Recientemente hemos escrito varios blogs que cubren cómo los diferentes proveedores de nube manejan la conmutación por error de la base de datos. Comparamos el rendimiento de la conmutación por error en Amazon Aurora, Amazon RDS y ClusterControl, probamos el comportamiento de la conmutación por error en Amazon RDS y también en Google Cloud Platform. Si bien esos servicios brindan excelentes opciones cuando se trata de conmutación por error, es posible que no sean adecuados para todas las aplicaciones.
En esta publicación de blog, dedicaremos un poco de tiempo a analizar los pros y los contras de usar las soluciones DBaaS en comparación con el diseño de un entorno de forma manual o mediante el uso de una plataforma de administración de bases de datos, como ClusterControl.
Implementación de bases de datos de alta disponibilidad con soluciones administradas
La razón principal para usar las soluciones existentes es la facilidad de uso. Puede implementar una solución de alta disponibilidad con conmutación por error automatizada con solo un par de clics. No es necesario combinar diferentes herramientas, administrar las bases de datos manualmente, implementar herramientas, escribir scripts, diseñar el monitoreo o cualquier otra operación de administración de bases de datos. Todo ya está en su lugar. Esto puede reducir considerablemente la curva de aprendizaje y requiere menos experiencia para configurar un entorno de alta disponibilidad para las bases de datos; permitiendo básicamente que todos implementen tales configuraciones.
En la mayoría de los casos con estas soluciones, el proceso de conmutación por error se ejecuta en un tiempo razonable. Puede ser increíblemente rápido como con Amazon Aurora o un poco más lento como con los nodos SQL de Google Cloud Platform. Para la mayoría de los casos, este tipo de resultados son aceptables.
El resultado final. Si puede aceptar entre 30 y 60 segundos de tiempo de inactividad, debería poder utilizar cualquiera de las plataformas DBaaS.
La desventaja de usar una solución administrada para HA
Si bien las soluciones DBaaS son fáciles de usar, también presentan algunos inconvenientes graves. Para empezar, siempre hay un componente de bloqueo de proveedor a considerar. Una vez que implementa un clúster en Amazon Web Services, es bastante complicado migrar fuera de ese proveedor. No existen métodos sencillos para descargar el conjunto de datos completo a través de una copia de seguridad física. Con la mayoría de los proveedores, solo están disponibles las copias de seguridad lógicas ejecutadas manualmente. Claro, siempre hay opciones para lograr esto, pero normalmente es un proceso complejo y lento, que aún puede requerir algún tiempo de inactividad después de todo.
Usar un proveedor como Amazon RDS también tiene limitaciones. Algunas acciones no se pueden realizar fácilmente, lo que sería muy sencillo de lograr en entornos implementados de una manera totalmente controlada por el usuario (por ejemplo, AWS EC2). Algunas de estas limitaciones ya se han tratado en otros blogs, pero para resumir, ningún servicio DBaaS le brinda el mismo nivel de flexibilidad que la replicación regular basada en GTID de MySQL. Puede promocionar cualquier esclavo, puede volver a esclavizar cada nodo de cualquier otro... prácticamente todas las acciones son posibles. Con herramientas como RDS, enfrenta limitaciones inducidas por el diseño que no puede eludir.
El problema también radica en la capacidad de comprender los detalles del rendimiento. Cuando diseña su propia configuración de alta disponibilidad, adquiere conocimiento sobre los posibles problemas de rendimiento que pueden surgir. Por otro lado, RDS y entornos similares son prácticamente "cajas negras". Sí, hemos aprendido que Amazon RDS usa DRBD para crear una instantánea del maestro, sabemos que Aurora usa almacenamiento compartido y replicado para implementar conmutaciones por error muy rápidas. Eso es solo un conocimiento general. No podemos decir cuáles son las implicaciones de rendimiento de esas soluciones aparte de lo que podríamos notar casualmente. ¿Cuáles son los problemas comunes asociados con ellos? ¿Qué tan estables son esas soluciones? Solo los desarrolladores detrás de la solución lo saben con certeza.
¿Cuál es la alternativa a las soluciones DBaaS?
Puede preguntarse, ¿existe una alternativa a DBaaS? Después de todo, es muy conveniente ejecutar el servicio administrado donde puede acceder a la mayoría de las acciones típicas a través de la interfaz de usuario. Puede crear y restaurar copias de seguridad, la conmutación por error se maneja automáticamente por usted. El entorno es fácil de usar, lo que puede ser atractivo para las empresas que no cuentan con personal dedicado y experimentado para manejar bases de datos.
ClusterControl proporciona una excelente alternativa a los servicios DBaaS basados en la nube. Le proporciona una interfaz gráfica de usuario, que se puede utilizar para implementar, administrar y monitorear bases de datos de código abierto.
