Un problema de rendimiento que veo a menudo es cuando los usuarios necesitan hacer coincidir parte de una cadena con una consulta como la siguiente:
... DONDE AlgunaColumna COMO N'%AlgunaPorción%';
Con un comodín inicial, este predicado es "no SARGable", solo una forma elegante de decir que no podemos encontrar las filas relevantes usando una búsqueda contra un índice en SomeColumn .
Una solución con la que nos ponemos nerviosos es la búsqueda de texto completo; sin embargo, esta es una solución compleja y requiere que el patrón de búsqueda consista en palabras completas, no use palabras vacías, etc. Esto puede ayudar si buscamos filas en las que una descripción contenga la palabra "suave" (u otros derivados como "más suave" o "suavemente"), pero no ayuda cuando buscamos cadenas que podrían estar contenidas dentro de palabras (o que no son palabras en absoluto, como todos los SKU de productos que contienen "X45-B" o todas las matrículas que contienen la secuencia "7RA").
¿Qué pasaría si SQL Server de alguna manera conociera todas las partes posibles de una cadena? Mi proceso de pensamiento está en la línea de trigram / trigraph en PostgresSQL. El concepto básico es que el motor tiene la capacidad de realizar búsquedas de estilo de punto en subcadenas, lo que significa que no tiene que escanear toda la tabla y analizar cada valor completo.
El ejemplo específico que usan allí es la palabra cat . Además de la palabra completa, se puede dividir en porciones:c , ca y at (dejan fuera a y t por definición, ninguna subcadena final puede tener menos de dos caracteres). En SQL Server, no necesitamos que sea tan complejo; realmente solo necesitamos la mitad del trigrama, si pensamos en construir una estructura de datos que contenga todas las subcadenas de cat , solo necesitamos estos valores:
No necesitamos c o ca , porque cualquiera que busque LIKE '%ca%' podría encontrar fácilmente el valor 1 usando LIKE 'ca%' en cambio. Del mismo modo, cualquiera que busque LIKE '%at%' o LIKE '%a%' podría usar un comodín final solo contra estos tres valores y encontrar el que coincida (por ejemplo, LIKE 'at%' encontrará el valor 2 y LIKE 'a%' también encontrará el valor 2, sin tener que buscar esas subcadenas dentro del valor 1, que es de donde vendría el verdadero dolor).
Entonces, dado que SQL Server no tiene nada como esto integrado, ¿cómo generamos ese trigrama?
Una tabla de fragmentos separada
Voy a dejar de hacer referencia a "trigrama" aquí porque esto no es realmente análogo a esa función en PostgreSQL. Esencialmente, lo que vamos a hacer es construir una tabla separada con todos los "fragmentos" de la cadena original. (Así que en el cat ejemplo, habría una nueva tabla con esas tres filas y LIKE '%pattern%' las búsquedas se dirigirían a esa nueva tabla como LIKE 'pattern%' predicados.)
Antes de comenzar a mostrar cómo funcionaría mi solución propuesta, permítanme dejar absolutamente claro que esta solución no debe usarse en todos los casos en los que LIKE '%wildcard%' Las búsquedas son lentas. Debido a la forma en que vamos a "explotar" los datos de origen en fragmentos, es probable que se limite en la práctica a cadenas más pequeñas, como direcciones o nombres, en lugar de cadenas más grandes, como descripciones de productos o resúmenes de sesiones.
