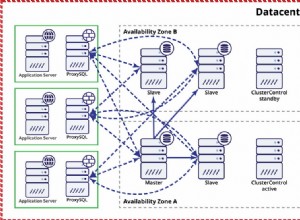
Actualmente existen numerosos proveedores de nube. Pueden ser pequeños o grandes, locales o con centros de datos repartidos por todo el mundo. Muchos de estos proveedores de nube ofrecen algún tipo de solución de base de datos relacional administrada. Las bases de datos admitidas tienden a ser MySQL o PostgreSQL o algún otro tipo de base de datos relacional.
Al diseñar cualquier tipo de infraestructura de base de datos, es importante comprender las necesidades de su negocio y decidir qué tipo de disponibilidad necesita lograr.
En esta publicación de blog, analizaremos las opciones de alta disponibilidad para las soluciones basadas en MySQL de uno de los proveedores de nube más importantes:Google Cloud Platform.
Implementación de un entorno de alta disponibilidad mediante la instancia SQL de GCP
Para este blog queremos un entorno muy simple - una base de datos, con tal vez una o dos réplicas. Queremos poder realizar la conmutación por error fácilmente y restaurar las operaciones lo antes posible si falla el maestro. Usaremos MySQL 5.7 como la versión elegida y comenzaremos con el asistente de implementación de instancias:
