Anteriormente publicamos un blog sobre cómo lograr la conmutación por error y la conmutación por recuperación de MySQL en Google Cloud Platform (GCP) y en este blog veremos cómo su rival, Amazon Relational Database Service (RDS), maneja la conmutación por error. También veremos cómo puede realizar una conmutación por recuperación de su antiguo nodo maestro, devolviéndolo a su orden original como maestro.
Al comparar las nubes públicas gigantes tecnológicas que admiten servicios de bases de datos relacionales administrados, Amazon es el único que ofrece una opción alternativa (junto con MySQL/MariaDB, PostgreSQL, Oracle y SQL Server) para entregar su propio tipo de gestión de base de datos llamado Amazon Aurora. Para aquellos que no estén familiarizados con Aurora, es un motor de base de datos relacional totalmente administrado que es compatible con MySQL y PostgreSQL. Aurora es parte del servicio de base de datos administrado Amazon RDS, un servicio web que facilita la configuración, el funcionamiento y el escalado de una base de datos relacional en la nube.
¿Por qué necesitaría conmutación por error o conmutación por recuperación?
El diseño de un sistema grande que sea tolerante a fallas, de alta disponibilidad y sin punto único de falla (SPOF) requiere pruebas adecuadas para determinar cómo reaccionaría cuando las cosas salen mal.
Si le preocupa el rendimiento de su sistema al responder a la detección, aislamiento y recuperación de fallas (FDIR) de su sistema, entonces la conmutación por error y la conmutación por recuperación deben ser de gran importancia.
Conmutación por error de la base de datos en Amazon RDS
La conmutación por error se produce automáticamente (ya que la conmutación por error manual se denomina conmutación). Como se discutió en un blog anterior, la necesidad de conmutación por error ocurre una vez que su maestro de base de datos actual experimenta una falla en la red o una terminación anormal del sistema host. La conmutación por error lo cambia a un estado estable de redundancia o a un servidor de computadora, sistema, componente de hardware o red en espera.
En Amazon RDS no es necesario que haga esto, ni que lo controle usted mismo, ya que RDS es un servicio de base de datos administrado (lo que significa que Amazon maneja el trabajo por usted). Este servicio administra cosas como problemas de hardware, copia de seguridad y recuperación, actualizaciones de software, actualizaciones de almacenamiento e incluso parches de software. Hablaremos de eso más adelante en este blog.
Conmutación por recuperación de la base de datos en Amazon RDS
En el blog anterior también explicamos por qué necesitaría una conmutación por recuperación. En un entorno replicado típico, el maestro debe ser lo suficientemente potente como para soportar una carga enorme, especialmente cuando el requisito de carga de trabajo es alto. Su configuración maestra requiere especificaciones de hardware adecuadas para garantizar que pueda procesar escrituras, generar eventos de replicación, procesar lecturas críticas, etc., de manera estable. Cuando se requiere conmutación por error durante la recuperación ante desastres (o para el mantenimiento), no es raro que al promocionar un nuevo maestro se utilice un hardware inferior. Esta situación puede estar bien temporalmente, pero a la larga, se debe traer de vuelta al maestro designado para que dirija la replicación después de que se considere que está en buen estado (o se complete el mantenimiento).
A diferencia de la conmutación por error, las operaciones de conmutación por recuperación generalmente ocurren en un entorno controlado mediante el uso de la conmutación. Rara vez se hace cuando está en modo de pánico. Este enfoque brinda a sus ingenieros suficiente tiempo para planificar cuidadosamente y ensayar el ejercicio para garantizar una transición sin problemas. Su objetivo principal es simplemente traer de vuelta el maestro antiguo y bueno al estado más reciente y restaurar la configuración de replicación a su topología original. Dado que estamos tratando con Amazon RDS, realmente no hay necesidad de que se preocupe demasiado por este tipo de problemas, ya que es un servicio administrado con la mayoría de los trabajos a cargo de Amazon.
