El manejo de NULL es uno de los aspectos más complicados del modelado y la manipulación de datos con SQL. Comencemos con el hecho de que un intento de explicar exactamente qué es un NULL no es trivial en sí mismo. Incluso entre las personas que tienen un buen conocimiento de la teoría relacional y SQL, escuchará opiniones muy sólidas tanto a favor como en contra del uso de valores NULL en su base de datos. Le gusten o no, como profesional de la base de datos, a menudo tiene que lidiar con ellos, y dado que los NULL agregan complejidad a la escritura de su código SQL, es una buena idea hacer que sea una prioridad comprenderlos bien. De esta forma, puede evitar errores y errores innecesarios.
Este artículo es el primero de una serie sobre las complejidades de NULL. Comienzo con la cobertura de lo que son NULL y cómo se comportan en las comparaciones. Luego cubro las inconsistencias del tratamiento NULL en diferentes elementos del lenguaje. Finalmente, cubro las características estándar faltantes relacionadas con el manejo de NULL en T-SQL y sugiero alternativas que están disponibles en T-SQL.
La mayor parte de la cobertura es relevante para cualquier plataforma que implemente un dialecto de SQL, pero en algunos casos menciono aspectos que son específicos de T-SQL.
En mis ejemplos, usaré una base de datos de muestra llamada TSQLV5. Puede encontrar el script que crea y completa esta base de datos aquí, y su diagrama ER aquí.
NULL como marcador de un valor faltante
Empecemos por entender qué son los valores NULL. En SQL, NULL es un marcador, o un marcador de posición, para un valor faltante. Es el intento de SQL de representar en su base de datos una realidad en la que cierto valor de atributo a veces está presente y a veces falta. Por ejemplo, suponga que necesita almacenar datos de empleados en una tabla Empleados. Tiene atributos para nombre, segundo nombre y apellido. Los atributos de nombre y apellido son obligatorios y, por lo tanto, los define como que no permiten valores NULL. El atributo del segundo nombre es opcional y, por lo tanto, lo define como que permite valores NULL.
Si se pregunta qué tiene que decir el modelo relacional sobre los valores faltantes, el creador del modelo, Edgar F. Codd, creía en ellos. De hecho, incluso hizo una distinción entre dos tipos de valores faltantes:faltantes pero aplicables (marcador de valores A) y faltantes pero no aplicables (marcador de valores I). Si tomamos el atributo del segundo nombre como ejemplo, en un caso en el que un empleado tiene un segundo nombre, pero por razones de privacidad elige no compartir la información, usaría el marcador de valores A. En el caso de que un empleado no tenga un segundo nombre, usaría el marcador I-Values. Aquí, el mismo atributo a veces podría ser relevante y estar presente, a veces faltante pero aplicable y otras veces faltante pero inaplicable. Otros casos podrían ser más claros, admitiendo solo un tipo de valores faltantes. Por ejemplo, suponga que tiene una tabla Pedidos con un atributo llamado fecha de envío que contiene la fecha de envío del pedido. Un pedido que se envió siempre tendrá una fecha de envío actual y relevante. El único caso de no tener una fecha de envío conocida sería para pedidos que aún no se enviaron. Así que aquí, debe estar presente un valor de fecha de envío relevante o se debe usar el marcador I-Values.
Los diseñadores de SQL optaron por no entrar en la distinción entre valores faltantes aplicables e inaplicables y nos proporcionaron NULL como marcador para cualquier tipo de valor faltante. En su mayor parte, SQL fue diseñado para asumir que los valores NULL representan el tipo de valor faltante que falta pero es aplicable. En consecuencia, especialmente cuando su uso de NULL es como marcador de posición para un valor inaplicable, el manejo predeterminado de SQL NULL puede no ser el que perciba como correcto. En ocasiones, deberá agregar una lógica de manejo NULL explícita para obtener el tratamiento que considere correcto para usted.
Como práctica recomendada, si sabe que un atributo no debe permitir valores NULL, asegúrese de imponerlo con una restricción NOT NULL como parte de la definición de la columna. Hay un par de razones importantes para esto. Una razón es que si no hace cumplir esto, en un momento u otro, los NULL llegarán allí. Podría ser el resultado de un error en la aplicación o la importación de datos incorrectos. Al usar una restricción, sabe que los valores NULL nunca llegarán a la tabla. Otra razón es que el optimizador evalúa restricciones como NOT NULL para una mejor optimización, evitando el trabajo innecesario buscando NULL y habilitando ciertas reglas de transformación.
