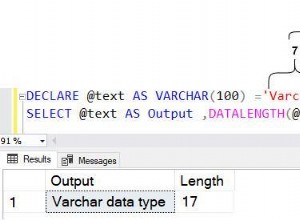
¿Qué problemas consideraremos?
Si el servidor notifica que "no hay más espacio en la unidad E", no se necesita un análisis profundo. No consideraremos los errores, cuya solución es obvia a partir del texto del mensaje y para los cuales Google lanza inmediatamente un enlace a MSDN con la solución.
Examinemos los problemas que no son evidentes para Google, como, por ejemplo, una caída repentina del rendimiento o la ausencia de conexión. Considere las principales herramientas para la personalización y el análisis. Veamos dónde se encuentran los registros y otra información útil. De hecho, intentaré recopilar en un artículo toda la información necesaria para un comienzo rápido.
En primer lugar
Vamos a comenzar con las preguntas más frecuentes y considerarlas por separado.
Si su base de datos de repente, sin razón aparente, comenzó a funcionar lentamente, pero no cambió nada, en primer lugar, actualice las estadísticas y reconstruya los índices.
En Internet, hay muchos métodos como este, se proporcionan ejemplos de scripts. Asumiré que todos esos métodos son para profesionales. Bueno, describiré la forma más simple:solo necesitas un mouse para implementarlo.
Abreviaturas
- SSMS es una aplicación de Microsoft SQL Server Management Studio. A partir de la versión 2016, está disponible de forma gratuita en el sitio web de MS como aplicación independiente. docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
- Profiler es una aplicación de "SQL Server Profiler" instalada con SSMS.
- Performance Monitor es un complemento del panel de control que le permite monitorear los contadores de rendimiento, registrar y ver el historial de mediciones.
Actualización de estadísticas usando un “plan de servicio”:
- ejecutar SSMS;
- conectarse a un servidor requerido;
- expanda el árbol en Object Inspector:Gestión\Planes de mantenimiento (Planes de servicio);
- haga clic con el botón derecho en el nodo y seleccione "Asistente para planes de mantenimiento";
- en el asistente, marque las tareas requeridas:reconstruir índice y actualizar estadísticas
- puede marcar ambas tareas a la vez o hacer dos planes de mantenimiento con una tarea en cada uno (consulte las "notas importantes" a continuación);
- Además, verificamos una base de datos requerida (o varias bases de datos). Hacemos esto para cada tarea (si se eligen dos tareas, habrá dos diálogos con la elección de una base de datos);
- Siguiente, Siguiente, Finalizar.
Luego de estas acciones, se creará (no ejecutará) un “plan de mantenimiento”. Puede ejecutarlo manualmente haciendo clic derecho y seleccionando "Ejecutar". Alternativamente, configura el lanzamiento a través del Agente SQL.
Notas importantes:
- La actualización de estadísticas es una operación sin bloqueo. Puede realizarlo en un modo de trabajo.
- La reconstrucción del índice es una operación de bloqueo. Puede ejecutarlo solo fuera de las horas de trabajo. Hay una excepción:la edición Enterprise del servidor permite la ejecución de una "reconstrucción en línea". Esta opción se puede habilitar en la configuración de la tarea. Tenga en cuenta que hay una marca de verificación en todas las ediciones, pero solo funciona en Enterprise.
- Por supuesto, estas tareas deben realizarse con regularidad. Sugiero una manera fácil de determinar con qué frecuencia hace esto:
– Con los primeros problemas, ejecutar el plan de mantenimiento;
– Si ayudó, espere hasta que los problemas vuelvan a ocurrir (generalmente hasta el próximo cierre mensual/cálculo de salario/etc. de transacciones masivas);
– El periodo resultante de un funcionamiento normal será su punto de referencia;
– Por ejemplo, configurar la ejecución del plan de mantenimiento con el doble de frecuencia.
El servidor es lento:¿qué debe hacer?
Los recursos utilizados por el servidor
Como cualquier otro programa, el servidor necesita tiempo de procesador, datos en el disco, cantidad de RAM y ancho de banda de la red.
El Administrador de tareas lo ayudará a evaluar la falta de un recurso determinado en primera aproximación, sin importar cuán terrible pueda sonar.
CPU Cargar
Incluso un escolar puede comprobar la utilización en el Administrador. Solo debemos asegurarnos de que si el procesador está cargado, entonces es el proceso sqlserver.exe.
Si este es su caso, debe ir al análisis de la actividad del usuario para comprender qué causó exactamente la carga (ver más abajo).