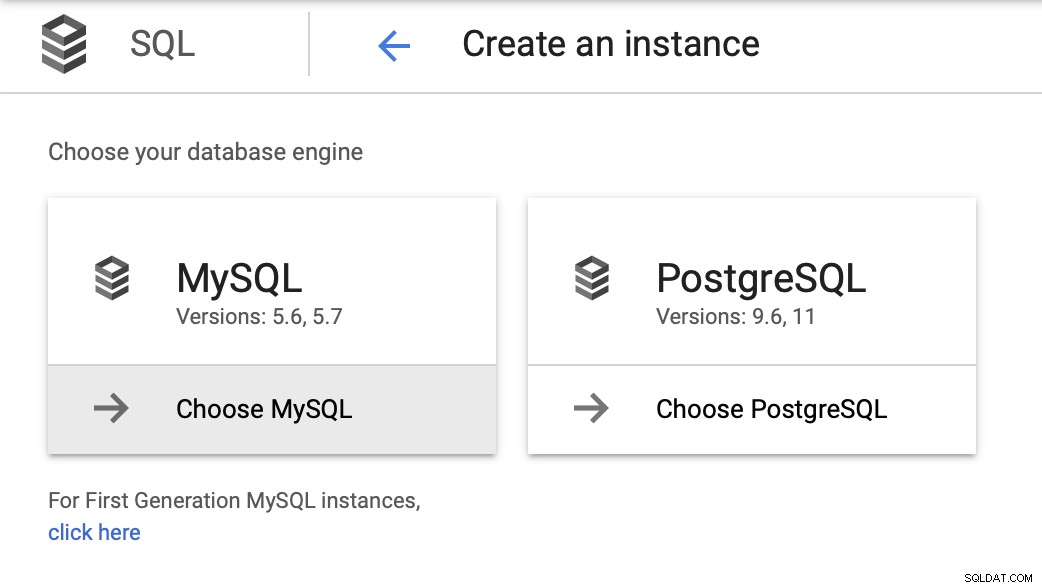
Luego tenemos que crear la contraseña raíz, establecer el nombre de la instancia y determinar dónde debe ubicarse:
A continuación, veremos las opciones de configuración:
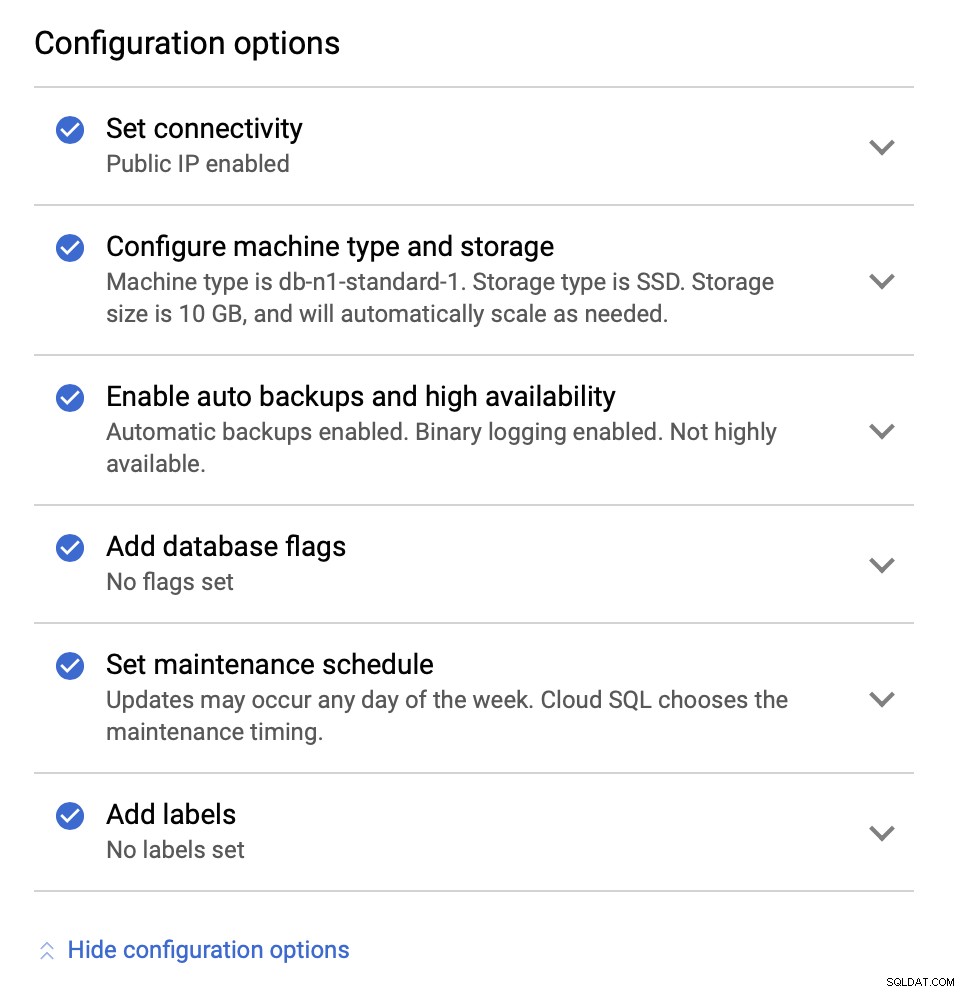
Podemos hacer cambios en cuanto al tamaño de la instancia (iremos con db-n1-standard-4), almacenamiento y programa de mantenimiento. Lo más importante para nosotros en esta configuración son las opciones de alta disponibilidad:
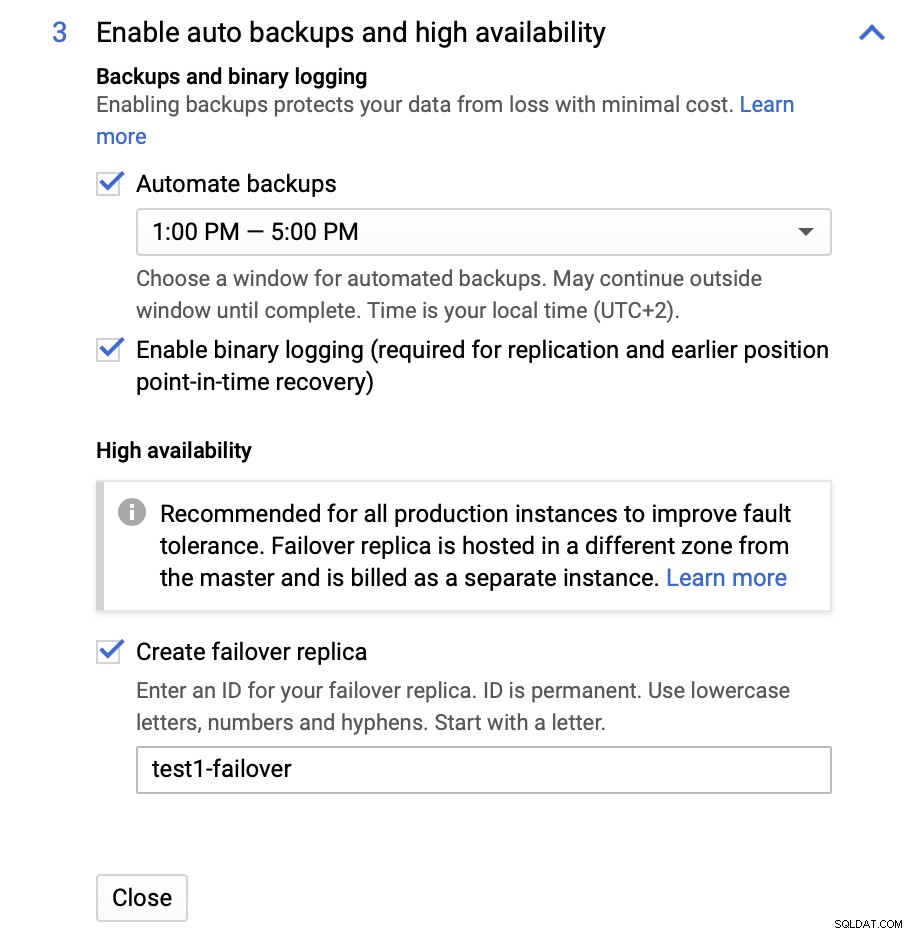
Aquí podemos elegir que se cree una réplica de conmutación por error. Esta réplica se promocionará a maestra en caso de que falle la maestra original.

