Amazon Aurora Serverless proporciona una base de datos relacional bajo demanda, escalable automáticamente y de alta disponibilidad que solo le cobra cuando está en uso. Proporciona una opción relativamente simple y rentable para cargas de trabajo poco frecuentes, intermitentes o impredecibles. Lo que hace que esto sea posible es que se inicia automáticamente, escala la capacidad informática para que coincida con el uso de su aplicación y luego se apaga cuando ya no se necesita.
El siguiente diagrama muestra la arquitectura de alto nivel de Aurora Serverless.
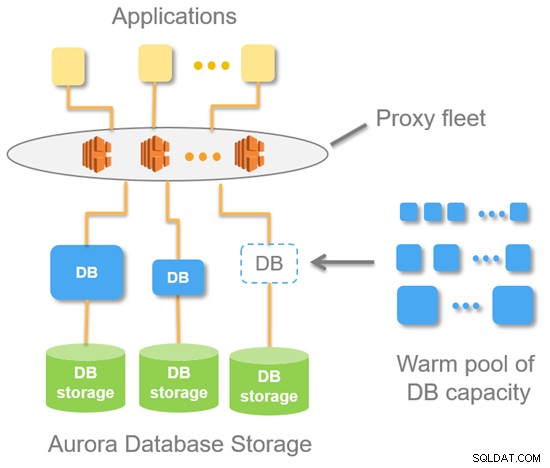
Con Aurora Serverless, obtiene un punto final (en lugar de dos puntos finales para la base de datos aprovisionada de Aurora estándar). Básicamente, se trata de un registro DNS que consta de una flota de proxies que se encuentra en la parte superior de la instancia de la base de datos. Desde un punto de servidor MySQL, significa que las conexiones siempre provienen de la flota de proxy.
Aurora Auto-Scaling sin servidor
Aurora Serverless actualmente solo está disponible para MySQL 5.6. Básicamente, debe establecer la unidad de capacidad mínima y máxima para el clúster de base de datos. Cada unidad de capacidad es equivalente a una configuración específica de cómputo y memoria. Aurora Serverless reduce los recursos para el clúster de base de datos cuando su carga de trabajo está por debajo de estos umbrales. Aurora Serverless puede reducir la capacidad al mínimo o aumentar la capacidad a la unidad de capacidad máxima.
El clúster se ampliará automáticamente si se cumple alguna de las siguientes condiciones:
- La utilización de la CPU es superior al 70 % O
- Más del 90% de las conexiones están siendo utilizadas
El clúster se reducirá automáticamente si se cumplen las dos condiciones siguientes:
- La utilización de la CPU cae por debajo del 30 % Y
- Se utilizan menos del 40 % de las conexiones.
Algunas de las cosas notables que debe saber sobre el flujo de escalado automático de Aurora:
- Solo se amplía cuando detecta problemas de rendimiento que se pueden resolver mediante la ampliación.
- Después de escalar hacia arriba, el período de enfriamiento para escalar hacia abajo es de 15 minutos.
- Después de reducir, el período de recuperación para la siguiente reducción es de 310 segundos.
- Escala a capacidad cero cuando no hay conexiones durante un período de 5 minutos.
De forma predeterminada, Aurora Serverless realiza el escalado automático sin problemas, sin cortar ninguna conexión de base de datos activa con el servidor. Es capaz de determinar un punto de escalado (un punto en el tiempo en el que la base de datos puede iniciar con seguridad la operación de escalado). Sin embargo, bajo las siguientes condiciones, es posible que Aurora Serverless no pueda encontrar un punto de escala:
- Hay transacciones o consultas de ejecución prolongada en curso.
- Las tablas temporales o los bloqueos de tablas están en uso.
Si ocurre alguno de los casos anteriores, Aurora Serverless continúa intentando encontrar un punto de escalado para poder iniciar la operación de escalado (a menos que esté habilitado "Forzar escalado"). Hace esto mientras determina que se debe escalar el clúster de base de datos.
