Las bases de datos relacionales representan los datos de una organización en tablas que usan columnas con diferentes tipos de datos que les permiten almacenar valores válidos. Los desarrolladores y administradores de bases de datos deben conocer y comprender el tipo de datos adecuado para cada columna para mejorar el rendimiento de las consultas.
Este artículo tratará sobre los tipos de datos populares VARCHAR() y NVARCHAR(), su comparación y revisiones de rendimiento en SQL Server.
VARCHAR [ ( n | máx ) ] en SQL
El VARCHAR el tipo de datos representa el no Unicode tipo de datos de cadena de longitud variable. Puede almacenar letras, números y caracteres especiales en él.
- N representa el tamaño de la cadena en bytes.
- La columna de tipo de datos VARCHAR almacena un máximo de 8000 caracteres no Unicode.
- El tipo de datos VARCHAR ocupa 1 byte por carácter. Si no especifica explícitamente el valor de N, ocupa 1 byte de almacenamiento.
Nota:No confunda N con un valor que representa el número de caracteres en una cadena.
La siguiente consulta define el tipo de datos VARCHAR con 100 bytes de datos.
DECLARE @text AS VARCHAR(100) ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Devuelve la longitud como 17 debido a 1 byte por carácter, incluido un carácter de espacio.
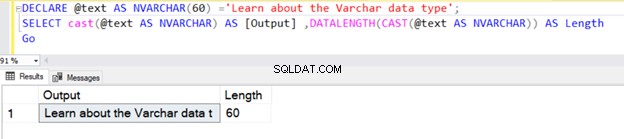
La siguiente consulta define el tipo de datos VARCHAR sin ningún valor de N . Por lo tanto, SQL Server considera el valor predeterminado como 1 byte, como se muestra a continuación.
DECLARE @text AS VARCHAR ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
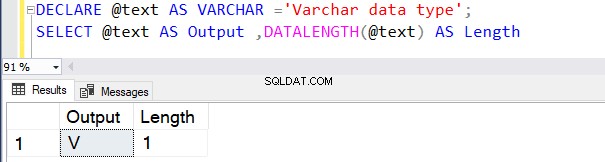
También podemos usar VARCHAR usando la función CAST o CONVERT. Por ejemplo, en los dos ejemplos siguientes, declaramos una variable con una longitud de 100 bytes y luego usamos el operador CAST.
La primera consulta devuelve la longitud como 30 porque no especificamos N en el tipo de datos VARCHAR del operador CAST. La longitud predeterminada es 30.
DECLARE @text AS VARCHAR(100) ='Learn about the VARCHAR data type';
SELECT cast(@text AS VARCHAR) AS [Output] ,DATALENGTH(CAST(@text AS VARCHAR)) AS Length
Go
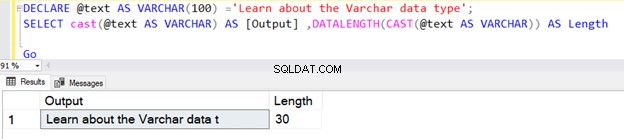
Sin embargo, si la longitud de la cadena es inferior a 30, se toma el tamaño real de la cadena.

NVARCHAR [ ( n | máx ) ] en SQL
El NVARCHAR el tipo de datos es para Unicode tipo de datos de caracteres de longitud variable. Aquí, N se refiere al conjunto de caracteres del idioma nacional y se usa para definir la cadena Unicode. Puede almacenar caracteres Unicode y no Unicode (kanji japonés, hangul coreano, etc.).
- N representa el tamaño de la cadena en bytes.
- Puede almacenar un máximo de 4000 caracteres Unicode y no Unicode.
- El tipo de datos VARCHAR ocupa 2 bytes por carácter. Se necesitan 2 bytes de almacenamiento si no especifica ningún valor para N.
La siguiente consulta define el tipo de datos VARCHAR con 100 bytes de datos.
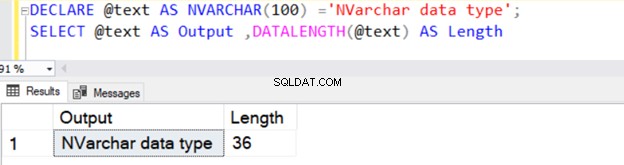
DECLARE @text AS NVARCHAR(100) ='NVARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Devuelve la longitud de cadena de 36 porque NVARCHAR toma 2 bytes por almacenamiento de caracteres.