Un ejemplo más práctico que cat es mirar el Sales.Customer en la base de datos de muestra de WideWorldImporters. Tiene líneas de dirección (ambas nvarchar(60) ), con la valiosa información de la dirección en la columna DeliveryAddressLine2 (por razones desconocidas). Alguien podría estar buscando a alguien que vive en una calle llamada Hudecova , por lo que realizarán una búsqueda como esta:
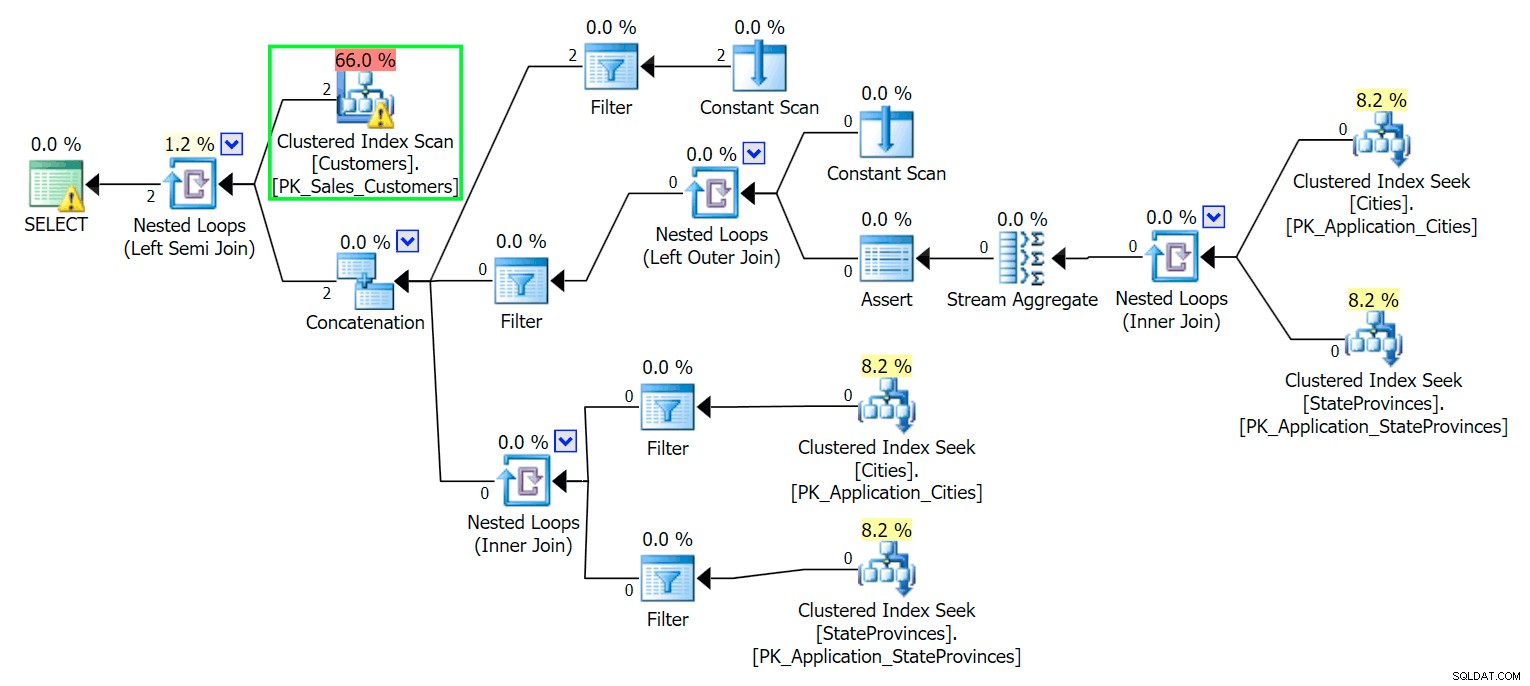
SELECT CustomerID, DeliveryAddressLine2 FROM Sales.Customers WHERE DeliveryAddressLine2 LIKE N'%Hudecova%'; /* Esto devuelve dos filas:CustomerID DeliveryAddressLine2 ---------- ---------------------- 61 1695 Hudecova Avenue 181 1846 Hudecova Crescent* //pre>Como era de esperar, SQL Server necesita realizar un escaneo para ubicar esas dos filas. Que debería ser simple; sin embargo, debido a la complejidad de la tabla, esta consulta trivial produce un plan de ejecución muy desordenado (el escaneo está resaltado y tiene una advertencia de E/S residual):
Blech. Para mantener nuestras vidas simples y asegurarnos de no perseguir un montón de pistas falsas, creemos una nueva tabla con un subconjunto de las columnas y, para comenzar, solo insertaremos esas mismas dos filas desde arriba:
CREATE TABLE Sales.CustomersCopy( CustomerID int IDENTITY(1,1) CONSTRAINT PK_CustomersCopy PRIMARY KEY, CustomerName nvarchar(100) NOT NULL, DeliveryAddressLine1 nvarchar(60) NOT NULL, DeliveryAddressLine2 nvarchar(60));GO INSERT Sales.CustomersCopy ( CustomerName, DeliveryAddressLine1, DeliveryAddressLine2)SELECT CustomerName, DeliveryAddressLine1, DeliveryAddressLine2FROM Sales.CustomersWHERE DeliveryAddressLine2 LIKE N'%Hudecova%';Ahora, si ejecutamos la misma consulta que ejecutamos en la tabla principal, obtenemos algo mucho más razonable como punto de partida. Esto seguirá siendo un escaneo sin importar lo que hagamos, si agregamos un índice con
