Gran parte del código T-SQL de producción se escribe con la suposición implícita de que los datos subyacentes no cambiarán durante la ejecución. Como vimos en el artículo anterior de esta serie, esta es una suposición insegura porque los datos y las entradas de índice pueden moverse debajo de nosotros, incluso durante la ejecución de una sola instrucción.
Cuando el programador de T-SQL es consciente de los tipos de problemas de corrección e integridad de datos que pueden surgir debido a modificaciones simultáneas de datos por parte de otros procesos, la solución que se ofrece con más frecuencia es envolver las declaraciones vulnerables en una transacción. No está claro cómo se aplicaría el mismo tipo de razonamiento al caso de declaración única, que ya está envuelto en una transacción de confirmación automática de forma predeterminada.
Dejando eso de lado por un segundo, la idea de proteger un área importante del código T-SQL con una transacción parece estar basada en un malentendido de las protecciones que ofrecen las propiedades de transacción ACID. El elemento importante de ese acrónimo para la presente discusión es el Aislamiento propiedad. La idea es que el uso de una transacción proporciona automáticamente un aislamiento completo de los efectos de otras actividades simultáneas.
La verdad del asunto es que las transacciones por debajo de SERIALIZABLE solo proporcionar un título de aislamiento, que depende del nivel de aislamiento de transacciones efectivo actualmente. Para entender lo que todo esto significa para nuestro día a día T Prácticas de codificación SQL, primero veremos en detalle el nivel de aislamiento serializable.
Aislamiento serializable
Serializable es el más aislado de los niveles de aislamiento de transacciones estándar. También es el predeterminado nivel de aislamiento especificado por el estándar SQL, aunque SQL Server (como la mayoría de los sistemas de bases de datos comerciales) difiere del estándar en este aspecto. El nivel de aislamiento predeterminado en SQL Server es lectura confirmada, un nivel de aislamiento más bajo que exploraremos más adelante en la serie.
La definición del nivel de aislamiento serializable en el estándar SQL-92 contiene el siguiente texto (énfasis mío):
Una ejecución serializable se define como una ejecución de operaciones de ejecución simultánea de transacciones SQL que produce el mismo efecto que alguna ejecución en serie de esas mismas transacciones SQL. Una ejecución en serie es aquella en la que cada transacción SQL se ejecuta hasta su finalización antes de que comience la siguiente transacción SQL.
Hay que hacer una distinción importante aquí entre verdaderamente serializado ejecución (donde cada transacción en realidad se ejecuta exclusivamente hasta su finalización antes de que comience la siguiente) y serializable aislamiento, donde solo se requiere que las transacciones tengan los mismos efectos como si se ejecutaron en serie (en un orden no especificado).
Para decirlo de otra manera, un sistema de base de datos real puede superponerse físicamente la ejecución de transacciones serializables en el tiempo (aumentando así la concurrencia) siempre que los efectos de esas transacciones aún correspondan a algún posible orden de ejecución en serie. En otras palabras, las transacciones serializables son potencialmente serializables. en lugar de ser realmente serializado .
Transacciones lógicamente serializables
Deje de lado todas las consideraciones físicas (como el bloqueo) por un momento y piense solo en el procesamiento lógico de dos transacciones serializables simultáneas.
Considere una tabla que contiene una gran cantidad de filas, cinco de las cuales satisfacen algún predicado de consulta interesante. Una transacción serializable T1 comienza a contar el número de filas en la tabla que coinciden con este predicado. Algún tiempo después de T1 comienza, pero antes de que se confirme, una segunda transacción serializable T2 empieza. Transacción T2 agrega cuatro nuevas filas que también satisfacen el predicado de la consulta a la tabla y confirma. El siguiente diagrama muestra la secuencia temporal de los eventos:

La pregunta es, cuántas filas debe tener la consulta en la transacción serializable T1 contar? Recuerde que estamos pensando únicamente en los requisitos lógicos aquí, así que evite pensar en qué bloqueos se pueden tomar, etc.
Las dos transacciones se superponen físicamente en el tiempo, lo cual está bien. El aislamiento serializable solo requiere que los resultados de estas dos transacciones correspondan a alguna posible ejecución en serie. Claramente, hay dos posibilidades para un calendario serial lógico de transacciones T1 y T2 :
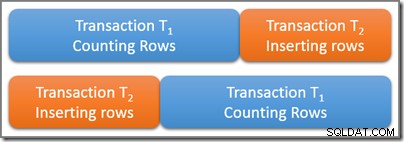
Usando el primer horario serial posible (T1 entonces T2 ) el T1 la consulta de conteo vería cinco filas , porque la segunda transacción no comienza hasta que se completa la primera. Usando el segundo horario lógico posible, el T1 la consulta contaría nueve filas , porque la inserción de cuatro filas se completó lógicamente antes de que comenzara la transacción de conteo.
Ambas respuestas son lógicamente correctas bajo aislamiento serializable. Además, no es posible otra respuesta (así que la transacción T1 no podía contar siete filas, por ejemplo). Cuál de los dos resultados posibles se observa realmente depende de la sincronización precisa y una serie de detalles de implementación específicos del motor de base de datos en uso.
Tenga en cuenta que no estamos concluyendo que las transacciones se reordenen de alguna manera en el tiempo. La ejecución física es libre de superponerse como se muestra en el primer diagrama, siempre que el motor de la base de datos garantice que los resultados reflejen lo que habría sucedido si se hubieran ejecutado en una de las dos secuencias seriales posibles.
