Tan pronto como comienza a ejecutar un servidor de base de datos y su uso crece, se expone a muchos tipos de problemas técnicos, degradación del rendimiento y mal funcionamiento de la base de datos. Cada uno de estos podría generar problemas mucho mayores, como fallas catastróficas o pérdida de datos. Es como una reacción en cadena, donde una cosa puede llevar a la otra, causando más y más problemas. Se deben realizar contramedidas proactivas para que usted tenga un entorno estable el mayor tiempo posible.
En esta publicación de blog, vamos a ver un montón de características geniales que ofrece ClusterControl que pueden ayudarnos mucho a solucionar y solucionar los problemas de nuestra base de datos MySQL cuando ocurran.
Alarmas y notificaciones de la base de datos
Para todos los eventos no deseados, ClusterControl registrará todo en Alarmas, accesible en la página Actividad (menú superior) de ClusterControl. Este suele ser el primer paso para comenzar a solucionar problemas cuando algo sale mal. Desde esta página, podemos tener una idea de lo que realmente está pasando con nuestro clúster de base de datos:
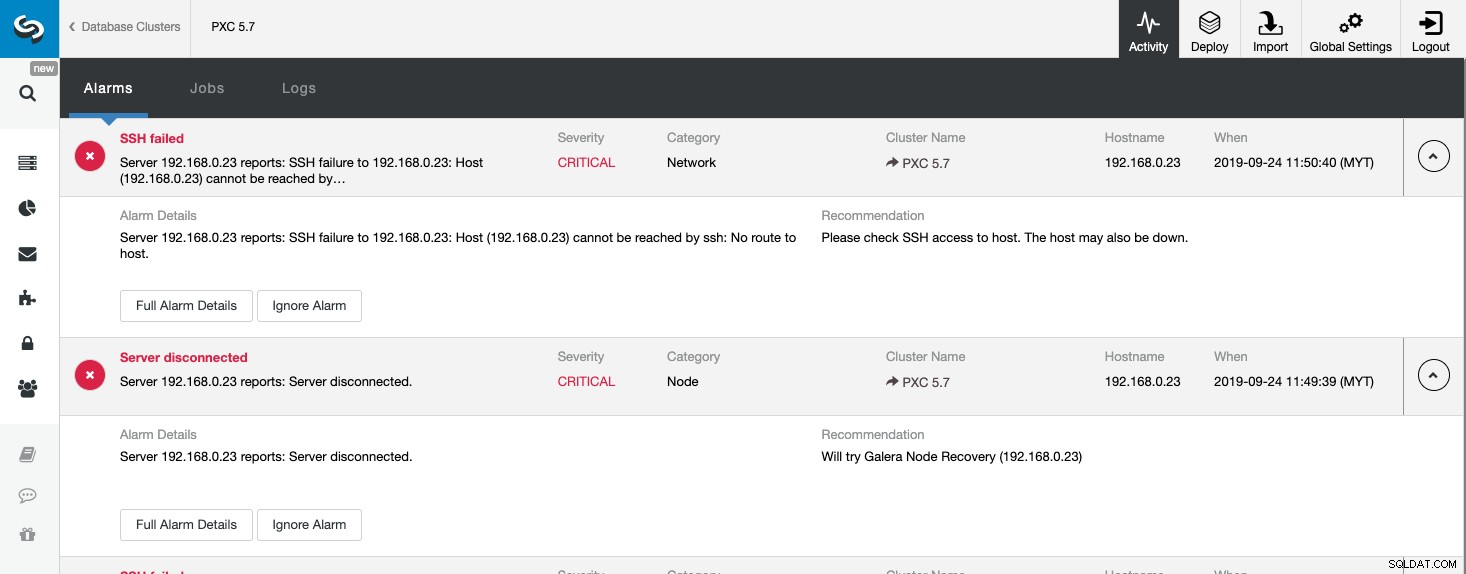
La captura de pantalla anterior muestra un ejemplo de un evento de servidor inalcanzable, con gravedad CRÍTICA , detectado por dos componentes, Network y Node. Si ha configurado la configuración de notificaciones por correo electrónico, debería recibir una copia de estas alarmas en su buzón.