Con un par de clics, puede implementar fácilmente un clúster de base de datos de alta disponibilidad, con conmutación por error automatizada (más rápida que la mayoría de las ofertas de DBaaS), administración de copias de seguridad, monitoreo avanzado y otras características como integración con herramientas externas. (por ejemplo, Slack o PagerDuty) o gestión de actualizaciones. Todo esto mientras se evita por completo el bloqueo de proveedores.
A ClusterControl no le importa dónde se encuentran sus bases de datos, siempre y cuando pueda conectarse a ellas mediante SSH. Puede tener configuraciones en la nube, en las instalaciones o en un entorno mixto de varios proveedores de la nube. Mientras haya conectividad, ClusterControl podrá administrar el entorno. Utilizar las soluciones que desea (y no las que no conoce ni conoce) le permite tomar el control total del entorno en cualquier momento.
Cualquiera que sea la configuración que implementó con ClusterControl, puede administrarla fácilmente de una manera más tradicional, manual o mediante secuencias de comandos. ClusterControl incluso le proporciona una interfaz de línea de comandos, que le permitirá incorporar tareas ejecutadas por ClusterControl en sus scripts de shell. Tiene todo el control que desea:nada es una caja negra, cada pieza del entorno se crearía utilizando soluciones de código abierto combinadas e implementadas por ClusterControl.
Echemos un vistazo a la facilidad con la que puede implementar un clúster de replicación de MySQL mediante ClusterControl. Supongamos que tiene el entorno preparado con ClusterControl instalado en una instancia y todos los demás nodos accesibles a través de SSH desde el host de ClusterControl.
Comenzaremos eligiendo el asistente "Implementar".
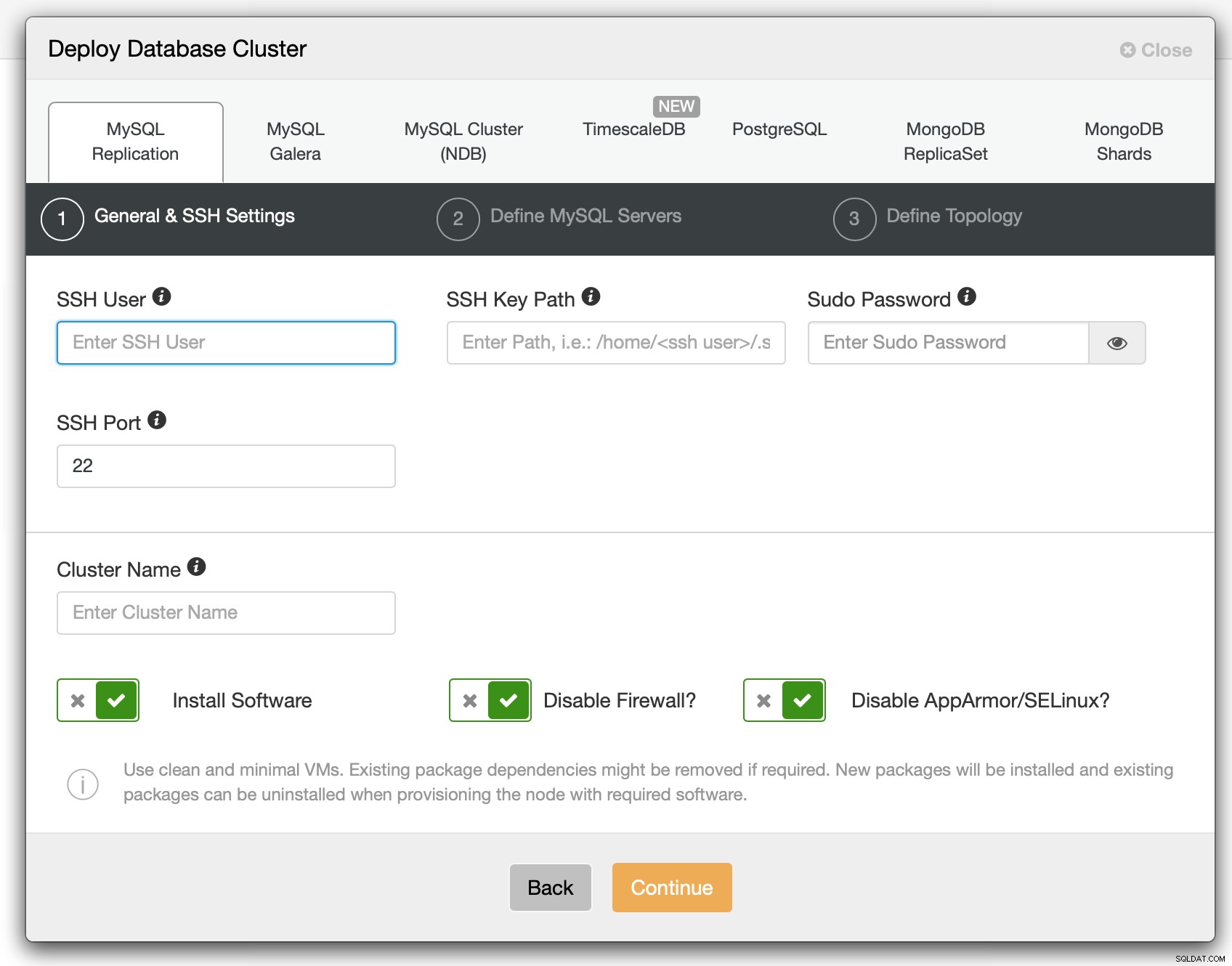
En el primer paso tenemos que definir cómo debe conectarse ClusterControl a los nodos en qué bases de datos se implementarán. Se admiten tanto el acceso raíz como sudo (con o sin contraseña).
