La monitorización es una de las tareas fundamentales en cualquier sistema. Nos puede ayudar a detectar problemas y tomar medidas, o simplemente a conocer el estado actual de nuestros sistemas. El uso de pantallas visuales puede hacernos más efectivos, ya que podemos detectar más fácilmente los problemas de rendimiento.
En este blog, veremos cómo usar SCUMM para monitorear nuestras bases de datos PostgreSQL y qué métricas podemos usar para esta tarea. También revisaremos los paneles disponibles, para que pueda averiguar fácilmente lo que realmente está sucediendo con sus instancias de PostgreSQL.
¿Qué es SCUMM?
En primer lugar, veamos qué es SCUMM (Severalnines ClusterControl Unified Monitoring and Management).
Es una nueva solución basada en agentes con agentes instalados en los nodos de la base de datos.
Los SCUMM Agents son exportadores de Prometheus que exportan métricas de servicios como PostgreSQL como métricas de Prometheus.
Se utiliza un servidor Prometheus para recopilar y almacenar datos de series temporales de los agentes SCUMM.
Prometheus es un kit de herramientas de monitoreo y alerta de sistemas de código abierto creado originalmente en SoundCloud. Ahora es un proyecto de código abierto independiente y se mantiene de forma independiente.
Prometheus está diseñado para brindar confiabilidad, para ser el sistema al que acudir durante una interrupción que le permita diagnosticar problemas rápidamente.
¿Cómo usar SCUMM?
Cuando usamos ClusterControl, cuando seleccionamos un clúster, podemos ver una descripción general de nuestras bases de datos, así como algunas métricas básicas que se pueden usar para identificar un problema. En el siguiente panel, podemos ver una configuración maestro-esclavo con un maestro y 2 esclavos, con HAProxy y Keepalived.
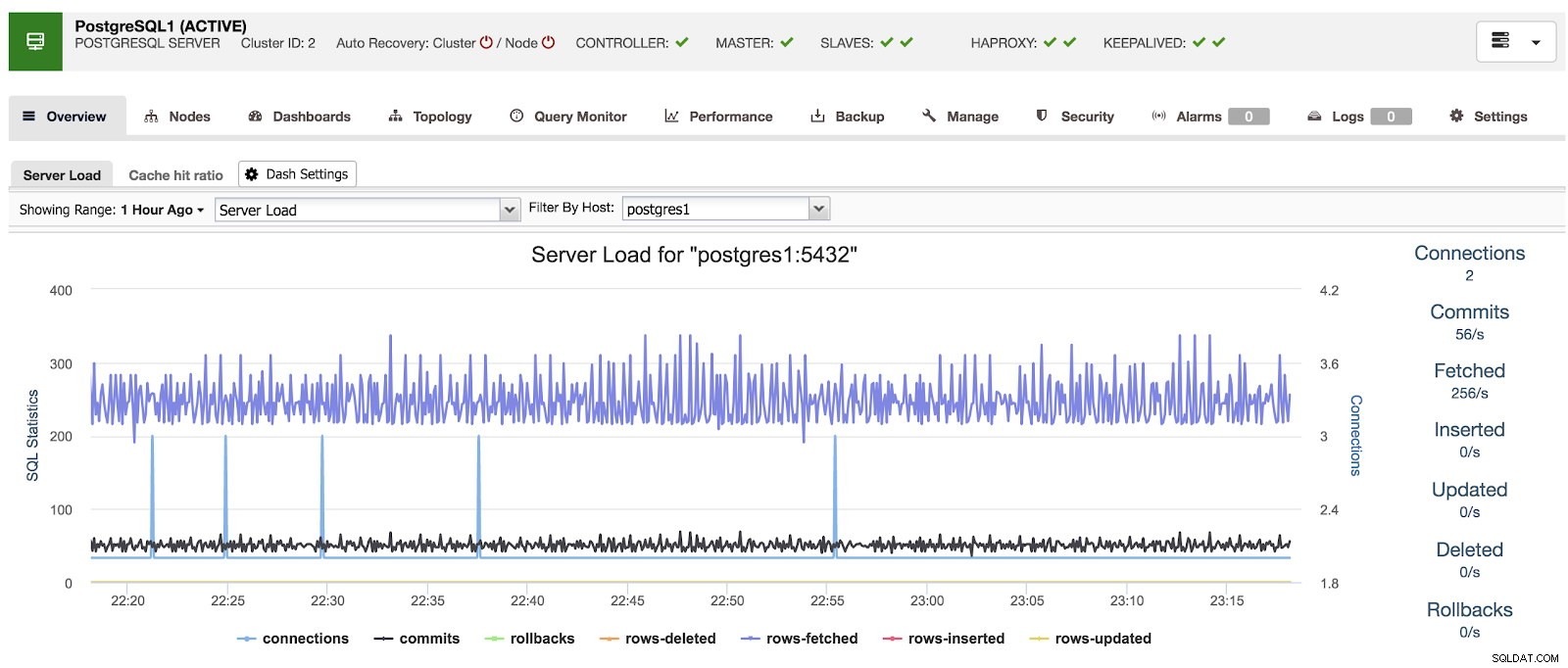 Resumen de ClusterControl
Resumen de ClusterControl Si vamos a la opción “Dashboards”, podemos ver un mensaje como el siguiente.
