La disponibilidad, accesibilidad y rendimiento de los datos son vitales para el éxito empresarial. El ajuste del rendimiento y la optimización de consultas SQL son prácticas complicadas pero necesarias para los profesionales de bases de datos. Requieren mirar varias colecciones de datos usando eventos extendidos, perfmon, planes de ejecución, estadísticas e índices, por nombrar algunos. A veces, los propietarios de las aplicaciones solicitan aumentar los recursos del sistema (CPU y memoria) para mejorar el rendimiento del sistema. Sin embargo, es posible que no necesite estos recursos adicionales y pueden tener un costo asociado. A veces, todo lo que se requiere es realizar mejoras menores para cambiar el comportamiento de la consulta.
En este artículo, analizaremos algunas de las mejores prácticas de optimización de consultas SQL para aplicar al escribir consultas SQL.
Lista de columnas SELECT * frente a SELECT
Por lo general, los desarrolladores usan la instrucción SELECT * para leer datos de una tabla. Lee todos los datos disponibles de la columna en la tabla. Supongamos que una tabla [AdventureWorks2019].[HumanResources].[Employee] almacena datos para 290 empleados y tiene el requisito de recuperar la siguiente información:
- Número de identificación nacional del empleado
- Fecha de nacimiento
- Género
- Fecha de contratación
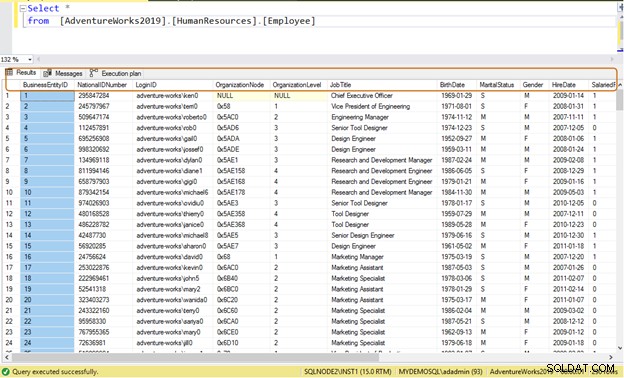
Consulta ineficiente: Si usa la declaración SELECT *, devuelve todos los datos de la columna para los 290 empleados.
Select * from [AdventureWorks2019].[HumanResources].[Employee]
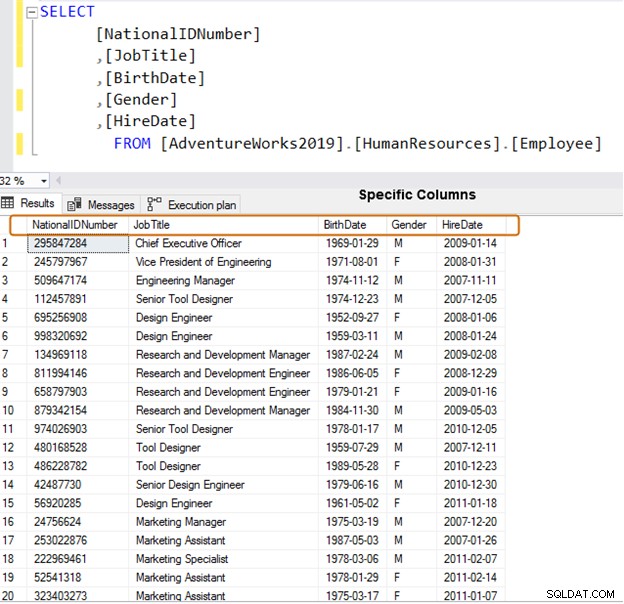
En su lugar, utilice nombres de columna específicos para la recuperación de datos.
SELECT [NationalIDNumber] ,[JobTitle] ,[BirthDate] ,[Gender] ,[HireDate] FROM [AdventureWorks2019].[HumanResources].[Employee]
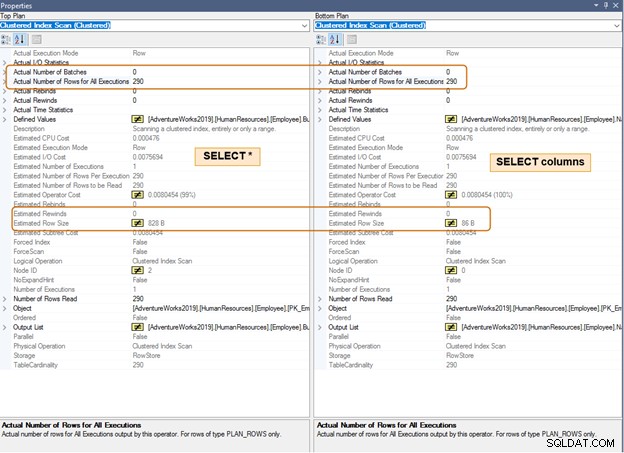
En el siguiente plan de ejecución, observe la diferencia en el tamaño de fila estimado para el mismo número de filas. También notará una diferencia en la CPU y la E/S para una gran cantidad de filas.
