Existen varios métodos para analizar las consultas de bajo rendimiento en SQL Server, en particular, el almacén de consultas, los eventos extendidos y las vistas de administración dinámica (DMV). Cada opción tiene pros y contras. Extended Events proporciona datos sobre la ejecución individual de consultas, mientras que Query Store y los DMV agregan datos de rendimiento. Para utilizar Query Store y Extended Events, debe configurarlos con anticipación, ya sea habilitando Query Store para sus bases de datos o configurando una sesión XE e iniciándola. Los datos del DMV siempre están disponibles, por lo que muy a menudo es el método más fácil para obtener un primer vistazo rápido al rendimiento de las consultas. Aquí es donde las consultas DMV de Glenn son útiles:dentro de su secuencia de comandos, tiene varias consultas que puede usar para encontrar las consultas principales para la instancia en función de la CPU, la E/S lógica y la duración. Dirigirse a las consultas que consumen más recursos suele ser un buen comienzo para la resolución de problemas, pero no podemos olvidarnos del escenario de "muerte por mil cortes":la consulta o el conjunto de consultas que se ejecutan con MUCHA frecuencia, tal vez cientos o miles de veces al día. minuto. Glenn tiene una consulta en su conjunto que enumera las principales consultas para una base de datos en función del recuento de ejecuciones, pero según mi experiencia, no ofrece una imagen completa de su carga de trabajo.
El DMV principal que se usa para ver las métricas de rendimiento de las consultas es sys.dm_exec_query_stats. Los datos adicionales específicos de los procedimientos almacenados (sys.dm_exec_procedure_stats), las funciones (sys.dm_exec_function_stats) y los disparadores (sys.dm_exec_trigger_stats) también están disponibles, pero considere una carga de trabajo que no sea únicamente procedimientos, funciones y disparadores almacenados. Considere una carga de trabajo mixta que tenga algunas consultas ad hoc, o tal vez sea completamente ad hoc.
Ejemplo de escenario
Tomando prestado y adaptando el código de una publicación anterior, Examinando el impacto en el rendimiento de una carga de trabajo Adhoc, primero crearemos dos procedimientos almacenados. El primero, dbo.RandomSelects, genera y ejecuta una declaración ad hoc, y el segundo, dbo.SPRandomSelects, genera y ejecuta una consulta parametrizada.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT c.CustomerID, c.AccountOpenedDate, COUNT(ct.CustomerTransactionID)