Observación del comportamiento de Auto Scaling de Aurora
Tenga en cuenta que en Aurora Serverless, solo se puede modificar una pequeña cantidad de parámetros y max_connections no es uno de ellos. Para todos los demás parámetros de configuración, los clústeres de Aurora MySQL Serverless utilizan los valores predeterminados. Para max_connections, Aurora Serverless lo controla dinámicamente mediante la siguiente fórmula:
conexiones_máx =MÁS GRANDE ({registro (DBInstanceClassMemory/805306368)*45}, {registro (DBInstanceClassMemory/8187281408)*1000})
Donde, log es log2 (log base-2) y "DBInstanceClassMemory" es la cantidad de bytes de memoria asignados a la clase de instancia de base de datos asociada con la instancia de base de datos actual, menos la memoria utilizada por los procesos de Amazon RDS que administran la instancia. Es bastante difícil predeterminar el valor que utilizará Aurora, por lo que es bueno realizar algunas pruebas para comprender cómo se escala este valor en consecuencia.
Este es nuestro resumen de implementación de Aurora Serverless para esta prueba:
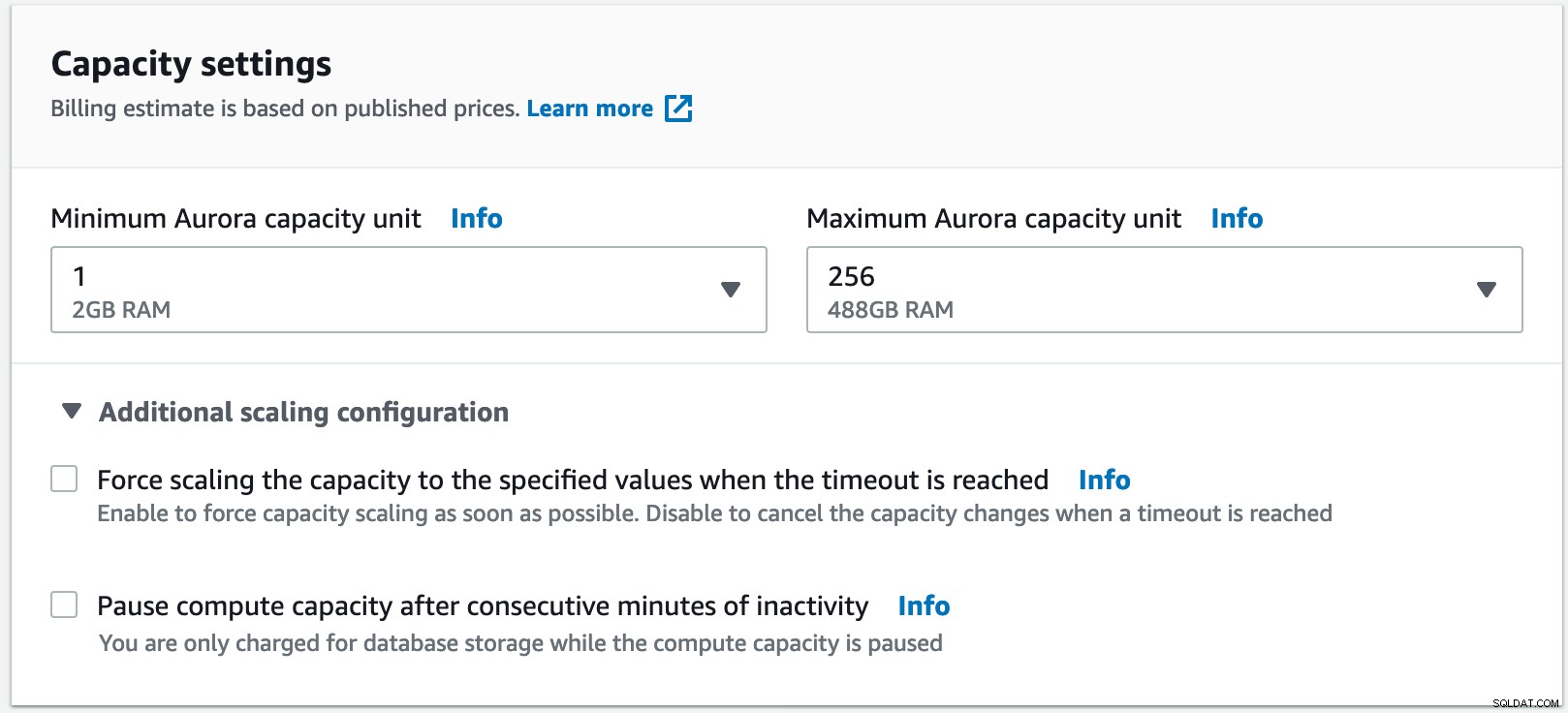
Para este ejemplo, he seleccionado un mínimo de 1 unidad de capacidad Aurora, que equivale a 2 GB de RAM hasta la unidad de capacidad máxima de 256 con 488 GB de RAM.