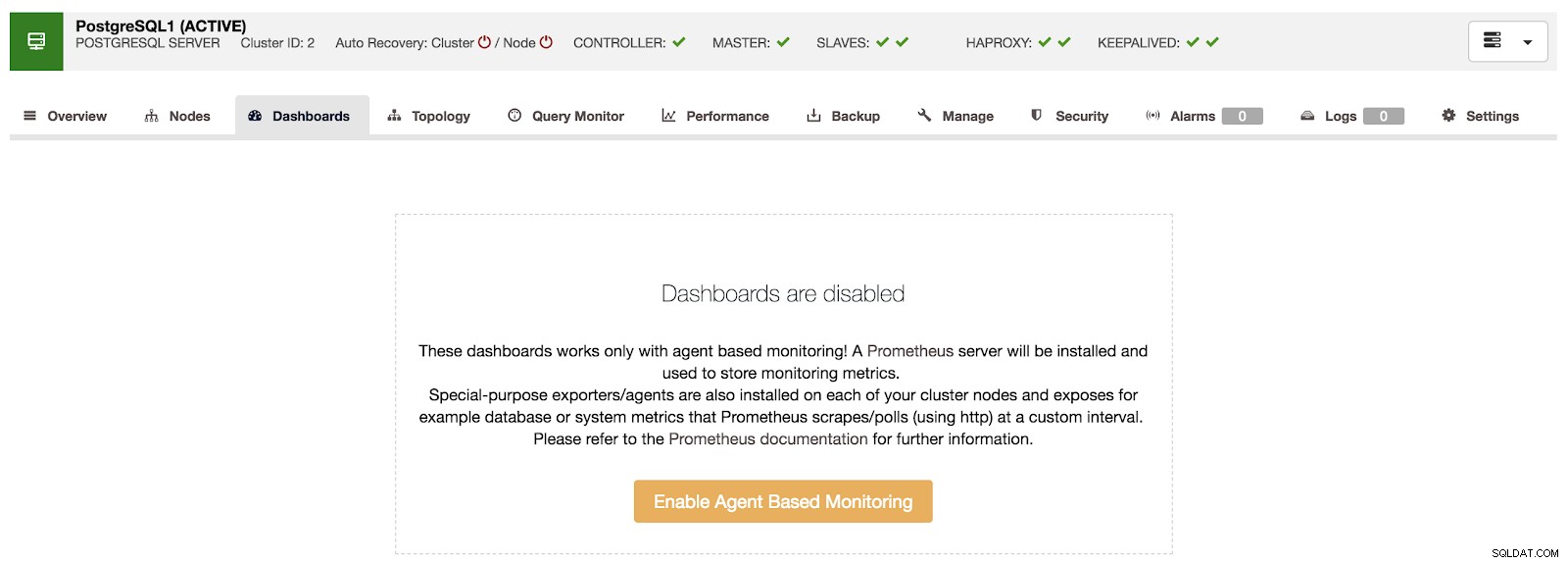 Paneles de control de clúster deshabilitados
Paneles de control de clúster deshabilitados Para usar esta función, debemos habilitar el agente mencionado anteriormente. Para ello, solo tenemos que pulsar sobre el botón "Activar monitorización basada en agentes" de este apartado.
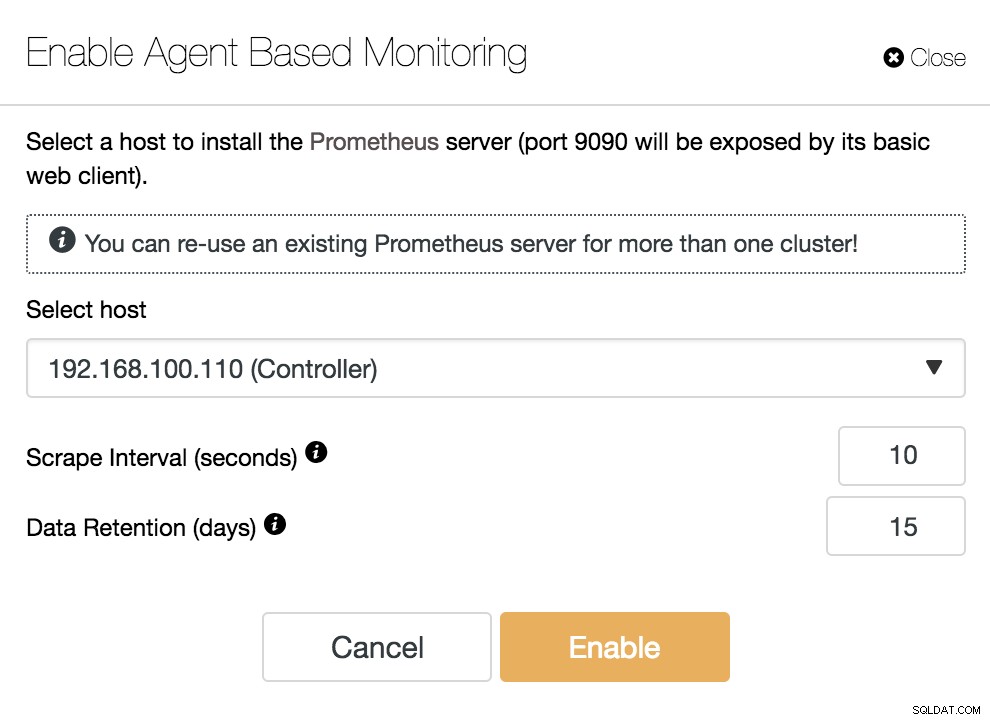 ClusterControl Activar supervisión basada en agentes
ClusterControl Activar supervisión basada en agentes Para habilitar nuestro agente, debemos especificar el host donde instalaremos nuestro servidor Prometheus, que, como podemos ver en el ejemplo, puede ser nuestro servidor ClusterControl.