Disco Loa d
Muchas personas solo miran la carga de la CPU pero olvidan que el DBMS es un almacén de datos. Los volúmenes de datos están creciendo, el rendimiento del procesador está aumentando mientras que la velocidad del disco duro es prácticamente la misma. Con los SSD la situación es mejor, pero almacenar terabytes en ellos es costoso.
Resulta que a menudo encuentro situaciones en las que el sistema de disco se convierte en el cuello de botella, en lugar de la CPU.
Para los discos, las siguientes métricas son importantes:
- longitud promedio de la cola (operaciones de E/S pendientes, número);
- velocidad de lectura-escritura (en Mb/s).
La versión del servidor del Administrador de tareas, por regla general (dependiendo de la versión del sistema), muestra ambos. De lo contrario, ejecute el complemento Monitor de rendimiento (monitor del sistema). Estamos interesados en los siguientes contadores:
- Disco físico (lógico)/Tiempo medio de lectura (escritura)
- Disco físico (lógico)/Longitud promedio de cola de disco
- Disco físico (lógico)/Velocidad del disco
Para obtener más detalles, puede leer los manuales del fabricante, por ejemplo, aquí:social.technet.microsoft.com/wiki/contents/articles/3214.monitoring-disk-usage.aspx.
En resumen:
- La cola no debe exceder de 1. Se permiten ráfagas breves si desaparecen rápidamente. Las ráfagas pueden ser diferentes dependiendo de su sistema. Para un espejo RAID simple de dos HDD, la cola de más de 10-20 es un problema. Para una biblioteca genial con súper almacenamiento en caché, vi ráfagas de hasta 600-800 que se resolvieron instantáneamente sin causar demoras.
- El tipo de cambio normal también depende del tipo de sistema de disco. El HDD habitual (de escritorio) transmite a 50-100 MB/s. Una buena biblioteca de discos:a 500 MB/s y más. Para pequeñas operaciones aleatorias, la velocidad es menor. Este puede ser su punto de referencia.
- Estos parámetros deben considerarse como un todo. Si su biblioteca transmite 50 MB/s y se forma una cola de 50 operaciones, obviamente, algo anda mal con el hardware. Si la cola se alinea cuando la transmisión está cerca de un máximo, lo más probable es que no se culpe a los discos, simplemente no pueden hacer más, debemos buscar una manera de reducir la carga.
- La carga debe verificarse por separado en los discos (si hay varios) y compararse con la ubicación de los archivos del servidor. El Administrador de tareas puede mostrar los archivos más utilizados. Esto se puede usar para garantizar que la carga sea causada por DBMS.
Qué puede causar los problemas del sistema de disco:
- problemas con el hardware
- caché quemado, el rendimiento se redujo drásticamente;
- el sistema de disco es utilizado por otra cosa;
- Escasez de RAM. Intercambio. El almacenamiento en caché decayó, el rendimiento disminuyó (consulte la sección sobre RAM a continuación).
- Aumentó la carga de usuarios. Es necesario evaluar el trabajo de los usuarios (consulta problemática/nueva funcionalidad/aumento del número de usuarios/aumento de la cantidad de datos/etc).
- Fragmentación de datos de la base de datos (consulte la reconstrucción del índice anterior), fragmentación de archivos del sistema.
- El sistema de disco ha alcanzado sus capacidades máximas.
En el caso de la última opción, no tire el hardware de una vez. A veces, puede obtener un poco más del sistema si aborda el problema con prudencia. Verifique la ubicación de los archivos del sistema para cumplir con los requisitos recomendados:
- No mezcle los archivos del sistema operativo con los archivos de datos de la base de datos. Almacénelos en diferentes medios físicos para que el sistema no compita con DBMS por E/S.
- La base de datos consta de dos tipos de archivos:datos (*.mdf, *.ndf) y registros (*.ldf).
Los archivos de datos, por regla general, se utilizan principalmente para la lectura. Los registros sirven para la escritura (donde la escritura es consecutiva). Por lo tanto, se recomienda almacenar registros y datos en diferentes medios físicos para que el registro no interrumpa la lectura de datos (como regla, la operación de escritura tiene prioridad sobre la lectura). - MS SQL puede usar "tablas temporales" para el procesamiento de consultas. Se almacenan en la base de datos del sistema tempdb. Si tiene una gran carga de archivos de esta base de datos, puede intentar renderizarla en medios separados físicamente.
Resumiendo el problema con la ubicación del archivo, utilice el principio de "divide y vencerás". Evalúe a qué archivos se accede e intente distribuirlos a diferentes medios. Además, utilice las características de los sistemas RAID. Por ejemplo, las lecturas RAID-5 son más rápidas que las escrituras, lo que es bueno para los archivos de datos.