¿Cómo maneja Amazon RDS la conmutación por error de la base de datos?
Al implementar sus nodos de Amazon RDS, puede configurar su clúster de base de datos con Zona de disponibilidad múltiple (AZ) o en una Zona de disponibilidad única. Revisemos cada uno de ellos sobre cómo se procesa la conmutación por error.
¿Qué es una configuración Multi-AZ?
Cuando ocurre una catástrofe o un desastre, como interrupciones no planificadas o desastres naturales que afectan las instancias de su base de datos, Amazon RDS cambia automáticamente a una réplica en espera en otra zona de disponibilidad. Esta zona de disponibilidad suele estar en otra rama del centro de datos, a menudo lejos de la zona de disponibilidad actual donde se encuentran las instancias. Estos AZ son instalaciones de última generación y alta disponibilidad que protegen las instancias de su base de datos. Los tiempos de conmutación por error dependen de la finalización de la configuración, que a menudo se basa en el tamaño y la actividad de la base de datos, así como en otras condiciones presentes en el momento en que la instancia de base de datos principal dejó de estar disponible.
Los tiempos de conmutación por error suelen ser de 60 a 120 segundos. Sin embargo, pueden ser más largos, ya que las transacciones grandes o un proceso de recuperación prolongado pueden aumentar el tiempo de conmutación por error. Cuando se completa la conmutación por error, la consola de RDS (IU) también puede tardar más en reflejar la nueva zona de disponibilidad.
¿Qué es una configuración Single-AZ?
Las configuraciones Single-AZ solo deben usarse para sus instancias de base de datos si su RTO (Objetivo de tiempo de recuperación) y RPO (Objetivo de punto de recuperación) son lo suficientemente altos como para permitirlo. Existen riesgos relacionados con el uso de Single-AZ, como grandes tiempos de inactividad que podrían interrumpir las operaciones comerciales.
Escenarios comunes de fallas de RDS
La cantidad de tiempo de inactividad depende del tipo de falla. Repasemos cuáles son y cómo se maneja la recuperación de la instancia.
Error de instancia recuperable
Una falla de instancia de Amazon RDS ocurre cuando la instancia EC2 subyacente sufre una falla. Cuando ocurra, AWS activará una notificación de evento y le enviará una alerta mediante las notificaciones de eventos de Amazon RDS. Este sistema utiliza AWS Simple Notification Service (SNS) como procesador de alertas.
RDS intentará iniciar automáticamente una nueva instancia en la misma zona de disponibilidad, adjuntará el volumen de EBS e intentará la recuperación. En este escenario, el RTO suele ser inferior a 30 minutos. El RPO es cero porque se pudo recuperar el volumen de EBS. El volumen de EBS se encuentra en una única zona de disponibilidad y este tipo de recuperación se produce en la misma zona de disponibilidad que la instancia original.
Errores de instancias no recuperables o errores de volumen de EBS
Para la recuperación fallida de la instancia de RDS (o si el volumen de EBS subyacente sufre una falla de pérdida de datos), se requiere la recuperación de un punto en el tiempo (PITR). Amazon no maneja automáticamente PITR, por lo que debe crear un script para automatizarlo (usando AWS Lambda) o hacerlo manualmente.
El tiempo de RTO requiere iniciar una nueva instancia de Amazon RDS, que tendrá un nuevo nombre de DNS una vez creado, y luego aplicar todos los cambios desde la última copia de seguridad.
El RPO suele ser de 5 minutos, pero puede encontrarlo llamando a RDS:describe-db-instances:LatestRestorableTime. El tiempo puede variar de 10 minutos a horas dependiendo de la cantidad de registros que se deban aplicar. Solo se puede determinar mediante pruebas, ya que depende del tamaño de la base de datos, la cantidad de cambios realizados desde la última copia de seguridad y los niveles de carga de trabajo en la base de datos. Dado que las copias de seguridad y los registros de transacciones se almacenan en Amazon S3, esta recuperación puede ocurrir en cualquier zona de disponibilidad admitida en la región.
