El IGNORE_DUP_KEY opción para índices únicos especifica cómo SQL Server responde a un intento de INSERT valores duplicados:solo se aplica a tablas (no vistas) y solo a inserciones. Cualquier porción de inserción de un MERGE declaración ignora cualquier IGNORE_DUP_KEY configuración de índice.
Cuando IGNORE_DUP_KEY está OFF , el primer duplicado encontrado da como resultado un error y no se inserta ninguna de las filas nuevas.
Cuando IGNORE_DUP_KEY está ON , se descartan las filas insertadas que violarían la exclusividad. Las filas restantes se insertaron correctamente. Una advertencia se emite un mensaje en lugar de un error:
Resumen del artículo
El IGNORE_DUP_KEY La opción de índice se puede especificar para índices únicos agrupados y no agrupados. Usarlo en un índice agrupado puede resultar en un rendimiento mucho más bajo que para un índice único no agrupado.
El tamaño de la diferencia de rendimiento depende de cuántas infracciones de unicidad se encuentren durante el INSERT operación. Cuantas más infracciones, peor se comporta el índice único agrupado en comparación. Si no hay violaciones en absoluto, la inserción de índice agrupado puede incluso funcionar mejor.
Inserciones de índices únicos agrupados
Para un índice único agrupado con IGNORE_DUP_KEY establecido, los duplicados son manejados por el motor de almacenamiento .
Gran parte del trabajo relacionado con la inserción de cada fila se realiza antes de que se detecte el duplicado. Por ejemplo, un inserto de índice agrupado El operador navega por el árbol b del índice agrupado hasta el punto donde iría la nueva fila, tomando pestillos de página y la jerarquía habitual de bloqueos, antes de descubrir la clave duplicada.
Cuando se detecta la condición de clave duplicada, aparece un error es elevado. En lugar de cancelar la ejecución y devolver el error al cliente, el error se maneja internamente. La fila problemática no se inserta y la ejecución continúa, buscando la siguiente fila para insertar. Si esa fila encuentra una clave duplicada, se genera y maneja otro error, y así sucesivamente.
Las excepciones son muy costosas de lanzar y atrapar. Un número significativo de duplicados ralentizará notablemente la ejecución.
Inserciones de índice único no agrupado
Para un índice único no agrupado con IGNORE_DUP_KEY establecido, los duplicados son manejados por el procesador de consultas . Se detectan los duplicados y se emite una advertencia antes de intentar cada inserción.
El procesador de consultas elimina los duplicados del flujo de inserción, lo que garantiza que el motor de almacenamiento no vea duplicados. Como resultado, no se genera ni se maneja internamente ningún error de infracción de clave única.
El intercambio
Existe una compensación entre el costo de detectar y eliminar claves duplicadas en el plan de ejecución, versus el costo de realizar un trabajo significativo relacionado con la inserción y arrojar y capturar errores cuando se encuentra un duplicado.
Si se espera que los duplicados sean muy raros , la solución del motor de almacenamiento (índice agrupado) puede ser más eficiente. Cuando los duplicados son menos raros, el enfoque del procesador de consultas probablemente dará sus frutos. El punto de cruce exacto dependerá de factores como la eficiencia del tiempo de ejecución de los componentes del plan de ejecución utilizados para detectar y eliminar duplicados.
El resto de este artículo proporciona una demostración y analiza con más detalle por qué el enfoque del motor de almacenamiento puede funcionar tan mal.
Demostración
El siguiente script crea una tabla temporal con un millón de filas. Tiene 1000 valores únicos y 1000 filas para cada valor único. Este conjunto de datos se utilizará como fuente de datos para inserciones en tablas con diferentes configuraciones de índice.
DROP TABLE IF EXISTS #Data;
GO
CREATE TABLE #Data (c1 integer NOT NULL);
GO
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE
@Loop integer = 1,
@N integer = 1;
WHILE @N <= 1000
BEGIN
SET @Loop = 1;
BEGIN TRANSACTION;
-- Add 1,000 copies of the current loop value
WHILE @Loop <= 50
BEGIN
INSERT #Data
(c1)
VALUES
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N);
SET @Loop += 1;
END;
COMMIT TRANSACTION;
SET @N += 1;
END;
CREATE CLUSTERED INDEX cx
ON #Data (c1)
WITH (MAXDOP = 1); Línea de base
La siguiente inserción en una variable de tabla con un índice agrupado no único toma alrededor de 900 ms :
DECLARE @T table
(
c1 integer NOT NULL
INDEX cuq CLUSTERED (c1)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D;
Tenga en cuenta la falta de IGNORE_DUP_KEY en la variable de la tabla de destino.
