Los cambios en la representación interna de las tablas particionadas entre SQL Server 2005 y SQL Server 2008 dieron como resultado mejores planes de consulta y rendimiento en la mayoría de los casos (especialmente cuando se trata de ejecución en paralelo). Lamentablemente, los mismos cambios provocaron que algunas cosas que funcionaban bien en SQL Server 2005 de repente no funcionaran tan bien en SQL Server 2008 y versiones posteriores. Esta publicación analiza un ejemplo en el que el optimizador de consultas de SQL Server 2005 produjo un plan de ejecución superior en comparación con las versiones posteriores.
Tabla y datos de muestra
Los ejemplos en esta publicación usan la siguiente tabla y datos particionados:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T4
(
RowID integer IDENTITY NOT NULL,
SomeData integer NOT NULL,
CONSTRAINT PK_T4
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T4 WITH (TABLOCKX)
(SomeData)
SELECT
ABS(CHECKSUM(NEWID()))
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
CREATE NONCLUSTERED INDEX nc1
ON dbo.T4 (SomeData)
ON PS (RowID); Diseño de datos particionados
Nuestra tabla tiene un índice agrupado particionado. En este caso, la clave de agrupación también sirve como clave de partición (aunque esto no es un requisito, en general). La partición da como resultado unidades de almacenamiento físico separadas (conjuntos de filas) que el procesador de consultas presenta a los usuarios como una sola entidad.
El siguiente diagrama muestra las tres primeras particiones de nuestra tabla (haga clic para ampliar):
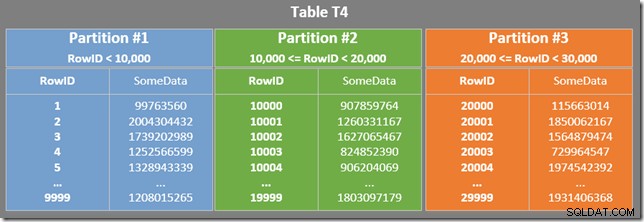
El índice no agrupado se particiona de la misma manera (está "alineado"):

Cada partición del índice no agrupado cubre un rango de valores de RowID. Dentro de cada partición, los datos están ordenados por SomeData (pero los valores de RowID no estarán ordenados en general).
El problema MÍN./MÁX.
Es razonablemente conocido que MIN y MAX los agregados no se optimizan bien en tablas particionadas (a menos que la columna que se agrega también sea la columna de partición). Esta limitación (que todavía existe en SQL Server 2014 CTP 1) se ha escrito muchas veces a lo largo de los años; mi cobertura favorita está en este artículo de Itzik Ben-Gan. Para ilustrar brevemente el problema, considere la siguiente consulta:
SELECT MIN(SomeData) FROM dbo.T4;
El plan de ejecución en SQL Server 2008 o superior es el siguiente:

Este plan lee las 150 000 filas del índice y un Stream Aggregate calcula el valor mínimo (el plan de ejecución es esencialmente el mismo si en su lugar solicitamos el valor máximo). El plan de ejecución de SQL Server 2005 es ligeramente diferente (aunque no mejor):
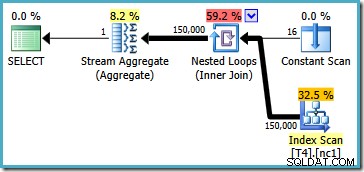
Este plan itera sobre los números de partición (enumerados en Constant Scan) escaneando completamente una partición a la vez. Las 150 000 filas aún son finalmente leídas y procesadas por Stream Aggregate.
Vuelva a mirar la tabla particionada y los diagramas de índice y piense en cómo la consulta podría procesarse de manera más eficiente en nuestro conjunto de datos. El índice no agrupado parece una buena opción para resolver la consulta porque contiene valores SomeData en un orden que podría aprovecharse al calcular el agregado.
Ahora bien, el hecho de que el índice esté particionado complica un poco las cosas:cada partición del índice está ordenado por la columna SomeData, pero no podemos simplemente leer el valor más bajo de cualquier particular partición para obtener la respuesta correcta a toda la consulta.