Serializable y los fenómenos de concurrencia
Además de la serialización lógica, el estándar SQL también menciona que una transacción que opera en el nivel de aislamiento serializable no debe experimentar ciertos fenómenos de concurrencia. No debe leer datos no confirmados (sin lecturas sucias ); y una vez que se han leído los datos, una repetición de la misma operación debe devolver exactamente el mismo conjunto de datos (lecturas repetibles sin fantasmas ).
El estándar destaca que esos fenómenos de concurrencia se excluyen en el nivel de aislamiento serializable como una consecuencia directa. de exigir que la transacción sea lógicamente serializable. En otras palabras, el requisito de serialización es suficiente por sí mismo para evitar los fenómenos de lectura sucia, lectura no repetible y simultaneidad fantasma. Por el contrario, evitar los tres fenómenos de concurrencia por sí solo no es suficiente para garantizar la serialización, como veremos en breve.
Intuitivamente, las transacciones serializables evitan todos los fenómenos relacionados con la concurrencia porque deben actuar como si se hubieran ejecutado en completo aislamiento. En ese sentido, el nivel de aislamiento de transacciones serializables coincide bastante con las expectativas comunes de los programadores de T-SQL.
Implementaciones serializables
SQL Server utiliza una implementación de bloqueo del nivel de aislamiento serializable, donde los bloqueos físicos se adquieren y retienen hasta el final de la transacción (de ahí la sugerencia de tabla en desuso HOLDLOCK como sinónimo de SERIALIZABLE ).
Esta estrategia no es suficiente para proporcionar una garantía técnica de serialización completa, porque los datos nuevos o modificados podrían aparecer en un rango de filas previamente procesadas por la transacción. Este fenómeno de concurrencia se conoce como fantasma y puede tener efectos que no podrían haber ocurrido en ningún programa de serie.
Para garantizar la protección contra el fenómeno de la concurrencia fantasma, los bloqueos realizados por SQL Server en el nivel de aislamiento serializable también pueden incorporar bloqueo de rango de claves para evitar que aparezcan filas nuevas o modificadas entre valores de clave de índice examinados anteriormente. Los bloqueos de rango no son siempre adquirido bajo el nivel de aislamiento serializable; todo lo que podemos decir en general es que SQL Server siempre adquiere suficientes bloqueos para cumplir con los requisitos lógicos del nivel de aislamiento serializable. De hecho, las implementaciones de bloqueo a menudo adquieren más bloqueos y más estrictos de los que realmente se necesitan para garantizar la serialización, pero estoy divagando.
El bloqueo es solo una de las posibles implementaciones físicas del nivel de aislamiento serializable. Debemos tener cuidado de separar mentalmente los comportamientos específicos de la implementación de bloqueo de SQL Server de la definición lógica de serializable.
Como ejemplo de una estrategia física alternativa, consulte la implementación de PostgreSQL del aislamiento de instantáneas serializables, aunque esta es solo una alternativa. Por supuesto, cada implementación física diferente tiene sus propias fortalezas y debilidades. Aparte, tenga en cuenta que Oracle todavía no proporciona una implementación totalmente compatible con el nivel de aislamiento serializable. Tiene un nivel de aislamiento denominado serializable, pero realmente no garantiza que las transacciones se ejecutarán de acuerdo con algún programa serial posible. En su lugar, Oracle proporciona aislamiento de instantáneas cuando se solicita serializable, de la misma manera que lo hizo PostgreSQL antes del aislamiento de instantánea serializable (SSI ) fue implementado.
El aislamiento de instantáneas no evita anomalías de simultaneidad como el sesgo de escritura, lo que no es posible con un aislamiento realmente serializable. Si está interesado, puede encontrar ejemplos de sesgo de escritura y otros efectos de concurrencia permitidos por el aislamiento de instantáneas en el enlace SSI anterior. También discutiremos la implementación de SQL Server del nivel de aislamiento de instantáneas más adelante en la serie.
¿Una vista puntual?
Una de las razones por las que he dedicado tiempo a hablar sobre las diferencias entre la capacidad de serialización lógica y la ejecución serializada físicamente es que, de lo contrario, es fácil inferir garantías que en realidad podrían no existir. Por ejemplo, si piensa en transacciones serializables como realmente ejecutando uno tras otro, puede inferir que una transacción serializable necesariamente verá la base de datos tal como existía al comienzo de la transacción, proporcionando una vista puntual.
De hecho, este es un detalle específico de la implementación. Recuerde el ejemplo anterior, donde la transacción serializable T1 podría contar legítimamente cinco o nueve filas. Si se devuelve un recuento de nueve, la primera transacción ve claramente las filas que no existían en el momento en que comenzó la transacción. Este resultado es posible en SQL Server pero no en PostgreSQL SSI, aunque ambas implementaciones cumplen con los comportamientos lógicos especificados para el nivel de aislamiento serializable.
En SQL Server, las transacciones serializables no necesariamente ven los datos tal como existían al comienzo de la transacción. Más bien, los detalles de la implementación de SQL Server significan que una transacción serializable ve los datos confirmados más recientes, desde el momento en que los datos se bloquearon por primera vez para el acceso. Además, se garantiza que el conjunto de datos confirmados más recientemente que se lea en última instancia no cambiará su membresía antes de que finalice la transacción.
La próxima vez
La siguiente parte de esta serie examina el nivel de aislamiento de lectura repetible, que ofrece garantías de aislamiento de transacciones más débiles que las serializables.
[ Ver el índice de toda la serie ]