Uso de COUNT() frente a EXISTS
Suponga que desea verificar si existe un registro específico en la tabla SQL. Por lo general, usamos COUNT (*) para verificar el registro y devuelve la cantidad de registros en la salida.
Sin embargo, podemos usar la función IF EXISTS() para este propósito. Para la comparación, habilité las estadísticas antes de ejecutar las consultas.
La consulta de COUNT()
SET STATISTICS IO ON Select count(*) from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824 SET STATISTICS IO OFF
La consulta SI EXISTE()
SET STATISTICS IO ON IF EXISTS(Select [CarrierTrackingNumber] from [AdventureWorks2019].[Sales].[SalesOrderDetail] where [SalesOrderDetailID]=44824) PRINT 'YES' ELSE PRINT 'NO' SET STATISTICS IO OFF
Usé statisticsparser para analizar los resultados estadísticos de ambas consultas. Mira los resultados a continuación. La consulta con COUNT(*) tiene 276 lecturas lógicas mientras que IF EXISTS() tiene 83 lecturas lógicas. Incluso puede obtener una reducción más significativa en las lecturas lógicas con IF EXISTS(). Por lo tanto, debe usarlo para optimizar las consultas SQL para un mejor rendimiento.

Evite usar SQL DISTINCT
Siempre que queremos registros únicos de la consulta, habitualmente utilizamos la cláusula SQL DISTINCT. Suponga que unió dos tablas y en el resultado devuelve las filas duplicadas. Una solución rápida es especificar el operador DISTINCT que suprime la fila duplicada.
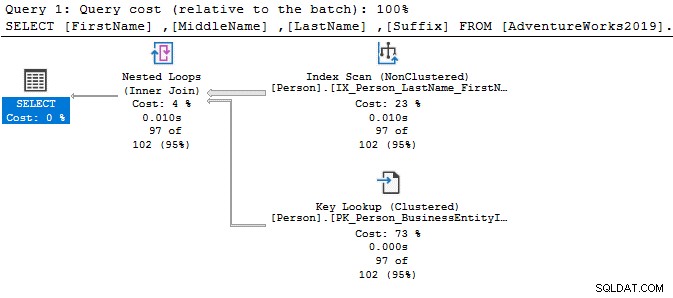
Veamos las instrucciones SELECT simples y comparemos los planes de ejecución. La única diferencia entre ambas consultas es un operador DISTINCT.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Go SELECT DISTINCT SalesOrderID FROM Sales.SalesOrderDetail Go
Con el operador DISTINCT, el costo de la consulta es del 77 %, mientras que la consulta anterior (sin DISTINCT) tiene solo un costo por lotes del 23 %.
Puede usar GROUP BY, CTE o una subconsulta para escribir código SQL eficiente en lugar de usar DISTINCT para obtener valores distintos del conjunto de resultados. Además, puede recuperar columnas adicionales para un conjunto de resultados distinto.
SELECT SalesOrderID FROM Sales.SalesOrderDetail Group by SalesOrderID
Uso de comodines en la consulta SQL
Suponga que desea buscar los registros específicos que contienen nombres que comienzan con la cadena especificada. Los desarrolladores usan un comodín para buscar los registros coincidentes.
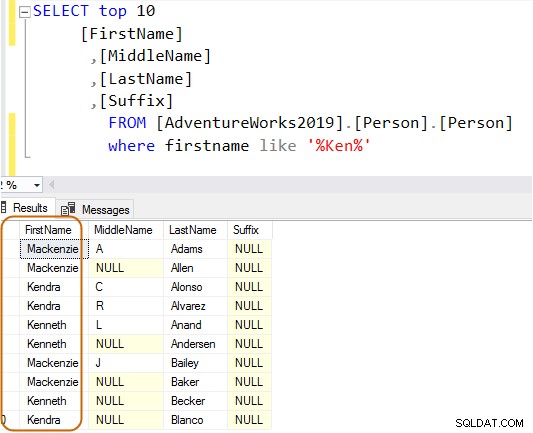
En la consulta a continuación, busca la cadena Ken en la columna de nombre. Esta consulta recupera los resultados esperados de Ken Dra y Ken Neto. Pero también proporciona resultados inesperados, por ejemplo, Macken zie y Nken ge.
En el plan de ejecución, verá el escaneo del índice y la búsqueda de clave para la consulta anterior.
Puede evitar el resultado inesperado utilizando el carácter comodín al final de la cadena.