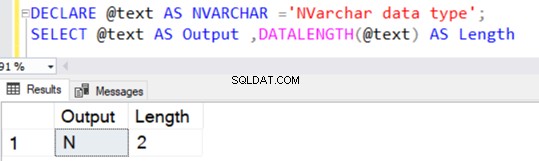
Similar al tipo de datos VARCHAR, NVARCHAR también tiene un valor predeterminado de 1 carácter (2 bytes) sin especificar un valor explícito para N.
Si aplicamos la conversión NVARCHAR usando la función CAST o CONVERT sin ningún valor explícito de N, el valor predeterminado es 30 caracteres, es decir, 60 bytes.
Almacenamiento de valores Unicode y no Unicode en el tipo de datos VARCHAR
Supongamos que tenemos una tabla que registra los comentarios de los clientes de un portal de compras electrónicas. Para ello disponemos de una tabla SQL con la siguiente consulta.
CREATE TABLE UserComments
(
ID int IDENTITY (1,1),
[Language] VARCHAR(50),
[comment] VARCHAR(200),
[NewComment] NVARCHAR(200)
)
Insertamos varios registros de muestra en esta tabla en inglés, japonés e hindi. El tipo de datos para [Comentario] es VARCHAR y [Nuevo comentario] es NVARCHAR() .
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('English','Hello World', N'Hello World')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Japanese','こんにちは世界', N'こんにちは世界')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Hindi','नमस्ते दुनिया', N'नमस्ते दुनिया')
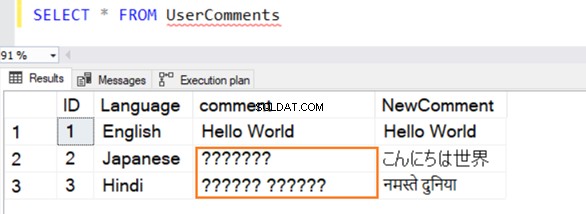
La consulta se ejecuta con éxito y proporciona las siguientes filas al seleccionar un valor de ella. Para la fila 2 y 3, no reconoce datos si no están en inglés.
Tipos de datos VARCHAR y NVARCHAR:comparación de rendimiento
No debemos mezclar el uso de tipos de datos VARCHAR y NVARCHAR en los predicados JOIN o WHERE. Invalida los índices existentes porque SQL Server requiere los mismos tipos de datos en ambos lados de JOIN. SQL Server intenta realizar la conversión implícita mediante la función CONVERT_IMPLICIT() en caso de discrepancia.
SQL Server usa la precedencia del tipo de datos para determinar cuál es el tipo de datos de destino. NVARCHAR tiene mayor prioridad que el tipo de datos VARCHAR. Por lo tanto, durante la conversión del tipo de datos, SQL Server convierte los valores VARCHAR existentes en NVARCHAR.
CREATE TABLE #PerformanceTest
(
[ID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Col1] VARCHAR(50) NOT NULL,
[Col2] NVARCHAR(50) NOT NULL
)
CREATE INDEX [ix_performancetest_col] ON #PerformanceTest (col1)
CREATE INDEX [ix_performancetest_col2] ON #PerformanceTest (col2)
INSERT INTO #PerformanceTest VALUES ('A',N'C')
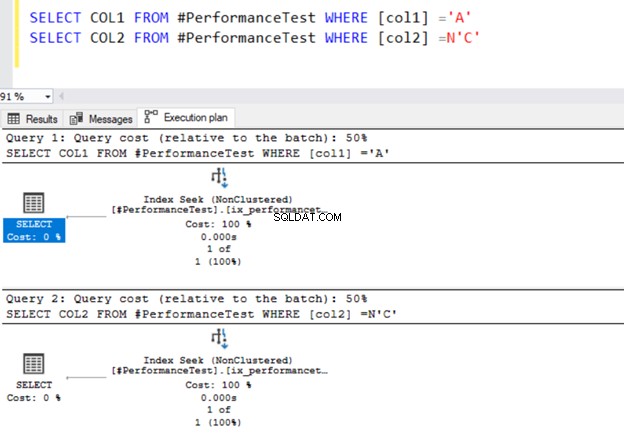
Ahora, ejecutemos dos declaraciones SELECT que recuperan registros según sus tipos de datos.