Comparaciones que involucran valores NULL
Hay algunos trucos en la evaluación de predicados de SQL cuando se trata de valores NULL. Primero cubriré las comparaciones que involucran constantes. Más adelante cubriré las comparaciones que involucran variables, parámetros y columnas.
Cuando usa predicados que comparan operandos en elementos de consulta como WHERE, ON y HAVING, los posibles resultados de la comparación dependen de si alguno de los operandos puede ser NULL. Si sabe con certeza que ninguno de los operandos puede ser NULO, el resultado del predicado siempre será VERDADERO o FALSO. Esto es lo que se conoce como lógica de predicados de dos valores, o en resumen, simplemente lógica de dos valores. Este es el caso, por ejemplo, cuando está comparando una columna que está definida como que no permite valores NULL con algún otro operando que no sea NULL.
Si alguno de los operandos en la comparación puede ser un NULL, digamos, una columna que permite NULLs, usando operadores de igualdad (=) y desigualdad (<>,>, <,>=, <=, etc.), usted está ahora a merced de la lógica de predicados de tres valores. Si en una comparación dada, los dos operandos resultan ser valores que no son NULOS, el resultado seguirá siendo VERDADERO o FALSO. Sin embargo, si alguno de los operandos es NULL, obtiene un tercer valor lógico llamado DESCONOCIDO. Tenga en cuenta que ese es el caso incluso cuando se comparan dos NULL. El tratamiento de VERDADERO y FALSO por parte de la mayoría de los elementos de SQL es bastante intuitivo. El tratamiento de UNKNOWN no siempre es tan intuitivo. Además, diferentes elementos de SQL manejan el caso DESCONOCIDO de manera diferente, como explicaré en detalle más adelante en el artículo bajo "Inconsistencias de tratamiento NULL".
Como ejemplo, suponga que necesita consultar la tabla Sales.Orders en la base de datos de muestra TSQLV5 y devolver los pedidos que se enviaron el 2 de enero de 2019. Utilice la siguiente consulta:
USE TSQLV5; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = '20190102';
Está claro que el predicado del filtro se evalúa como VERDADERO para las filas cuya fecha de envío es el 2 de enero de 2019 y que esas filas deben devolverse. También está claro que el predicado se evalúa como FALSO para las filas donde la fecha de envío está presente, pero no es el 2 de enero de 2019, y esas filas deben descartarse. Pero, ¿qué pasa con las filas con una fecha de envío NULL? Recuerde que tanto los predicados basados en la igualdad como los predicados basados en la desigualdad devuelven UNKNOWN si alguno de los operandos es NULL. El filtro WHERE está diseñado para descartar dichas filas. Debe recordar que el filtro WHERE devuelve las filas para las que el predicado del filtro se evalúa como VERDADERO y descarta las filas para las que el predicado se evalúa como FALSO o DESCONOCIDO.
Esta consulta genera el siguiente resultado:
orderid shippeddate ----------- ----------- 10771 2019-01-02 10794 2019-01-02 10802 2019-01-02
Suponga que necesita devolver pedidos que no se enviaron el 2 de enero de 2019. En lo que a usted respecta, se supone que los pedidos que aún no se enviaron se incluyen en el resultado. Utiliza una consulta similar a la anterior, solo negando el predicado, así:
SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate = '20190102');
Esta consulta devuelve el siguiente resultado:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
El resultado naturalmente excluye las filas con la fecha de envío 2 de enero de 2019, pero también excluye las filas con una fecha de envío NULL. Lo que podría ser contrario a la intuición aquí es lo que sucede cuando usa el operador NOT para negar un predicado que se evalúa como DESCONOCIDO. Obviamente, NO ES VERDADERO es FALSO y NO FALSO es VERDADERO. Sin embargo, NO DESCONOCIDO permanece DESCONOCIDO. La lógica de SQL detrás de este diseño es que si no sabe si una proposición es verdadera, tampoco sabe si la proposición no es verdadera. Esto significa que cuando se usan operadores de igualdad y desigualdad en el predicado de filtro, ni las formas positivas ni negativas del predicado devuelven las filas con valores NULL.