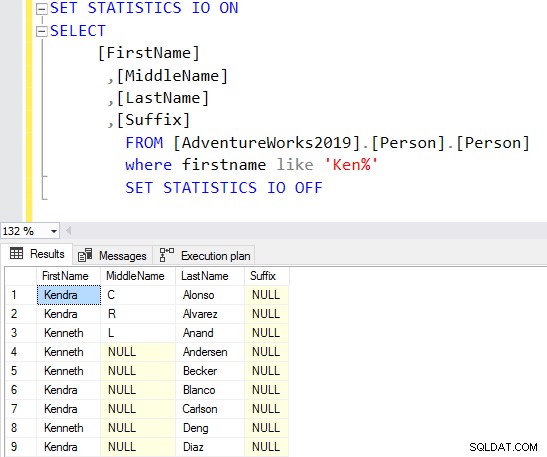
SELECT Top 10 [FirstName] ,[MiddleName] ,[LastName] ,[Suffix] FROM [AdventureWorks2019].[Person].[Person] Where firstname like 'Ken%'
Ahora, obtiene el resultado filtrado según sus requisitos.
Al usar el carácter comodín al principio, es posible que el optimizador de consultas no pueda usar el índice adecuado. Como se muestra en la siguiente captura de pantalla, con un carácter comodín al final, el optimizador de consultas también sugiere que falta un índice.
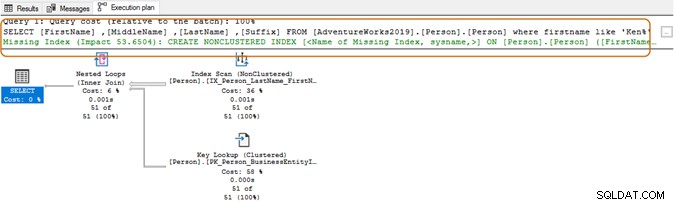
Aquí, querrá evaluar los requisitos de su aplicación. Debe intentar evitar el uso de un carácter comodín en las cadenas de búsqueda, ya que podría obligar al optimizador de consultas a usar un escaneo de tabla. Si la tabla es enorme, requerirá mayores recursos del sistema para IO, CPU y memoria, y puede causar problemas de rendimiento para su consulta SQL.
Uso de las cláusulas WHERE y HAVING
Las cláusulas WHERE y HAVING se utilizan como filtros de fila de datos. La cláusula WHERE filtra los datos antes de aplicar la lógica de agrupación, mientras que la cláusula HAVING filtra las filas después de los cálculos agregados.
Por ejemplo, en la siguiente consulta, usamos un filtro de datos en la cláusula HAVING sin una cláusula WHERE.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail GROUP BY SalesOrderID HAVING SalesOrderID>30000 and SalesOrderID<55555 and SUM(UnitPrice* OrderQty)>1 Go
La siguiente consulta filtra los datos primero en la cláusula WHERE y luego usa la cláusula HAVING para el filtro de datos agregados.
Select SalesOrderID, SUM(UnitPrice* OrderQty) as OrderTotal From Sales.salesOrderDetail where SalesOrderID>30000 and SalesOrderID<55555 GROUP BY SalesOrderID HAVING SUM(UnitPrice* OrderQty)>1000 Go
Recomiendo usar la cláusula WHERE para el filtrado de datos y la cláusula HAVING para su filtro de datos agregados como práctica recomendada.
Uso de las cláusulas IN y EXISTS
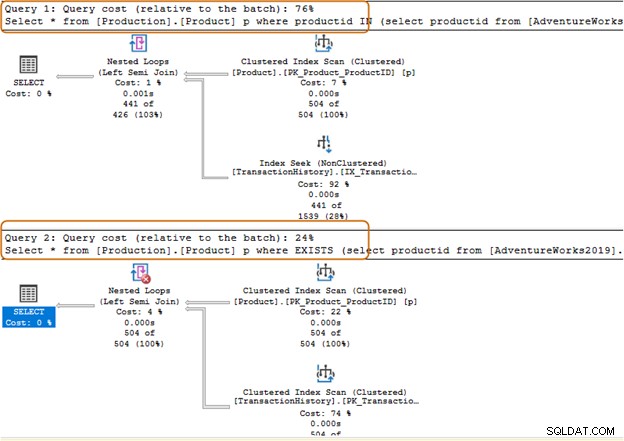
Debe evitar el uso de la cláusula del operador IN para sus consultas SQL. Por ejemplo, en la siguiente consulta, primero encontramos el ID de producto de la tabla [Producción].[Historial de transacciones]) y luego buscamos los registros correspondientes en la tabla [Producción].[Producto].