También debemos especificar:
- Intervalo de raspado (segundos):establezca la frecuencia con la que se raspan los nodos para obtener métricas. El valor predeterminado es 10 segundos.
- Retención de datos (días):establezca cuánto tiempo se conservan las métricas antes de eliminarlas. El valor predeterminado es 15 días.
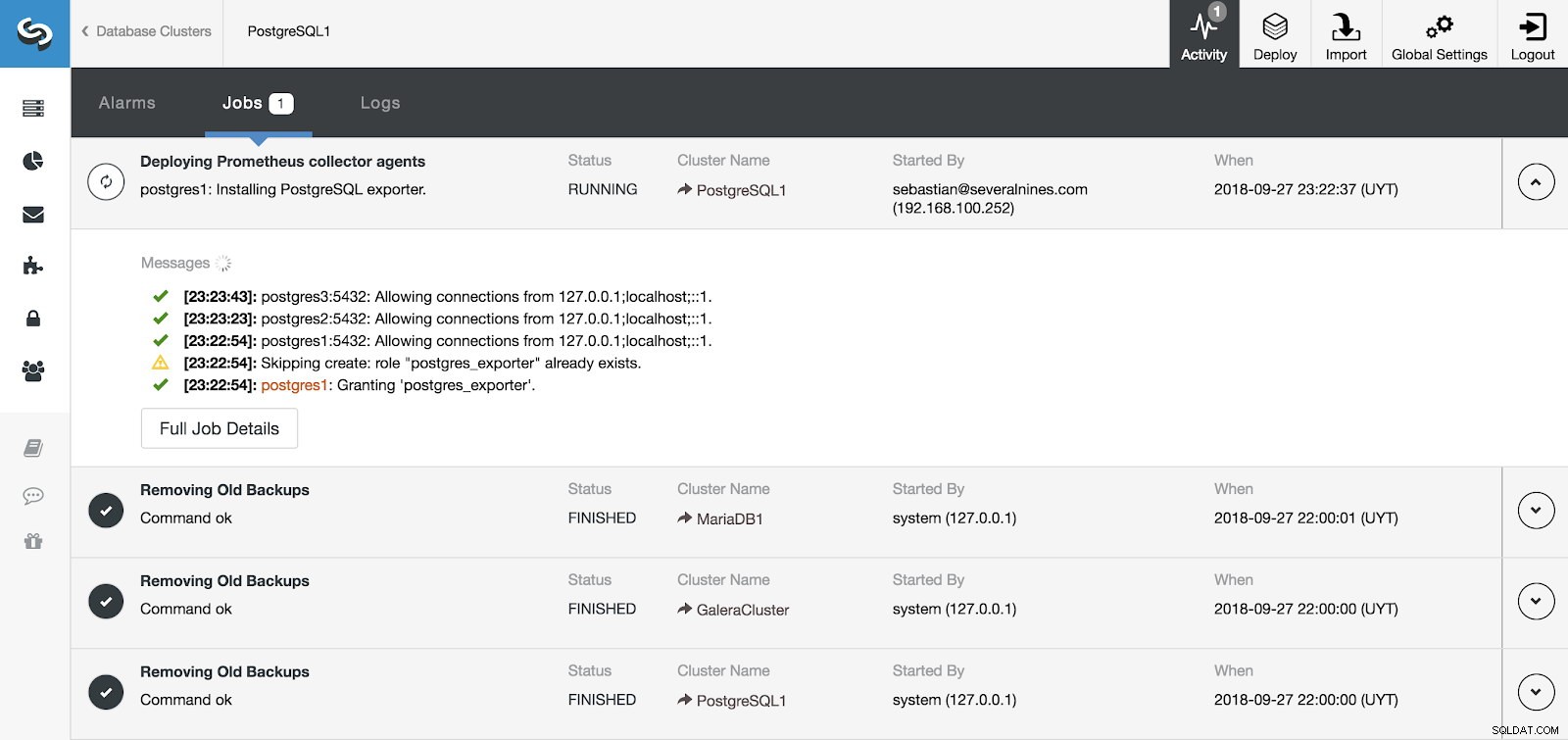 Sección de actividad de ClusterControl
Sección de actividad de ClusterControl Podemos monitorizar la instalación de nuestro servidor y agentes desde la sección Actividad en ClusterControl y, una vez finalizada, podemos ver nuestro clúster con los agentes habilitados desde la pantalla principal de ClusterControl.