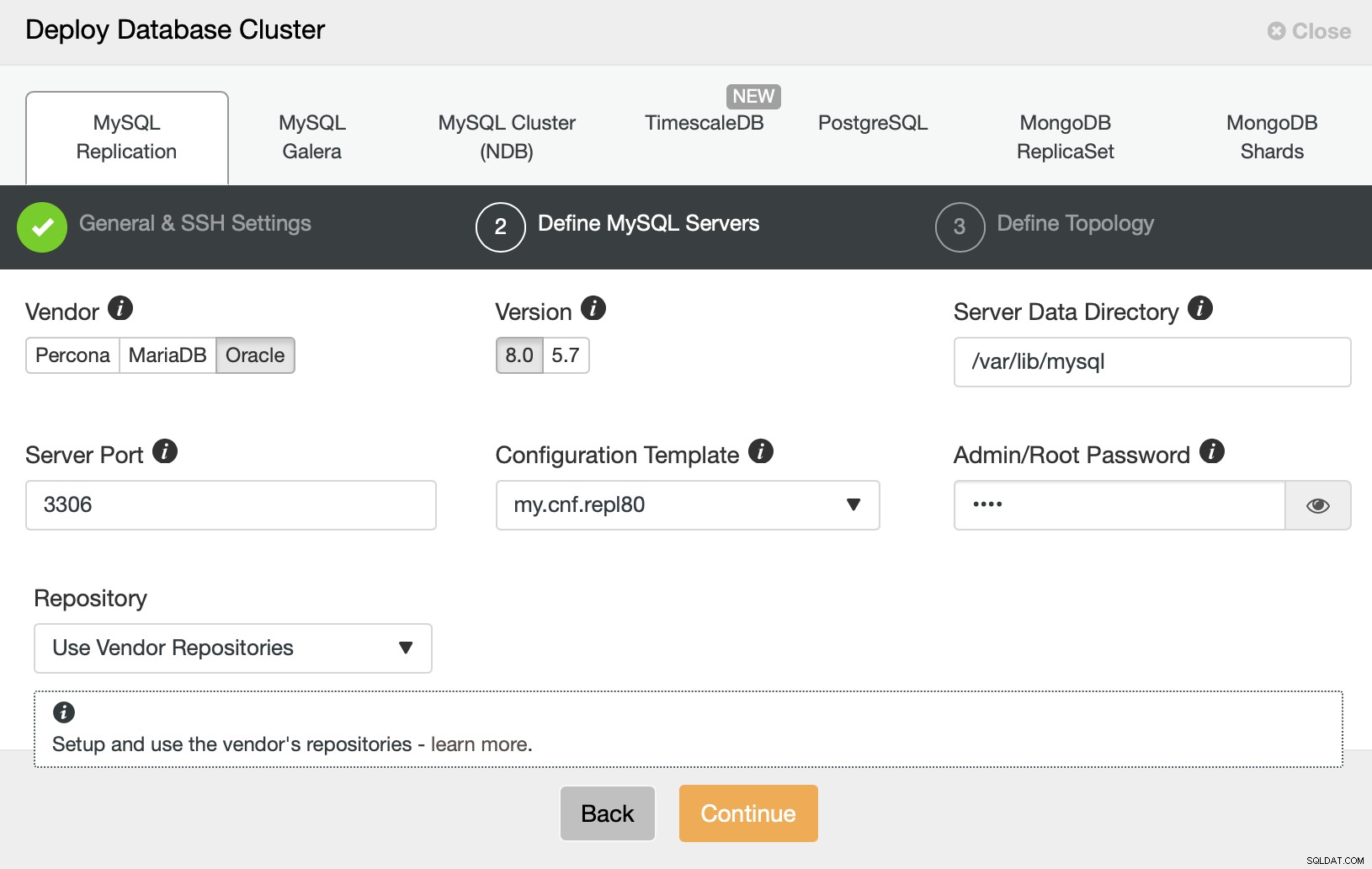
Luego, queremos elegir un proveedor, una versión y pasar la contraseña para el usuario administrativo en nuestra base de datos MySQL.