Exploremos cómo recuperar información sobre el rendimiento del usuario:quién hace qué y cuántos recursos se consumen
Dividí las tareas de auditoría de la actividad de los usuarios en los siguientes grupos:
- Tareas de análisis de solicitudes particulares.
- Tareas de análisis de carga de la aplicación en condiciones específicas (por ejemplo, cuando un usuario hace clic en un botón en una aplicación de terceros compatible con la base de datos).
- Tareas de análisis de la situación actual.
Consideremos cada uno de ellos en detalle.
Advertencia
El análisis de rendimiento requiere una comprensión profunda de la estructura y los principios de funcionamiento del servidor de base de datos y el sistema operativo. Es por eso que la lectura de solo estos artículos no lo convertirá en un profesional.
Los criterios y contadores considerados en los sistemas reales dependen en gran medida unos de otros. Por ejemplo, una alta carga de disco duro a menudo se debe a la falta de RAM. Incluso si realiza algunas mediciones, esto no es suficiente para evaluar los problemas de manera razonable.
El propósito de los artículos es introducir lo esencial en ejemplos simples. No debe considerar mis recomendaciones como una guía. Te recomiendo que los uses como tareas de entrenamiento que puedan explicar el flujo de pensamientos.
Espero que aprenda a racionalizar sus conclusiones sobre el rendimiento del servidor en cifras.
En lugar de decir "el servidor se ralentiza", proporcionará valores específicos de indicadores específicos.
Analizar una P R articular solicitud
El primer punto es bastante simple, detengámonos en él brevemente. Consideraremos algunos problemas menos obvios.
Además de los resultados de la consulta, SSMS permite recuperar información adicional sobre la ejecución de la consulta:
- Puede obtener el plan de consulta haciendo clic en los botones "Mostrar plan de ejecución estimado" e "Incluir plan de ejecución real". La diferencia entre ellos es que el plan de estimación se construye sin una ejecución de consulta. Así, se estimará la información sobre el número de filas procesadas. En el plan real, habrá datos estimados y reales. Fuertes discrepancias de estos valores indican que las estadísticas no son relevantes. Sin embargo, el análisis del plan es tema para otro artículo; hasta ahora, no profundizaremos.
- Podemos obtener mediciones de los costos del procesador y las operaciones de disco del servidor. Para ello, es necesario habilitar la opción SET. Puede hacerlo en el cuadro de diálogo "Opciones de consulta" como este:
O con los comandos SET directos en la consulta:
SET STATISTICS IO ON
SET STATISTICS TIME ON
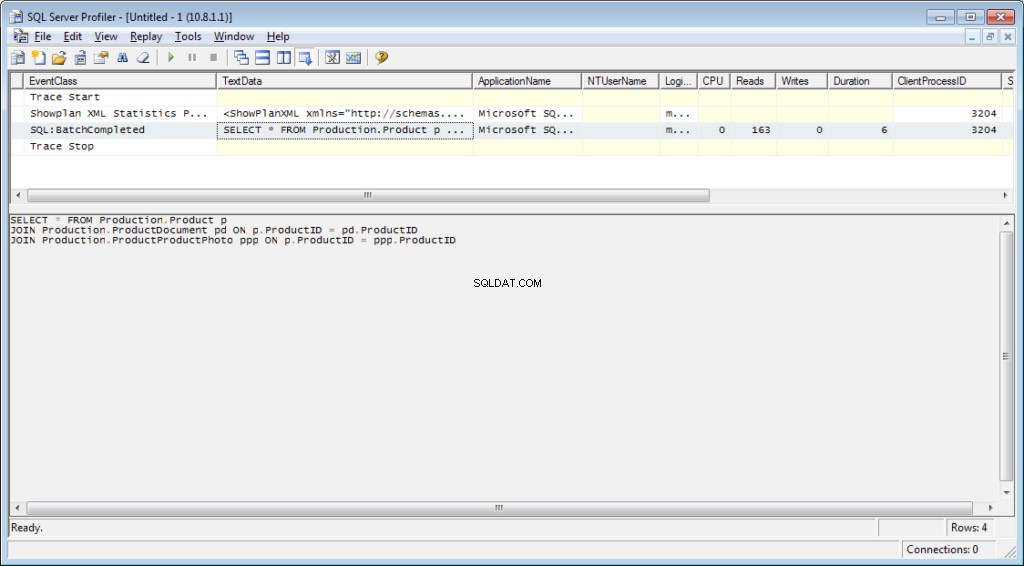
SELECT * FROM Production.Product p
JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID
JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductIDComo resultado, obtendremos datos sobre el tiempo dedicado a la compilación y ejecución, así como la cantidad de operaciones de disco.