Este ejemplo es bastante simple. Hay casos más complicados que implican subconsultas. Hay un error común cuando usa el predicado NOT IN con una subconsulta, cuando la subconsulta devuelve un NULL entre los valores devueltos. La consulta siempre devuelve un resultado vacío. La razón es que la forma positiva del predicado (la parte IN) devuelve VERDADERO cuando se encuentra el valor externo y DESCONOCIDO cuando no se encuentra debido a la comparación con NULL. Luego, la negación del predicado con el operador NO siempre devuelve FALSO o DESCONOCIDO, respectivamente, nunca VERDADERO. Cubro este error en detalle en Errores, trampas y mejores prácticas de T-SQL:subconsultas, incluidas soluciones sugeridas, consideraciones de optimización y mejores prácticas. Si aún no está familiarizado con este error clásico, asegúrese de consultar este artículo, ya que el error es bastante común y existen medidas simples que puede tomar para evitarlo.
Volviendo a nuestra necesidad, ¿qué tal si intentamos devolver pedidos con una fecha de envío diferente al 2 de enero de 2019, usando el operador diferente a (<>):
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> '20190102';
Desafortunadamente, tanto los operadores de igualdad como los de desigualdad arrojan UNKNOWN cuando cualquiera de los operandos es NULL, por lo que esta consulta genera el siguiente resultado como la consulta anterior, excluyendo los NULL:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (806 rows affected)
Para aislar el problema de las comparaciones con valores NULL que generan DESCONOCIDO usando la igualdad, la desigualdad y la negación de los dos tipos de operadores, todas las siguientes consultas devuelven un conjunto de resultados vacío:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate = NULL); SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT (shippeddate <> NULL);
De acuerdo con SQL, se supone que no debe verificar si algo es igual a NULL o diferente a NULL, sino si algo es NULL o no es NULL, usando los operadores especiales IS NULL y IS NOT NULL, respectivamente. Estos operadores utilizan una lógica de dos valores y siempre devuelven VERDADERO o FALSO. Por ejemplo, use el operador IS NULL para devolver pedidos no enviados, así:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NULL;
Esta consulta genera el siguiente resultado:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... (21 rows affected)
Utilice el operador IS NOT NULL para devolver los pedidos enviados, así:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT NULL;
Esta consulta genera el siguiente resultado:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (809 rows affected)
Utilice el siguiente código para devolver pedidos que se enviaron en una fecha diferente al 2 de enero de 2019, así como pedidos no enviados:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate <> '20190102' OR shippeddate IS NULL;
Esta consulta genera el siguiente resultado:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11050 2019-05-05 11055 2019-05-05 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 (827 rows affected)
En una parte posterior de la serie, cubro las funciones estándar para el tratamiento NULL que actualmente faltan en T-SQL, incluido el predicado DISTINCT , que tienen el potencial de simplificar mucho el manejo de NULL.
Comparaciones con variables, parámetros y columnas
La sección anterior se centró en los predicados que comparan una columna con una constante. En realidad, sin embargo, comparará principalmente una columna con variables/parámetros o con otras columnas. Tales comparaciones implican más complejidades.
Desde el punto de vista del manejo de NULL, las variables y los parámetros se tratan de la misma manera. Usaré variables en mis ejemplos, pero los puntos que hago sobre su manejo son igualmente relevantes para los parámetros.
Considere la siguiente consulta básica (la llamaré Consulta 1), que filtra los pedidos que se enviaron en una fecha determinada:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Utilizo una variable en este ejemplo y la inicializo con alguna fecha de muestra, pero esto también podría haber sido una consulta parametrizada en un procedimiento almacenado o una función definida por el usuario.
La ejecución de esta consulta genera el siguiente resultado:
orderid shippeddate ----------- ----------- 10865 2019-02-12 10866 2019-02-12 10876 2019-02-12 10878 2019-02-12 10879 2019-02-12
El plan para la Consulta 1 se muestra en la Figura 1.