Una vez que se crea la nueva instancia, deberá actualizar el nombre del punto final de su cliente. También tiene la opción de cambiarle el nombre al nombre del punto final de la instancia de base de datos anterior (pero eso requiere que elimine la instancia fallida anterior), pero eso hace que sea imposible determinar la causa raíz del problema.
Alteraciones de la zona de disponibilidad
Las interrupciones de la zona de disponibilidad pueden ser temporales y raras; sin embargo, si la falla de AZ es más permanente, la instancia se establecerá en un estado fallido. La recuperación funcionaría como se describió anteriormente y se podría crear una nueva instancia en una zona de disponibilidad diferente, mediante la recuperación de un punto en el tiempo. Este paso debe realizarse manualmente o mediante secuencias de comandos. La estrategia para este tipo de escenario de recuperación debe ser parte de sus planes más grandes de recuperación ante desastres (DR).
Si la falla de la zona de disponibilidad es temporal, la base de datos estará inactiva pero permanecerá en el estado disponible. Usted es responsable del monitoreo a nivel de aplicación (usando herramientas de Amazon o de terceros) para detectar este tipo de escenario. Si esto ocurre, puede esperar a que se recupere la zona de disponibilidad o puede optar por recuperar la instancia en otra zona de disponibilidad con una recuperación puntual.
El RTO sería el tiempo que lleva iniciar una nueva instancia de RDS y luego aplicar todos los cambios desde la última copia de seguridad. El RPO puede ser más largo, hasta el momento en que ocurrió la falla de la zona de disponibilidad.
Prueba de conmutación por error y conmutación por recuperación en Amazon RDS
Creamos y configuramos un Amazon RDS Aurora usando db.r4.large con una implementación Multi-AZ (que creará una réplica/lector de Aurora en un AZ diferente) al que solo se puede acceder a través de EC2. Deberá asegurarse de elegir esta opción en el momento de la creación si pretende tener Amazon RDS como mecanismo de conmutación por error.
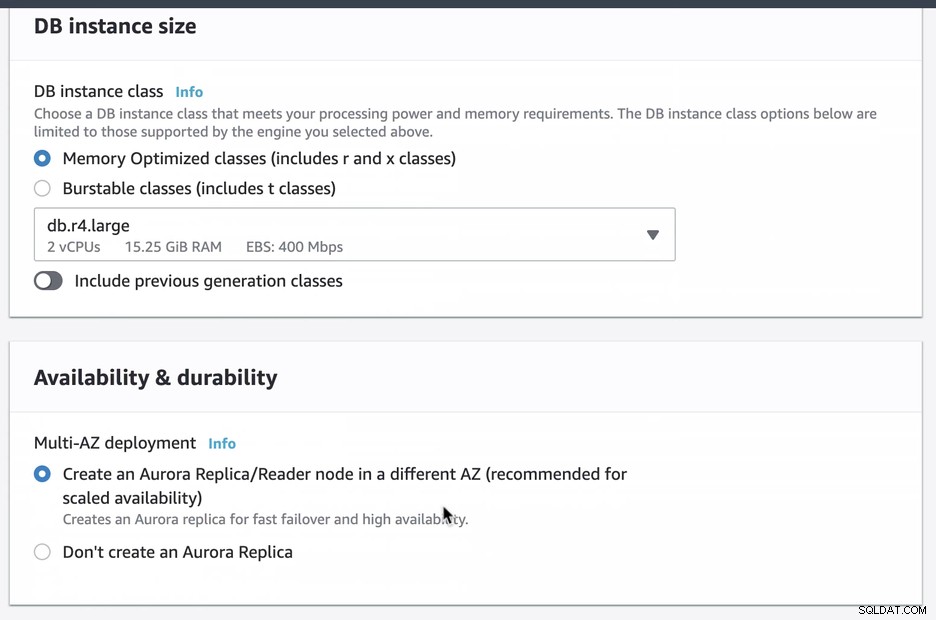