Las pruebas se realizaron utilizando sysbench, simplemente enviando varios subprocesos hasta alcanzar el límite de conexiones de la base de datos MySQL. Nuestro primer intento de enviar 128 conexiones de base de datos simultáneas a la vez fracasó:
$ sysbench \
/usr/share/sysbench/oltp_read_write.lua \
--report-interval=2 \
--threads=128 \
--delete_inserts=5 \
--time=360 \
--max-requests=0 \
--db-driver=mysql \
--db-ps-mode=disable \
--mysql-host=${_HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=20 \
--table-size=100000 \
runEl comando anterior devolvió inmediatamente el error 'Demasiadas conexiones':
FATAL: unable to connect to MySQL server on host 'aurora-sysbench.cluster-cdw9q2wnb00s.ap-southeast-1.rds.amazonaws.com', port 3306, aborting...
FATAL: error 1040: Too many connectionsAl observar la configuración de max_connection, obtuvimos lo siguiente:
mysql> SELECT @@hostname, @@max_connections;
+----------------+-------------------+
| @@hostname | @@max_connections |
+----------------+-------------------+
| ip-10-2-56-105 | 90 |
+----------------+-------------------+Resulta que el valor inicial de max_connections para nuestra instancia de Aurora con una capacidad de base de datos (2 GB de RAM) es 90. En realidad, esto es mucho más bajo que nuestro valor anticipado si se calcula usando la fórmula provista para estimar el valor max_connections:
mysql> SELECT GREATEST({log2(2147483648/805306368)*45},{log2(2147483648/8187281408)*1000});
+------------------------------------------------------------------------------+
| GREATEST({log2(2147483648/805306368)*45},{log2(2147483648/8187281408)*1000}) |
+------------------------------------------------------------------------------+
| 262.2951 |
+------------------------------------------------------------------------------+Esto simplemente significa que DBInstanceClassMemory no es igual a la memoria real de la instancia de Aurora. Debe ser mucho más bajo. De acuerdo con este hilo de discusión, el valor de la variable se ajusta para tener en cuenta la memoria que ya está en uso para los servicios del sistema operativo y el demonio de administración de RDS.
Sin embargo, cambiar el valor predeterminado de max_connections a algo más alto tampoco nos ayudará, ya que este valor lo controla dinámicamente el clúster de Aurora Serverless. Por lo tanto, tuvimos que reducir el valor de los subprocesos iniciales de sysbench a 84 porque los subprocesos internos de Aurora ya reservaron alrededor de 4 a 5 conexiones a través de 'rdsadmin'@'localhost'. Además, también necesitamos una conexión adicional para nuestros propósitos de administración y monitoreo.