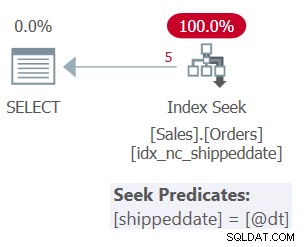 Figura 1:Plan para Consulta 1
Figura 1:Plan para Consulta 1
La tabla tiene un índice de cobertura para admitir esta consulta. El índice se llama idx_nc_shippeddate y se define con la lista de claves (shippeddate, orderid). El predicado de filtro de la consulta se expresa como un argumento de búsqueda (SARG) , lo que significa que permite que el optimizador considere aplicar una operación de búsqueda en el índice de soporte, yendo directamente al rango de filas de calificación. Lo que hace que el predicado de filtro sea SARGable es que usa un operador que representa un rango consecutivo de filas calificadas en el índice y que no aplica manipulación a la columna filtrada. El plan que obtiene es el plan óptimo para esta consulta.
Pero, ¿qué sucede si desea permitir que los usuarios soliciten pedidos no enviados? Dichos pedidos tienen una fecha de envío NULL. Aquí hay un intento de pasar un NULL como fecha de entrada:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Como ya sabe, un predicado que usa un operador de igualdad produce UNKNOWN cuando cualquiera de los operandos es NULL. En consecuencia, esta consulta devuelve un resultado vacío:
orderid shippeddate ----------- ----------- (0 rows affected)
Aunque T-SQL admite un operador IS NULL, no admite un operador IS
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE ISNULL(shippeddate, '99991231') = ISNULL(@dt, '99991231');
Esta consulta genera el resultado correcto:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 11075 NULL 11076 NULL 11077 NULL (21 rows affected)
Pero el plan para esta consulta, como se muestra en la Figura 2, no es óptimo.
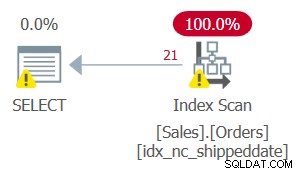 Figura 2:Plan para la consulta 2
Figura 2:Plan para la consulta 2
Dado que aplicó la manipulación a la columna filtrada, el predicado de filtro ya no se considera un SARG. El índice todavía está cubriendo, por lo que se puede usar; pero en lugar de aplicar una búsqueda en el índice que va directamente al rango de filas calificadas, se escanea toda la hoja del índice. Suponga que la tabla tiene 50 000 000 pedidos, y solo 1000 son pedidos sin enviar. Este plan escanearía las 50 000 000 filas en lugar de realizar una búsqueda que vaya directamente a las 1000 filas calificadas.
Una forma de predicado de filtro que tiene el significado correcto que buscamos y se considera un argumento de búsqueda es (shippeddate =@dt OR (shippeddate IS NULL AND @dt IS NULL)). Aquí hay una consulta que usa este predicado SARGable (lo llamaremos Consulta 3):
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE (shippeddate = @dt OR (shippeddate IS NULL AND @dt IS NULL));
El plan para esta consulta se muestra en la Figura 3.
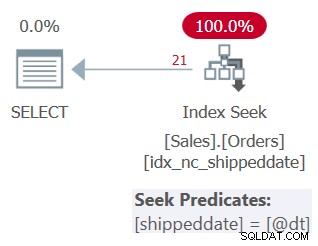 Figura 3:Plan para la consulta 3
Figura 3:Plan para la consulta 3
Como puede ver, el plan aplica una búsqueda en el índice de soporte. El predicado de búsqueda dice fecha de envío =@dt, pero está diseñado internamente para manejar valores NULL como valores no NULL por el bien de la comparación.
Esta solución se considera generalmente razonable. Es estándar, óptimo y correcto. Su principal inconveniente es que es detallado. ¿Qué pasaría si tuviera varios predicados de filtro basados en columnas NULLable? Rápidamente terminaría con una cláusula WHERE larga y engorrosa. Y se vuelve mucho peor cuando necesita escribir un predicado de filtro que involucre una columna NULLable en busca de filas donde la columna es diferente al parámetro de entrada. Entonces, el predicado se convierte en:(fecha de envío <> @dt AND ((fecha de envío ES NULO Y @dt NO ES NULO) O (fecha de envío NO ES NULO y @dt ES NULO))).
