El serializable el nivel de aislamiento proporciona protección completa de los efectos de concurrencia que pueden amenazar la integridad de los datos y dar lugar a resultados de consulta incorrectos. El uso de aislamiento serializable significa que si se puede demostrar que una transacción produce resultados correctos sin actividad simultánea, seguirá funcionando correctamente cuando compita con cualquier combinación de transacciones simultáneas.
Esta es una garantía muy poderosa , y uno que probablemente coincida con las expectativas intuitivas de aislamiento de transacciones de muchos programadores de T-SQL (aunque, en realidad, relativamente pocos de ellos usarán rutinariamente el aislamiento serializable en producción).
El estándar SQL define tres niveles de aislamiento adicionales que ofrecen un ACID mucho más débil garantías de aislamiento que serializables, a cambio de una simultaneidad potencialmente mayor y menos efectos secundarios potenciales como bloqueo, interbloqueo y abortos en tiempo de compromiso.
A diferencia del aislamiento serializable, los otros niveles de aislamiento se definen únicamente en términos de ciertos fenómenos de concurrencia que pueden observarse. El siguiente más fuerte de los niveles de aislamiento estándar después de serializable se denomina lectura repetible . El estándar SQL especifica que las transacciones en este nivel permiten un único fenómeno de concurrencia conocido como fantasma. .
Así como hemos visto diferencias importantes entre el significado intuitivo común de las propiedades de transacción de ACID y la realidad, el fenómeno fantasma abarca una gama más amplia de comportamientos de lo que suele apreciarse.
Esta publicación de la serie analiza las garantías reales proporcionadas por la lectura repetible nivel de aislamiento y muestra algunos de los comportamientos relacionados con fantasmas que se pueden encontrar. Para ilustrar algunos puntos, nos referiremos a la siguiente consulta de ejemplo simple, donde la tarea simple es contar el número total de filas en una tabla:
SELECT COUNT_BIG(*) FROM dbo.SomeTable;
Lectura repetible
Una cosa extraña sobre el nivel de aislamiento de lectura repetible es que no en realidad garantiza que las lecturas son repetibles , al menos en un sentido comúnmente entendido. Este es otro ejemplo en el que el significado intuitivo por sí solo puede ser engañoso. Ejecutar la misma consulta dos veces dentro de la misma transacción de lectura repetible puede arrojar resultados diferentes.
Además de eso, la implementación de SQL Server de lectura repetible significa que una sola lectura de un conjunto de datos podría perder algunas filas que lógicamente debería ser considerado en el resultado de la consulta. Si bien es innegable que es específico de la implementación, este comportamiento está completamente en línea con la definición de lectura repetible contenida en el estándar SQL.
Lo último que quiero señalar rápidamente antes de profundizar en los detalles es que la lectura repetible en SQL Server no proporcionar una vista puntual de los datos.
Lecturas no repetibles
El nivel de aislamiento de lectura repetible proporciona una garantía de que los datos no cambiarán durante la vigencia de la transacción una vez que haya sido leída por primera vez.
Hay un par de sutilezas contenidas en esa definición. Primero, permite que los datos cambien después la transacción comienza pero antes de que los datos sean primeros accedido En segundo lugar, no hay garantía de que la transacción realmente encuentre todos los datos que califican lógicamente. Veremos ejemplos de ambos en breve.
Hay otro preliminar que debemos eliminar rápidamente, que tiene que ver con la consulta de ejemplo que usaremos. Para ser justos, la semántica de esta consulta es un poco confusa. A riesgo de sonar un poco filosófico, ¿qué significa para contar el número de filas en la tabla? ¿Debería el resultado reflejar el estado de la tabla tal como estaba en algún momento particular? ¿Este punto en el tiempo debería ser el comienzo o el final de la transacción, o algo más?
Esto puede parecer un poco quisquilloso, pero la pregunta es válida en cualquier base de datos que admita lecturas y modificaciones de datos simultáneas. La ejecución de nuestra consulta de ejemplo podría llevar un período de tiempo arbitrariamente largo (dada una tabla lo suficientemente grande o limitaciones de recursos, por ejemplo), por lo que los cambios simultáneos no solo son posibles, sino que pueden ser inevitables .
El problema fundamental aquí es el potencial del fenómeno de concurrencia denominado fantasma en el estándar SQL. Mientras contamos filas en la tabla, otra transacción simultánea podría insertar nuevas filas en un lugar que ya hemos marcado, o cambiar una fila que aún no hemos revisado de tal manera que se mueve a un lugar que ya hemos mirado. La gente a menudo piensa en los fantasmas como filas que pueden aparecer mágicamente cuando se leen por segunda vez, en una declaración separada, pero los efectos pueden ser mucho más sutiles que eso.
Ejemplo de inserción simultánea
Este primer ejemplo muestra cómo las inserciones simultáneas pueden producir un no repetible leer y/o hacer que se omitan filas. Imagine que nuestra tabla de prueba contiene inicialmente cinco filas con los valores que se muestran a continuación:

