La partición de tablas en SQL Server es esencialmente una forma de hacer que varias tablas físicas (conjuntos de filas) parezcan una sola tabla. Esta abstracción la realiza completamente el procesador de consultas, un diseño que simplifica las cosas para los usuarios, pero que plantea demandas complejas al optimizador de consultas. Esta publicación analiza dos ejemplos que superan las capacidades del optimizador en SQL Server 2008 en adelante.
El orden de las columnas de unión es importante
Este primer ejemplo muestra cómo el orden textual de ON Las condiciones de la cláusula pueden afectar el plan de consulta producido al unir tablas particionadas. Para empezar, necesitamos un esquema de partición, una función de partición y dos tablas:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T1
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T1
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
);
CREATE TABLE dbo.T2
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T2
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
); A continuación, cargamos ambas tablas con 150 000 filas. Los datos no importan mucho; este ejemplo utiliza una tabla de números estándar que contiene todos los valores enteros del 1 al 150 000 como fuente de datos. Ambas tablas se cargan con los mismos datos.
INSERT dbo.T1 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
INSERT dbo.T2 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
Nuestra consulta de prueba realiza una combinación interna simple de estas dos tablas. Nuevamente, la consulta no es importante ni pretende ser particularmente realista, se usa para demostrar un efecto extraño al unir tablas particionadas. La primera forma de la consulta usa un ON cláusula escrita en el orden de las columnas c3, c2, c1:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1; El plan de ejecución generado para esta consulta (en SQL Server 2008 y versiones posteriores) presenta una unión hash paralela, con un costo estimado de 2,6953 :
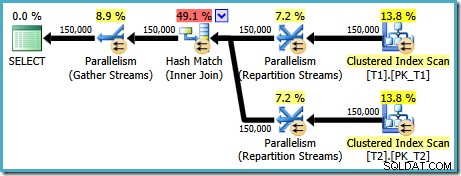
Esto es un poco inesperado. Ambas tablas tienen un índice agrupado en orden (c1, c2, c3), particionado por c1, por lo que esperaríamos una combinación de combinación, aprovechando el orden del índice. Intentemos escribir ON cláusula en el orden (c1, c2, c3) en su lugar:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c1 = t2.c1
AND t1.c2 = t2.c2
AND t1.c3 = t2.c3; El plan de ejecución ahora usa la combinación de fusión esperada, con un costo estimado de 1.64119 (por debajo de 2.6953 ). El optimizador también decide que no vale la pena usar la ejecución en paralelo:
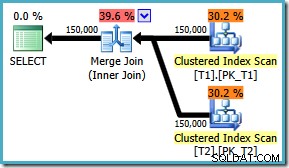
Teniendo en cuenta que el plan de combinación de combinación es claramente más eficiente, podemos intentar forzar una combinación de combinación para el ON original orden de la cláusula usando una sugerencia de consulta:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (MERGE JOIN); El plan resultante usa una combinación de combinación según lo solicitado, pero también presenta ordenaciones en ambas entradas y vuelve a usar el paralelismo. El costo estimado de este plan es la friolera de 8.71063 :
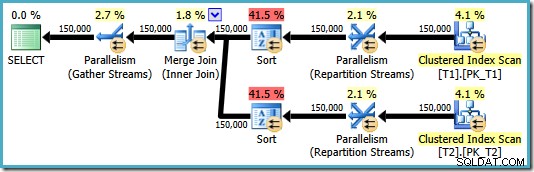
Ambos operadores de clasificación tienen las mismas propiedades:
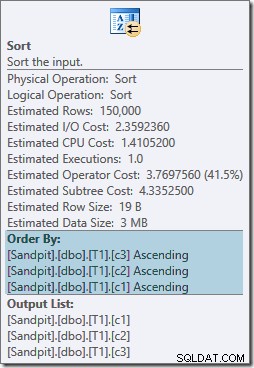
El optimizador cree que la combinación de combinación necesita que sus entradas se clasifiquen en el estricto orden escrito de ON cláusula, introduciendo géneros explícitos como resultado. El optimizador es consciente de que una combinación de combinación requiere que sus entradas se clasifiquen de la misma manera, pero también sabe que el orden de las columnas no importa. Merge join en (c1, c2, c3) es igualmente feliz con las entradas ordenadas en (c3, c2, c1) que con las entradas ordenadas en (c2, c1, c3) o cualquier otra combinación.