Índice único agrupado
Insertar los mismos datos en un único agrupado índice con IGNORE_DUP_KEY establecer ON toma alrededor de 15,900ms — casi 18 veces peor:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Índice único no agrupado
Insertar los datos en un único no agrupado índice con IGNORE_DUP_KEY establecer ON toma alrededor de 700ms :
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE NONCLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Resumen de rendimiento
La prueba de referencia tarda 900 ms para insertar el millón de filas. La prueba de índice no agrupado tarda 700 ms para insertar solo las 1000 claves distintas. La prueba del índice agrupado tarda 15 900 ms para insertar las mismas 1000 filas únicas.
Esta prueba se configura deliberadamente para resaltar el bajo rendimiento de la implementación del motor de almacenamiento, al generar 999 unidades de trabajo desperdiciado (bloqueos, bloqueos, manejo de errores) por cada fila exitosa.
El mensaje previsto no es que IGNORE_DUP_KEY siempre tendrá un desempeño deficiente en los índices agrupados, solo que podría ser así, y puede haber una gran diferencia entre los índices agrupados y los no agrupados.
Plan de ejecución de índices agrupados
No hay mucho que ver en el plan de inserción de índice agrupado:
Se pasan 1 000 000 de filas a la inserción de índice agrupado operador, que se muestra como 'retornando' 1,000 filas. Profundizando en los detalles del plan, podemos ver:
- 1 244 008 lecturas lógicas en el operador de inserción.
- La mayor parte del tiempo de ejecución se gasta en Insertar operador.
- 11ms de
SOS_SCHEDULER_YIELDespera (es decir, no hay otras esperas).
Nada que realmente explique los 15.900 ms del tiempo transcurrido.
Por qué el rendimiento es tan bajo
Es evidente que este plan tendrá que hacer mucho trabajo para cada fila:
- Navegue por los niveles del árbol B del índice agrupado, trabando y bloqueando a medida que avanza, para encontrar el punto de inserción para el nuevo registro.
- Si alguna de las páginas de índice necesarias no está en la memoria, será necesario recuperarlas del disco.
- Construya una nueva fila de árbol b en la memoria.
- Preparar registros.
- Si se encuentra una clave duplicada (que no es un registro fantasma), genera un error, maneja ese error internamente, libera la fila actual y continúa en un punto adecuado del código para procesar la siguiente fila candidata.
Todo eso es una buena cantidad de trabajo, y recuerda que todo sucede para cada fila .
La parte en la que quiero concentrarme es en la generación y el manejo de errores, porque es extremadamente caro. Los aspectos restantes mencionados anteriormente ya se abarataron al máximo mediante el uso de una variable de tabla y una tabla temporal en la demostración.
Excepciones
Lo primero que quiero hacer es mostrar que la inserción de índice agrupado El operador realmente genera una excepción cuando encuentra una clave duplicada.
Una forma de mostrar esto directamente es adjuntando un depurador y capturando un seguimiento de la pila en el punto en que se lanza la excepción:
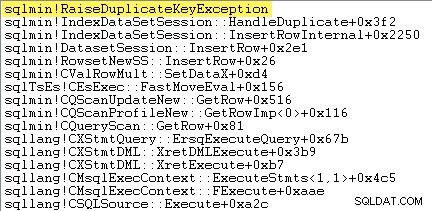
El punto importante aquí es que lanzar y capturar excepciones es muy costoso.
Supervisar SQL Server con Windows Performance Recorder mientras se ejecutaba la prueba y analizar los resultados en Windows Performance Analyzer muestra:
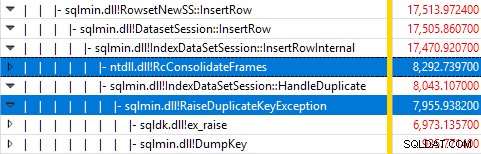
Casi todo el tiempo de ejecución de la consulta se gasta en sqlmin!IndexDataSetSession::InsertRowInternal como se esperaría de una consulta que hace poco más que insertar filas.