Time of SQL Server parsing and compilation:
CPU time = 16 ms, elapsed time = 89 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
(32 row(s) affected)
The «ProductProductPhoto» table. The number of views is 32, logic reads – 96, physical reads 5, read-ahead reads 0, lob of logical reads 0, lob of physical reads 0, lob of read-ahead reads 0.
The ‘Product’ table. The number of views is 0, logic reads – 64, physical reads – 0, read-ahead reads – 0, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
The «ProductDocument» table. The number of views is 1, logical reads – 3, physical reads – 1, read-ahead reads -, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
Time of SQL activity:
CPU time = 15 ms, spent time = 35 ms.Me gustaría llamar su atención sobre el tiempo de compilación, las lecturas lógicas 96 y las lecturas físicas 5. Al ejecutar la misma consulta por segunda vez y más tarde, las lecturas físicas pueden disminuir y es posible que no sea necesario volver a compilar. Debido a este hecho, a menudo sucede que la consulta se ejecuta más rápido durante la segunda y siguientes veces que la primera vez. La razón, como comprenderá, está en el almacenamiento en caché de los datos y los planes de consulta compilados.
- El botón «Incluir estadísticas de clientes» muestra la información sobre el intercambio de red, la cantidad de operaciones ejecutadas y el tiempo total de ejecución, incluidos los costos del intercambio de red y el procesamiento por parte de un cliente. El ejemplo muestra que lleva más tiempo ejecutar la consulta por primera vez:
- En SSMS 2016, existe el botón "Incluir estadísticas de consulta en vivo". Muestra la imagen como en el caso del plan de consulta, pero contiene los dígitos no aleatorios de las filas procesadas, que cambian en la pantalla mientras se ejecuta la consulta. La imagen es muy clara:flechas intermitentes y números en ejecución, puede ver de inmediato dónde se pierde el tiempo. El botón también funciona para SQL Server 2014 y versiones posteriores.
En resumen:
- Compruebe los costos de la CPU usando SET STATISTICS TIME ON.
- Operaciones de disco:SET STATISTICS IO ON. No olvide que la lectura lógica es una operación de lectura completada en la memoria caché del disco sin acceder físicamente al sistema del disco. La "lectura física" lleva mucho más tiempo.
- Evaluar el volumen de tráfico de la red utilizando «Incluir estadísticas de clientes».
- Analizar el algoritmo de ejecución de la consulta por el plan de ejecución utilizando "Incluir plan de ejecución real" e "Incluir estadísticas de consulta en vivo".
Analizar la carga de aplicaciones
Aquí usaremos SQL Server Profiler. Después de iniciar y conectarse al servidor, es necesario seleccionar eventos de registro. Para ello, ejecute la creación de perfiles con una plantilla de seguimiento estándar. Sobre las Generales en la pestaña Usar la plantilla campo, seleccione Estándar (predeterminado) y haga clic en Ejecutar .
La forma más complicada es agregar/soltar filtros o eventos a/desde la plantilla seleccionada. Estas opciones se pueden encontrar en la segunda pestaña del menú de diálogo. Para ver la gama completa de posibles eventos y columnas para seleccionar, seleccione Mostrar todos los eventos y Mostrar todas las columnas casillas de verificación.

Necesitaremos los siguientes eventos:
- Procedimientos almacenados \ RPC:Completado
- TSQL\SQL:BatchCompleted
Estos eventos supervisan todas las llamadas SQL externas al servidor. Aparecen después de la finalización del procesamiento de la consulta. Hay eventos similares que realizan un seguimiento del inicio de SQL Server:
- Procedimientos almacenados \ RPC:Iniciando
- TSQL\SQL:Inicio por lotes
Sin embargo, no necesitamos estos procedimientos ya que no contienen información sobre los recursos del servidor gastados en la ejecución de la consulta. Es obvio que dicha información está disponible solo después de la finalización del proceso de ejecución. Por lo tanto, las columnas con datos sobre CPU, Lecturas, Escrituras en los eventos *Iniciales estarán vacías.
Los siguientes eventos también pueden interesarnos, sin embargo, no los habilitaremos por el momento:
- Procedimientos almacenados \ SP:Starting (*Completado) supervisa la llamada interna al procedimiento almacenado no desde el cliente, sino dentro de la solicitud actual u otro procedimiento.