Una vez que se comprende la naturaleza esencial del problema, un ser humano puede ver que una estrategia eficiente sería encontrar el valor único más bajo de SomeData en cada partición del índice y luego tome el valor más bajo de los resultados por partición.
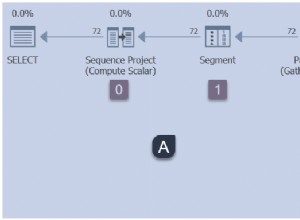
Esta es esencialmente la solución alternativa que presenta Itzik en su artículo; reescriba la consulta para calcular un agregado por partición (usando APPLY sintaxis) y luego agregar nuevamente sobre esos resultados por partición. Usando ese enfoque, el MIN reescrito consulta produce este plan de ejecución (consulte el artículo de Itzik para conocer la sintaxis exacta):
Este plan lee los números de partición de una tabla del sistema y recupera el valor más bajo de SomeData en cada partición. El Stream Aggregate final solo calcula el mínimo sobre los resultados por partición.
La característica importante de este plan es que lee una fila única de cada partición (explotando el orden de clasificación del índice dentro de cada partición). Es mucho más eficiente que el plan del optimizador que procesó las 150 000 filas de la tabla.
MIN y MAX dentro de una sola partición
Ahora considere la siguiente consulta para encontrar el valor mínimo en la columna SomeData, para un rango de valores RowID que están contenidos dentro de una sola partición :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 18000;
Hemos visto que el optimizador tiene problemas con MIN y MAX sobre múltiples particiones, pero esperaríamos que esas limitaciones no se apliquen a una sola consulta de partición.
La partición única es la que está delimitada por los valores RowID 10 000 y 20 000 (consulte la definición de la función de partición). La función de partición se definió como RANGE RIGHT , por lo que el valor del límite de 10 000 pertenece a la partición n.º 2 y el límite de 20 000 pertenece a la partición n.º 3. Por lo tanto, el rango de valores de RowID especificado por nuestra nueva consulta está contenido solo en la partición 2.
Los planes de ejecución gráfica para esta consulta tienen el mismo aspecto en todas las versiones de SQL Server desde 2005 en adelante:
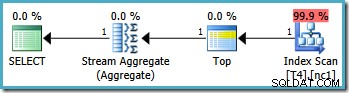
Análisis del plan
El optimizador tomó el rango RowID especificado en WHERE y la comparó con la definición de la función de partición para determinar que solo se necesitaba acceder a la partición 2 del índice no agrupado. Las propiedades del plan de SQL Server 2005 para Index Scan muestran claramente el acceso a una sola partición:
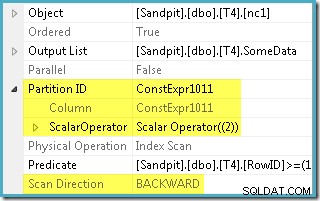
La otra propiedad resaltada es la Dirección de escaneo. El orden de la exploración difiere dependiendo de si la consulta busca el valor mínimo o máximo de SomeData. El índice no agrupado se ordena (por partición, recuerde) en valores ascendentes de SomeData, por lo que la dirección de exploración del índice es FORWARD si la consulta solicita el valor mínimo, y BACKWARD si se necesita el valor máximo (la captura de pantalla anterior se tomó del MAX plan de consultas).
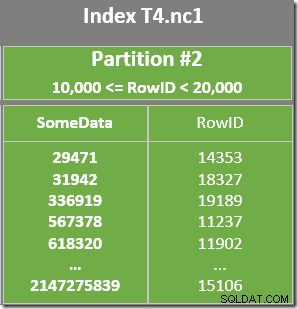
También hay un predicado residual en el escaneo de índice para verificar que los valores de RowID escaneados desde la partición 2 coincidan con WHERE predicado de la cláusula. El optimizador asume que los valores de RowID se distribuyen de manera bastante aleatoria a través del índice no agrupado, por lo que espera encontrar la primera fila que coincida con WHERE predicado de la cláusula con bastante rapidez. El diagrama de diseño de datos particionados muestra que los valores de RowID se distribuyen de manera bastante aleatoria en el índice (que está ordenado por la columna SomeData, recuerde):
El operador superior en el plan de consulta limita el escaneo de índice a una sola fila (desde el extremo inferior o superior del índice según la dirección de escaneo). Los escaneos de índice pueden ser problemáticos en los planes de consulta, pero el operador Top lo convierte en una opción eficiente aquí:el escaneo solo puede producir una fila y luego se detiene. La combinación de Escaneo superior e índice ordenado realiza de manera efectiva una búsqueda del valor más alto o más bajo en el índice que también coincide con el WHERE predicados de la cláusula. También aparece un Stream Aggregate en el plan para garantizar que un NULL se genera en caso de que Index Scan no devuelva filas. Escalar MIN y MAX los agregados están definidos para devolver un NULL cuando la entrada es un conjunto vacío.