Durante el aprovisionamiento de nuestra instancia de RDS, tomó alrededor de ~11 minutos antes las instancias se volvieron disponibles y accesibles. A continuación se muestra una captura de pantalla de los nodos disponibles en RDS después de la creación:
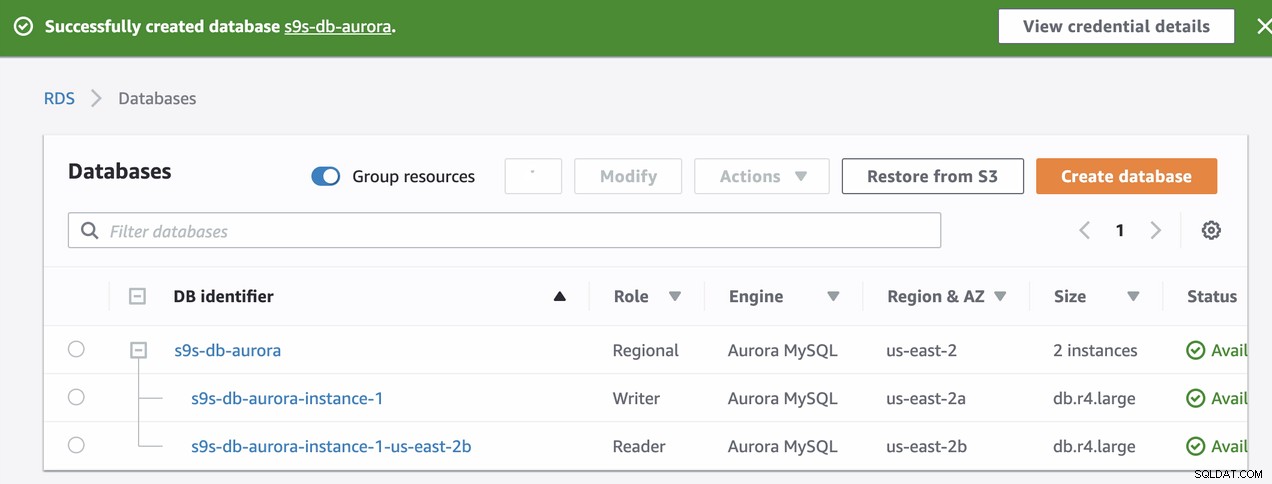
Estos dos nodos tendrán sus propios nombres de punto final designados, que utilizar para conectarse desde la perspectiva del cliente. Verifíquelo primero y verifique el nombre de host subyacente para cada uno de estos nodos. Para verificar, puede ejecutar este comando bash a continuación y simplemente reemplazar los nombres de host/puntos finales en consecuencia:
example@sqldat.com:~# host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done;
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+El resultado aclara lo siguiente,
s9s-db-aurora-instance-1 = s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-0-94 (read-write)
s9s-db-aurora-instance-1-us-east-2b = s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-1-139 (read-only)Simulación de conmutación por error de Amazon RDS
Ahora, simulemos un bloqueo para simular una conmutación por error para la instancia de escritor de Amazon RDS Aurora, que es s9s-db-aurora-instance-1 con el punto de enlace s9s-db-aurora.cluster-cmu8qdlvkepg.us -east-2.rds.amazonaws.com.
Para hacer esto, conéctese a su instancia de escritor usando el símbolo del sistema del cliente mysql y luego emita la siguiente sintaxis:
ALTER SYSTEM SIMULATE percentage_of_failure PERCENT DISK FAILURE [ IN DISK index | NODE index ]
FOR INTERVAL quantity [ YEAR | QUARTER | MONTH | WEEK| DAY | HOUR | MINUTE | SECOND ];Emitir este comando tiene su detección de recuperación de Amazon RDS y actúa bastante rápido. Aunque la consulta es para fines de prueba, puede diferir cuando esto ocurre en un evento fáctico. Puede que le interese saber más sobre cómo probar un bloqueo de instancia en su documentación. Vea cómo terminamos a continuación:
mysql> ALTER SYSTEM SIMULATE 100 PERCENT DISK FAILURE FOR INTERVAL 3 MINUTE;
Query OK, 0 rows affected (0.01 sec)Ejecutar el comando SQL anterior significa que debe simular una falla del disco durante al menos 3 minutos. Supervisé el punto en el tiempo para comenzar la simulación y tomó alrededor de 18 segundos antes de que comience la conmutación por error.