Al hacer clic en "Detalles completos de la alarma", puede obtener los detalles importantes de la alarma, como el nombre de host, la marca de tiempo, el nombre del clúster, etc. También proporciona el siguiente paso recomendado a seguir. También puede enviar esta alarma como un correo electrónico a otros destinatarios configurados en Configuración de notificación por correo electrónico.
También puede optar por silenciar una alarma haciendo clic en el botón "Ignorar alarma" y no volverá a aparecer en la lista. Ignorar una alarma puede ser útil si tiene una alarma de gravedad baja y sabe cómo manejarla o solucionarla. Por ejemplo, si ClusterControl detecta un índice duplicado en su base de datos, donde en algunos casos sus aplicaciones heredadas lo necesitarían.
Al mirar esta página, podemos obtener una comprensión inmediata de lo que está sucediendo con nuestro clúster de base de datos y cuál es el siguiente paso para resolver el problema. Como en este caso, uno de los nodos de la base de datos dejó de funcionar y no se pudo acceder a través de SSH desde el host de ClusterControl. Incluso un administrador de sistemas principiante ahora sabría qué hacer a continuación si aparece esta alarma.
Archivos de registro de la base de datos centralizada
Aquí es donde podemos profundizar en el problema de nuestro servidor de base de datos. En ClusterControl -> Registros -> Registros del sistema, puede ver todos los archivos de registro relacionados con el clúster de la base de datos. En cuanto al clúster de base de datos basado en MySQL, ClusterControl extrae el registro de ProxySQL, el registro de errores de MySQL y los registros de copia de seguridad:
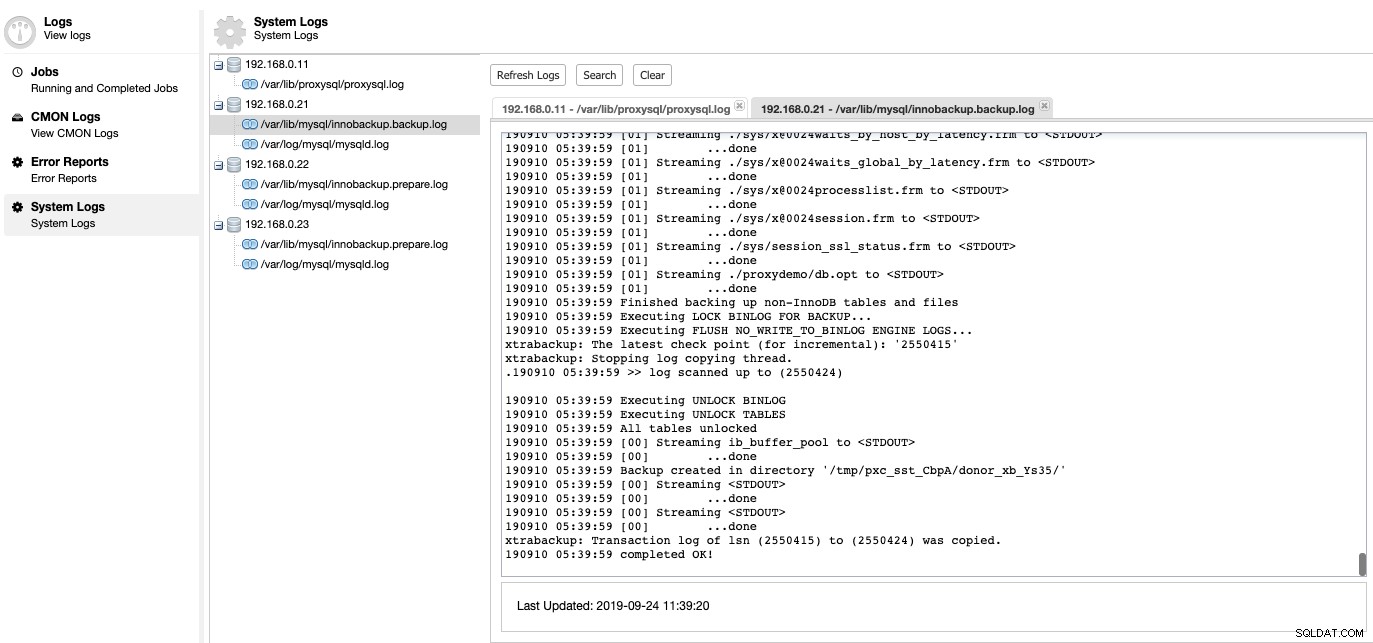
Haga clic en "Actualizar registro" para recuperar el último registro de todos los hosts a los que se puede acceder en ese momento en particular. Si no se puede acceder a un nodo, ClusterControl aún verá el inicio de sesión desactualizado ya que esta información se almacena dentro de la base de datos de CMON. Por defecto, ClusterControl sigue recuperando los registros del sistema cada 10 minutos, configurable en Configuración -> Intervalo de registro.