Después de implementar la configuración, agreguemos un esclavo de replicación:
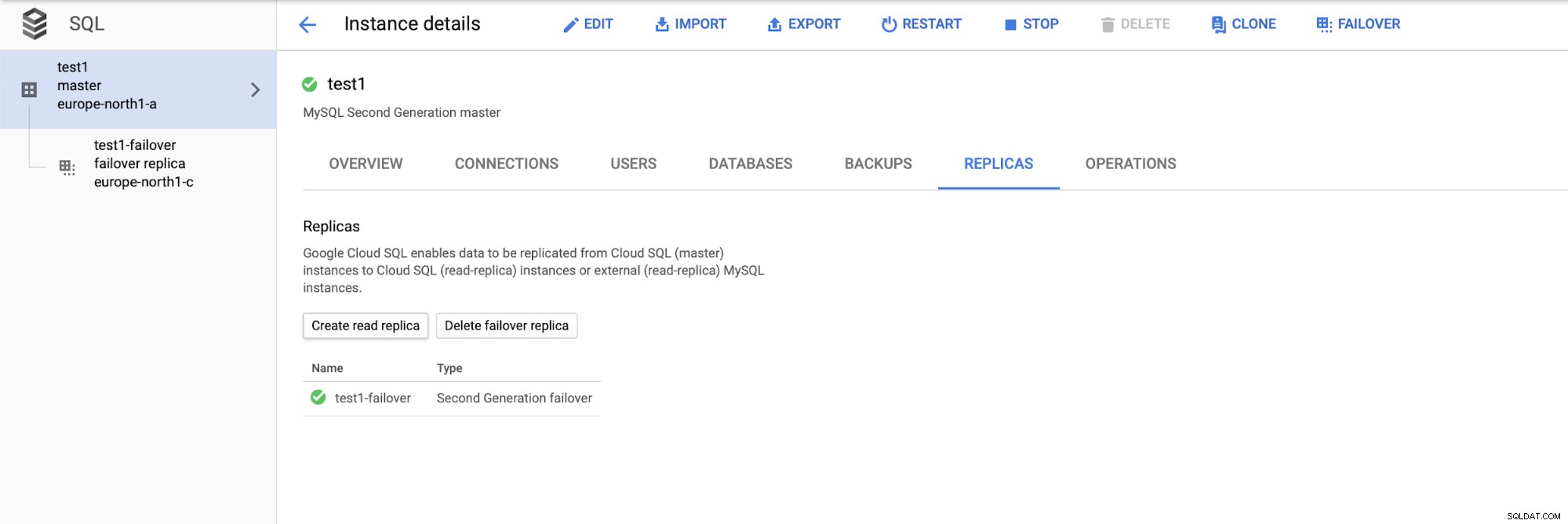
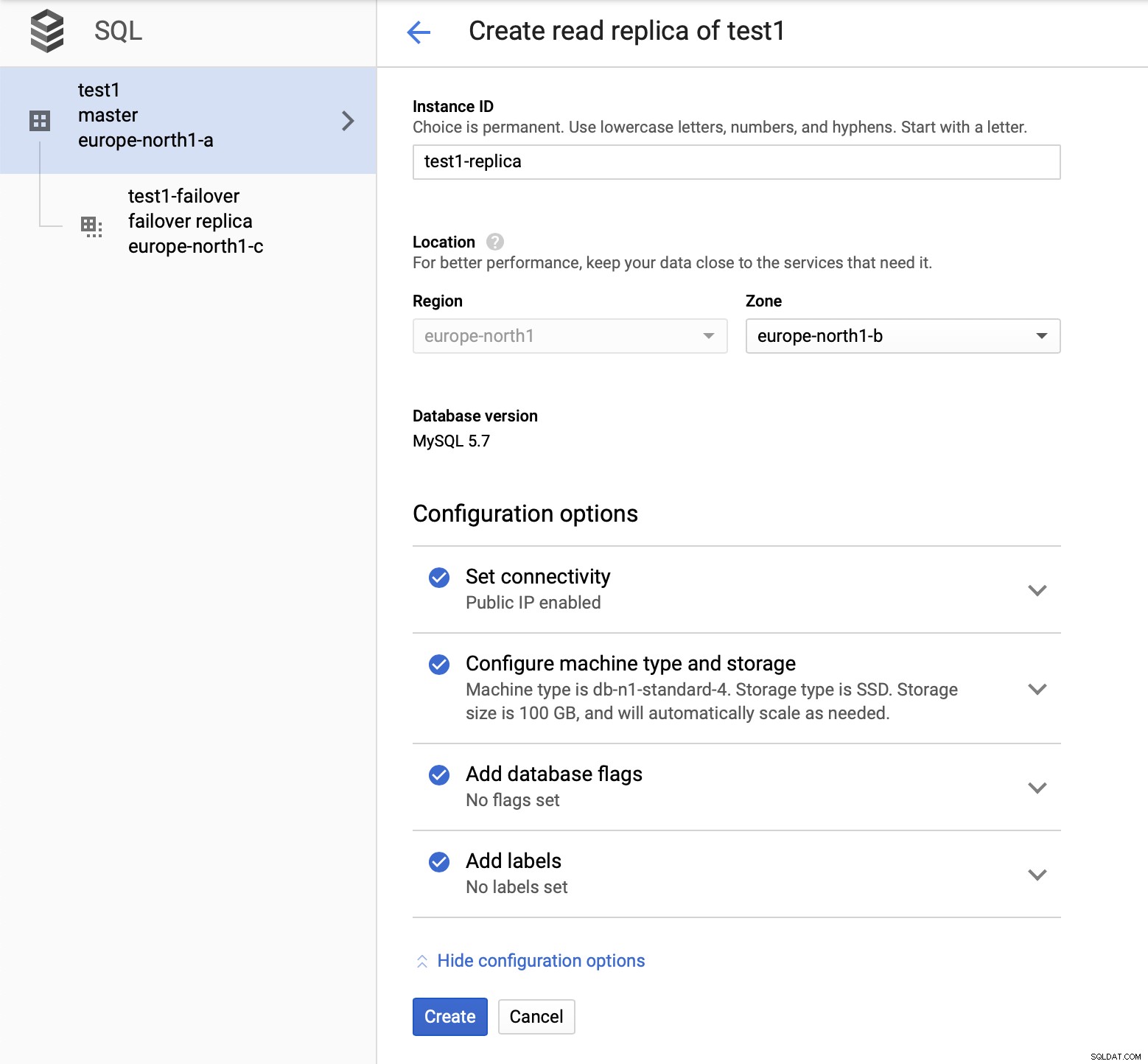
Una vez que finaliza el proceso de agregar la réplica, estamos listos para algunos pruebas Vamos a ejecutar la carga de trabajo de prueba usando Sysbench en nuestro maestro, la réplica de conmutación por error y la réplica de lectura para ver cómo funcionará. Ejecutaremos tres instancias de Sysbench, utilizando los puntos finales para los tres tipos de nodos.