FROM Sales.Customers c
JOIN Sales.CustomerTransactions ct
ON c.CustomerID = ct.CustomerID
WHERE c.CustomerName = @ConcatString
GROUP BY c.CustomerID, c.AccountOpenedDate;
SELECT @RowLoop = @RowLoop + 1;
END
GO Ahora ejecutaremos ambos procedimientos almacenados 1000 veces, usando el mismo método descrito en mi publicación anterior con archivos .cmd llamando a archivos .sql con las siguientes declaraciones:
Contenido del archivo adhoc.sql:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 1000;
Contenido del archivo parametrizado.sql:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 1000;
Ejemplo de sintaxis en el archivo .cmd que llama al archivo .sql:
sqlcmd -S WIN2016\SQL2017 -i"Adhoc.sql" exit
Si usamos una variación de la consulta Tiempo del trabajador principal de Glenn para ver las consultas principales según el tiempo del trabajador (CPU):
-- Get top total worker time queries for entire instance (Query 44) (Top Worker Time Queries) SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.total_worker_time AS [Total Worker Time], qs.execution_count AS [Execution Count], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);
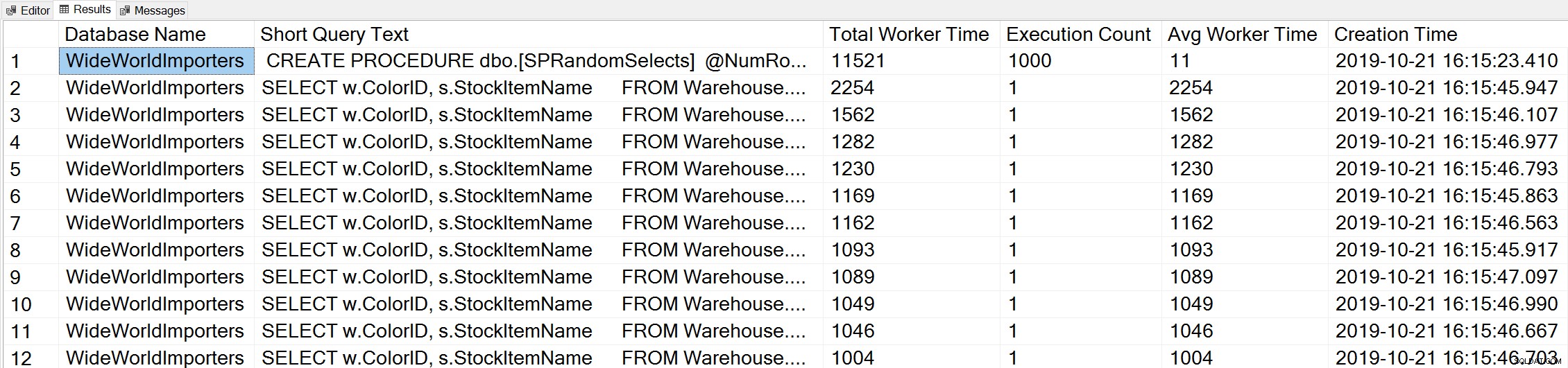
Vemos la declaración de nuestro procedimiento almacenado como la consulta que se ejecuta con la mayor cantidad de CPU acumulada.
Si ejecutamos una variación de la consulta Recuentos de ejecución de consultas de Glenn en la base de datos de WideWorldImporters:
USE [WideWorldImporters]; GO -- Get most frequently executed queries for this database (Query 57) (Query Execution Counts) SELECT TOP(50) LEFT(t.[text], 50) AS [Short Query Text], qs.execution_count AS [Execution Count], qs.total_logical_reads AS [Total Logical Reads], qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads], qs.total_worker_time AS [Total Worker Time], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.total_elapsed_time AS [Total Elapsed Time], qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp WHERE t.dbid = DB_ID() ORDER BY qs.execution_count DESC OPTION (RECOMPILE);
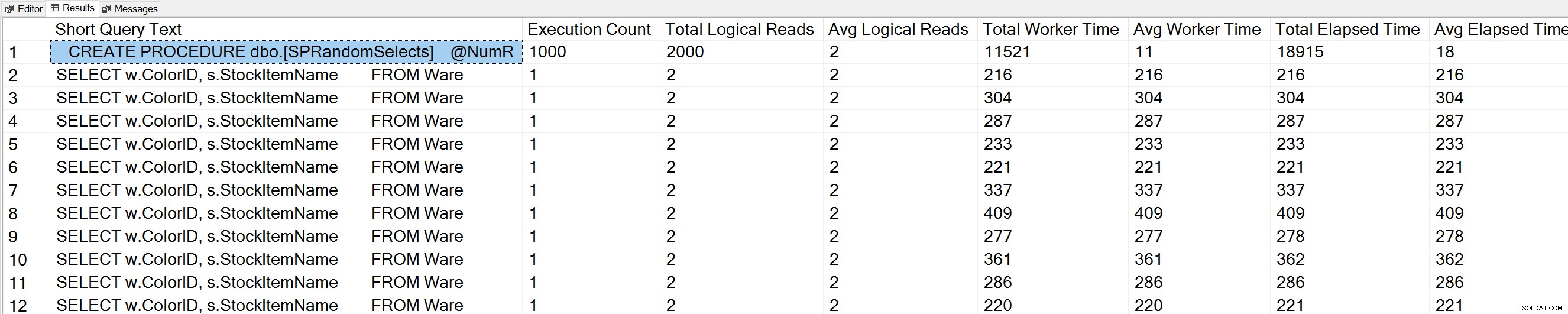
También vemos nuestra instrucción de procedimiento almacenado en la parte superior de la lista.