 Agentes de ClusterControl habilitados
Agentes de ClusterControl habilitados Paneles
Teniendo nuestros agentes habilitados, si vamos a la sección Dashboards, veríamos algo como esto:
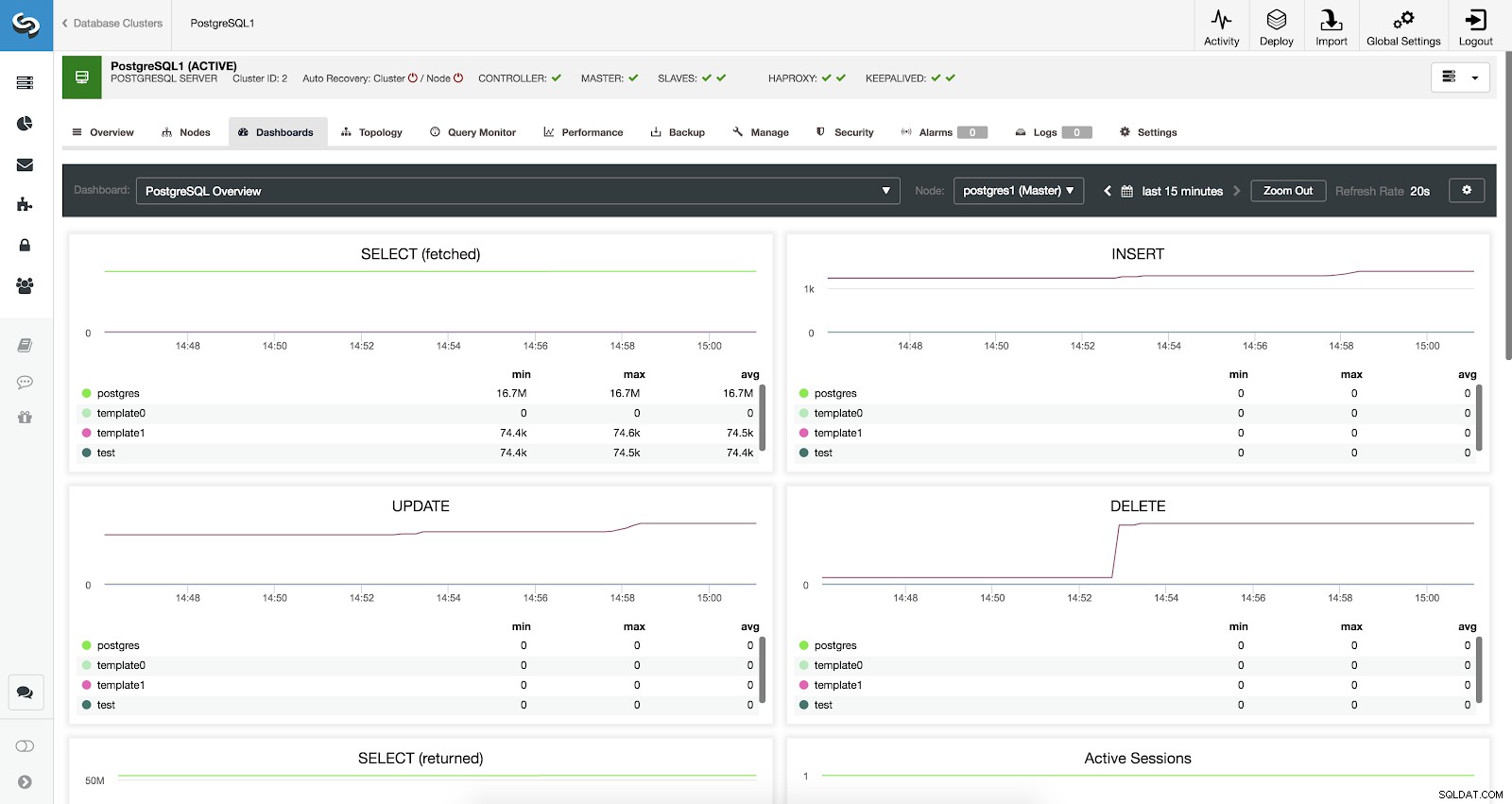 Paneles de ClusterControl habilitados
Paneles de ClusterControl habilitados Tenemos tres tipos diferentes de tableros disponibles, Descripción general del sistema, Gráficos de servidores cruzados y Descripción general de PostgreSQL. El último es el que vemos por defecto al entrar en este apartado.