Puede ver claramente la necesidad de una solución más elegante que sea a la vez concisa y óptima. Desafortunadamente, algunos recurren a una solución no estándar en la que desactiva la opción de sesión ANSI_NULLS. Esta opción hace que SQL Server utilice un manejo no estándar de los operadores de igualdad (=) y diferente de (<>) con una lógica de dos valores en lugar de una lógica de tres valores, tratando los valores NULL como valores no NULL con fines de comparación. Al menos ese es el caso siempre que uno de los operandos sea un parámetro/variable o un literal.
Ejecute el siguiente código para desactivar la opción ANSI_NULLS en la sesión:
SET ANSI_NULLS OFF;
Ejecute la siguiente consulta usando un predicado simple basado en la igualdad:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate = @dt;
Esta consulta devuelve los 21 pedidos no enviados. Obtiene el mismo plan que se muestra anteriormente en la Figura 3, que muestra una búsqueda en el índice.
Ejecute el siguiente código para volver al comportamiento estándar donde ANSI_NULLS está activado:
SET ANSI_NULLS ON;
Se desaconseja encarecidamente confiar en un comportamiento tan poco estándar. La documentación también establece que la compatibilidad con esta opción se eliminará en alguna versión futura de SQL Server. Además, muchos no se dan cuenta de que esta opción solo es aplicable cuando al menos uno de los operandos es un parámetro/variable o una constante, aunque la documentación es bastante clara al respecto. No se aplica cuando se comparan dos columnas, como en una unión.
Entonces, ¿cómo maneja las uniones que involucran columnas de unión NULLable si desea obtener una coincidencia cuando los dos lados son NULL? Como ejemplo, use el siguiente código para crear y completar las tablas T1 y T2:
DROP TABLE IF EXISTS dbo.T1, dbo.T2; GO CREATE TABLE dbo.T1(k1 INT NULL, k2 INT NULL, k3 INT NULL, val1 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T1 UNIQUE CLUSTERED(k1, k2, k3)); CREATE TABLE dbo.T2(k1 INT NULL, k2 INT NULL, k3 INT NULL, val2 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T2 UNIQUE CLUSTERED(k1, k2, k3)); INSERT INTO dbo.T1(k1, k2, k3, val1) VALUES (1, NULL, 0, 'A'),(NULL, NULL, 1, 'B'),(0, NULL, NULL, 'C'),(1, 1, 0, 'D'),(0, NULL, 1, 'F'); INSERT INTO dbo.T2(k1, k2, k3, val2) VALUES (0, 0, 0, 'G'),(1, 1, 1, 'H'),(0, NULL, NULL, 'I'),(NULL, NULL, NULL, 'J'),(0, NULL, 1, 'K');
El código crea índices de cobertura en ambas tablas para admitir una combinación basada en las claves de combinación (k1, k2, k3) en ambos lados.
Use el siguiente código para actualizar las estadísticas de cardinalidad, inflando los números para que el optimizador piense que está tratando con tablas más grandes:
UPDATE STATISTICS dbo.T1(UNQ_T1) WITH ROWCOUNT = 1000000; UPDATE STATISTICS dbo.T2(UNQ_T2) WITH ROWCOUNT = 1000000;
Use el siguiente código para intentar unir las dos tablas usando predicados simples basados en la igualdad:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON T1.k1 = T2.k1
AND T1.k2 = T2.k2
AND T1.k3 = T2.k3; Al igual que con los ejemplos de filtrado anteriores, aquí también las comparaciones entre valores NULL que usan un operador de igualdad arrojan UNKNOWN, lo que genera no coincidencias. Esta consulta genera una salida vacía:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- (0 rows affected)
Usar ISNULL o COALESCE como en un ejemplo de filtrado anterior, reemplazar un NULL con un valor que normalmente no puede aparecer en los datos en ambos lados, da como resultado una consulta correcta (me referiré a esta consulta como Consulta 4):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON ISNULL(T1.k1, -2147483648) = ISNULL(T2.k1, -2147483648)
AND ISNULL(T1.k2, -2147483648) = ISNULL(T2.k2, -2147483648)
AND ISNULL(T1.k3, -2147483648) = ISNULL(T2.k3, -2147483648); Esta consulta genera el siguiente resultado:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
Sin embargo, al igual que la manipulación de una columna filtrada rompe la SARGability del predicado de filtro, la manipulación de una columna de unión impide la capacidad de confiar en el orden del índice. Esto se puede ver en el plan para esta consulta como se muestra en la Figura 4.