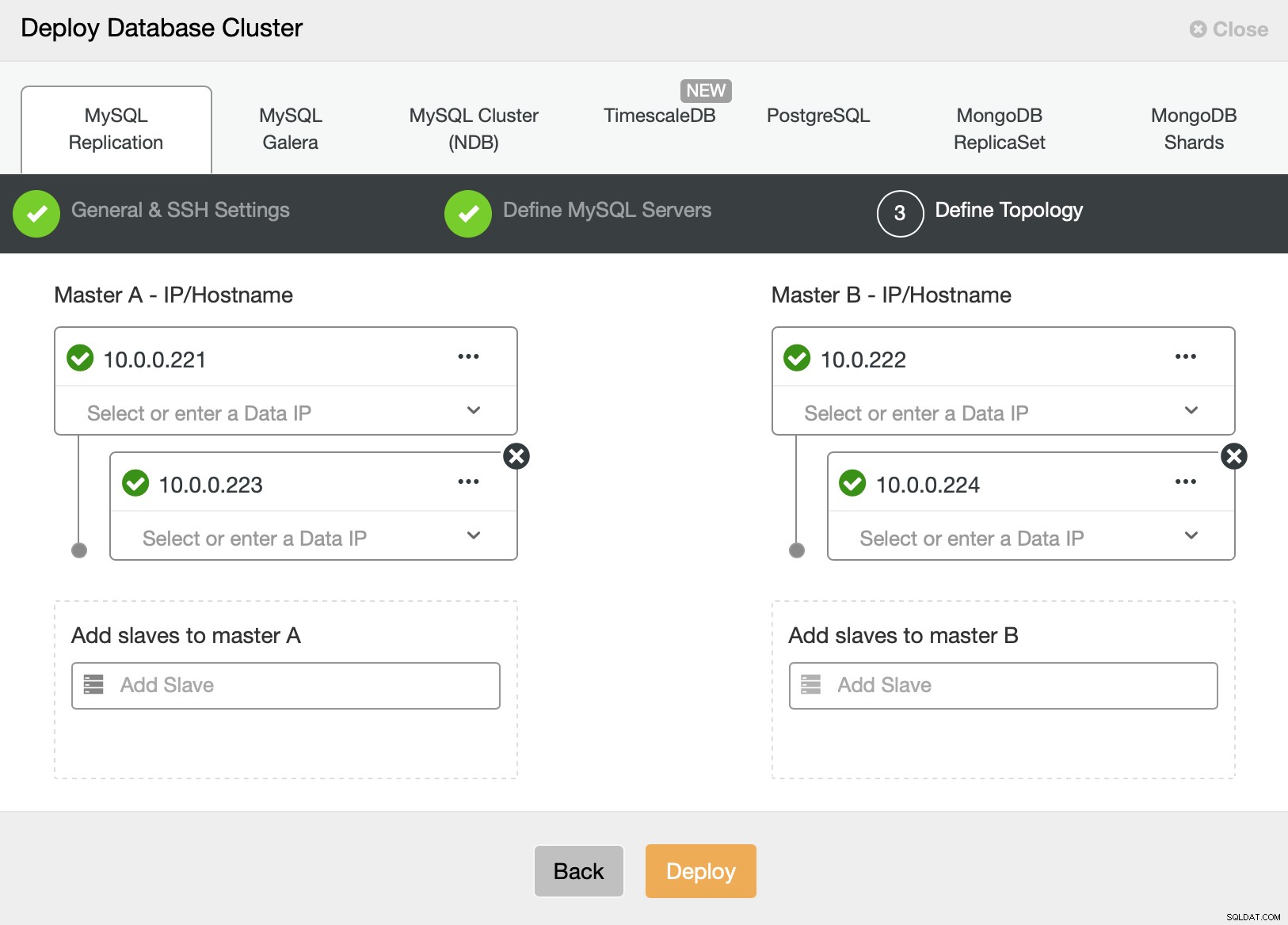
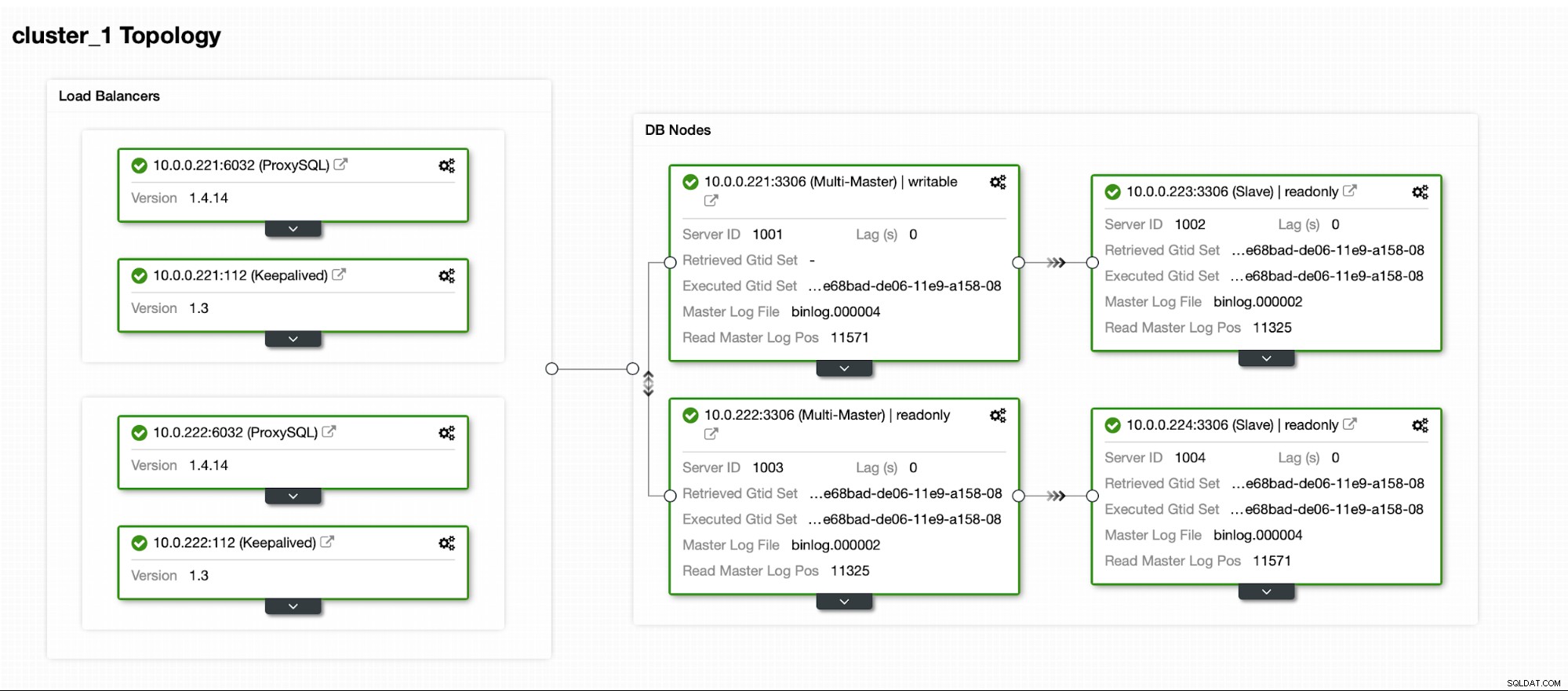
Finalmente, queremos definir la topología para nuestro nuevo clúster. Como puede ver, esta ya es una configuración bastante compleja, a diferencia de algo que puede implementar con AWS RDS o el nodo SQL de GCP.