Select * from [Production].[Product] p where productid IN (select productid from [AdventureWorks2019].[Production].[TransactionHistory]); Go
En la siguiente consulta, reemplazamos la cláusula IN con una cláusula EXISTS.
Select * from [Production].[Product] p where EXISTS (select productid from [AdventureWorks2019].[Production].[TransactionHistory])
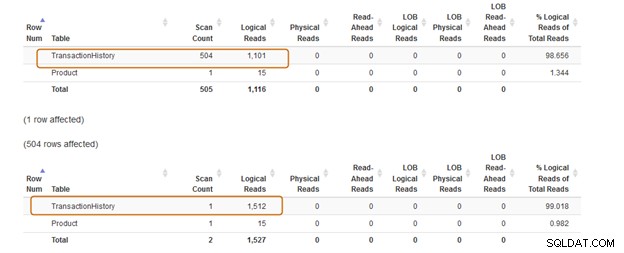
Ahora, comparemos las estadísticas después de ejecutar ambas consultas.
La cláusula IN usa 504 escaneos, mientras que la cláusula EXISTS usa 1 escaneo para la tabla [Producción].[Historial de transacciones]).
El lote de consulta de la cláusula IN cuesta el 74%, mientras que el costo de la cláusula EXISTS es del 24%. Por lo tanto, debe evitar la cláusula IN, especialmente si la subconsulta devuelve un gran conjunto de datos.
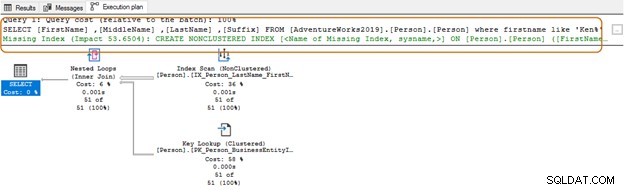
Índices faltantes
A veces, cuando ejecutamos una consulta SQL y buscamos el plan de ejecución real en SSMS, recibe una sugerencia sobre un índice que podría mejorar su consulta SQL.
Como alternativa, puede utilizar las vistas de gestión dinámica para comprobar los detalles de los índices que faltan en su entorno.
- sys.dm_db_missing_index_detalles
- sys.dm_db_missing_index_group_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_missing_index_columns
Por lo general, los DBA siguen los consejos de SSMS y crean los índices. Podría mejorar el rendimiento de las consultas por el momento. Sin embargo, no debe crear el índice directamente en función de esas recomendaciones. Podría afectar el rendimiento de otras consultas y ralentizar sus declaraciones INSERT y UPDATE.
- Primero, revise los índices existentes para su tabla SQL.
- Tenga en cuenta que la indexación excesiva y la indexación insuficiente son malas para el rendimiento de las consultas.
- Aplique las recomendaciones de índice que faltan con el mayor impacto después de revisar sus índices existentes e impleméntelas en su entorno inferior. Si su carga de trabajo funciona bien después de implementar el nuevo índice faltante, vale la pena agregarlo.
Le sugiero que consulte este artículo para obtener información detallada sobre las prácticas recomendadas de indexación:11 prácticas recomendadas de SQL Server Index para mejorar el ajuste del rendimiento.
Sugerencias de consulta
Los desarrolladores especifican las sugerencias de consulta explícitamente en sus declaraciones t-SQL. Estas sugerencias de consulta anulan el comportamiento del optimizador de consultas y lo obligan a preparar un plan de ejecución basado en su sugerencia de consulta. Las sugerencias de consulta utilizadas con frecuencia son NOLOCK, Optimize For y Recompile Merge/Hash/Loop. Son soluciones a corto plazo para sus consultas. Sin embargo, debe trabajar en el análisis de su consulta, índices, estadísticas y plan de ejecución para una solución permanente.
Según las mejores prácticas, debe minimizar el uso de cualquier sugerencia de consulta. Desea utilizar las sugerencias de consulta en la consulta SQL después de comprender primero sus implicaciones y no utilizarlas innecesariamente.
Recordatorios de optimización de consultas SQL
Como comentamos, la optimización de consultas SQL es un camino abierto. Puede aplicar mejores prácticas y pequeñas correcciones que pueden mejorar en gran medida el rendimiento. Considere los siguientes consejos para un mejor desarrollo de consultas:
- Mire siempre las asignaciones de recursos del sistema (discos, CPU, memoria)
- Revise sus marcas de rastreo de inicio, índices y tareas de mantenimiento de la base de datos
- Analice su carga de trabajo mediante eventos extendidos, generadores de perfiles o herramientas de supervisión de bases de datos de terceros
- Siempre implemente cualquier solución (incluso si está 100 % seguro) primero en el entorno de prueba y analice su impacto; una vez que esté satisfecho, planifique las implementaciones de producción