Desafortunadamente, este razonamiento se rompe en el optimizador de consultas cuando se trata de particiones. Este es un error del optimizador que se ha corregido en SQL Server 2008 R2 y versiones posteriores, aunque el indicador de seguimiento 4199 es necesario para activar la corrección:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (QUERYTRACEON 4199);
Normalmente, habilitaría esta marca de rastreo usando DBCC TRACEON o como opción de inicio, porque el QUERYTRACEON la sugerencia no está documentada para su uso con 4199. La marca de seguimiento es necesaria en SQL Server 2008 R2, SQL Server 2012 y SQL Server 2014 CTP1.
De todos modos, independientemente de cómo esté habilitada la bandera, la consulta ahora produce la combinación de combinación óptima cualquiera que sea el ON ordenación de cláusulas:
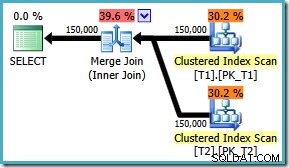
No hay ninguna solución para SQL Server 2008 , la solución es escribir ON cláusula en el orden 'correcto'! Si encuentra una consulta como esta en SQL Server 2008, intente forzar una combinación de combinación y observe los tipos para determinar la forma "correcta" de escribir su consulta ON cláusula.
Este problema no surge en SQL Server 2005 porque esa versión implementó consultas particionadas usando APPLY modelo:

El plan de consulta de SQL Server 2005 une una partición de cada tabla a la vez, utilizando una tabla en memoria (la Exploración constante) que contiene números de partición para procesar. Cada partición se combina por separado en el lado interno de la unión, y el optimizador de 2005 es lo suficientemente inteligente como para ver que ON el orden de las columnas de la cláusula no importa.
Este último plan es un ejemplo de una unión de fusión colocada , una función que se perdió al pasar de SQL Server 2005 a la nueva implementación de particiones en SQL Server 2008. Una sugerencia sobre Conectar para restablecer las uniones de combinación colocadas se cerró como No se solucionará.
Agrupar por orden importa
La segunda peculiaridad que quiero ver sigue un tema similar, pero se relaciona con el orden de las columnas en un GROUP BY cláusula en lugar de ON cláusula de una unión interna. Necesitaremos una nueva tabla para demostrar:
CREATE TABLE dbo.T3
(
RowID integer IDENTITY NOT NULL,
UserID integer NOT NULL,
SessionID integer NOT NULL,
LocationID integer NOT NULL,
CONSTRAINT PK_T3
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T3 WITH (TABLOCKX)
(UserID, SessionID, LocationID)
SELECT
ABS(CHECKSUM(NEWID())) % 50,
ABS(CHECKSUM(NEWID())) % 30,
ABS(CHECKSUM(NEWID())) % 10
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000; La tabla tiene un índice no agrupado alineado, donde "alineado" simplemente significa que está particionado de la misma manera que el índice agrupado (o montón):
CREATE NONCLUSTERED INDEX nc1 ON dbo.T3 (UserID, SessionID, LocationID) ON PS (RowID);
Nuestra consulta de prueba agrupa datos en las tres columnas de índice no agrupadas y devuelve un recuento para cada grupo:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 GROUP BY LocationID, UserID, SessionID;
El plan de consulta escanea el índice no agrupado y usa un Hash Match Aggregate para contar filas en cada grupo:
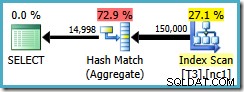
Hay dos problemas con Hash Aggregate:
- Es un operador de bloqueo. No se devuelven filas al cliente hasta que se hayan agregado todas las filas.
- Requiere una concesión de memoria para mantener la tabla hash.
En muchos escenarios del mundo real, preferiríamos un Stream Aggregate aquí porque ese operador solo bloquea por grupo y no requiere una concesión de memoria. Con esta opción, la aplicación del cliente comenzaría a recibir datos antes, no tendría que esperar a que se concediera la memoria y SQL Server puede usar la memoria para otros fines.
Podemos requerir que el optimizador de consultas use un Stream Aggregate para esta consulta agregando una OPTION (ORDER GROUP) sugerencia de consulta. Esto da como resultado el siguiente plan de ejecución:

El operador Sort bloquea completamente y también requiere una concesión de memoria, por lo que este plan parece ser peor que simplemente usar un agregado de hash. Pero, ¿por qué se necesita el tipo? Las propiedades muestran que las filas se ordenan en el orden especificado por nuestro GROUP BY cláusula:
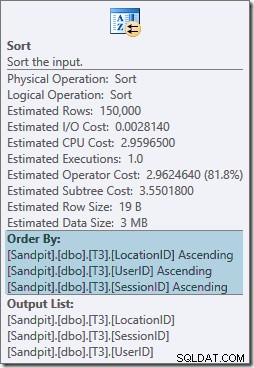
Este tipo es esperado porque la alineación de particiones del índice (en SQL Server 2008 en adelante) significa que el número de partición se agrega como una columna inicial del índice. En efecto, las claves de índice no agrupadas son (partición, usuario, sesión, ubicación) debido a la partición. Las filas del índice aún se ordenan por usuario, sesión y ubicación, pero solo dentro de cada partición.