Vea a continuación cómo RDS maneja la falla de simulación y la conmutación por error,
Tue Sep 24 10:06:29 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
….
…..
………..
Tue Sep 24 10:06:44 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
……..
………..
Tue Sep 24 10:06:51 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
….
………..
…………………
Tue Sep 24 10:07:13 UTC 2019
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Los resultados de esta simulación son bastante interesantes. Tomemos esto uno a la vez.
- Alrededor de las 10:06:29, comencé a ejecutar la consulta de simulación como se indicó anteriormente.
- Alrededor de las 10:06:44, muestra que el punto final s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com con el nombre de host asignado de ip-10-20-1- 139 donde de hecho es la instancia de solo lectura, quedó inaccesible a pesar de que el comando de simulación se ejecutó bajo la instancia de lectura y escritura.
- Alrededor de las 10:06:51, muestra que el punto final s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com con el nombre de host asignado de ip-10-20-1- 139 está activo pero tiene una marca como estado de lectura y escritura. Tenga en cuenta que la variable innodb_read_only, para instancias administradas de Aurora MySQL, es su identificador para determinar si el host es un nodo de lectura y escritura o de solo lectura y Aurora también se ejecuta solo en el motor de almacenamiento InnoDB para instancias compatibles con MySQL.
- Alrededor de las 10:07:13, el orden ha cambiado. Esto significa que se realizó la conmutación por error y que las instancias se asignaron a sus puntos finales designados.
Consulte el resultado a continuación que se muestra en la consola RDS:
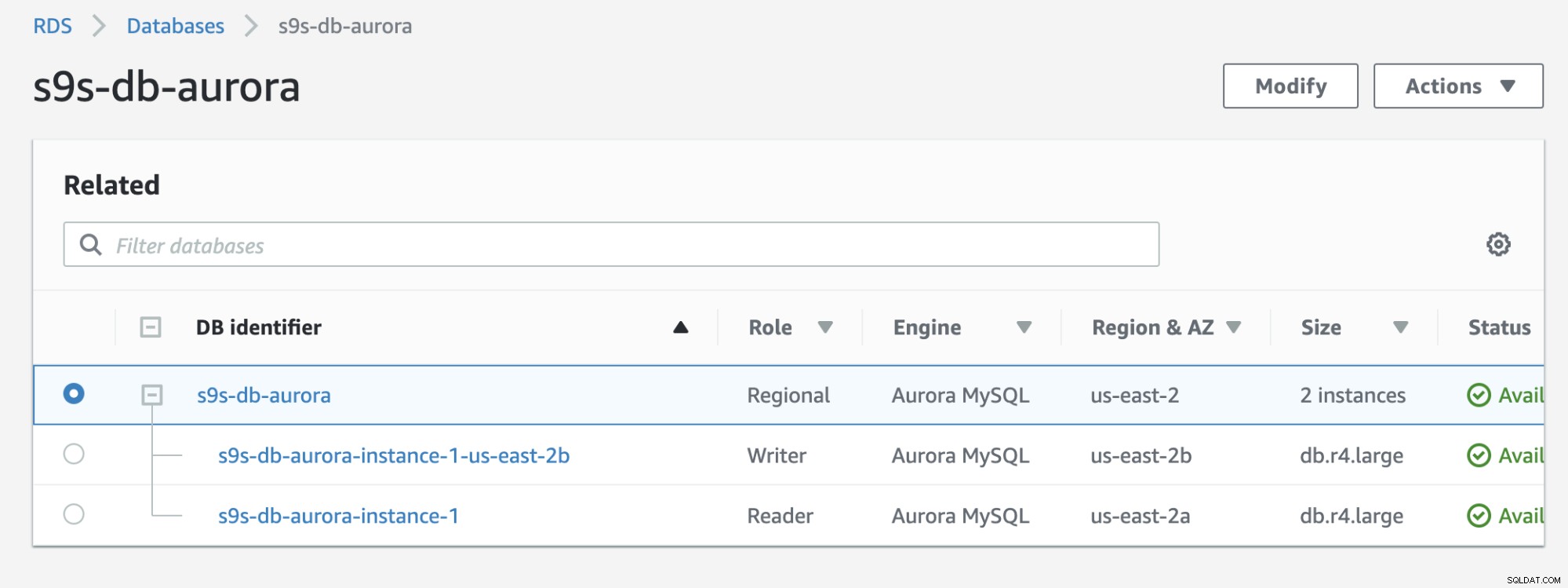
Si lo compara con el anterior, el s9s-db-aurora- instancia-1 era un lector, pero luego se promovió como escritor después de la conmutación por error. El proceso, incluida la prueba, tomó unos 44 segundos para completar la tarea, pero la conmutación por error se muestra completada en casi 30 segundos. Eso es impresionante y rápido para una conmutación por error, especialmente considerando que se trata de una base de datos de servicios administrados; lo que significa que no necesita preocuparse por ningún problema de hardware o mantenimiento.
Realización de una conmutación por recuperación en Amazon RDS
La recuperación en Amazon RDS es bastante simple. Antes de analizarlo, agreguemos una nueva réplica del lector. Necesitamos una opción para probar e identificar qué nodo elegiría AWS RDS cuando intente conmutar por recuperación al maestro deseado (o conmutar por recuperación al maestro anterior) y para ver si selecciona el nodo correcto en función de la prioridad. La lista actual de instancias a partir de ahora y sus puntos finales se muestran a continuación.
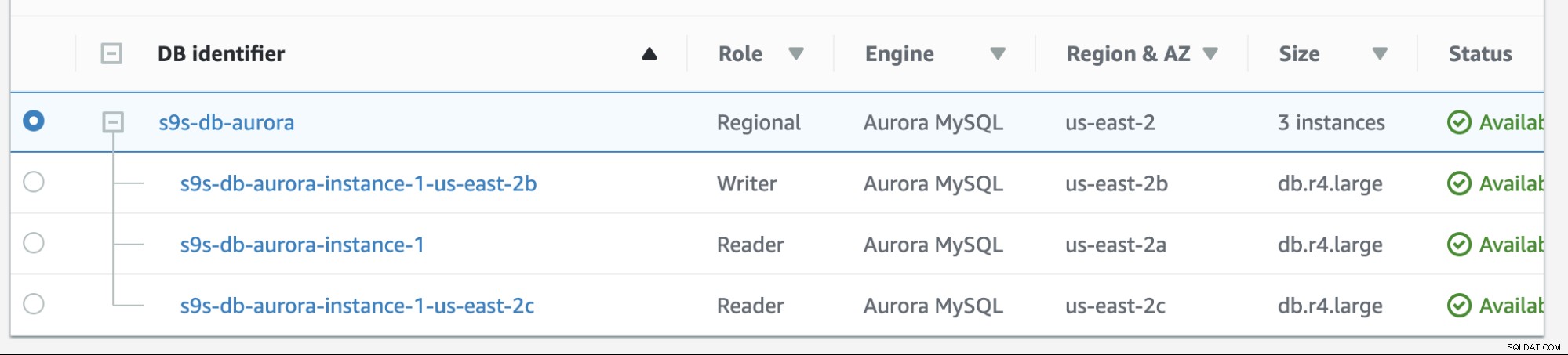

La nueva réplica se encuentra en us-east-2c AZ con nombre de host db de ip-10-20-2-239.