Luego activaremos la conmutación por error manual a través de la interfaz de usuario:
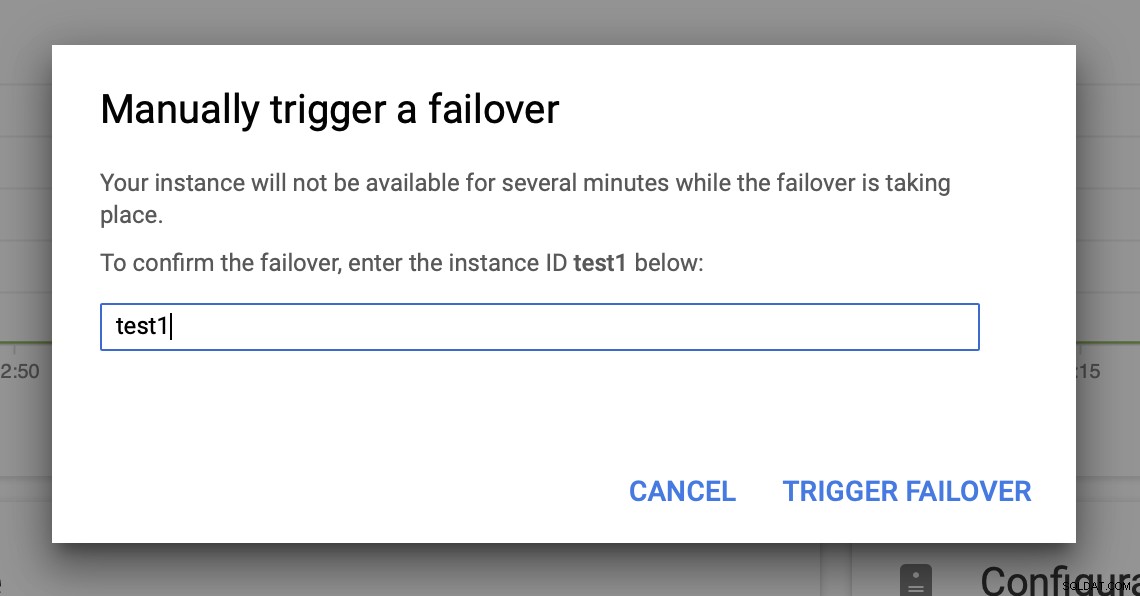
¿Prueba la conmutación por error de MySQL en Google Cloud Platform?
Llegué a este punto sin ningún conocimiento detallado de cómo funcionan los nodos SQL en GCP. Sin embargo, tenía algunas expectativas, basadas en la experiencia anterior de MySQL y lo que he visto en los otros proveedores de la nube. Para empezar, la conmutación por error al nodo de conmutación por error debería ser muy rápida. Lo que nos gustaría es mantener disponibles los esclavos de replicación, sin necesidad de una reconstrucción. También nos gustaría ver qué tan rápido podemos ejecutar la conmutación por error por segunda vez (ya que no es raro que el problema se propague de una base de datos a otra).
Lo que determinamos durante nuestras pruebas...
- Durante la conmutación por error, el maestro volvió a estar disponible en 75 a 80 segundos.
- La réplica de conmutación por error no estuvo disponible durante 5 o 6 minutos.