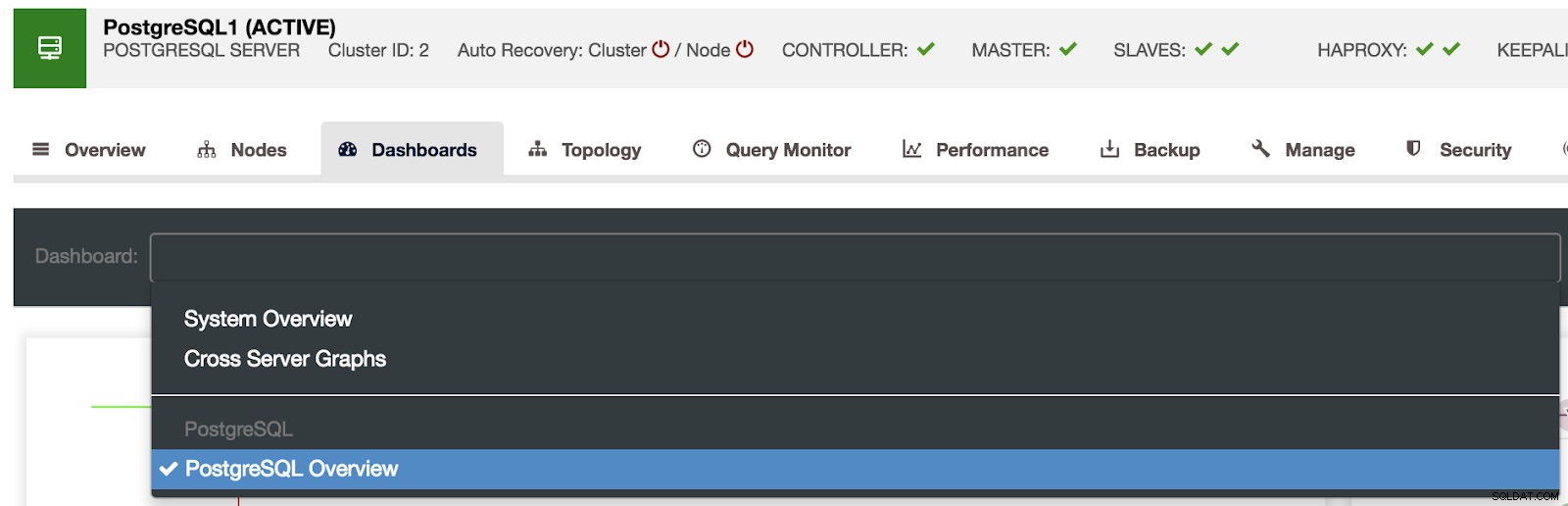 Selección de tableros de control de clúster
Selección de tableros de control de clúster Aquí también podemos especificar qué nodo monitorear, el rango de tiempo y la frecuencia de actualización.
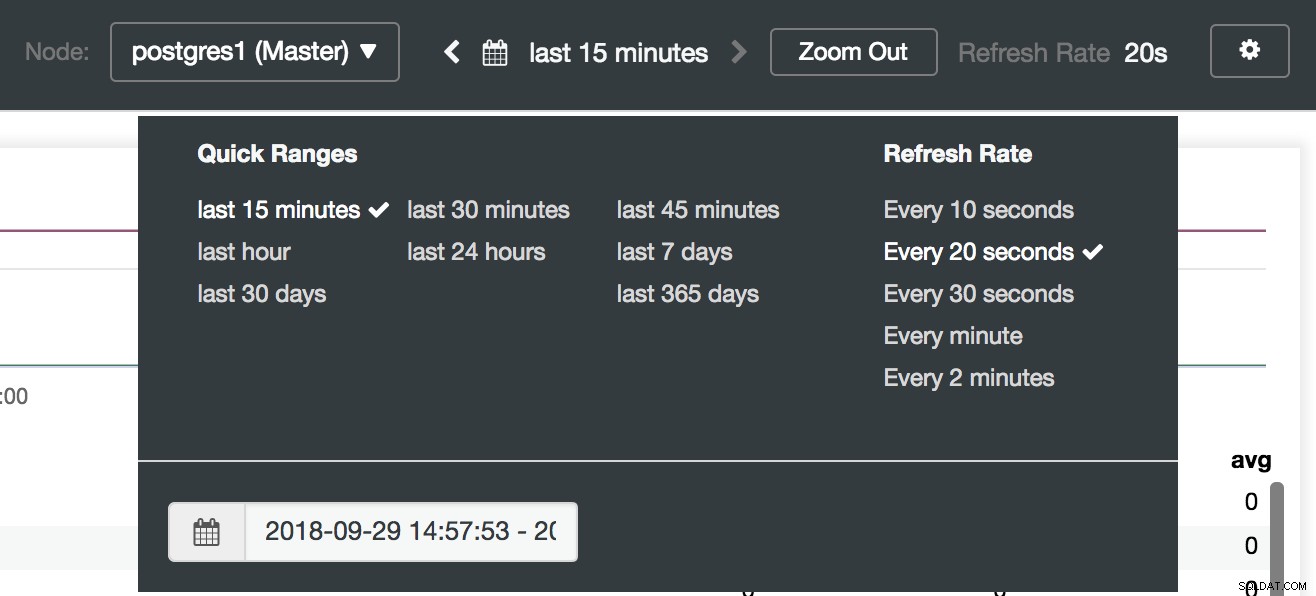 Opciones del panel de control de clúster
Opciones del panel de control de clúster En la sección de configuración podemos habilitar o deshabilitar nuestros agentes (Exportadores), consultar el estado de los agentes y verificar la versión de nuestro servidor Prometheus.
