a
Admite entorno distribuido
Si desea tener distribuciones uniformes desde la nube local o privada a la nube pública, ClusterControl también es compatible con la implementación en la nube. Pero para un clúster de PostgreSQL y planea tener un esclavo secundario que resida en una nube diferente, puede crear un clúster esclavo como se muestra a continuación,
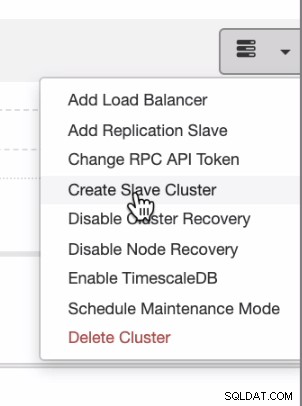
y puede llegar con el resultado final como se muestra a continuación,

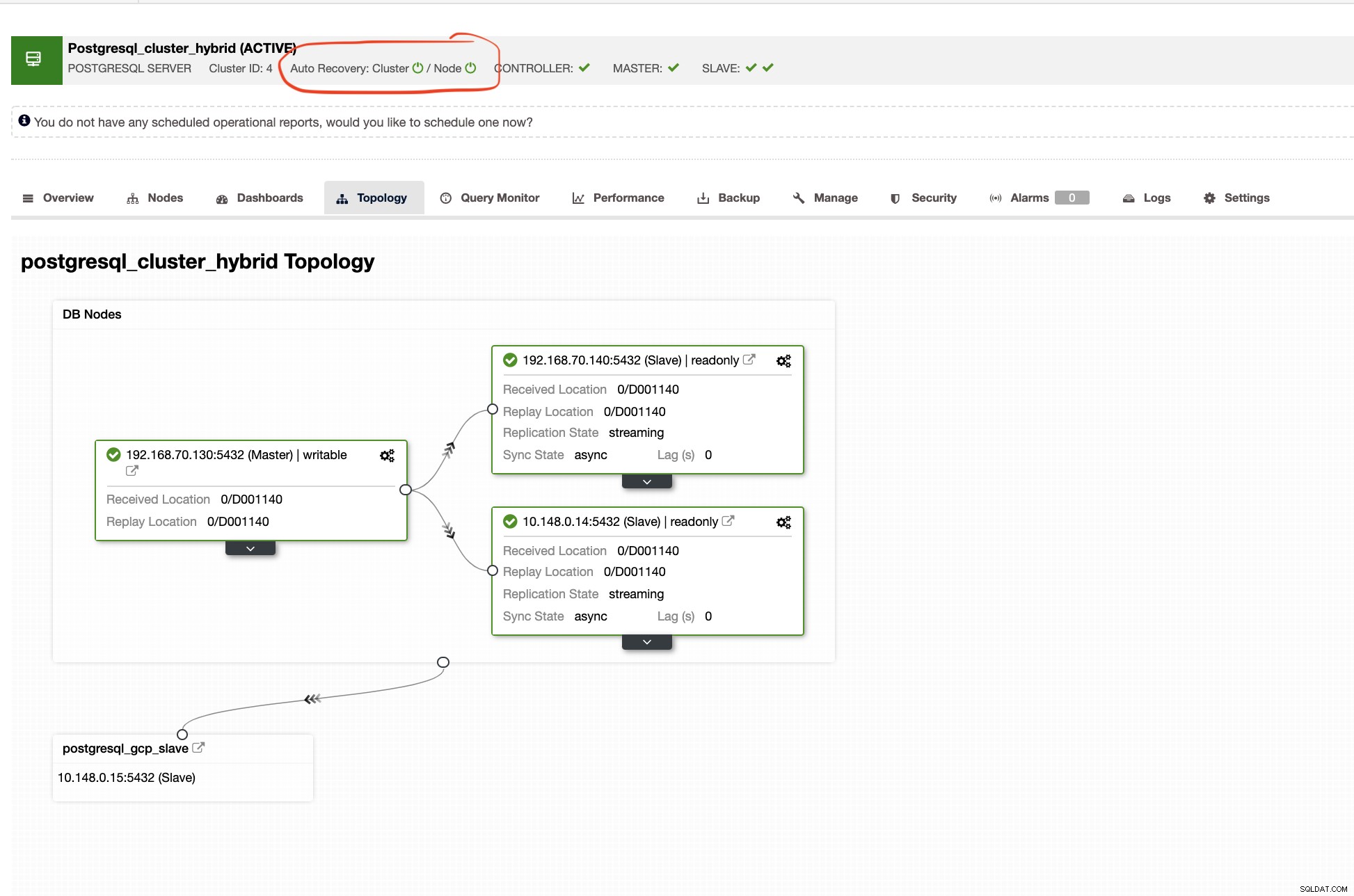
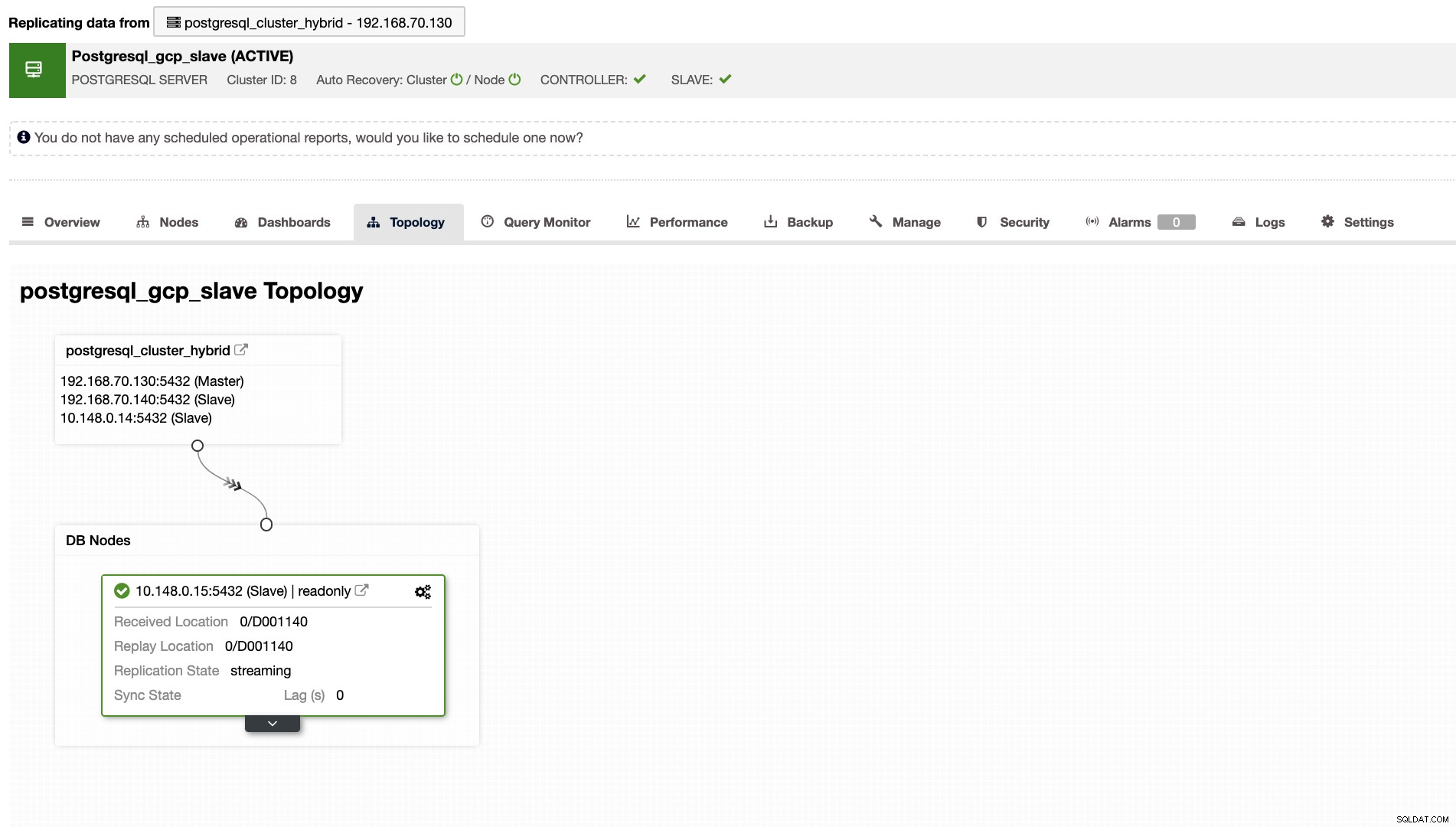
ClusterControl también le mostrará la topología correcta de su clúster cada vez que tenga una configuración de entorno de nube híbrida. Vea lo siguiente a continuación,
Mientras que en el clúster esclavo, la topología mostrará su árbol de origen revelando su maestro. El esclavo aquí se muestra como si estuviera ubicado en una red separada ubicada principalmente en Google Cloud, mientras que el maestro está en las instalaciones.
Conclusión
Es aceptable admitir que una configuración de nube híbrida, especialmente con un clúster de PostgreSQL, agrega complejidad. Debe tener la herramienta adecuada con opciones presentes para respaldar su planificación de recuperación ante desastres. Estos son muy importantes para salvar y evitar que su negocio sufra una catástrofe potencial de daños financieros y la pérdida de la confianza del cliente. Invierta en las herramientas y habilidades adecuadas de su tecnología, y salvará a su negocio del impacto negativo.