- Procedimientos almacenados \ SP:StmtStarting (*Completed) rastrea el inicio de cada declaración dentro del procedimiento almacenado. Si hay un ciclo en el procedimiento, la cantidad de eventos para los comandos en el ciclo será igual a la cantidad de iteraciones en el ciclo.
- TSQL \ SQL:StmtStarting (*Completed) supervisa el inicio de cada declaración dentro del lote de SQL. Si hay varios comandos en su consulta, cada uno de ellos contendrá un evento. Por lo tanto, funciona para los comandos ubicados en la consulta.
Estos eventos son convenientes para monitorear el proceso de ejecución.
Por C columnas
Qué columnas seleccionar está claro en el nombre del botón. Necesitaremos los siguientes:
- TextData, BinaryData contienen el texto de consulta.
- CPU, lecturas, escrituras, duración muestran datos de consumo de recursos.
- StartTime, EndTime es el momento de iniciar y finalizar el proceso de ejecución. Son convenientes para clasificar.
Agrega otras columnas según tus preferencias.
Los Filtros de columna... El botón abre el cuadro de diálogo para configurar los filtros de eventos. Si está interesado en la actividad de un usuario en particular, puede configurar el filtro por número de SID o nombre de usuario. Desafortunadamente, en el caso de conectar la aplicación a través del servidor de aplicaciones con la atracción de las conexiones, el seguimiento del usuario en particular se vuelve más complicado.
Puede usar filtros para la selección de solo consultas complicadas (Duración>X), consultas que causan escritura intensiva (Escrituras>Y), así como selecciones de contenido de consulta, etc.
¿Qué más necesitamos del generador de perfiles? ¡Por supuesto, el plan de ejecución!
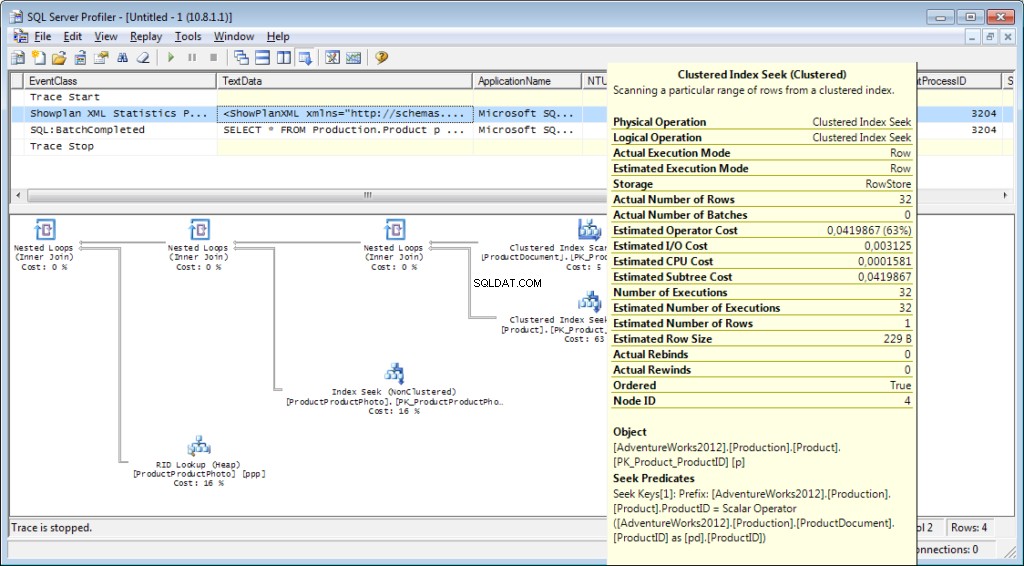
Es necesario agregar el evento «Performance \ Showplan XML Statistics Profile» al rastreo. Al ejecutar nuestra consulta, obtendremos la siguiente imagen:
El texto de consulta:
El plan de ejecución:
Y eso no es todo
Es posible guardar un seguimiento en un archivo o en una tabla de base de datos. La configuración de rastreo se puede almacenar como una plantilla personal para una ejecución rápida. Puede ejecutar el rastreo sin un generador de perfiles, simplemente usando un código T-SQL y los procedimientos sp_trace_create, sp_trace_setevent, sp_trace_setstatus, sp_trace_getdata. Puedes encontrar un ejemplo aquí. Este enfoque puede ser útil, por ejemplo, para comenzar a almacenar automáticamente un seguimiento en un archivo en un horario. Puede echar un vistazo furtivo al generador de perfiles para ver cómo usar estos comandos. Puede ejecutar dos seguimientos y, en uno de ellos, hacer un seguimiento de lo que sucede cuando se inicia el segundo. Verifique que no haya ningún filtro por la columna "Nombre de la aplicación" en el generador de perfiles.