DeliveryAddressLine2como columna de clave principal, lo más probable es que obtengamos un escaneo de índice, con una búsqueda de clave dependiendo de si el índice cubre las columnas de la consulta. Tal como está, obtenemos un escaneo de índice agrupado:
A continuación, creemos una función que "explotará" estos valores de dirección en fragmentos. Esperaríamos
1846 Hudecova Crescent, por ejemplo, para tener el siguiente conjunto de fragmentos:
- 1846 Creciente Hudecova
- 846 Creciente Hudecova
- 46 Creciente Hudecova
- 6 Media Luna Hudecova
- Creciente Hudecova
- Creciente Hudecova
- Media Luna udecova
- media luna decova
- media luna ecova
- cova Creciente
- media luna de óvulos
- una media luna
- una media luna
- Media Luna
- Media Luna
- reciente
- escente
- aroma
- centavo
- ent
- no
- t
Es bastante trivial escribir una función que produzca esta salida; solo necesitamos un CTE recursivo que se pueda usar para recorrer cada carácter a lo largo de la entrada:
CREAR FUNCIÓN dbo.CreateStringFragments( @input nvarchar(60) )TABLA DE DEVOLUCIONES CON SCHEMABINDINGAS RETURN ( CON x(x) COMO ( SELECCIONE 1 UNIÓN TODO SELECCIONE x+1 DESDE x DONDE x <(LEN(@input)) ) SELECCIONE Fragmento =SUBCADENA(@input, x, LEN(@input)) DE x );IR SELECCIONE Fragmento DE dbo.CreateStringFragments(N'1846 Hudecova Crescent');-- mismo resultado que la lista con viñetas anterior
Ahora, creemos una tabla que almacenará todos los fragmentos de direcciones y a qué Cliente pertenecen:
CREATE TABLE Sales.CustomerAddressFragments( CustomerID int NOT NULL, Fragment nvarchar(60) NOT NULL, CONSTRAINT FK_Customers FOREIGN KEY(CustomerID) REFERENCES Sales.CustomersCopy(CustomerID)); CREAR ÍNDICE CLÚSTER s_cat EN Sales.CustomerAddressFragments(Fragment, CustomerID);
Entonces podemos llenarlo así:
INSERTAR Sales.CustomerAddressFragments(CustomerID, Fragment)SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;
Para nuestros dos valores, esto inserta 42 filas (una dirección tiene 20 caracteres y la otra tiene 22). Ahora nuestra consulta se convierte en:
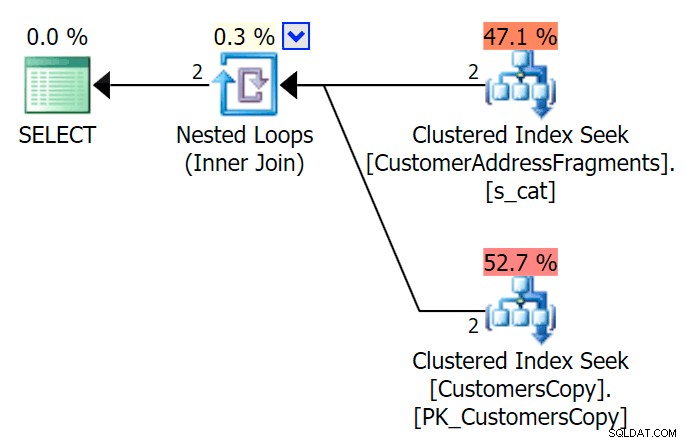
SELECCIONE c.CustomerID, c.DeliveryAddressLine2 FROM Sales.CustomersCopy AS c INNER JOIN Sales.CustomerAddressFragments AS f ON f.CustomerID =c.CustomerID AND f.Fragment LIKE N'Hudecova%';
Aquí hay un plan mucho mejor:dos índices agrupados *búsquedas* y una unión de bucles anidados:
También podemos hacer esto de otra manera, usando EXISTS :
SELECCIONE c.CustomerID, c.DeliveryAddressLine2 FROM Sales.CustomersCopy COMO c DONDE EXISTE ( SELECCIONE 1 DE Sales.CustomerAddressFragments WHERE CustomerID =c.CustomerID AND Fragment LIKE N'Hudecova%' );
Aquí está ese plan, que aparentemente parece ser más costoso:elige escanear la tabla CustomersCopy. Veremos en breve por qué este es el mejor enfoque de consulta:
Ahora, en este conjunto de datos masivo de 42 filas, las diferencias observadas en duración y E/S son tan minúsculas que son irrelevantes (y, de hecho, con este tamaño pequeño, el escaneo contra la tabla base parece más económico en términos de E/S). O que los otros dos planes que usan la tabla de fragmentos):

¿Qué pasaría si llenáramos estas tablas con muchos más datos? Mi copia de Sales.Customers tiene 663 filas, por lo que si lo unimos contra sí mismo, obtendríamos cerca de 440 000 filas. Así que simplemente combinemos 400K y generemos una tabla mucho más grande:
TRUNCATE TABLE Sales.CustomerAddressFragments;DELETE Sales.CustomersCopy;DBCC FREEPROCCACHE SIN_INFOMSGS; INSERTE Sales.CustomersCopy WITH (TABLOCKX) (CustomerName, DeliveryAddressLine1, DeliveryAddressLine2)SELECT TOP (400000) c1.CustomerName, c1.DeliveryAddressLine1, c2.DeliveryAddressLine2 FROM Sales.Customers c1 CROSS JOIN Sales.Customers c2 ORDER BY NEWID(); -- divertido para la distribución -- esto tomará un poco más de tiempo - en mi sistema, ~4 minutos-- probablemente porque no me molesté en expandir previamente los archivosINSERT Sales.CustomerAddressFragments WITH (TABLOCKX) (CustomerID, Fragment)SELECT c. CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f; -- repetido para la versión comprimida de la tabla -- 7,25 millones de filas, 278 MB (79 MB comprimidos; guardando esas pruebas para otro día)
Ahora, para comparar los planes de rendimiento y ejecución dada una variedad de posibles parámetros de búsqueda, probé las tres consultas anteriores con estos predicados:
| Consulta | Predicados | ||||
|---|---|---|---|---|---|
| DONDE DeliveryLineAddress2 COMO... | N'%Hudecova%' | N'%cova%' | N'%ova%' | N'%va%' | |
| ÚNETE... DONDE Fragmento COMO... | N'Hudecova%' | N'cova%' | N'ova%' | N'va%' | |
| DONDE EXISTE (... DONDE Fragmento COMO...) | |||||
A medida que eliminamos letras del patrón de búsqueda, esperaría ver más resultados de filas y tal vez diferentes estrategias elegidas por el optimizador. Veamos cómo fue para cada patrón:
Hudecova%
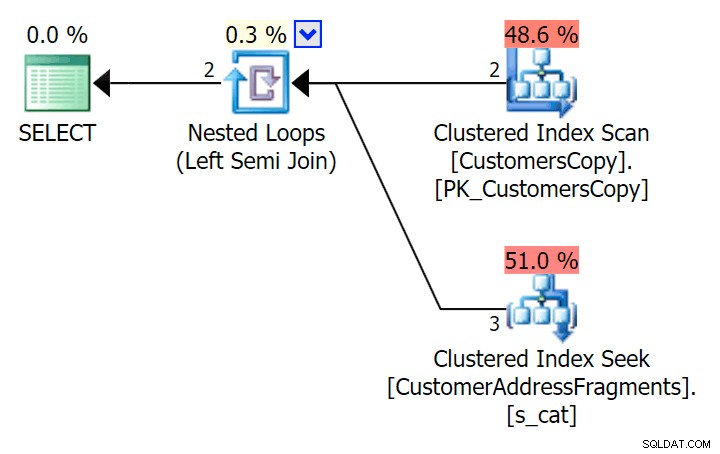
Para este patrón, el escaneo seguía siendo el mismo para la condición LIKE; sin embargo, con más datos, el costo es mucho mayor. Las búsquedas en la tabla de fragmentos realmente dan sus frutos en este recuento de filas (1206), incluso con estimaciones realmente bajas. El plan EXISTS agrega una clasificación distinta, que esperaría agregar al costo, aunque en este caso termina haciendo menos lecturas:

 Plan para JOIN a la tabla de fragmentos
Plan para JOIN a la tabla de fragmentos 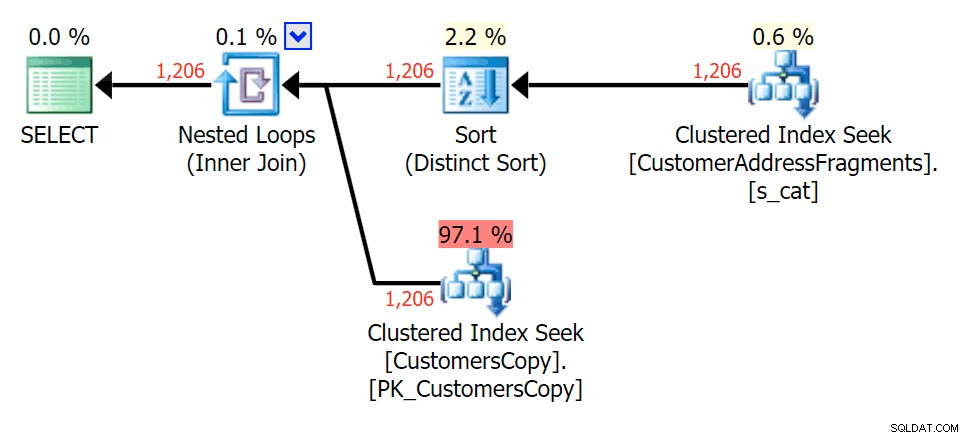 Plan para EXISTS contra la tabla de fragmentos