Entonces ejecutamos el siguiente comando en su lugar (con --threads=84):
$ sysbench \
/usr/share/sysbench/oltp_read_write.lua \
--report-interval=2 \
--threads=84 \
--delete_inserts=5 \
--time=600 \
--max-requests=0 \
--db-driver=mysql \
--db-ps-mode=disable \
--mysql-host=${_HOST} \
--mysql-user=sbtest \
--mysql-db=sbtest \
--mysql-password=password \
--tables=20 \
--table-size=100000 \
runDespués de completar la prueba anterior en 10 minutos (--time=600), ejecutamos el mismo comando nuevamente y en este momento, algunas de las variables notables y el estado habían cambiado como se muestra a continuación:
mysql> SELECT @@hostname AS hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+--------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+--------------+-----------------+-------------------+--------+
| ip-10-2-34-7 | 180 | 179 | 157 |
+--------------+-----------------+-------------------+--------+Observe que max_connections ahora se ha duplicado hasta 180, con un nombre de host diferente y un tiempo de actividad pequeño como si el servidor estuviera recién comenzando. Desde el punto de vista de la aplicación, parece que otra "instancia de base de datos más grande" se ha hecho cargo del punto final y se ha configurado con una variable max_connections diferente. Mirando el evento Aurora, ha sucedido lo siguiente:
Wed, 04 Sep 2019 08:50:56 GMT The DB cluster has scaled from 1 capacity unit to 2 capacity units.Luego, activamos el mismo comando sysbench, creando otras 84 conexiones al extremo de la base de datos. Una vez completada la prueba de estrés generada, el servidor escala automáticamente hasta 4 DB de capacidad, como se muestra a continuación:
mysql> SELECT @@hostname AS hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+---------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+---------------+-----------------+-------------------+--------+
| ip-10-2-12-75 | 270 | 6 | 300 |
+---------------+-----------------+-------------------+--------+Puede saberlo al observar los diferentes valores de nombre de host, max_connection y tiempo de actividad en comparación con el anterior. Otra instancia más grande ha "asumido" el rol de la instancia anterior, donde la capacidad de la base de datos era igual a 2. El punto de escala real es cuando la carga del servidor estaba cayendo y casi tocando el suelo. En nuestra prueba, si mantuviéramos la conexión completa y la carga de la base de datos constantemente alta, la escala automática no se llevaría a cabo.
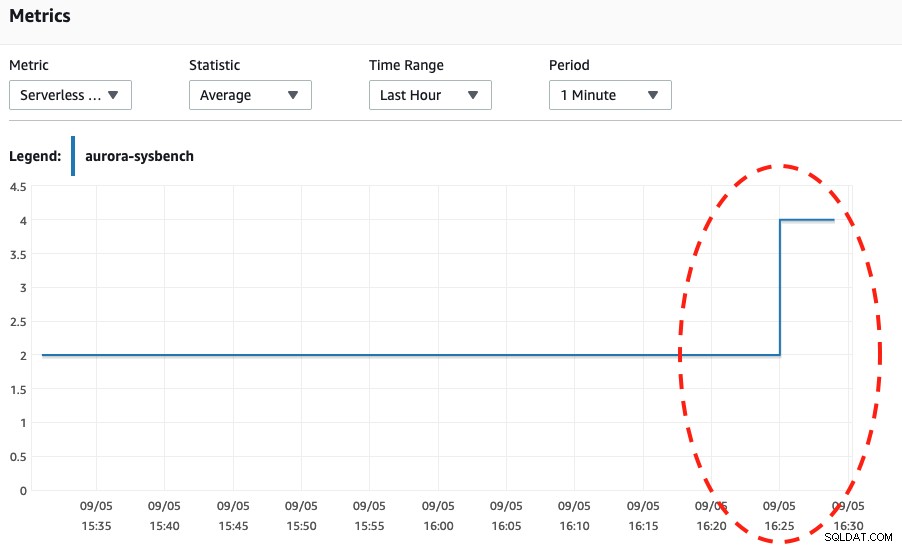
Al observar las dos capturas de pantalla a continuación, podemos decir que el escalado solo ocurre cuando nuestro Sysbench ha completado su prueba de esfuerzo durante 600 segundos porque ese es el punto más seguro para realizar el escalado automático.