La sorpresa es que el 45 % de ese tiempo se dedica a generar excepciones a través de sqlmin!RaiseDuplicateKeyException y otro 47% se gasta en el bloque catch de excepción asociado (el ntdll!RcConsolidateFrames jerarquía) .
Para resumir:generar y capturar excepciones constituye 92% del tiempo de ejecución de nuestra consulta de inserción de índice agrupado de prueba.
Problemas de recopilación de datos
Los lectores perspicaces pueden notar una cantidad significativa (alrededor del 12 %) de tiempo dedicado a generar excepciones en sqlmin!DumpKey en el gráfico del Analizador de rendimiento de Windows. Vale la pena explorarlo rápidamente, junto con un par de elementos relacionados.
Como parte de generar una excepción, SQL Server debe recopilar algunos datos que solo están disponibles en el momento en que ocurrió el error. El número de error asociado con una excepción de clave duplicada es 2627. El texto del mensaje en sys.messages para ese número de error es:
La información para completar esos marcadores de lugar debe recopilarse en el momento en que se genera el error; ¡no estará disponible más adelante! Eso significa buscar y formatear el tipo de restricción, su nombre, el nombre completo del objeto de destino y el valor clave específico. Todo eso lleva tiempo.
El siguiente seguimiento de la pila muestra el servidor formateando el valor de la clave duplicada como una cadena Unicode durante el DumpKey llamar:
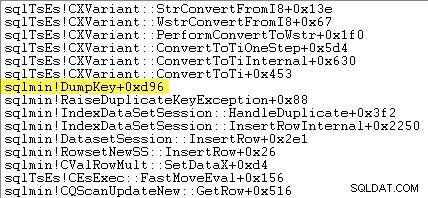
El manejo de excepciones también implica capturar un seguimiento de la pila:
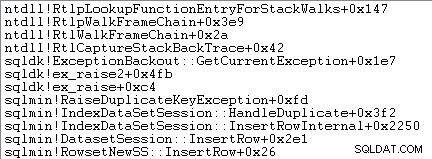
SQL Server también registra información sobre excepciones (incluidos los marcos de pila) en un búfer de anillo pequeño, como se muestra a continuación:
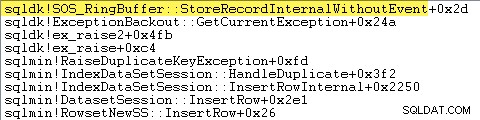
Puede ver esas entradas del búfer circular usando un comando como:
SELECT TOP (10)
date_time =
DATEADD
(
MILLISECOND,
DORB.[timestamp] - DOSI.ms_ticks,
SYSDATETIME()
),
record = CONVERT(xml, DORB.record)
FROM sys.dm_os_ring_buffers AS DORB
CROSS JOIN sys.dm_os_sys_info AS DOSI
WHERE
DORB.ring_buffer_type = N'RING_BUFFER_EXCEPTION'
ORDER BY
DORB.[timestamp] DESC; A continuación se muestra un ejemplo del registro xml para una excepción de clave duplicada. Tenga en cuenta los marcos de pila:
<Record id="4611442" type="RING_BUFFER_EXCEPTION" time="93079430">
<Exception>
<Task address="0x00000245B5E1FC28" />
<Error>2627</Error>
<Severity>14</Severity>
<State>1</State>
<UserDefined>0</UserDefined>
<Origin>0</Origin>
</Exception>
<Stack>
<frame id="0">0X00007FFAC659E80A</frame>
<frame id="1">0X00007FFACBAC0EFD</frame>
<frame id="2">0X00007FFACBAA1252</frame>
<frame id="3">0X00007FFACBA9E040</frame>
<frame id="4">0X00007FFACAB55D53</frame>
<frame id="5">0X00007FFACAB55C06</frame>
<frame id="6">0X00007FFACB3E3D0B</frame>
<frame id="7">0X00007FFAC92020EC</frame>
<frame id="8">0X00007FFACAB5B2FA</frame>
<frame id="9">0X00007FFACABA3B9B</frame>
<frame id="10">0X00007FFACAB3D89F</frame>
<frame id="11">0X00007FFAC6A9D108</frame>
<frame id="12">0X00007FFAC6AB2BBF</frame>
<frame id="13">0X00007FFAC6AB296F</frame>
<frame id="14">0X00007FFAC6A9B7D0</frame>
<frame id="15">0X00007FFAC6A9B233</frame>
</Stack>
</Record> Todo este trabajo de fondo ocurre para cada excepción. En nuestra prueba, eso significa que sucede 999 000 veces, una vez por cada fila que encuentra una infracción de clave duplicada.