Pero la consulta ad hoc que ejecutamos, aunque tiene diferentes valores literales, era esencialmente la misma declaración ejecutada repetidamente, como podemos ver al mirar el query_hash:
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.query_hash AS [query_hash], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY [Short Query Text];
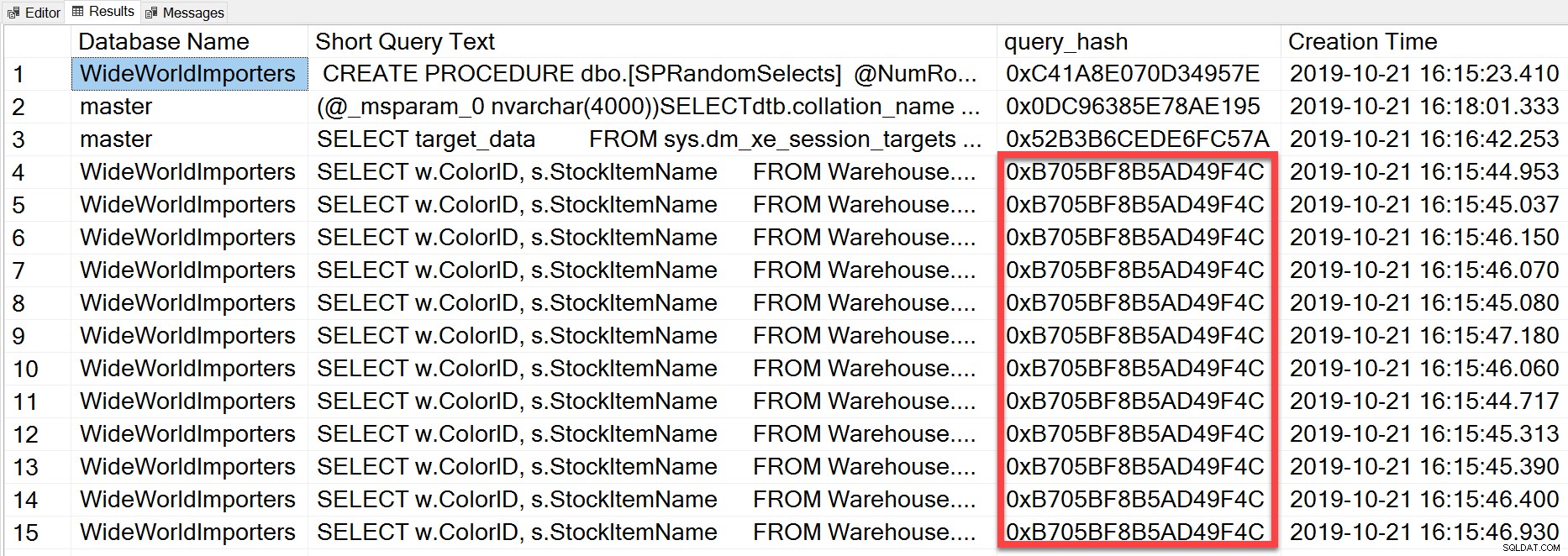
El query_hash se agregó en SQL Server 2008 y se basa en el árbol de los operadores lógicos generados por Query Optimizer para el texto de la declaración. Las consultas que tienen un texto de declaración similar que generan el mismo árbol de operadores lógicos tendrán el mismo query_hash, incluso si los valores literales en el predicado de la consulta son diferentes. Si bien los valores literales pueden ser diferentes, los objetos y sus alias deben ser los mismos, así como las sugerencias de consulta y, potencialmente, las opciones SET. El procedimiento almacenado RandomSelects genera consultas con diferentes valores literales:
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1005451175198';
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1006416358897'; Pero cada ejecución tiene exactamente el mismo valor para query_hash, 0xB705BF8B5AD49F4C. Para comprender con qué frecuencia se ejecuta una consulta ad hoc, y aquellas que son iguales en términos de query_hash, tenemos que agrupar por el orden de query_hash en ese recuento, en lugar de mirar el recuento de ejecución en sys.dm_exec_query_stats (que a menudo muestra un valor de 1).