Intentaremos realizar una conmutación por recuperación utilizando la instancia s9s-db-aurora-instance-1 como destino de conmutación por recuperación deseado. En esta configuración tenemos dos instancias de lector. Para asegurarse de que se seleccione el nodo correcto durante la conmutación por error, deberá establecer si la prioridad o la disponibilidad están en la parte superior (nivel 0> nivel 1> nivel 2 y así sucesivamente hasta el nivel 15). Esto se puede hacer modificando la instancia o durante la creación de la réplica.
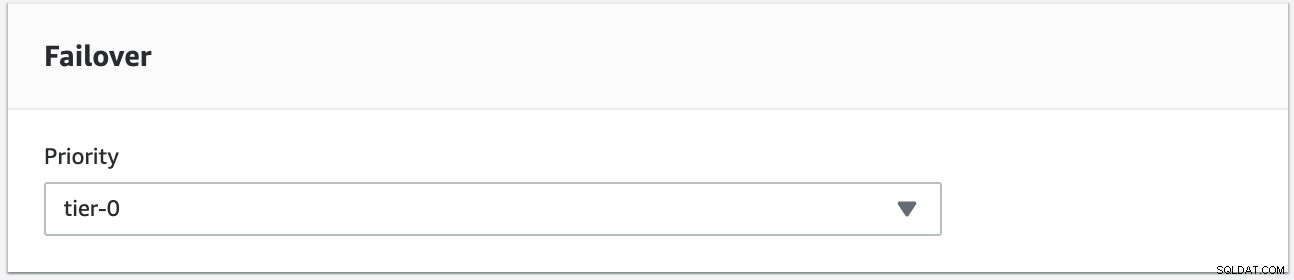
Puede verificar esto en su consola RDS.
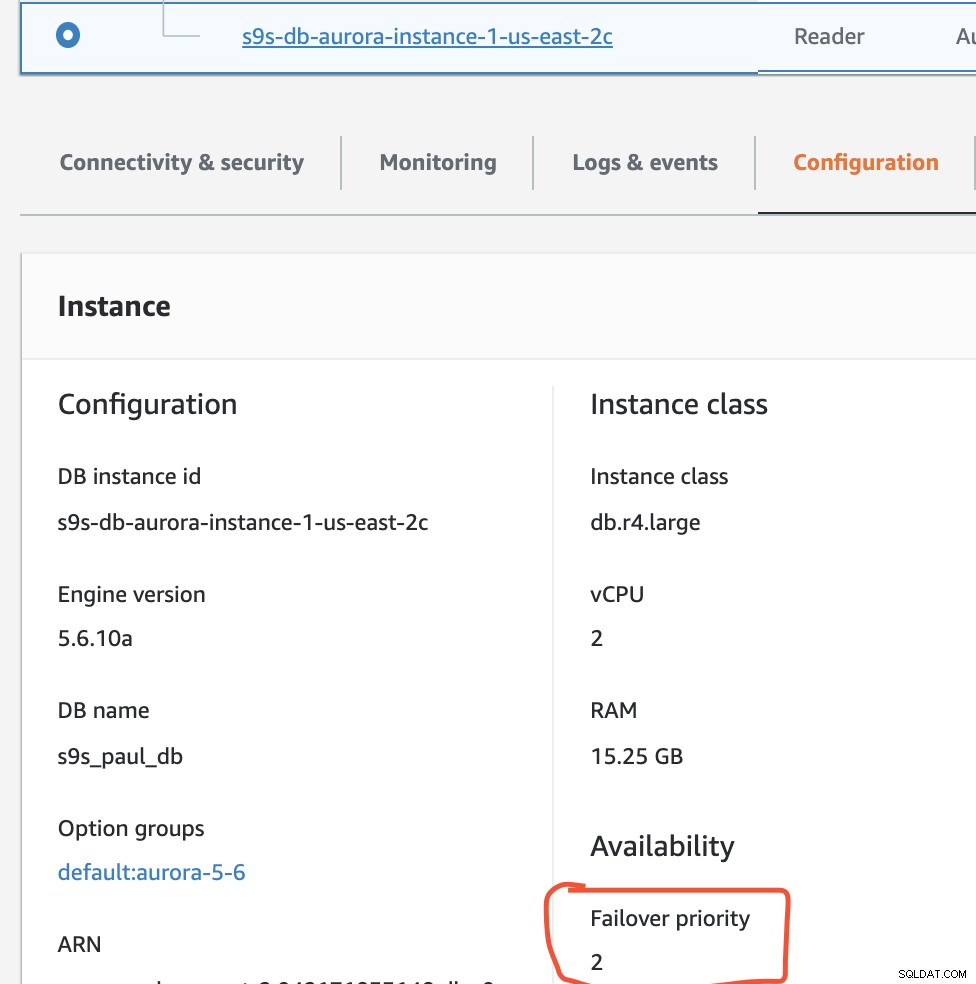
En esta configuración, s9s-db-aurora-instance-1 tiene prioridad =0 (y es una réplica de lectura), s9s-db-aurora-instance-1-us-east-2b tiene prioridad =1 (y es el escritor actual), y s9s-db-aurora-instance-1-us- east-2c tiene prioridad =2 (y también es una réplica de lectura). Veamos qué sucede cuando intentamos la conmutación por recuperación.
Puede monitorear el estado usando este comando.
$ host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); while true; do echo -e "\n==========================================="; date; echo -e "===========================================\n"; for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done; sleep 1; done;Después de que se haya activado la conmutación por error, volverá a nuestro destino deseado, que es el nodo s9s-db-aurora-instance-1.
===========================================
Tue Sep 24 13:30:59 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
…
……
………
===========================================
Tue Sep 24 13:31:35 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
…..
===========================================
Tue Sep 24 13:31:38 UTC 2019
===========================================