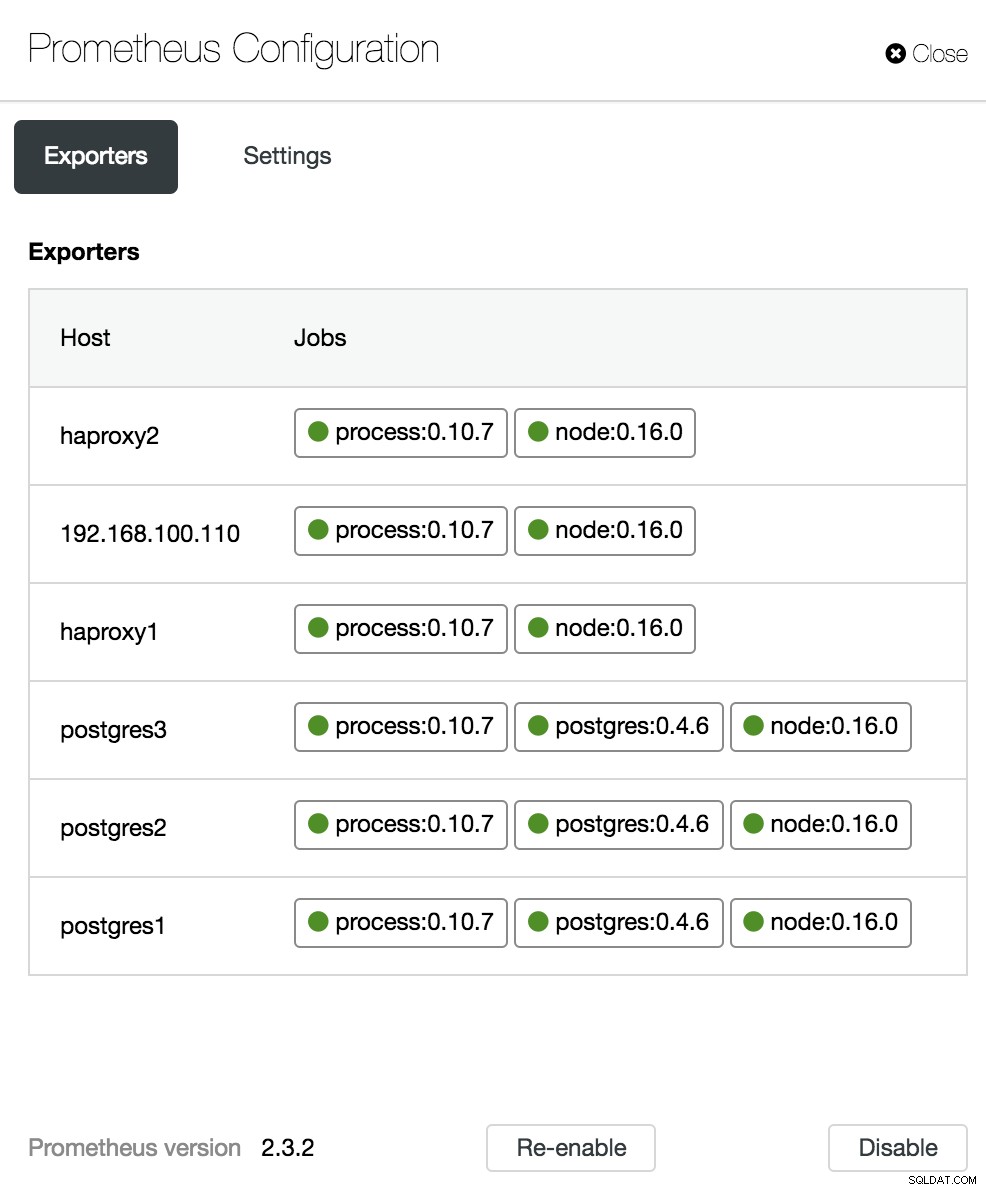 Configuración del tablero de ClusterControl
Configuración del tablero de ClusterControl Métricas generales de PostgreSQL
Veamos ahora qué métricas tenemos disponibles para cada una de nuestras bases de datos PostgreSQL (todas ellas para el nodo seleccionado).
- SELECT (obtenido):cantidad de filas seleccionadas (obtenidas) para cada base de datos. Las filas obtenidas se refieren a filas activas obtenidas de la tabla.
- SELECT (devuelto):cantidad de filas seleccionadas (devueltas) para cada base de datos. Las filas devueltas se refieren a todas las filas leídas de la tabla, que incluye filas inactivas y filas que aún no están confirmadas (en contraste con las filas recuperadas que solo cuentan las tuplas vivas).
- INSERTAR:Cantidad de filas insertadas para cada base de datos.
- ACTUALIZAR:Cantidad de filas actualizadas para cada base de datos.
- ELIMINAR:Cantidad de filas eliminadas para cada base de datos.
- Sesiones activas:Cantidad de sesiones activas (mín., máx. y promedio) para cada base de datos.
- Sesiones inactivas:Cantidad de sesiones inactivas (mín., máx. y promedio) para cada base de datos.
- Tablas de bloqueo:Cantidad de bloqueos (mín., máx. y promedio) separados por tipo para cada base de datos.
- Utilización de E/S de disco:Utilización de E/S de disco del servidor.
- Uso del disco:porcentaje de uso del disco del servidor (mínimo, máximo y promedio).
- Latencia del disco:latencia del disco del servidor.
Métricas de descripción general de ClusterControl PostgreSQL Métricas de descripción general del sistema
Para monitorizar nuestro sistema, tenemos disponibles para cada servidor las siguientes métricas (todas ellas para el nodo seleccionado):
- Tiempo de actividad del sistema:tiempo desde que el servidor está activo.
- CPU:cantidad de CPU.
- RAM:Cantidad de memoria RAM.