Plan para EXISTS contra la tabla de fragmentos cova%
A medida que eliminamos algunas letras de nuestro predicado, vemos que las lecturas en realidad son un poco más altas que con el escaneo de índice agrupado original, y ahora sobre -estimar las filas. Aún así, nuestra duración sigue siendo significativamente menor con ambas consultas de fragmentos; la diferencia esta vez es más sutil:ambos tienen tipos (solo EXISTS es distinto):

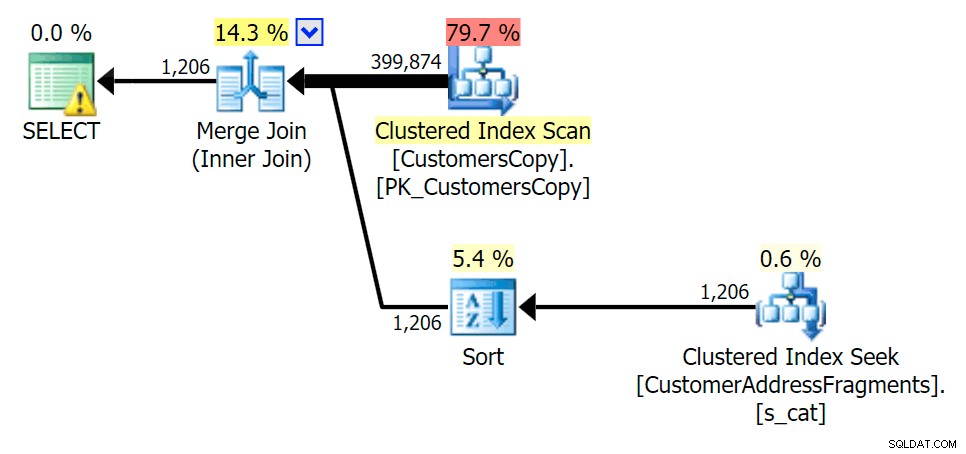 Plan para JOIN a la tabla de fragmentos
Plan para JOIN a la tabla de fragmentos 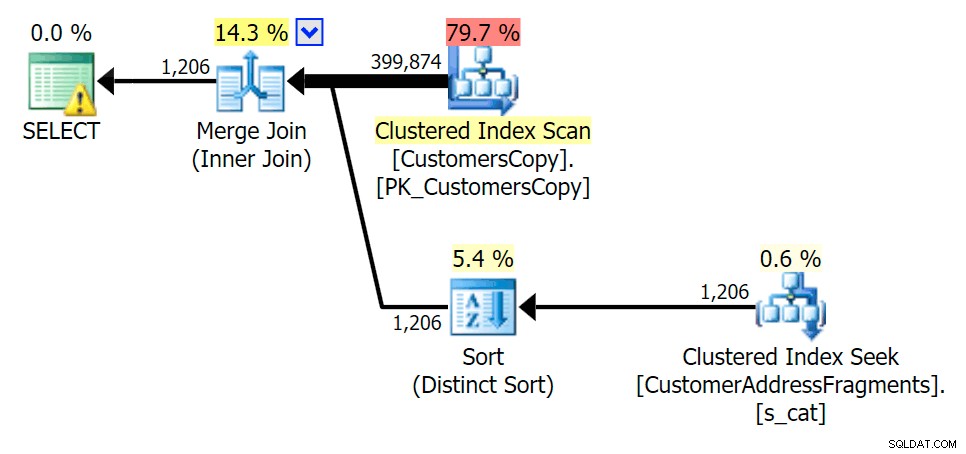 Plan para EXISTS contra la tabla de fragmentos
Plan para EXISTS contra la tabla de fragmentos % de óvulos
Eliminar una letra adicional no cambió mucho; aunque vale la pena señalar cuánto saltan aquí las filas estimadas y reales, lo que significa que esto puede ser un patrón de subcadena común. La consulta LIKE original sigue siendo un poco más lenta que las consultas fragmentadas.

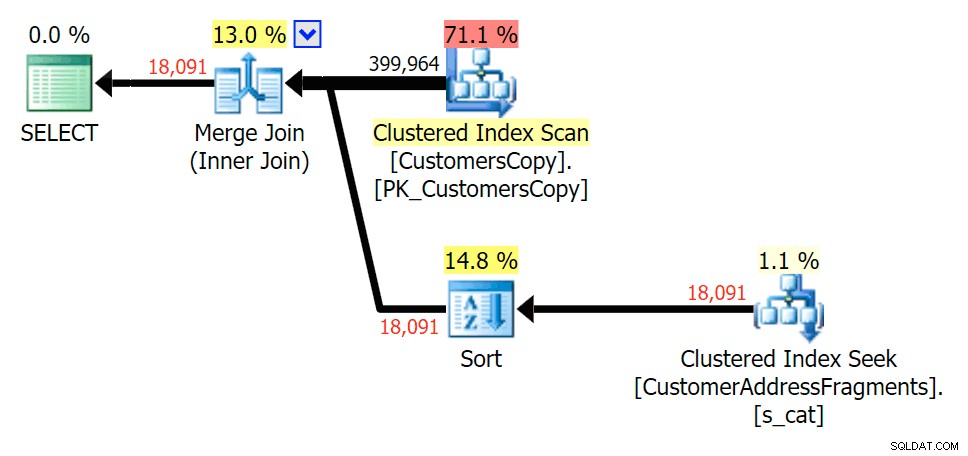 Plan para JOIN a la tabla de fragmentos
Plan para JOIN a la tabla de fragmentos 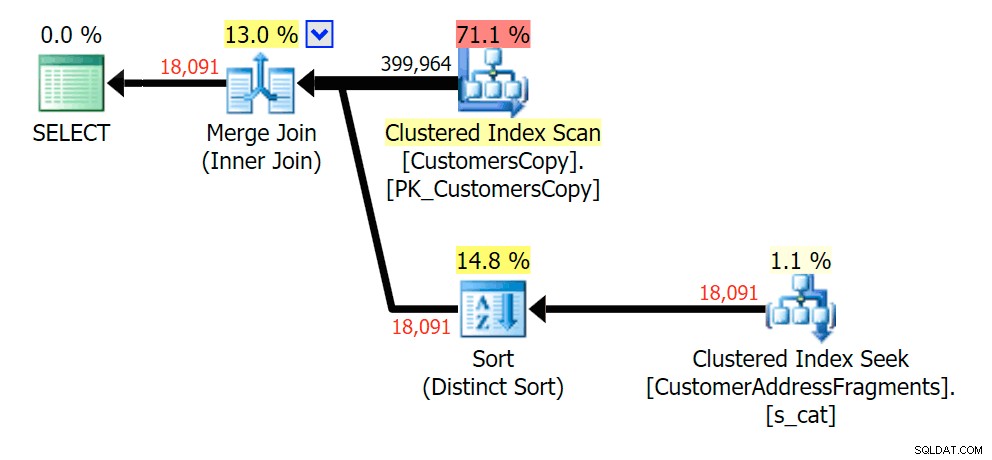 Plan para EXISTS contra la tabla de fragmentos
Plan para EXISTS contra la tabla de fragmentos va%
Hasta dos letras, esto introduce nuestra primera discrepancia. Observe que JOIN produce más filas que la consulta original o EXISTS. ¿Por qué sería eso?

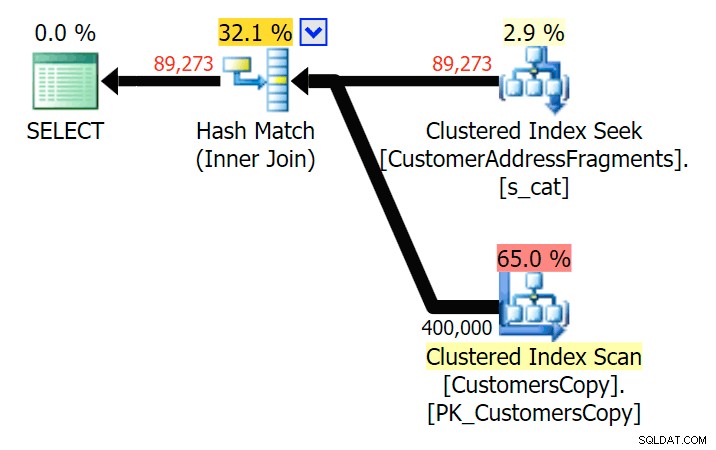 Plan para JOIN a la tabla de fragmentos
Plan para JOIN a la tabla de fragmentos 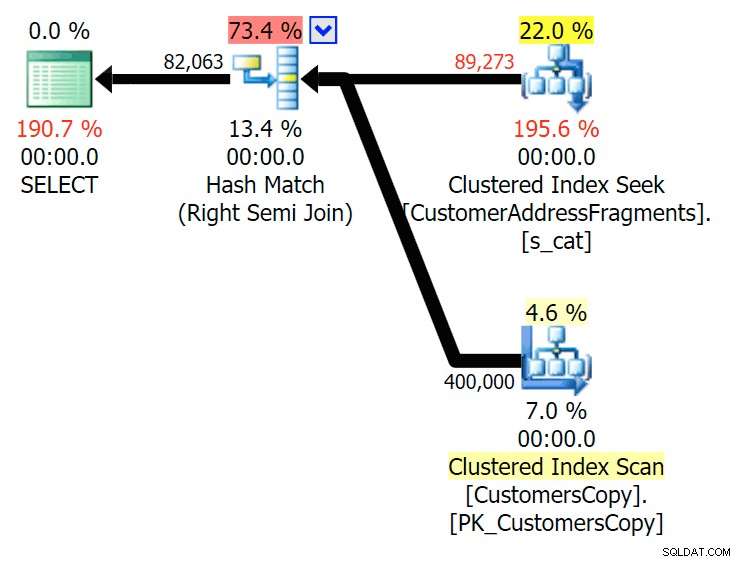 Plan para EXISTS contra la tabla de fragmentos No tenemos que mirar muy lejos. Recuerde que hay un fragmento a partir de cada carácter sucesivo en la dirección original, lo que significa algo así como