Ahora establecemos el nivel de aislamiento en lectura repetible, comenzamos una transacción y ejecutamos nuestra consulta de conteo. Como era de esperar, el resultado es cinco . Ningún gran misterio hasta ahora.
Sigue ejecutándose dentro de la misma transacción de lectura repetible , ejecutamos la consulta de conteo nuevamente, pero esta vez mientras una segunda transacción simultánea está insertando nuevas filas en la misma tabla. El siguiente diagrama muestra la secuencia de eventos, con la segunda transacción agregando filas con los valores 2 y 6 (es posible que haya notado que estos valores brillaban por su ausencia justo arriba):
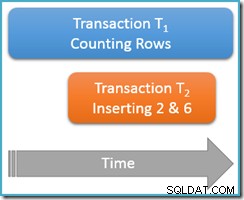
Si nuestra consulta de conteo se estuviera ejecutando en el serializable nivel de aislamiento, se garantizaría contar cinco o siete filas (consulte el artículo anterior de esta serie si necesita un repaso sobre por qué ese es el caso). ¿Cómo funciona correr en los menos aislados ¿El nivel de lectura repetible afecta las cosas?
Bueno, lectura repetible El aislamiento garantiza que la segunda ejecución de la consulta de conteo verá todas las filas leídas anteriormente y estarán en el mismo estado que antes. El problema es que el aislamiento de lectura repetible dice nada sobre cómo la transacción debe tratar las nuevas filas (los fantasmas).
Imagine que nuestra transacción de conteo de filas (T1 ) tiene una estrategia de ejecución física donde las filas se buscan en un orden de índice ascendente. Este es un caso común, por ejemplo, cuando el motor de ejecución emplea un escaneo de índice de árbol b ordenado hacia adelante. Ahora, justo después de la transacción T1 cuenta las filas 1 y 3 en orden ascendente, transacción T2 podría colarse, insertar nuevas filas 2 y 6, y luego confirmar su transacción.
Aunque estamos pensando principalmente en comportamientos lógicos en este punto, debo mencionar que no hay nada en la implementación de bloqueo de lectura repetible de SQL Server para prevenir transacción T2 de hacer esto. Bloqueos compartidos tomados por la transacción T1 en las filas leídas anteriormente impiden que esas filas se cambien, pero no impiden nuevas filas de ser insertado en el rango de valores probado por nuestra consulta de conteo (a diferencia de lo que sucedería con los bloqueos de rango de clave en el bloqueo del aislamiento serializable).
De todos modos, con las dos nuevas filas confirmadas, la transacción T1 continúa su búsqueda en orden ascendente y finalmente encuentra las filas 4, 5, 6 y 7. Tenga en cuenta que T1 ve la nueva fila 6 en este escenario, pero no nueva fila 2 (debido a la búsqueda ordenada y su posición cuando ocurrió la inserción).
El resultado es que la lectura repetible contar informes de consulta de que la tabla contiene seis filas (valores 1, 3, 4, 5, 6 y 7). Este resultado es inconsistente con el resultado anterior de cinco filas obtenido dentro de la misma transacción . La segunda lectura contó la fila fantasma 6 pero se perdió la fila fantasma 2. ¡Hasta aquí el significado intuitivo de una lectura repetible!
Ejemplo de actualización simultánea
Puede surgir una situación similar con una actualización simultánea en lugar de un inserto. Imagine que nuestra tabla de prueba se restablece para contener las mismas cinco filas que antes:

Esta vez, solo ejecutaremos nuestra consulta de conteo una vez en la lectura repetible nivel de aislamiento, mientras que una segunda transacción simultánea actualiza la fila con el valor 5 para tener un valor de 2:
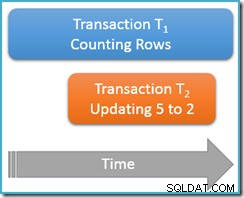
Transacción T1 nuevamente comienza a contar las filas (en orden ascendente) y encuentra primero las filas 1 y 3. Ahora, la transacción T2 se desliza, cambia el valor de la fila 5 a 2 y confirma:

He mostrado la fila actualizada en la misma posición que antes para aclarar el cambio, pero el índice de árbol b que estamos escaneando mantiene los datos en orden lógico, por lo que la imagen real se acerca más a esto:

El punto es que la transacción T1 está escaneando simultáneamente esta misma estructura en orden hacia adelante, estando actualmente posicionado justo después la entrada para el valor 3. La consulta de conteo continúa escaneando hacia adelante desde ese punto, encontrando las filas 4 y 7 (pero no la fila 5, por supuesto).
Para resumir, la consulta de conteo vio las filas 1, 3, 4 y 7 en este escenario. Informa un recuento de cuatro filas – lo cual es extraño, porque la tabla parece haber contenido cinco filas en todo!
Una segunda ejecución de la consulta de conteo dentro de la misma transacción de lectura repetible reportaría cinco filas, por razones similares a las anteriores. Como nota final, en caso de que se lo pregunte, las eliminaciones simultáneas no brindan la oportunidad de una anomalía basada en fantasmas bajo el aislamiento de lectura repetible.
Reflexiones finales
Los ejemplos anteriores utilizaron exploraciones en orden ascendente de una estructura de índice para presentar una vista simple del tipo de efectos que los fantasmas pueden tener en una lectura repetible consulta. Es importante comprender que estas ilustraciones no se basan de manera importante en la dirección de escaneo o en el hecho de que se utilizó un índice de árbol b. Por favor no formar la opinión de que los escaneos ordenados son de alguna manera responsables y, por lo tanto, deben evitarse.
Los mismos efectos de simultaneidad se pueden ver con un escaneo en orden descendente de una estructura de índice, o en una variedad de otros escenarios de acceso a datos físicos. El punto general es que los fenómenos fantasma están específicamente permitidos (aunque no requeridos) por el estándar SQL para transacciones en el nivel de aislamiento de lectura repetible.
No todas las transacciones requieren la garantía de aislamiento total proporcionada por el aislamiento serializable, y no muchos sistemas podrían tolerar los efectos secundarios si lo hicieran. Sin embargo, vale la pena tener una buena comprensión de exactamente qué garantías proporcionan los distintos niveles de aislamiento.
La próxima vez
La siguiente parte de esta serie analiza las garantías de aislamiento aún más débiles que ofrece el nivel de aislamiento predeterminado de SQL Server, lectura confirmada .
[ Ver el índice de toda la serie ]