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+El intento de conmutación por recuperación comenzó a las 13:30:59 y finalizó alrededor de las 13:31:38 (la marca de 30 segundos más cercana). Termina ~32 segundos en esta prueba, que sigue siendo rápida.
He verificado la conmutación por error/conmutación por recuperación varias veces y ha estado intercambiando constantemente su estado de lectura y escritura entre las instancias s9s-db-aurora-instance-1 y s9s-db-aurora-instance-1- nosotros-este-2b. Esto deja s9s-db-aurora-instance-1-us-east-2c sin seleccionar a menos que ambos nodos estén experimentando problemas (lo cual es muy raro ya que todos están situados en diferentes AZ).
Durante los intentos de conmutación por error/conmutación por recuperación, el RDS avanza a un ritmo de transición rápido durante la conmutación por error de alrededor de 15 a 25 segundos (que es muy rápido). Tenga en cuenta que no tenemos grandes archivos de datos almacenados en esta instancia, pero aun así es bastante impresionante teniendo en cuenta que no hay nada más que administrar.
Conclusión
Ejecutar un Single-AZ presenta peligro al realizar una conmutación por error. Amazon RDS le permite modificar y convertir su Single-AZ en una configuración compatible con Multi-AZ, aunque esto le supondrá algunos costos. Single-AZ puede estar bien si está de acuerdo con un tiempo de RTO y RPO más alto, pero definitivamente no se recomienda para aplicaciones comerciales de alto tráfico y de misión crítica.
Con Multi-AZ, puede automatizar la conmutación por error y la conmutación por recuperación en Amazon RDS y dedicar su tiempo a la optimización o el ajuste de consultas. Esto alivia muchos problemas que enfrentan DevOps o DBA.
Aunque Amazon RDS puede causar un dilema en algunas organizaciones (ya que no es independiente de la plataforma), sigue siendo digno de consideración; especialmente si su aplicación requiere un plan de recuperación ante desastres a largo plazo y no quiere tener que perder tiempo preocupándose por la planificación del hardware y la capacidad.