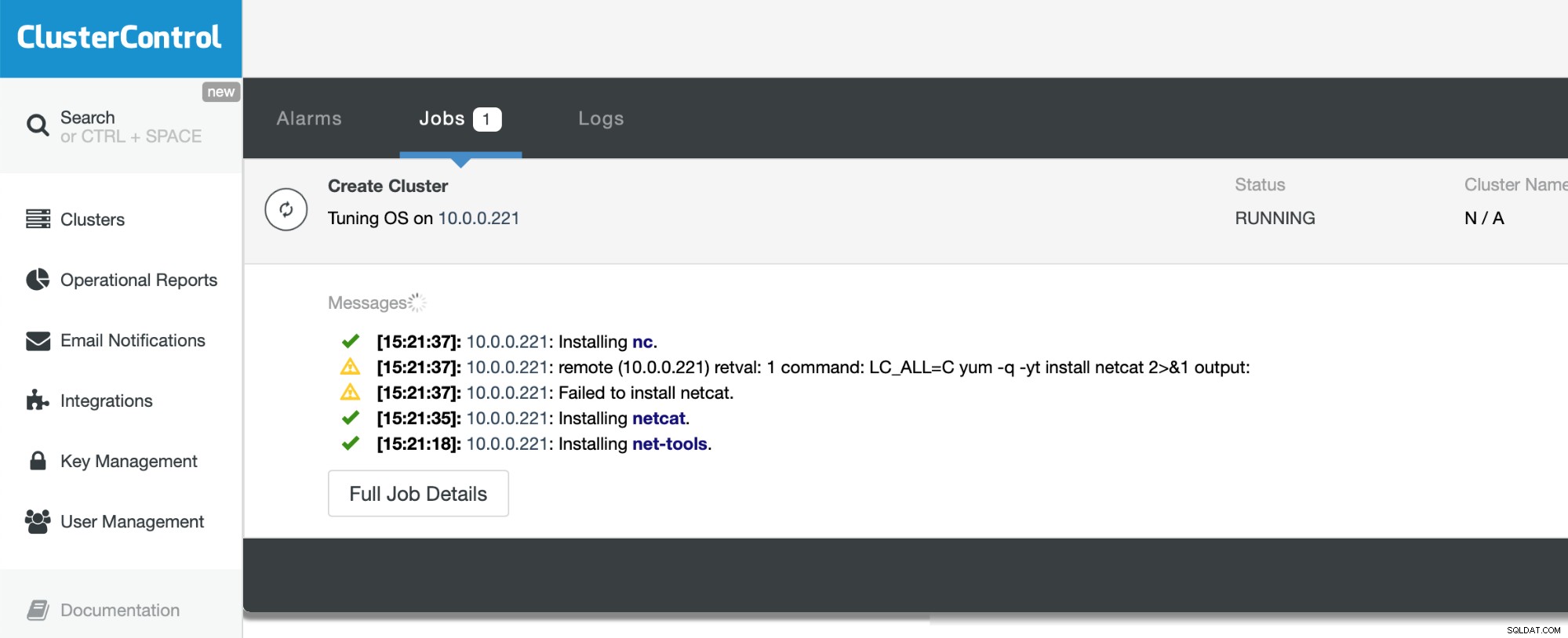
Todo lo que tenemos que hacer ahora es esperar a que se complete el proceso. ClusterControl hará todo lo posible para comprender el entorno en el que se está implementando e instalará el conjunto de paquetes necesarios, incluida la base de datos en sí.