Plan para EXISTS contra la tabla de fragmentos No tenemos que mirar muy lejos. Recuerde que hay un fragmento a partir de cada carácter sucesivo en la dirección original, lo que significa algo así como 899 Valentova Road tendrá dos filas en la tabla de fragmentos que comienzan con va (Sensible a mayúsculas y minúsculas a un lado). Entonces coincidirá en ambos Fragment = N'Valentova Road' y Fragment = N'va Road' . Te ahorraré la búsqueda y daré un solo ejemplo de muchos: SELECCIONE ARRIBA (2) c.ID de cliente, c.Línea de dirección de entrega2, f.Fragmento DESDE Sales.CustomersCopy AS cINNER JOIN Sales.CustomerAddressFragments AS fON c.ID de cliente =f.ID de cliente DONDE f.Fragmento LIKE N'va%'Y c.Línea de dirección de entrega2 =N'899 Valentova Road'AND f.CustomerID =351; /*Fragmento de CustomerID DeliveryAddressLine2---------- -------------------- --------------351 899 Valentova Road va Road351 899 Valentova Road Valentova Road*/
Esto explica fácilmente por qué JOIN produce más filas; si desea hacer coincidir el resultado de la consulta LIKE original, debe usar EXISTS. El hecho de que los resultados correctos generalmente también se puedan obtener de una manera menos intensiva en recursos es solo una ventaja. (Estaría nervioso si la gente eligiera JOIN si esa fuera la opción repetidamente más eficiente; siempre debe preferir los resultados correctos a preocuparse por el rendimiento).
Resumen
Está claro que en este caso específico, con una columna de dirección de nvarchar(60) y una longitud máxima de 26 caracteres:dividir cada dirección en fragmentos puede brindar cierto alivio a las búsquedas de "comodines principales", que de otro modo serían costosas. La mejor recompensa parece ocurrir cuando el patrón de búsqueda es más grande y, como resultado, más único. También he demostrado por qué EXISTS es mejor en escenarios donde son posibles múltiples coincidencias:con JOIN, obtendrá una salida redundante a menos que agregue alguna lógica de "mayor n por grupo".