 Capacidad de base de datos sin servidor Uso de CPU
Capacidad de base de datos sin servidor Uso de CPU 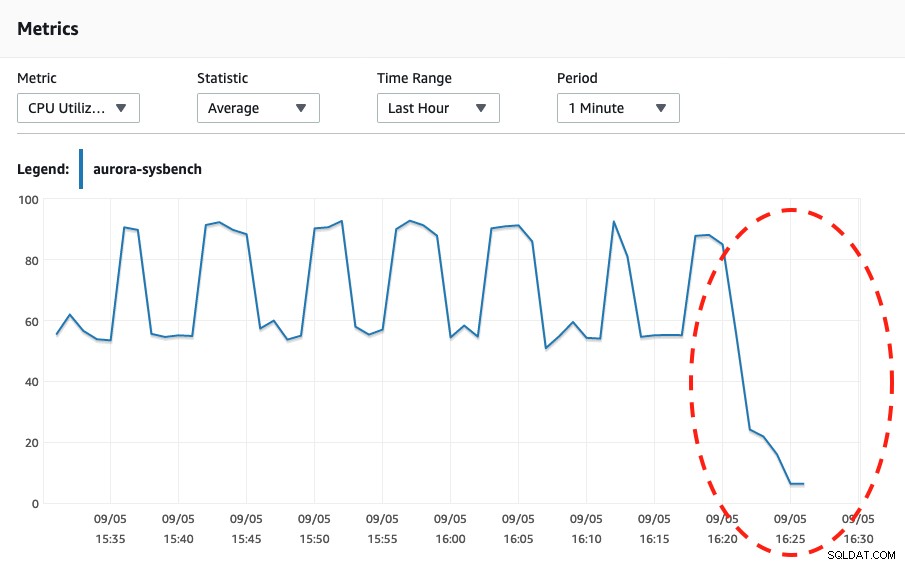 Uso de CPU
Uso de CPU Al observar los eventos de Aurora, ocurrieron los siguientes eventos:
Wed, 04 Sep 2019 16:25:00 GMT Scaling DB cluster from 4 capacity units to 2 capacity units for this reason: Autoscaling.
Wed, 04 Sep 2019 16:25:05 GMT The DB cluster has scaled from 4 capacity units to 2 capacity units.Finalmente, generamos muchas más conexiones hasta casi 270 y esperamos hasta que terminó, para llegar a la capacidad de 8 DB:
mysql> SELECT @@hostname as hostname, @@max_connections AS max_connections,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'THREADS_CONNECTED') AS threads_connected,
(SELECT VARIABLE_VALUE FROM global_status WHERE VARIABLE_NAME = 'UPTIME') AS uptime;
+---------------+-----------------+-------------------+--------+
| hostname | max_connections | threads_connected | uptime |
+---------------+-----------------+-------------------+--------+
| ip-10-2-72-12 | 1000 | 144 | 230 |
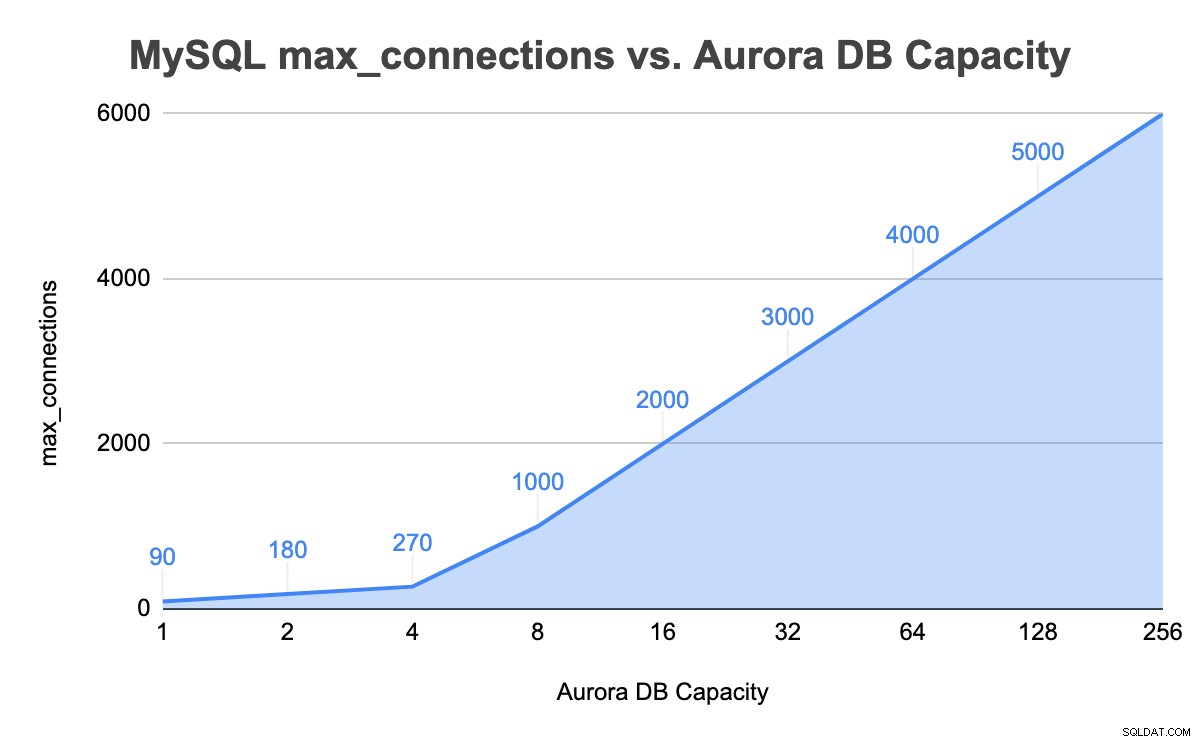
+---------------+-----------------+-------------------+--------+En la instancia de 8 unidades de capacidad, el valor de MySQL max_connections ahora es 1000. Repetimos pasos similares maximizando las conexiones de la base de datos y hasta el límite de 256 unidades de capacidad. La siguiente tabla resume la unidad de capacidad general de la base de datos frente al valor max_connections en nuestras pruebas hasta la capacidad máxima de la base de datos:
Escalado forzado
Como se mencionó anteriormente, Aurora Serverless solo realizará el escalado automático cuando sea seguro hacerlo. Sin embargo, el usuario tiene la opción de forzar el escalado de la capacidad de la base de datos de inmediato marcando la casilla de verificación Forzar escalado en la opción 'Configuración de escalado adicional':