- La réplica de lectura estuvo disponible durante el proceso de conmutación por error, pero dejó de estar disponible durante 55 a 60 segundos después de que la réplica de conmutación por error estuvo disponible
De lo que no estamos seguros...
¿Qué sucede cuando la réplica de conmutación por error no está disponible? Según la hora, parece que se está reconstruyendo la réplica de conmutación por error. Esto tiene sentido, pero el tiempo de recuperación estaría fuertemente relacionado con el tamaño de la instancia (especialmente el rendimiento de E/S) y el tamaño del archivo de datos.
¿Qué sucede con la réplica de lectura después de que se haya reconstruido la réplica de conmutación por error? Originalmente, la réplica de lectura estaba conectada al maestro. Cuando el maestro falló, esperaríamos que la réplica de lectura proporcionara una vista desactualizada del conjunto de datos. Una vez que aparece el nuevo maestro, debe volver a conectarse a través de la replicación a la instancia (que solía ser una réplica de conmutación por error y que se promovió a maestro). No hay necesidad de un minuto de inactividad cuando se está ejecutando CHANGE MASTER.
Más importante aún, durante el proceso de conmutación por error no hay forma de ejecutar otra conmutación por error (lo cual tiene sentido):
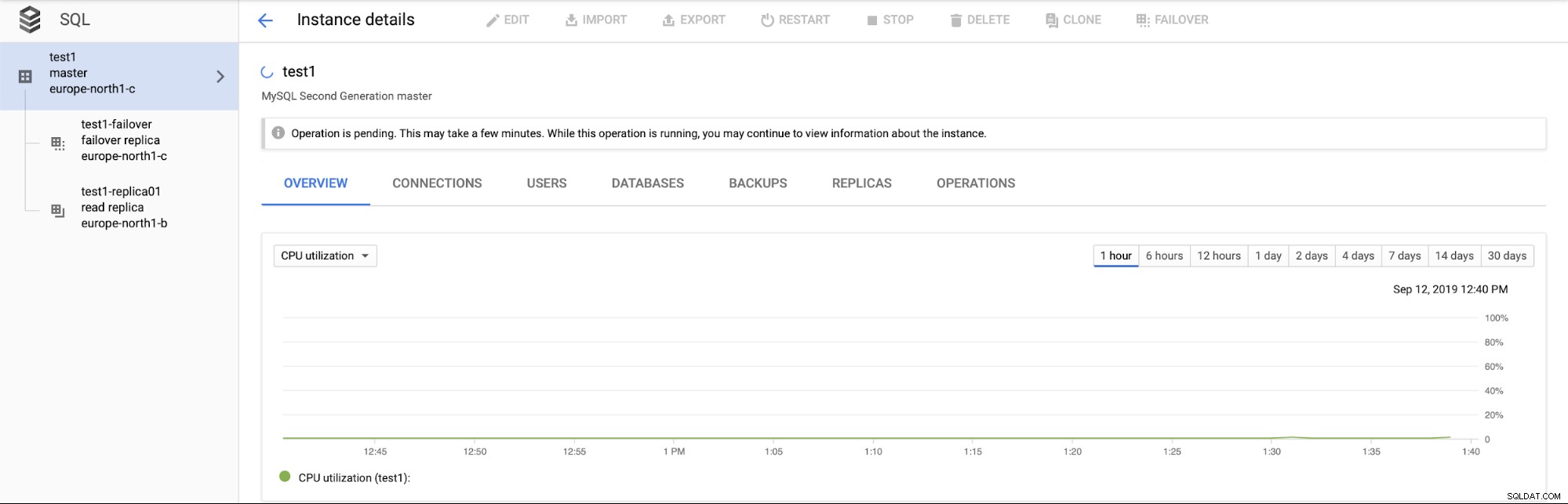
Tampoco es posible promover réplicas de lectura (que no necesariamente tiene sentido - esperaríamos poder promocionar réplicas de lectura en cualquier momento).