SELECT COL1 FROM #PerformanceTest WHERE [col1] ='A'
SELECT COL2 FROM #PerformanceTest WHERE [col2] =N'C'
Ambas consultas usan el operador de búsqueda de índice y los índices que definimos anteriormente.
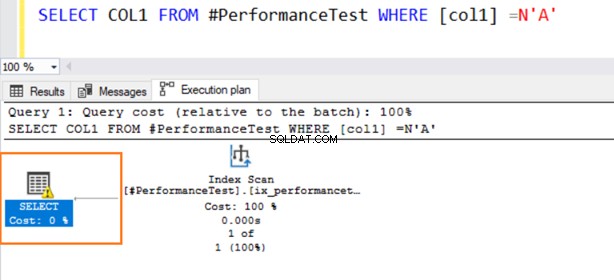
Ahora, cambiamos los valores del tipo de datos para compararlos con el predicado WHERE. La columna 1 tiene un tipo de datos VARCHAR, pero especificamos N'A' para ponerlo como tipo de datos NVARCHAR.
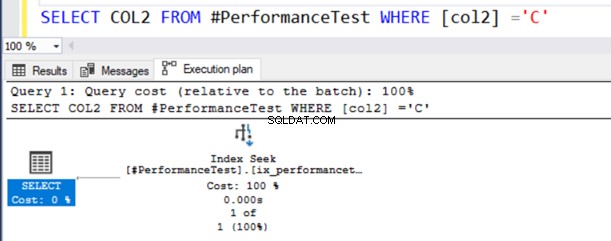
De manera similar, col2 es el tipo de datos NVARCHAR y especificamos el valor 'C' que se refiere al tipo de datos VARCHAR.
SELECT COL2 FROM #PerformanceTest WHERE [col2] ='C'En el plan de ejecución real de la consulta, obtiene un escaneo de índice y la instrucción SELECT tiene un símbolo de advertencia.
Esta consulta funciona bien porque el tipo de datos NVARCHAR() puede tener valores tanto Unicode como no Unicode.
Ahora, la segunda consulta utiliza un escaneo de índice y emite un símbolo de advertencia en el operador SELECCIONAR.
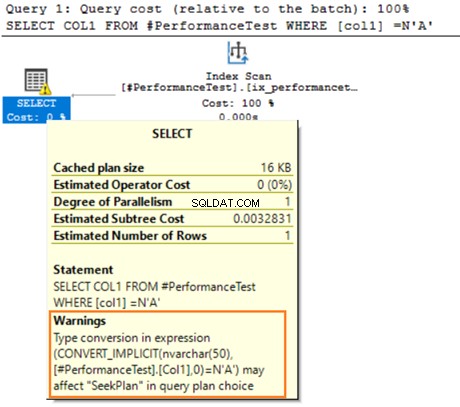
Pase el mouse sobre la declaración SELECT que emite una advertencia sobre la conversión implícita. SQL Server no pudo usar el índice existente correctamente. Se debe a los diferentes algoritmos de clasificación de datos para los tipos de datos VARCHAR y NVARCHAR.
Si la tabla tiene millones de filas, SQL Server debe realizar un trabajo adicional y convertir los datos mediante la conversión de datos implícitamente. Podría afectar negativamente el rendimiento de su consulta. Por lo tanto, debe evitar mezclar y combinar estos tipos de datos para optimizar las consultas.
Conclusión
Debe revisar sus requisitos de datos al diseñar las tablas de la base de datos y el tipo de datos de sus columnas de manera adecuada. Por lo general, el tipo de datos VARCHAR sirve para la mayoría de sus requisitos de datos. Sin embargo, si necesita almacenar tipos de datos tanto Unicode como no Unicode en una columna, puede considerar usar NVARCHAR. Sin embargo, debe revisar su implicación en el rendimiento y el tamaño del almacenamiento antes de tomar la decisión final.