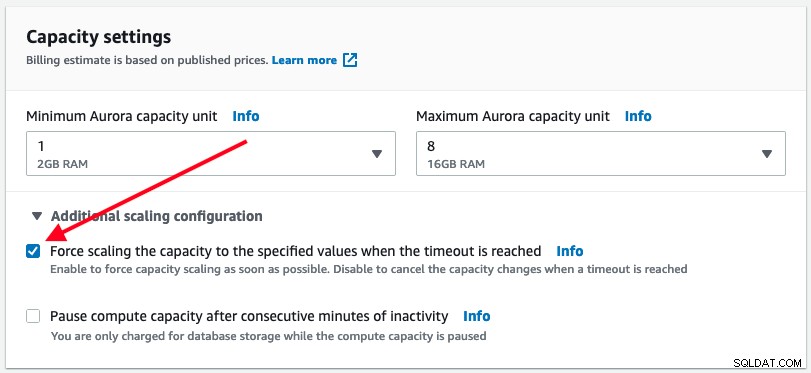
Cuando el escalado forzado está habilitado, el escalado ocurre tan pronto como se agota el tiempo de espera. alcanzado que es de 300 segundos. Este comportamiento puede provocar la interrupción de la base de datos de su aplicación, donde las conexiones activas a la base de datos pueden perderse. Observamos el siguiente error cuando se forzó el escalado automático después de que se agotó el tiempo de espera:
FATAL: mysql_drv_query() returned error 1105 (The last transaction was aborted due to an unknown error. Please retry.) for query 'SELECT c FROM sbtest19 WHERE id=52824'
FATAL: `thread_run' function failed: /usr/share/sysbench/oltp_common.lua:419: SQL error, errno = 1105, state = 'HY000': The last transaction was aborted due to an unknown error. Please retry.Lo anterior simplemente significa que, en lugar de encontrar el momento adecuado para escalar verticalmente, Aurora Serverless obliga a que el reemplazo de la instancia se realice inmediatamente después de que se agote el tiempo de espera, lo que provoca que las transacciones se anulen y retrocedan. Es probable que volver a intentar la consulta abortada por segunda vez resuelva el problema. Esta configuración podría usarse si su aplicación es resistente a caídas de conexión.
Resumen
El escalado automático sin servidor de Amazon Aurora es una solución de escalado vertical, donde una instancia más potente se hace cargo de una instancia inferior, utilizando la tecnología subyacente de almacenamiento compartido de Aurora de manera eficiente. De forma predeterminada, la operación de escalado automático se realiza sin problemas, por lo que Aurora encuentra un punto de escalado seguro para realizar el cambio de instancia. Uno tiene la opción de forzar el escalado automático con los riesgos de que se interrumpan las conexiones activas de la base de datos.