Advertencias
Seré el primero en admitir que esta solución es imperfecta, incompleta y no completamente desarrollada:
- Deberá mantener la tabla de fragmentos sincronizada con la tabla base mediante disparadores; lo más simple sería para inserciones y actualizaciones, eliminar todas las filas de esos clientes y volver a insertarlas, y para las eliminaciones, obviamente, elimine las filas de los fragmentos. mesa.
- Como se mencionó, esta solución funcionó mejor para este tamaño de datos específico y es posible que no funcione tan bien para otras longitudes de cadena. Sería necesario realizar más pruebas para garantizar que sea apropiado para el tamaño de columna, la longitud del valor promedio y la longitud típica del parámetro de búsqueda.
- Dado que tendremos muchas copias de fragmentos como "Crescent" y "Street" (no importa que todos tengan nombres de calles y números de casas iguales o similares), podría normalizarlo aún más almacenando cada fragmento único en una tabla de fragmentos, y luego otra tabla que actúa como una tabla de unión de muchos a muchos. Eso sería mucho más engorroso de configurar, y no estoy muy seguro de que haya mucho que ganar.
- Todavía no investigué completamente la compresión de páginas, parece que, al menos en teoría, esto podría proporcionar algún beneficio. También tengo la sensación de que la implementación de un almacén de columnas también puede ser beneficiosa en algunos casos.
De todos modos, dicho todo esto, solo quería compartirlo como una idea en desarrollo y solicitar comentarios sobre su practicidad para casos de uso específicos. Puedo profundizar en más detalles para una publicación futura si me dices qué aspectos de esta solución te interesan.