Es importante tener en cuenta que depender de las réplicas de lectura para proporcionar alta disponibilidad (sin crear una réplica de conmutación por error) no es una solución viable. Puede promocionar una réplica de lectura para que se convierta en maestra; sin embargo, se crearía un nuevo clúster; separado del resto de los nodos.
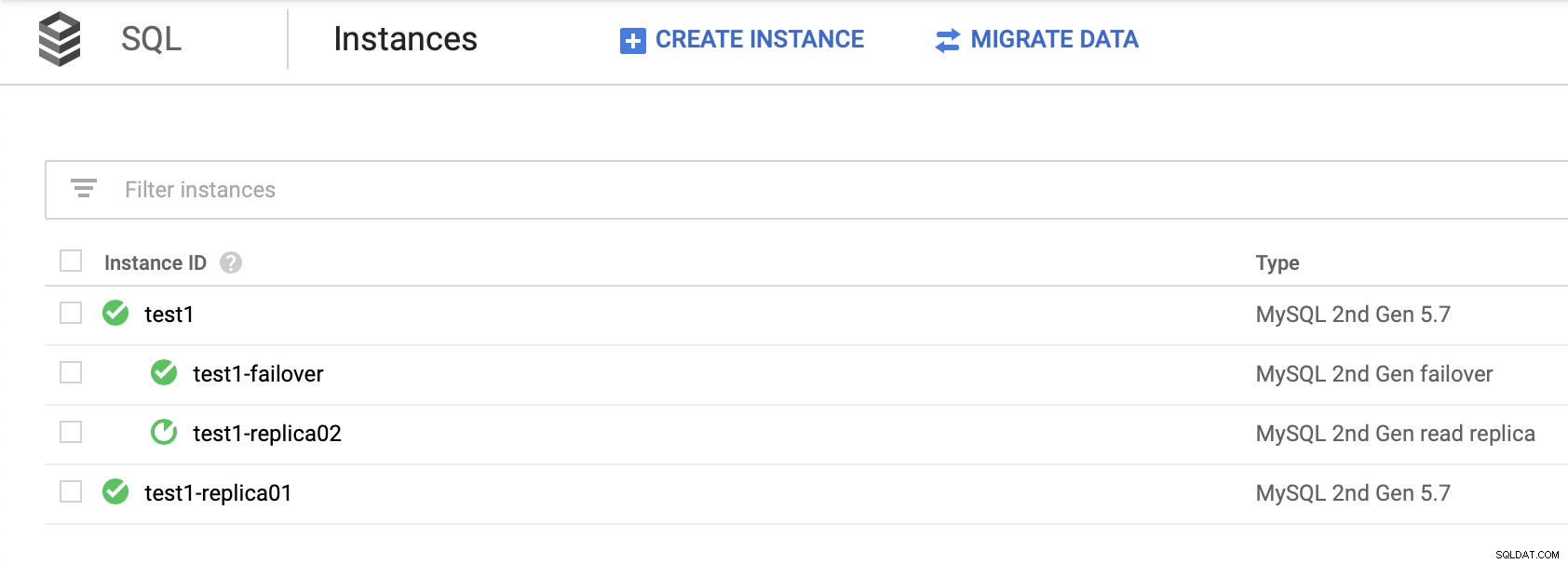
No hay forma de esclavizar sus otras réplicas fuera del nuevo clúster. La única forma de hacerlo sería crear nuevas réplicas, pero este es un proceso que requiere mucho tiempo. Además, es prácticamente inutilizable, lo que hace que la réplica de conmutación por error sea la única opción real de alta disponibilidad para los nodos SQL en Google Cloud Platform.
Conclusión
Si bien es posible crear un entorno de alta disponibilidad para los nodos de SQL en GCP, el maestro no estará disponible durante aproximadamente un minuto y medio. Todo el proceso (incluida la reconstrucción de la réplica de conmutación por error y algunas acciones en las réplicas de lectura) tomó varios minutos. Durante ese tiempo, no pudimos desencadenar una conmutación por error adicional, ni pudimos promover una réplica de lectura.
¿Tenemos usuarios de GCP? ¿Cómo está logrando una alta disponibilidad?