ClusterControl activará el trabajo para extraer el registro más reciente de cada servidor, como se muestra en el siguiente trabajo "Recopilar registros":
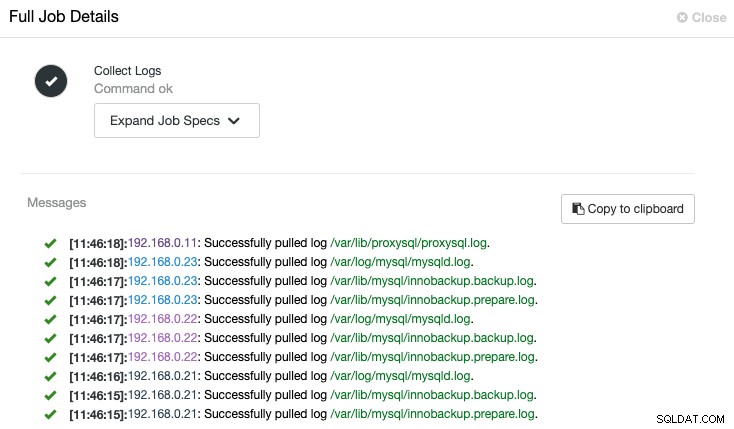
Una vista centralizada del archivo de registro nos permite tener una comprensión más rápida de lo que sucedió equivocado. Para un clúster de base de datos que comúnmente involucra múltiples nodos y niveles, esta característica mejorará en gran medida la lectura de registros donde un SysAdmin puede comparar estos registros uno al lado del otro y señalar eventos críticos, reduciendo el tiempo total de resolución de problemas.
Consola Web SSH
ClusterControl proporciona una consola SSH basada en la web para que pueda acceder al servidor DB directamente a través de la interfaz de usuario de ClusterControl (ya que el usuario SSH está configurado para conectarse a los hosts de la base de datos). Desde aquí, podemos recopilar mucha más información que nos permite solucionar el problema aún más rápido. Todo el mundo sabe cuándo un problema de base de datos afecta al sistema de producción, cada segundo de tiempo de inactividad cuenta.
Para acceder a la consola SSH a través de la web, simplemente elija los nodos en Nodos -> Acciones de nodo -> Consola SSH, o simplemente haga clic en el icono de engranaje para acceder a un acceso directo:
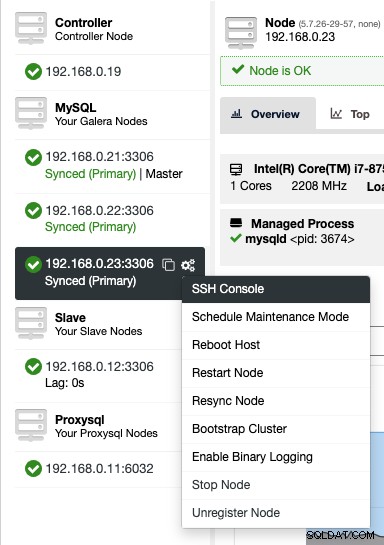
Debido a problemas de seguridad que pueden surgir con esta característica, especialmente para múltiples -usuario o entorno multiinquilino, uno puede deshabilitarlo yendo a /var/www/html/clustercontrol/bootstrap.php en el servidor ClusterControl y establecer la siguiente constante en falso:
define('SSH_ENABLED', false);Actualice la página de interfaz de usuario de ClusterControl para cargar los nuevos cambios.