- Memoria disponible:porcentaje de memoria RAM disponible.
- Promedio de carga:carga mínima, máxima y promedio del servidor.
- Memoria:memoria del servidor disponible, total y utilizada.
- Uso de CPU:información de uso mínimo, máximo y promedio de CPU del servidor.
- Distribución de memoria:distribución de memoria (búfer, caché, libre y utilizada) en el nodo seleccionado.
- Métricas de saturación:mínimo, máximo y promedio de carga de E/S y carga de CPU en el nodo seleccionado.
- Detalles avanzados de memoria:detalles de uso de memoria como páginas, búfer y más, en el nodo seleccionado.
- Bifurcaciones:Cantidad de procesos de bifurcaciones. Fork es una operación mediante la cual un proceso crea una copia de sí mismo. Suele ser una llamada al sistema, implementada en el kernel.
- Procesos:Cantidad de procesos ejecutándose o esperando en el Sistema Operativo.
- Cambios de contexto:un cambio de contexto es la acción de almacenar el estado de un proceso o de un subproceso.
- Interrupciones:cantidad de interrupciones. Una interrupción es un evento que altera el flujo de ejecución normal de un programa y puede ser generado por dispositivos de hardware o incluso por la propia CPU.
- Tráfico de red:tráfico de red entrante y saliente en KBytes por segundo en el nodo seleccionado.
- Utilización de la red por hora:tráfico enviado y recibido en el último día.
- Intercambiar:intercambiar el uso (libre y usado) en el nodo seleccionado.
- Actividad de intercambio:lee y escribe datos en el intercambio.
- Actividad de E/S:página de entrada y salida en IO.
- Descriptores de archivo:descriptores de archivo asignados y limitados.
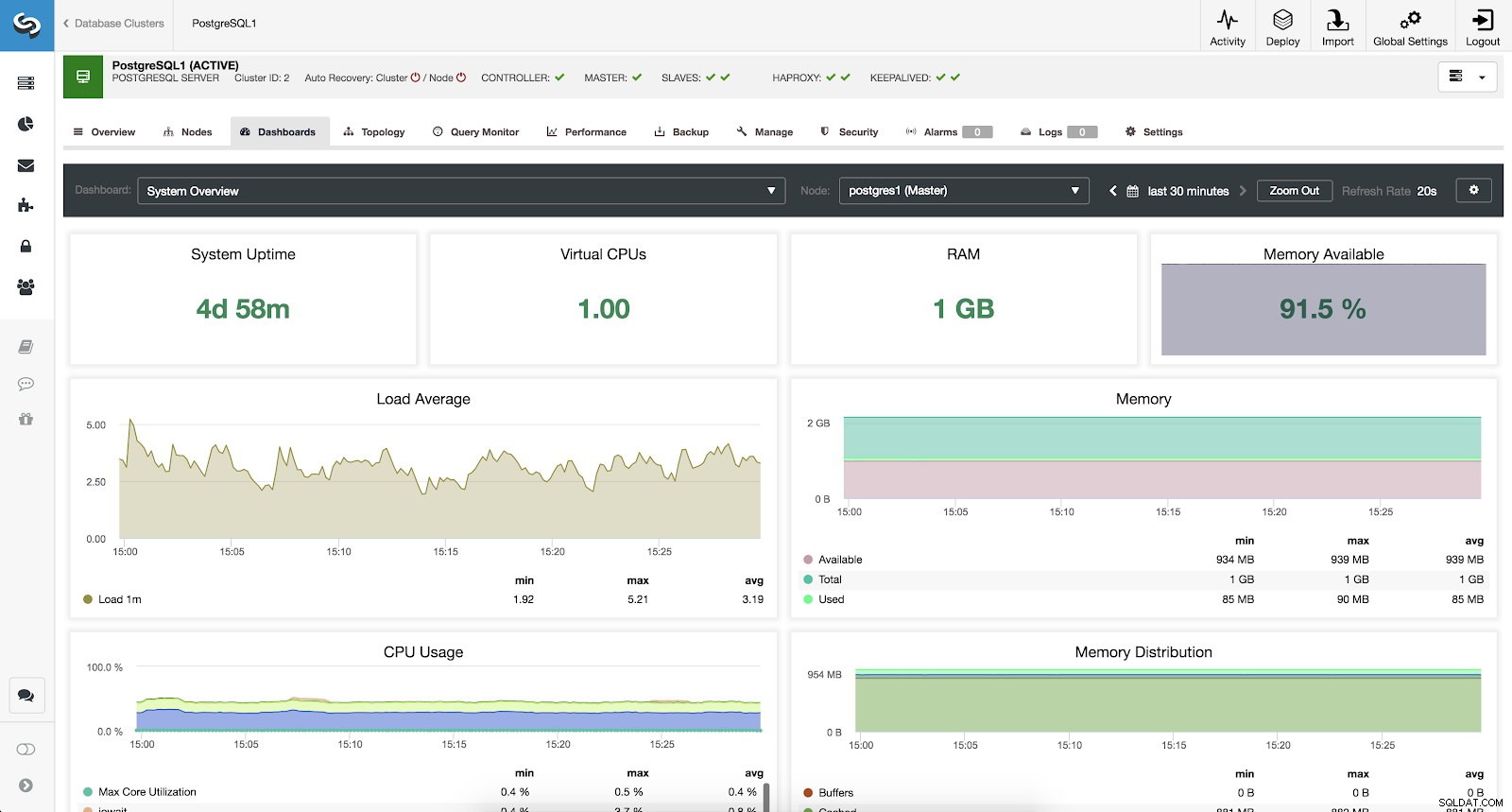 Métricas de descripción general del sistema ClusterControl
Métricas de descripción general del sistema ClusterControl Métricas de gráficos entre servidores
Si queremos ver el estado general de todos nuestros servidores podemos utilizar este panel con las siguientes métricas:
- Promedio de carga:los servidores cargan el promedio para cada servidor.