Si cambiamos el contexto a la base de datos de WideWorldImporters y buscamos las consultas principales según el recuento de ejecuciones, donde agrupamos en query_hash, ahora podemos ver el procedimiento almacenado y nuestra consulta ad hoc:
;WITH qh AS
(
SELECT TOP (25) query_hash, COUNT(*) AS COUNT
FROM sys.dm_exec_query_stats
GROUP BY query_hash
ORDER BY COUNT(*) DESC
),
qs AS
(
SELECT obj = COALESCE(ps.object_id, fs.object_id, ts.object_id),
db = COALESCE(ps.database_id, fs.database_id, ts.database_id),
qs.query_hash, qs.query_plan_hash, qs.execution_count,
qs.sql_handle, qs.plan_handle
FROM sys.dm_exec_query_stats AS qs
INNER JOIN qh ON qs.query_hash = qh.query_hash
LEFT OUTER JOIN sys.dm_exec_procedure_stats AS [ps]
ON [qs].[sql_handle] = [ps].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_function_stats AS [fs]
ON [qs].[sql_handle] = [fs].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_trigger_stats AS [ts]
ON [qs].[sql_handle] = [ts].[sql_handle]
)
SELECT TOP (50)
OBJECT_NAME(qs.obj, qs.db),
query_hash,
query_plan_hash,
SUM([qs].[execution_count]) AS [ExecutionCount],
MAX([st].[text]) AS [QueryText]
FROM qs
CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st]
CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp]
GROUP BY qs.obj, qs.db, qs.query_hash, qs.query_plan_hash
ORDER BY ExecutionCount DESC;

Nota:El DMV sys.dm_exec_function_stats se agregó en SQL Server 2016. Ejecutar esta consulta en SQL Server 2014 y versiones anteriores requiere eliminar la referencia a este DMV.
Esta salida proporciona una comprensión mucho más completa de qué consultas realmente se ejecutan con mayor frecuencia, ya que se agrega en función de query_hash, no simplemente mirando el recuento de ejecución en sys.dm_exec_query_stats, que puede tener varias entradas para el mismo query_hash cuando se utilizan diferentes valores literales. utilizado. La salida de la consulta también incluye query_plan_hash, que puede ser diferente para consultas con el mismo query_hash. Esta información adicional es útil al evaluar el rendimiento del plan para una consulta. En el ejemplo anterior, cada consulta tiene el mismo query_plan_hash, 0x299275DD475C4B17, lo que demuestra que incluso con diferentes valores de entrada, el Optimizador de consultas genera el mismo plan:es estable. Cuando existen varios valores de query_plan_hash para el mismo query_hash, existe la variabilidad del plan. En un escenario donde la misma consulta, basada en query_hash, se ejecuta miles de veces, una recomendación general es parametrizar la consulta. Si puede verificar que no existe ninguna variabilidad del plan, la parametrización de la consulta elimina el tiempo de optimización y compilación para cada ejecución y puede reducir la CPU general. En algunos escenarios, la parametrización de cinco a diez consultas ad hoc puede mejorar el rendimiento del sistema en su conjunto.
Resumen
Para cualquier entorno, es importante comprender qué consultas son más costosas en términos de uso de recursos y qué consultas se ejecutan con mayor frecuencia. El mismo conjunto de consultas puede aparecer para ambos tipos de análisis cuando se usa el script DMV de Glenn, lo que puede ser engañoso. Como tal, es importante establecer si la carga de trabajo es principalmente de procedimiento, en su mayoría ad hoc o una combinación. Si bien hay mucha documentación sobre los beneficios de los procedimientos almacenados, encuentro que las cargas de trabajo mixtas o altamente ad hoc son muy comunes, particularmente con soluciones que usan mapeadores relacionales de objetos (ORM) como Entity Framework, NHibernate y LINQ to SQL. Si no tiene claro el tipo de carga de trabajo para un servidor, ejecutar la consulta anterior para ver las consultas más ejecutadas basadas en query_hash es un buen comienzo. A medida que comience a comprender la carga de trabajo y lo que existe tanto para las consultas más importantes como para la muerte por mil cortes, puede pasar a comprender verdaderamente el uso de recursos y el impacto que estas consultas tienen en el rendimiento del sistema, y orientar sus esfuerzos para el ajuste.