Problemas de rendimiento de la base de datos
Además de las funciones de seguimiento y tendencias, ClusterControl le envía proactivamente varias alarmas y avisos relacionados con el rendimiento de la base de datos, por ejemplo:
- Uso excesivo:recurso que supera ciertos umbrales, como CPU, memoria, uso de intercambio y espacio en disco.
- Degradación del clúster:partición del clúster y de la red.
- Desviación del tiempo del sistema:diferencia de tiempo entre todos los nodos del clúster (incluido el nodo ClusterControl).
- Varios otros asesores relacionados con MySQL:
- Replicación:retraso de la replicación, caducidad del binlog, ubicación y crecimiento
- Galera:método SST, escaneo del archivo de registro GRA, verificador de direcciones de clúster
- Comprobación de esquema:existencia de tablas no transaccionales en Galera Cluster.
- Conexiones:proporción de hilos conectados
- InnoDB:proporción de páginas sucias, crecimiento del archivo de registro de InnoDB
- Consultas lentas:de forma predeterminada, ClusterControl activará una alarma si encuentra una consulta que se ejecuta durante más de 30 segundos. Por supuesto, esto se puede configurar en Configuración -> Configuración de tiempo de ejecución -> Consulta larga.
- Interbloqueos:interbloqueo de transacciones de InnoDB y interbloqueo de Galera.
- Índices:claves duplicadas, tabla sin claves principales.
Consulte la página de asesores en Rendimiento -> Asesores para obtener los detalles de las cosas que se pueden mejorar según lo sugerido por ClusterControl. Para cada asesor, proporciona justificaciones y consejos como se muestra en el siguiente ejemplo para el asesor "Comprobación del uso del espacio en disco":
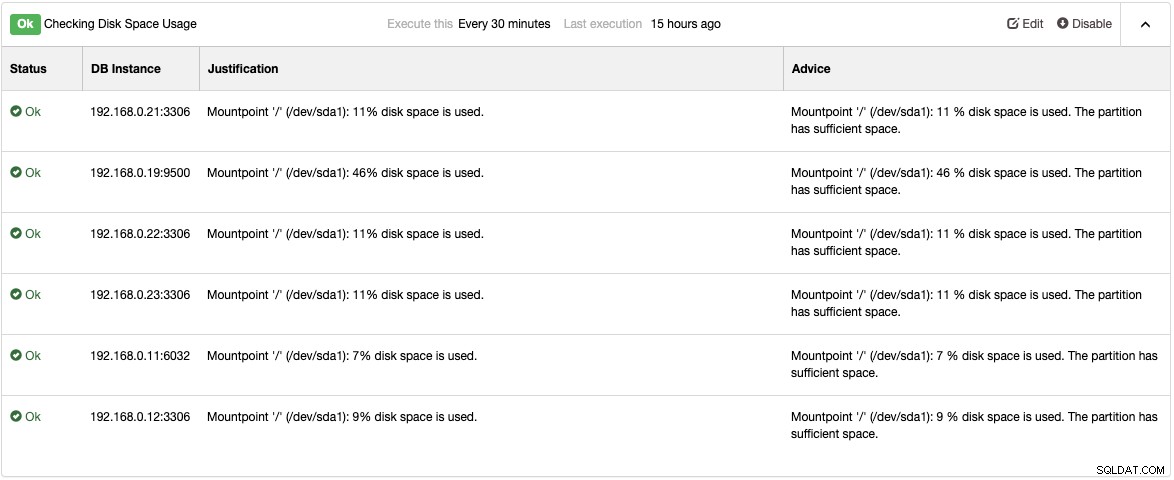
Cuando se produzca un problema de rendimiento, obtendrá una "Advertencia" (amarillo) o Estado "crítico" (rojo) en estos asesores. Por lo general, se requiere un ajuste adicional para superar el problema. Los asesores emiten alarmas, lo que significa que los usuarios obtendrán una copia de estas alarmas dentro del buzón si las notificaciones por correo electrónico están configuradas en consecuencia. Por cada alarma emitida por ClusterControl o sus asesores, los usuarios también recibirán un correo electrónico si la alarma se ha eliminado. Estos están preconfigurados dentro de ClusterControl y no requieren configuración inicial. Siempre es posible una mayor personalización en Administrar -> Developer Studio. Puede consultar esta publicación de blog sobre cómo escribir su propio asesor.