Una vez que el clúster está funcionando, puede continuar con la implementación la capa de proxy (que proporcionará a su aplicación un único punto de entrada a la capa de la base de datos). Esto es más o menos lo que sucede detrás de escena con DBaaS, donde también tiene puntos finales para conectarse al clúster de la base de datos. Es bastante común usar un solo punto final para escrituras y múltiples puntos finales para llegar a réplicas particulares.
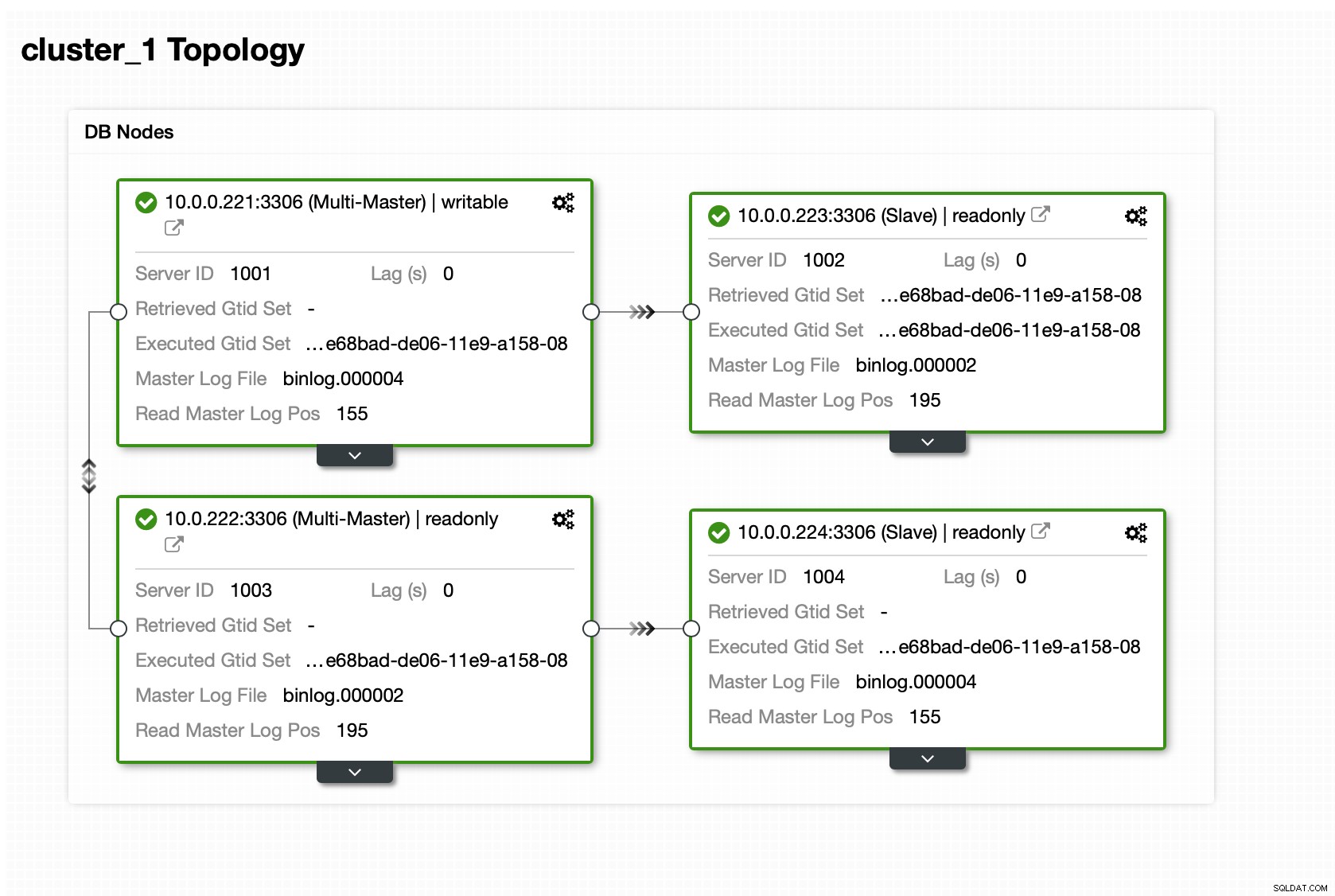
Aquí usaremos ProxySQL, que hará el trabajo sucio por nosotros:comprenderá la topología, envía escrituras solo al maestro y equilibra la carga de consultas de solo lectura en todas las réplicas que tenemos.