La lista de eventos monitoreados por el generador de perfiles es muy grande y no se limita a recibir textos de consulta. Hay eventos que rastrean el escaneo completo, la recompilación, el crecimiento automático, el interbloqueo y mucho más.
Análisis de la actividad del usuario en el servidor
Hay diferentes situaciones. Una consulta puede permanecer en "ejecución" durante mucho tiempo y no está claro si se completará o no. Me gustaría analizar la consulta problemática por separado; sin embargo, primero debemos determinar cuál es la consulta. Es inútil atraparlo con un generador de perfiles:ya nos hemos perdido el evento de inicio y no está claro cuánto tiempo esperar para que se complete el proceso.
Vamos a resolverlo
Es posible que haya oído hablar de 'Monitor de actividad'. Sus ediciones superiores tienen una funcionalidad realmente rica. ¿Cómo puede ayudarnos? Activity Monitor incluye muchas características útiles e interesantes. Obtendremos todo lo que necesitamos de las vistas y funciones del sistema. El monitor en sí es útil porque puede configurar el generador de perfiles en él y ver qué consultas realiza.
Necesitaremos:
- dm_exec_sessions proporciona información sobre las sesiones de los usuarios conectados. Dentro de nuestro artículo, los campos útiles son aquellos que identifican a un usuario (login_name, login_time, host_name, program_name, …) y campos con información sobre los recursos gastados (cpu_time, reads, writes, memory_usage, …)
- dm_exec_requests proporciona información sobre las consultas ejecutadas en este momento.
- session_id es un identificador de la sesión para vincular a la vista anterior.
- start_time es el tiempo de ejecución de la vista.
- comando es un campo que contiene un tipo del comando ejecutado. Para consultas de usuarios, es seleccionar/actualizar/eliminar/
- sql_handle, statement_start_offset, statement_end_offset proporcionan información para recuperar el texto de la consulta:handle, así como la posición inicial y final en el texto de la consulta, lo que significa la parte que se está ejecutando actualmente (en el caso de que su consulta contenga varios comandos).
- plan_handle es un identificador del plan generado.
- blocking_session_id indica el número de la sesión que provocó el bloqueo si hay bloqueos que impiden la ejecución de la consulta
- wait_type, wait_time, wait_resource son campos con información sobre el motivo y la duración de la espera. Para algunos tipos de esperas, por ejemplo, bloqueo de datos, es necesario indicar adicionalmente un código para el recurso bloqueado.
- percent_complete es el porcentaje de finalización. Desafortunadamente, solo está disponible para comandos con un progreso claramente predecible (por ejemplo, copia de seguridad o restauración).
- cpu_time, reads, writes, logical_reads, grant_query_memory son costos de recursos.
- dm_exec_sql_text(sql_handle | plan_handle), sys.dm_exec_query_plan(plan_handle) son funciones para obtener el texto y el plan de ejecución. A continuación, consideraremos un ejemplo de su uso.
- dm_exec_query_stats es un resumen de estadísticas de la ejecución de consultas. Muestra la consulta, el número de ejecuciones y el volumen de recursos gastados.
Notas importantes
La lista anterior es solo una pequeña parte. En la documentación se describe una lista completa de todas las vistas y funciones del sistema. Además, hay una hermosa imagen que muestra un diagrama de enlaces entre los objetos principales.
El texto de la consulta, su plan y las estadísticas de ejecución son datos almacenados en la memoria caché del procedimiento. Están disponibles durante la ejecución. Entonces, la disponibilidad no está garantizada y depende de la carga de caché. Sí, el caché se puede limpiar manualmente. A veces, se recomienda cuando los planes de ejecución "se descontrolan". Aún así, hay muchos matices.
El campo "comando" no tiene sentido para las solicitudes de los usuarios, ya que podemos obtener el texto completo. Sin embargo, es muy importante para obtener información sobre los procesos del sistema. Por regla general, realizan algunas tareas internas y no tienen el texto SQL. Para tales procesos, la información sobre el comando es la única pista del tipo de actividad.
En los comentarios al artículo anterior, había una pregunta sobre en qué está involucrado el servidor cuando no debería funcionar. La respuesta probablemente estará en el significado de este campo. En mi práctica, el campo de "comando" siempre proporcionó algo bastante comprensible para los procesos activos del sistema:autoshrink / autogrow / checkpoint / logwriter / etc.
Cómo usarlo
Pasaremos a la parte práctica. Daré varios ejemplos de su uso. Las posibilidades del servidor no están limitadas:puede pensar en sus propios ejemplos.