ClusterControl también proporciona una página dedicada al rendimiento de la base de datos en ClusterControl -> Rendimiento. Proporciona todo tipo de información sobre la base de datos siguiendo las mejores prácticas, como la vista centralizada del estado de la base de datos, las variables, el estado de InnoDB, el analizador de esquemas y los registros de transacciones. Estos se explican por sí mismos y son fáciles de entender.
Para el rendimiento de las consultas, puede inspeccionar las consultas principales y los valores atípicos de las consultas, donde ClusterControl resalta las consultas que se realizaron de forma significativamente diferente a la consulta promedio. Hemos tratado este tema en detalle en esta publicación de blog, Ajuste del rendimiento de consultas de MySQL.
Informes de errores de la base de datos
ClusterControl viene con una herramienta generadora de informes de errores para recopilar información de depuración sobre su clúster de base de datos para ayudar a comprender la situación y el estado actual. Para generar un informe de errores, simplemente vaya a ClusterControl -> Registros -> Informes de errores -> Crear informe de errores:
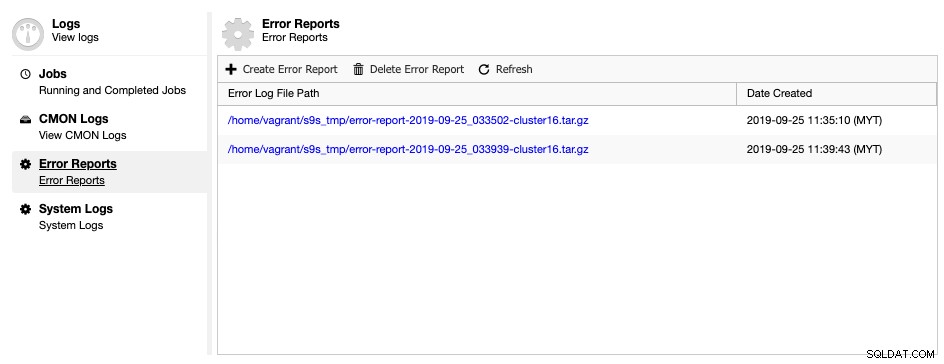
El informe de error generado se puede descargar desde esta página una vez que esté listo. Este informe generado estará en formato de bola TAR (tar.gz) y puede adjuntarlo a una solicitud de soporte. Dado que el ticket de soporte tiene un límite de 10 MB de tamaño de archivo, si el tamaño del tarball es mayor que eso, puede cargarlo en una unidad en la nube y solo compartir con nosotros el enlace de descarga con el permiso adecuado. Puede eliminarlo más tarde una vez que ya tengamos el archivo. También puede generar el informe de errores a través de la línea de comandos como se explica en la página de documentación del Informe de errores.
En caso de una interrupción, le recomendamos que genere varios informes de error durante la interrupción y justo después. Esos informes serán muy útiles para tratar de comprender qué salió mal, las consecuencias de la interrupción y para verificar que el clúster vuelva a estar operativo después de un evento desastroso.
Conclusión
La supervisión proactiva de ClusterControl, junto con un conjunto de funciones de solución de problemas, proporciona una plataforma eficiente para que los usuarios resuelvan cualquier tipo de problema con la base de datos MySQL. Atrás quedó la forma heredada de resolución de problemas en la que uno tiene que abrir múltiples sesiones SSH para acceder a múltiples hosts y ejecutar múltiples comandos repetidamente para identificar la causa raíz.
Si las características mencionadas anteriormente no lo ayudan a resolver el problema o solucionar el problema de la base de datos, siempre comuníquese con el equipo de soporte de Variousnines para que lo respalde. Nuestros expertos técnicos dedicados las 24 horas del día, los 7 días de la semana, los 365 días del año están disponibles para atender su solicitud en cualquier momento. Nuestro tiempo medio de primera respuesta suele ser inferior a 30 minutos.