Hay muchas maneras de ver esto, por ejemplo, ejecutando un seguimiento de Profiler usando la Excepción evento en Errores y advertencias clase. En nuestro caso de prueba, esto eventualmente producir 999.000 filas con TextData elementos como este:
Violación de la restricción CLAVE ÚNICA 'UQ__#AC166DE__3213663B8B6E2E0E'No se puede insertar la clave duplicada en el objeto 'dbo.@T'.
El valor de la clave duplicada es (173).
Adjuntar Profiler significa que cada evento de manejo de excepciones adquiere una gran cantidad de sobrecarga adicional, ya que los datos adicionales necesarios se recopilan y formatean. Los datos predeterminados mencionados anteriormente siempre se recopilan, incluso si nadie está consumiendo activamente la información.
Para ser claros:los números de rendimiento informados en este artículo se obtuvieron sin un depurador conectado y sin ningún otro monitoreo activo.
Plan de ejecución de índices no agrupados
A pesar de ser mucho más rápido, el plan de inserción de índices no agrupados es un poco más complejo, por lo que lo dividiré en dos partes.
El tema general es que este plan es más rápido porque elimina los duplicados antes tratando de insertarlos en la tabla de destino.
Parte 1
Primero, el lado derecho del plan de índice no agrupado:
Esta parte del plan rechaza cualquier fila que tenga una coincidencia clave en la tabla de destino para el índice único con IGNORE_DUP_KEY establecer ON .
Es posible que esté esperando ver un Anti Semi Join aquí, pero SQL Server no tiene la infraestructura necesaria para emitir la advertencia de clave duplicada requerida con un Anti Semi Join operador. (Si eso aún no tiene sentido, debería hacerlo en breve).
En su lugar, obtenemos un plan con una serie de características interesantes:
- La exploración del índice agrupado es
Ordered:Truepara proporcionar información a Fusionar la semiunión izquierda ordenado por columnac1en el#Datamesa. - El escaneo de índice de la variable de la tabla es
Ordered:False - La clasificación ordena filas por columna
c1en la variable de la tabla. Este pedido podría haber sido proporcionado por un pedido escaneo del índice de variables de la tabla enc1, pero el optimizador decide el Orden es la forma más económica de proporcionar el nivel requerido de protección de Halloween. - La variable de tabla Exploración de índice tiene
UPDLOCKinterno ySERIALIZABLEsugerencias aplicadas para garantizar la estabilidad del objetivo durante la ejecución del plan. - La Fusionar semiunión izquierda busca coincidencias en la variable de la tabla para cada valor de
c1devuelto desde el#Datamesa. A diferencia de una semi unión regular, emite cada fila recibida en su entrada superior. Establece una bandera en una columna de sondeo para indicar si la fila actual encontró una coincidencia o no. La columna de la sonda se emite desde Fusionar la semiunión izquierda como una expresión llamadaExpr1012. - La Afirmación el operador comprueba el valor de la columna de la sonda
Expr1012. La primera vez que ve una fila con un valor de columna de sondeo no nulo (lo que indica que se encontró una coincidencia de clave de índice), emite un "Se ignoró la clave duplicada" mensaje. - La Afirmación solo pasa las filas donde la columna de la sonda es nula. Esto elimina las filas entrantes que producirían un error de clave duplicada.
Todo eso puede parecer complejo, pero es esencialmente tan simple como establecer una marca si se encuentra una coincidencia, emitir una advertencia la primera vez que se establece la marca y solo pasar filas hacia la inserción que aún no existen en la tabla de destino. .
Parte 2
La segunda parte del plan sigue a Assert operador:
La parte anterior del plan eliminó las filas que tenían una coincidencia en la tabla de destino. Esta parte del plan elimina los duplicados dentro del conjunto de inserción .
Por ejemplo, imagine que no hay filas en la tabla de destino donde c1 = 1 . Todavía podríamos causar un error de clave duplicada si intentamos insertar dos filas con c1 = 1 de la tabla fuente. Necesitamos evitar eso para respetar la semántica de IGNORE_DUP_KEY = ON .