Ejemplo 1. Qué proceso consume CPU/lecturas/escrituras/memoria
Primero, eche un vistazo a las sesiones que consumen más recursos, por ejemplo, CPU. Puede encontrar esta información en sys.dm_exec_sessions. Sin embargo, los datos en la CPU, incluidas las lecturas y escrituras, son acumulativos. Significa que el número contiene el total de todo el tiempo de conexión. Está claro que el usuario que se conectó hace un mes y no se desconectó tendrá un valor mayor. No significa que sobrecarguen el sistema.
Un código con el siguiente algoritmo puede resolver este problema:
- Haga una selección y guárdela en una tabla temporal
- Espere un momento
- Hacer una selección por segunda vez
- Compare estos resultados. Su diferencia indicará los costos gastados en el paso 2.
- Por conveniencia, la diferencia se puede dividir por la duración del paso 2 para obtener los "costos por segundo" promedio.
if object_id('tempdb..#tmp') is NULL
BEGIN
SELECT * into #tmp from sys.dm_exec_sessions s
PRINT 'wait for a second to collect statistics at the first run '
-- we do not wait for the next launches, because we compare with the result of the previous launch
WAITFOR DELAY '00:00:01';
END
if object_id('tempdb..#tmp1') is not null drop table #tmp1
declare @d datetime
declare @dd float
select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp')
select * into #tmp1 from sys.dm_exec_sessions s
select @dd=datediff(ms,@d,getdate())
select @dd AS [time interval, ms]
SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec,
s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec,
s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D],
s.nt_user_name,s.nt_domain
from #tmp1 s
LEFT join #tmp t on s.session_id=t.session_id
order BY
cpu_Diff desc
--totIO_Diff desc
--logical_reads_Diff desc
drop table #tmp
GO
select * into #tmp from #tmp1
drop table #tmp1 Uso dos tablas en el código:#tmp, para la primera selección, y #tmp1, para la segunda. Durante la primera ejecución, el script crea y llena #tmp y #tmp1 en un intervalo de un segundo y luego realiza otras tareas. Con las próximas ejecuciones, el script utiliza los resultados de la ejecución anterior como base para la comparación. Por lo tanto, la duración del paso 2 será igual a la duración de la espera entre las ejecuciones del script.
Intente ejecutarlo, incluso en el servidor de producción. La secuencia de comandos creará solo "tablas temporales" (disponibles dentro de la sesión actual y eliminadas cuando están desactivadas) y no tiene subprocesos.
Aquellos a quienes no les gusta ejecutar una consulta en MS SSMS pueden incluirla en una aplicación escrita en su lenguaje de programación favorito. Te mostraré cómo hacer esto en MS Excel sin una sola línea de código.
En el menú Datos, conéctese al servidor. Si se le solicita que seleccione una tabla, seleccione una al azar. Haga clic en Siguiente y Finalizar hasta que vea el cuadro de diálogo Importación de datos. En esa ventana, debe hacer clic en Propiedades. En Propiedades, es necesario reemplazar un tipo de comando con el valor SQL e insertar nuestra consulta modificada en el campo de texto Comando.
Tendrás que modificar un poco la consulta:
- Añadir «FIJAR SIN CUENTA EN»
- Reemplace las tablas temporales con tablas de variables
- La demora durará 1 segundo. Los campos con valores promediados no son obligatorios
La consulta modificada para Excel
SET NOCOUNT ON;
declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint)
declare @d datetime;
select @d=GETDATE()
INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id)
SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id
from sys.dm_exec_sessions s;
WAITFOR DELAY '00:00:01';
declare @dd float;
select @dd=datediff(ms,@d,getdate());
SELECT
s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff,
s.reads-isnull(t.reads,0) as reads_Diff,
s.writes-isnull(t.writes,0) as writes_Diff,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff],
s.nt_user_name,s.nt_domain
from sys.dm_exec_sessions s
left join @tmp t on s.session_id=t.session_id Resultado:
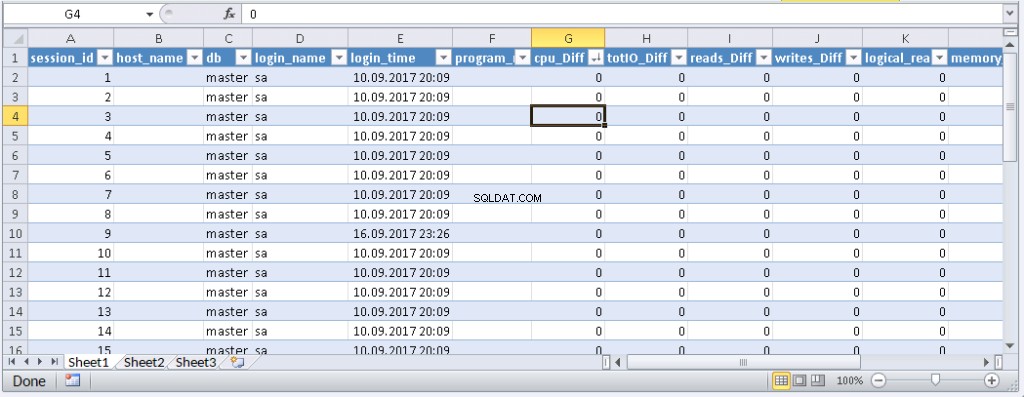
Cuando los datos aparecen en Excel, puede ordenarlos, según lo necesite. Para actualizar la información, haga clic en 'Actualizar'. En la configuración del libro de trabajo, puede poner "actualización automática" en un período de tiempo específico y "actualización al inicio". Puede guardar el archivo y pasárselo a sus colegas. Por lo tanto, creamos una herramienta conveniente y simple.