En general, esta es una estrategia muy eficiente y los planes tienen un costo estimado de solo 0.0032921 unidades como resultado. Hasta ahora todo bien.
El problema del valor límite
El siguiente ejemplo modifica el extremo superior del rango RowID:
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000;
Observe que la consulta excluye el valor 20,000 usando un operador "menor que". Recuerde que el valor 20,000 pertenece a la partición 3 (no a la partición 2) porque la función de partición se define como RANGE RIGHT . El Servidor SQL 2005 El optimizador maneja esta situación correctamente, produciendo el plan de consulta de partición única óptimo, con un costo estimado de 0.0032878 :
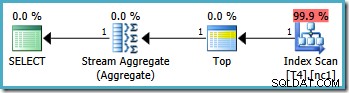
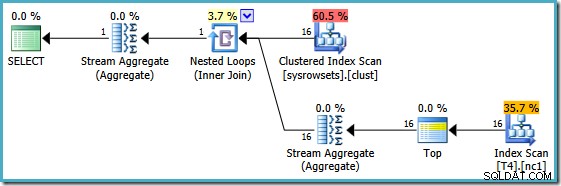
Sin embargo, la misma consulta produce un plan diferente en SQL Server 2008 y posteriores (incluido SQL Server 2014 CTP 1):
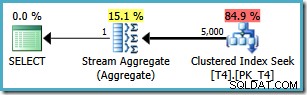
Ahora tenemos una búsqueda de índice agrupado (en lugar de la combinación deseada de exploración de índice y operador superior). Las 5000 filas que coinciden con WHERE se procesan a través de Stream Aggregate en este nuevo plan de ejecución. El costo estimado de este plan es 0.0199319 unidades:más de seis veces el costo del plan SQL Server 2005.
Causa
Los optimizadores de SQL Server 2008 (y posteriores) no entienden bien la lógica interna cuando un intervalo hace referencia, pero excluye , un valor límite que pertenece a una partición diferente. El optimizador piensa incorrectamente que se accederá a varias particiones y concluye que no puede usar la optimización de partición única para MIN y MAX agregados.
Soluciones alternativas
Una opción es reescribir la consulta usando los operadores>=y <=para que no hagamos referencia a un valor límite de otra partición (¡incluso para excluirlo!):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID <= 19999;
Esto da como resultado el plan óptimo, tocando una sola partición:
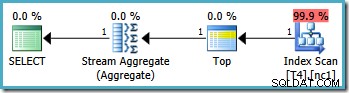
Desafortunadamente, no siempre es posible especificar valores límite correctos de esta manera (dependiendo del tipo de columna de partición). Un ejemplo de eso es con los tipos de fecha y hora donde es mejor usar intervalos semiabiertos. Otra objeción a esta solución es más subjetiva:la función de partición excluye un límite del rango, por lo que parece más natural escribir la consulta también usando la sintaxis de intervalo semiabierto.
Una segunda solución consiste en especificar el número de partición explícitamente (y conservar el intervalo semiabierto):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000 AND $PARTITION.PF(RowID) = 2;
Esto produce el plan óptimo, con el costo de requerir un predicado adicional y confiar en que el usuario determine cuál debería ser el número de partición.
Por supuesto, sería mejor si los optimizadores de 2008 y posteriores produjeran el mismo plan óptimo que SQL Server 2005. En un mundo perfecto, una solución más integral también abordaría el caso de varias particiones, lo que haría innecesaria la solución alternativa que Itzik describe.