Este aspecto es manejado por el Segmento y Superior operadores.
El segmento operador establece una nueva bandera (etiquetada como Segment1015 ) cuando encuentra una fila con un nuevo valor para c1 . Dado que las filas se presentan en c1 orden (gracias a la función Merge que preserva el orden) ), el plan puede confiar en todas las filas con el mismo c1 valor que llega en un flujo contiguo.
La parte superior el operador pasa una fila por cada grupo de duplicados, como lo indica el Segmento bandera. Si el Superior el operador encuentra más de una fila para el mismo Segmento grupo (c1 valor), emite un "Se ignoró la clave duplicada" advertencia, si es la primera vez que el plan encuentra esa condición.
El efecto neto de todo esto es que solo se pasa una fila a los operadores de inserción para cada valor único de c1 y se genera una advertencia si es necesario.
El plan de ejecución ahora ha eliminado todas las posibles infracciones de claves duplicadas, por lo que el inserto de tabla restante y Inserción de índice los operadores pueden insertar filas de forma segura en el montón y en el índice no agrupado sin temor a un error de clave duplicada.
Recuerda que el UPDLOCK y SERIALIZABLE las sugerencias aplicadas a la tabla de destino aseguran que el conjunto no pueda cambiar durante la ejecución. En otras palabras, una declaración concurrente no puede cambiar la tabla de destino de modo que se produzca un error de clave duplicada en Insertar operadores. Eso no es una preocupación aquí ya que estamos usando una variable de tabla privada, pero SQL Server aún agrega las sugerencias como medida de seguridad general.
Sin esas sugerencias, un proceso simultáneo podría agregar una fila a la tabla de destino que generaría una infracción de clave duplicada, a pesar de las comprobaciones realizadas en la parte 1 del plan. SQL Server debe asegurarse de que los resultados de la verificación de existencia sigan siendo válidos.
El lector curioso puede ver algunas de las funciones descritas anteriormente al habilitar las marcas de rastreo 3604 y 8607 para ver el árbol de salida del optimizador:
PhyOp_RestrRemap
PhyOp_StreamUpdate(INS TBL: @T, iid 0x2 as IDX, Sort(QCOL: .c1, )), {
- COL: Bmk10001013 = COL: Bmk1000
- COL: c11014 = QCOL: .c1}
PhyOp_StreamUpdate(INS TBL: @T, iid 0x0 as TBLInsLocator(COL: Bmk1000 ) REPORT-COUNT), {
- QCOL: .c1= QCOL: [D].c1}
PhyOp_GbTop Group(QCOL: [D].c1,) WARN-DUP
PhyOp_StreamCheck (WarnIgnoreDuplicate TABLE)
PhyOp_MergeJoin x_jtLeftSemi M-M, Probe COL: Expr1012 ( QCOL: [D].c1) = ( QCOL: .c1)
PhyOp_Range TBL: #Data(alias TBL: D)(1) ASC
PhyOp_Sort +s -d QCOL: .c1
PhyOp_Range TBL: @T(2) ASC Hints( UPDLOCK SERIALIZABLE FORCEDINDEX )
ScaOp_Comp x_cmpIs
ScaOp_Identifier QCOL: [D].c1
ScaOp_Identifier QCOL: .c1
ScaOp_Logical x_lopIsNotNull
ScaOp_Identifier COL: Expr1012
Pensamientos finales
El IGNORE_DUP_KEY La opción de índice no es algo que la mayoría de la gente usará muy a menudo. Aún así, es interesante ver cómo se implementa esta funcionalidad y por qué puede haber grandes diferencias de rendimiento entre IGNORE_DUP_KEY en índices agrupados y no agrupados.
En muchos casos, valdrá la pena seguir el ejemplo del procesador de consultas y buscar escribir consultas que eliminen duplicados explícitamente, en lugar de confiar en IGNORE_DUP_KEY . En nuestro ejemplo, eso significaría escribir:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED -- no IGNORE_DUP_KEY!
);
INSERT @T
(c1)
SELECT DISTINCT -- Remove duplicates
D.c1
FROM #Data AS D; Esto se ejecuta en alrededor de 400 ms , solo para que conste.