Ejemplo 2. ¿En qué gasta recursos una sesión?
Ahora, vamos a determinar qué hacen realmente las sesiones de problemas. Para hacer esto, use sys.dm_exec_requests y funciones para recibir el texto de consulta y el plan de consulta.
La consulta y el plan de ejecución por número de sesión
DECLARE @sql_handle varbinary(64) DECLARE @plan_handle varbinary(64) DECLARE @sid INT Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT -- for the information by a particular user – indicate a session number SELECT @sid=182 -- receive state variables for further processing IF @sid IS NOT NULL SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id FROM sys.dm_exec_requests der WHERE example@sqldat.com -- print the text of the query being executed DECLARE @txt VARCHAR(max) IF @sql_handle IS NOT NULL SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle) PRINT @txt -- output the plan of the batch/procedure being executed IF @plan_handle IS NOT NULL select * from sys.dm_exec_query_plan(@plan_handle) -- and the plan of the query being executed within the batch/procedure IF @plan_handle IS NOT NULL SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)
Inserte el número de sesión en la consulta y ejecútela. After execution, there will be plans on the Results tab (the first one is for the whole query, and the second one is for the current step if there are several steps in the query) and the query text on the Messages tab. To view the plan, you need to click the text that looks like the URL in the row. The plan will be opened in a separate tab. Sometimes, it happens that the plan is opened not in a graphical form, but in the form of XML-text. This may happen because the MS SSMS version is lower than the server. Delete the “Version” and “Build” from the first row and then save the result XML to a file with the .sqlplan extension. After that, open it separately. If this does not help, I remind you that the 2016 studio is officially available for free on the MS website.
It is obvious that the result plan will be an estimated one, as the query is being executed. Still, it is possible to receive some execution statistics. To do this, use the sys.dm_exec_query_stats view with the filter by our handles.
Add this information at the end of the previous query
-- plan statistics IF @sql_handle IS NOT NULL SELECT * FROM sys.dm_exec_query_stats QS WHERE example@sqldat.com_handle
As a result, we will get the information about the steps of the executed query:how many times they were executed and what resources were spent. This information is added to the statistics only after the execution process is completed. The statistics are not tied to the user but are maintained within the whole server. If different users execute the same query, the statistics will be total for all users.
Example 3. Can I see all of them?
Let’s combine the system views we considered with the functions in one query. It can be useful for evaluating the whole situation.
-- receive a list of all current queries SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt --,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat ,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, * from sys.dm_exec_requests der left join sys.dm_exec_sessions s ON s.session_id = der.session_id WHERE der.session_id<>@@SPID -- AND der.session_id>50
The query outputs a list of active sessions and texts of their queries. For system processes, usually, there is no query; however, the command field is filled up. You can see the information about blocks and waits, and mix this query with example 1 in order to sort by the load. Still, be careful, query texts may be large. Their massive selection can be resource-intensive and lead to a huge traffic increase. In the example, I limited the result query to the first 500 characters but did not execute the plan.
Conclusion
It would be great to get Live Query Statistics for an arbitrary session. According to the manufacturer, now, monitoring statistics requires many resources and therefore, it is disabled by default. Its enabling is not a problem, but additional manipulations complicate the process and reduce the practical benefit.
In this article, we analyzed user activity in the following ways:using possibilities MS SSMS, profiler, direct calls to system views. All these methods allow estimating costs on executing a query and getting the execution plan. Each method is suitable for a particular situation. Thus, the best solution is to combine them.