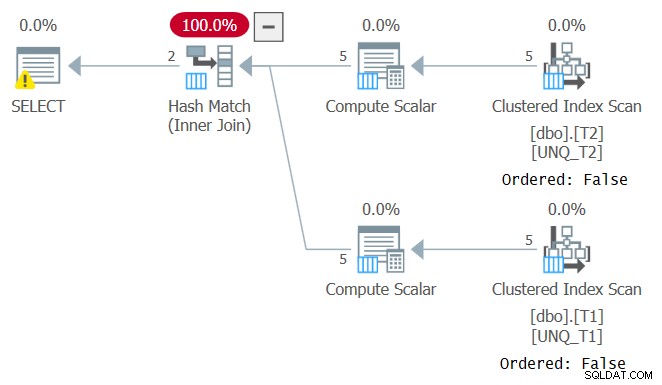 Figura 4:Plan para Consulta 4
Figura 4:Plan para Consulta 4
Un plan óptimo para esta consulta es el que aplica escaneos ordenados de los dos índices de cobertura seguidos de un algoritmo Merge Join, sin clasificación explícita. El optimizador eligió un plan diferente ya que no podía confiar en el orden del índice. Si intenta forzar un algoritmo Merge Join utilizando INNER MERGE JOIN, el plan aún se basaría en escaneos desordenados de los índices, seguidos de una clasificación explícita. ¡Pruébalo!
Por supuesto, puede usar predicados largos similares a los predicados SARGable mostrados anteriormente para tareas de filtrado:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2
FROM dbo.T1
INNER JOIN dbo.T2
ON (T1.k1 = T2.k1 OR (T1.k1 IS NULL AND T2.K1 IS NULL))
AND (T1.k2 = T2.k2 OR (T1.k2 IS NULL AND T2.K2 IS NULL))
AND (T1.k3 = T2.k3 OR (T1.k3 IS NULL AND T2.K3 IS NULL)); Esta consulta produce el resultado deseado y permite que el optimizador se base en el orden del índice. Sin embargo, nuestra esperanza es encontrar una solución que sea tanto óptima como concisa.
Hay una técnica elegante y concisa poco conocida que puede usar tanto en uniones como en filtros, tanto para identificar coincidencias como para identificar no coincidencias. Esta técnica se descubrió y documentó hace ya años, como en el excelente artículo de Paul White Planes de consulta no documentados:comparaciones de igualdad de 2011. soluciones no estándar. Sin duda merece más exposición y amor.
La técnica se basa en el hecho de que los operadores de conjuntos como INTERSECT y EXCEPT utilizan un enfoque de comparación basado en distinciones al comparar valores, y no un enfoque de comparación basado en igualdad o desigualdad.
Considere nuestra tarea de unión como un ejemplo. Si no tuviéramos que devolver columnas que no sean las claves de combinación, habríamos usado una consulta simple (me referiré a ella como Consulta 5) con un operador INTERSECT, así:
SELECT k1, k2, k3 FROM dbo.T1 INTERSECT SELECT k1, k2, k3 FROM dbo.T2;
Esta consulta genera el siguiente resultado:
k1 k2 k3 ----------- ----------- ----------- 0 NULL NULL 0 NULL 1
El plan para esta consulta se muestra en la Figura 5, lo que confirma que el optimizador pudo confiar en el orden del índice y usar un algoritmo Merge Join.