- Uso de memoria:porcentaje de uso de memoria para cada servidor.
- Tráfico de red:kBytes mínimo, máximo y promedio de tráfico de red por segundo.
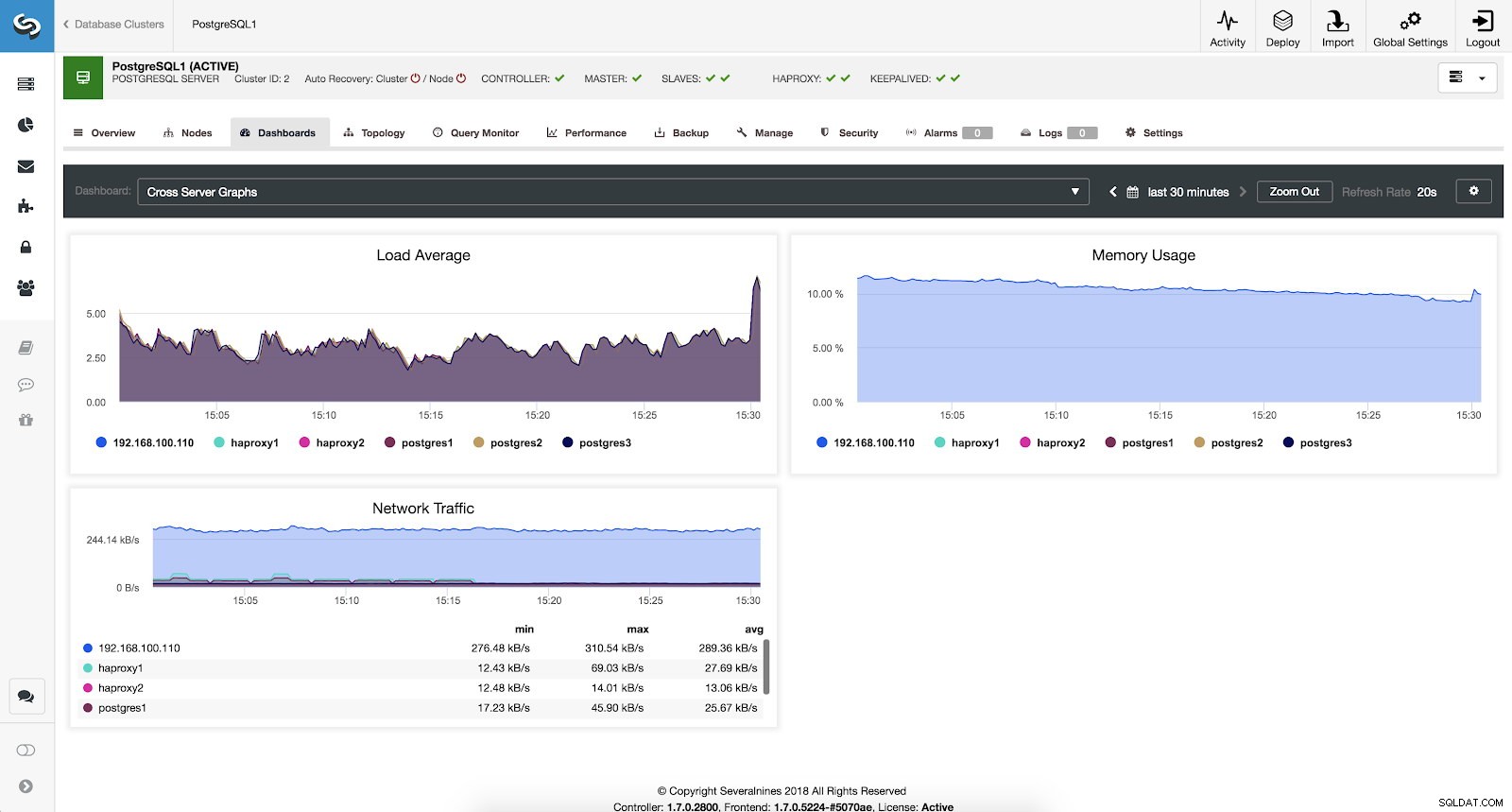 Métricas de gráficos de servidores cruzados de ClusterControl
Métricas de gráficos de servidores cruzados de ClusterControl Conclusión
Hay varias formas de monitorear PostgreSQL. ClusterControl proporciona monitoreo sin agente y ahora basado en agente a través de Prometheus. Proporciona datos de monitoreo de mayor resolución, así como diferentes paneles para comprender el rendimiento de la base de datos. ClusterControl también puede integrarse con herramientas externas como Slack o PagerDuty para alertas.