Para implementar ProxySQL iremos a Manage -> Load Balancers.
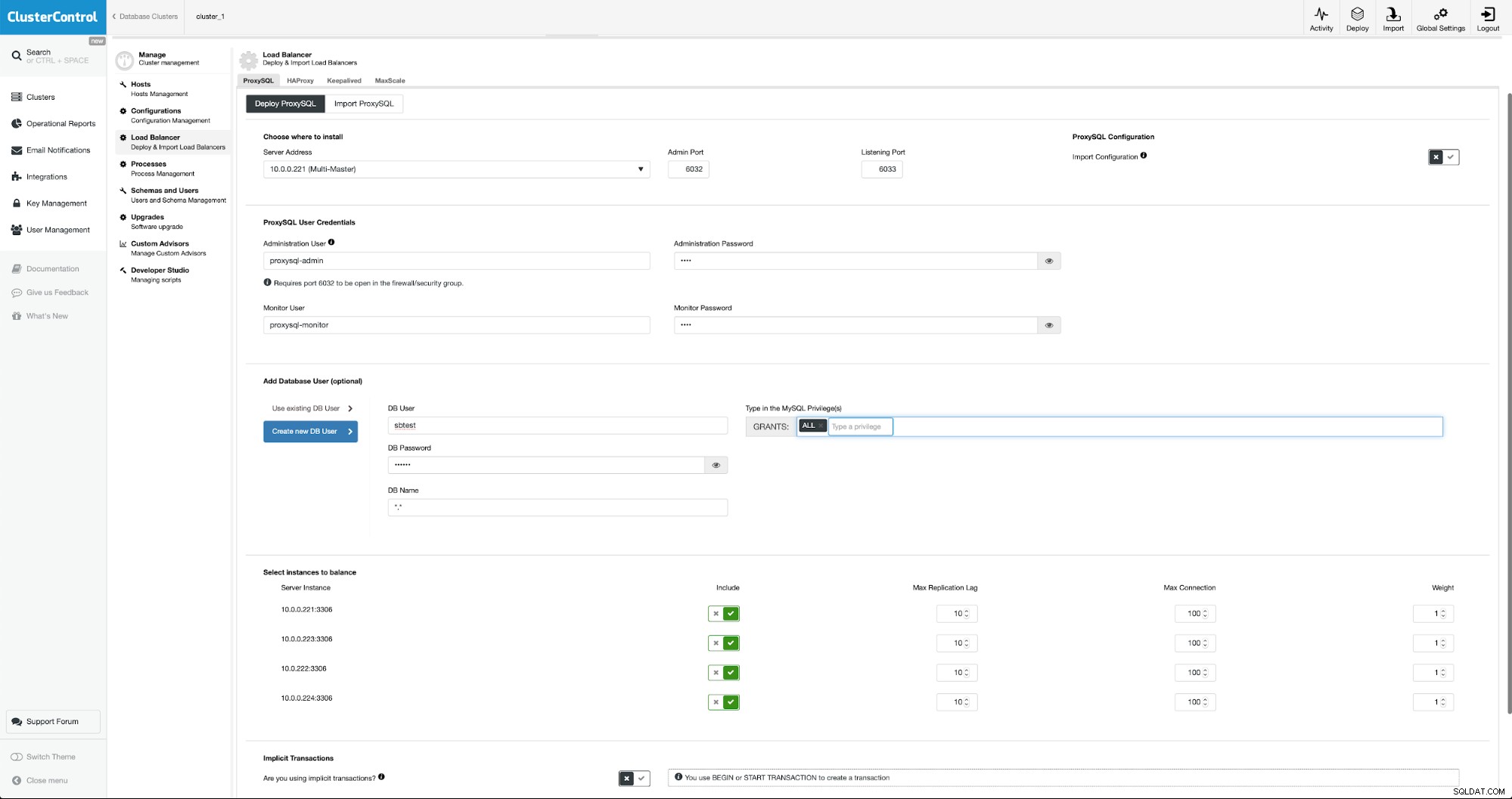
Debemos completar todos los campos obligatorios:hosts para implementar, credenciales para el usuario administrativo y de supervisión, podemos importar el usuario existente de MySQL a ProxySQL o crear uno nuevo. Todos los detalles sobre ProxySQL se pueden encontrar fácilmente en varios blogs en nuestra sección de blogs.