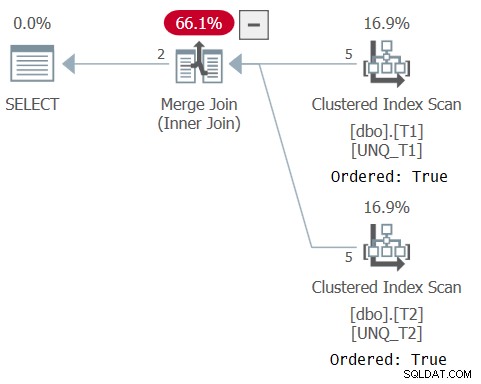 Figura 5:Plan para Consulta 5
Figura 5:Plan para Consulta 5
Como señala Paul en su artículo, el plan XML para el operador de conjunto utiliza un operador de comparación IS implícito (CompareOp="IS" ) a diferencia del operador de comparación EQ utilizado en una unión normal (CompareOp="EQ" ). El problema con una solución que se basa únicamente en un operador de conjunto es que lo limita a devolver solo las columnas que está comparando. Lo que realmente necesitamos es una especie de híbrido entre una unión y un operador de conjunto, lo que le permite comparar un subconjunto de los elementos mientras devuelve otros adicionales como lo hace una unión y usa la comparación basada en distinción (IS) como lo hace un operador de conjunto. Esto se puede lograr mediante el uso de una unión como construcción externa y un predicado EXISTS en la cláusula ON de la unión basada en una consulta con un operador INTERSECT que compara las claves de unión de los dos lados, así (me referiré a esta solución como Query 6):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
El operador INTERSECT opera en dos consultas, cada una de las cuales forma un conjunto de una fila en función de las claves de unión de cada lado. Cuando las dos filas son iguales, la consulta INTERSECT devuelve una fila; el predicado EXISTS devuelve VERDADERO, lo que resulta en una coincidencia. Cuando las dos filas no son iguales, la consulta INTERSECT devuelve un conjunto vacío; el predicado EXISTE devuelve FALSO, lo que resulta en una no coincidencia.
Esta solución genera el resultado deseado:
k1 K2 K3 val1 val2 ----------- ----------- ----------- ---------- ---------- 0 NULL NULL C I 0 NULL 1 F K
El plan para esta consulta se muestra en la Figura 6, lo que confirma que el optimizador pudo confiar en el orden del índice.
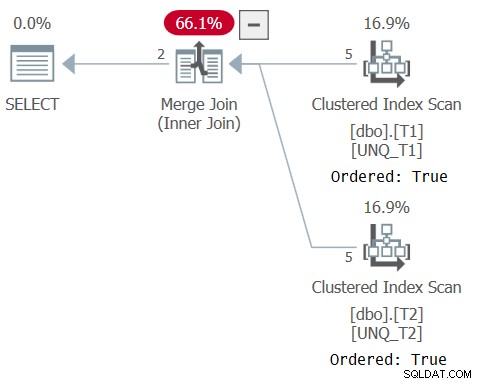 Figura 6:Plan para Consulta 6
Figura 6:Plan para Consulta 6
Puede usar una construcción similar como un predicado de filtro que involucre una columna y un parámetro/variable para buscar coincidencias según la distinción, así:
DECLARE @dt AS DATE = NULL; SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
El plan es el mismo que se muestra anteriormente en la Figura 3.
También puede negar el predicado para buscar no coincidencias, así:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE NOT EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Esta consulta genera el siguiente resultado:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10847 2019-02-10 10856 2019-02-10 10871 2019-02-10 10867 2019-02-11 10874 2019-02-11 10870 2019-02-13 10884 2019-02-13 10840 2019-02-16 10887 2019-02-16 ... (825 rows affected)
Alternativamente, puede usar un predicado positivo, pero reemplace INTERSECT con EXCEPT, así:
DECLARE @dt AS DATE = '20190212'; SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
Tenga en cuenta que los planes en los dos casos podrían ser diferentes, así que asegúrese de experimentar en ambos sentidos con grandes cantidades de datos.
Conclusión
Los NULL agregan su parte de complejidad a la escritura de su código SQL. Siempre querrá pensar en el potencial de la presencia de NULL en los datos y asegurarse de usar las construcciones de consulta correctas y agregar la lógica relevante a sus soluciones para manejar los NULL correctamente. Ignorarlos es una forma segura de terminar con errores en su código. Este mes me enfoqué en qué son los NULL y cómo se manejan en las comparaciones que involucran constantes, variables, parámetros y columnas. El próximo mes continuaré la cobertura discutiendo las inconsistencias en el tratamiento de NULL en diferentes elementos del lenguaje y las características estándar que faltan para el manejo de NULL.