Si restringimos la consulta a una sola partición, el optimizador debería poder usar el índice para alimentar un Stream Aggregate sin ordenar. En caso de que eso requiera alguna explicación, especificar una sola partición significa que el plan de consulta puede eliminar todas las demás particiones del análisis de índice no agrupado, lo que da como resultado una secuencia de filas ordenadas por (usuario, sesión, ubicación).
Podemos lograr esta eliminación de partición explícitamente usando $PARTITION función:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID;
Desafortunadamente, esta consulta todavía usa un Hash Aggregate, con un costo de plan estimado de 0.287878 :
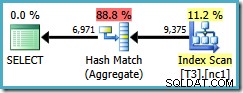
El escaneo ahora es solo sobre una partición, pero el orden (usuario, sesión, ubicación) no ha ayudado al optimizador a usar un Stream Aggregate. Puede objetar que el orden (usuario, sesión, ubicación) no es útil porque GROUP BY la cláusula es (ubicación, usuario, sesión), pero el orden de las claves no importa para una operación de agrupación.
Agreguemos un ORDER BY cláusula en el orden de las claves de índice para probar el punto:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID ORDER BY UserID, SessionID, LocationID;
Observe que ORDER BY la cláusula coincide con el orden de la clave del índice no agrupado, aunque el GROUP BY la cláusula no lo hace. El plan de ejecución para esta consulta es:
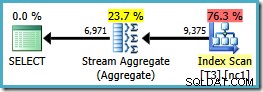
Ahora tenemos el Stream Aggregate que buscábamos, con un costo de plan estimado de 0.0423925 (en comparación con 0.287878 para el plan Hash Aggregate, casi 7 veces más).
La otra forma de lograr un Stream Aggregate aquí es reordenar el GROUP BY columnas para que coincidan con las claves de índice no agrupadas:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1 GROUP BY UserID, SessionID, LocationID;
Esta consulta produce el mismo plan Stream Aggregate que se muestra inmediatamente arriba, con exactamente el mismo costo. Esta sensibilidad a GROUP BY el orden de las columnas es específico para consultas de tablas particionadas en SQL Server 2008 y versiones posteriores.
Es posible que reconozca que la causa raíz del problema aquí es similar al caso anterior relacionado con una combinación de combinación. Tanto Merge Join como Stream Aggregate requieren entrada ordenada en las claves de unión o agregación, pero a ninguno le importa el orden de esas claves. Un Merge Join en (x, y, z) es igual de feliz al recibir filas ordenadas por (y, z, x) o (z, y, x) y lo mismo es cierto para Stream Aggregate.
Esta limitación del optimizador también se aplica a DISTINCT en las mismas circunstancias. La siguiente consulta da como resultado un plan Hash Aggregate con un costo estimado de 0.286539 :
SELECT DISTINCT LocationID, UserID, SessionID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
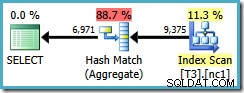
Si escribimos el DISTINCT columnas en el orden de las claves de índice no agrupadas...
SELECT DISTINCT UserID, SessionID, LocationID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
… somos recompensados con un plan Stream Aggregate con un costo de 0.041455 :

Para resumir, esta es una limitación del optimizador de consultas en SQL Server 2008 y versiones posteriores (incluido SQL Server 2014 CTP 1) que no se resuelve usando el indicador de seguimiento 4199 como fue el caso del ejemplo Merge Join. El problema solo ocurre con tablas particionadas con un GROUP BY o DISTINCT sobre tres o más columnas usando un índice particionado alineado, donde se procesa una sola partición.
Al igual que con el ejemplo Merge Join, esto representa un paso atrás del comportamiento de SQL Server 2005. SQL Server 2005 no agregó una clave principal implícita a los índices particionados, usando un APPLY técnica en su lugar. En SQL Server 2005, todas las consultas presentadas aquí usan $PARTITION para especificar un único resultado de partición en los planes de consulta que realiza la eliminación de particiones y usa Agregados de flujo sin reordenar el texto de la consulta.
Los cambios en el procesamiento de tablas particionadas en SQL Server 2008 mejoraron el rendimiento en varias áreas importantes, principalmente relacionadas con el procesamiento paralelo eficiente de particiones. Desafortunadamente, estos cambios tuvieron efectos secundarios que no se han resuelto en versiones posteriores.