Queremos que se implementen al menos dos nodos ProxySQL para garantizar una alta disponibilidad. Luego, una vez que se implementen, implementaremos Keepalived sobre ProxySQL. Esto garantizará que la IP virtual se configure y apunte a una de las instancias de ProxySQL, siempre que haya al menos un nodo en buen estado.
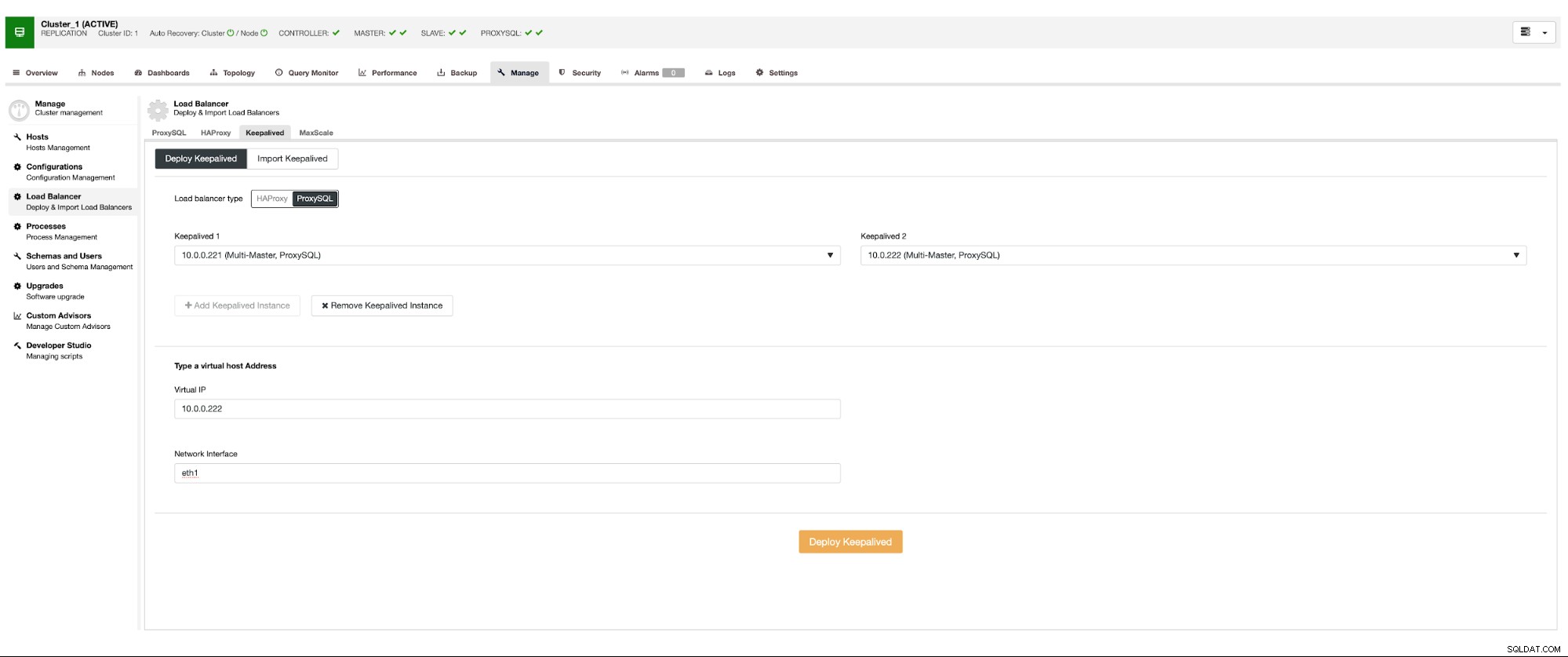
Este es el único problema potencial si utiliza entornos en la nube donde el enrutamiento funciona de una manera que no pueda abrir fácilmente una interfaz de red. En tal caso, tendrá que modificar la configuración de Keepalived, introducir el script 'notify_master' y usar un script, que hará los cambios de IP necesarios; en el caso de EC2, tendría que desconectar la IP elástica de un host y adjuntarla al otro anfitrión.
Hay muchas instrucciones sobre cómo hacerlo utilizando software de código abierto ampliamente probado en configuraciones implementadas por ClusterControl. Puede encontrar fácilmente información adicional, consejos y procedimientos que sean relevantes para su entorno particular.
Conclusión
Esperamos que esta publicación de blog le haya resultado útil. Si desea probar ClusterControl, viene con una prueba empresarial de 30 días en la que tiene disponibles todas las funciones. Puedes descargarlo gratis y probar si encaja en tu entorno.