El tipo y la cantidad de bloqueos adquiridos y liberados durante la ejecución de la consulta pueden tener un efecto sorprendente en el rendimiento (cuando se usa un nivel de aislamiento de bloqueo como la confirmación de lectura predeterminada) incluso cuando no se producen esperas ni bloqueos. No hay información en los planes de ejecución que indique la cantidad de actividad de bloqueo durante la ejecución, lo que hace que sea más difícil detectar cuándo un bloqueo excesivo está causando un problema de rendimiento.
Para explorar algunos comportamientos de bloqueo menos conocidos en SQL Server, reutilizaré las consultas y los datos de muestra de mi última publicación sobre el cálculo de medianas. En esa publicación, mencioné que el OFFSET la solución mediana agrupada necesitaba un PAGLOCK explícito sugerencia de bloqueo para evitar perder mucho con el cursor anidado solución, así que comencemos echando un vistazo a los motivos en detalle.
La solución de la mediana agrupada de OFFSET
La prueba de la mediana agrupada reutilizó los datos de muestra del artículo anterior de Aaron Bertrand. La siguiente secuencia de comandos recrea esta configuración de un millón de filas, que consta de diez mil registros para cada uno de los cien vendedores imaginarios:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
SQL Server 2012 (y versiones posteriores) OFFSET La solución creada por Peter Larsson es la siguiente (sin sugerencias de bloqueo):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
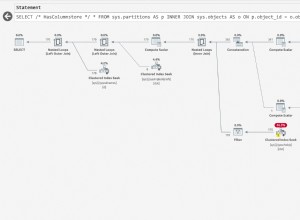
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Las partes importantes del plan posterior a la ejecución se muestran a continuación:

Con todos los datos requeridos en la memoria, esta consulta se ejecuta en 580 ms en promedio en mi computadora portátil (ejecutando SQL Server 2014 Service Pack 1). El rendimiento de esta consulta se puede mejorar a 320 ms simplemente agregando una sugerencia de bloqueo de granularidad de página a la tabla Ventas en la subconsulta de aplicación:
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK) -- NEW!
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
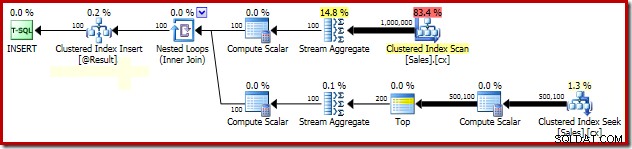
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); El plan de ejecución no ha cambiado (bueno, además del texto de sugerencia de bloqueo en el XML del plan de presentación, por supuesto):
Análisis de bloqueo de la mediana agrupada
La explicación de la espectacular mejora en el rendimiento debido al PAGLOCK La pista es bastante simple, al menos inicialmente.
Si supervisamos manualmente la actividad de bloqueo mientras se ejecuta esta consulta, vemos que sin la sugerencia de granularidad de bloqueo de página, SQL Server adquiere y libera más de medio millón de bloqueos de nivel de fila mientras busca el índice agrupado. No hay bloqueo a quien culpar; simplemente adquirir y liberar tantos bloqueos agrega una sobrecarga sustancial a la ejecución de esta consulta. La solicitud de bloqueos a nivel de página reduce en gran medida la actividad de bloqueo, lo que mejora mucho el rendimiento.
El problema de rendimiento de bloqueo de este plan en particular se limita a la búsqueda de índice agrupado en el plan anterior. El escaneo completo del índice agrupado (usado para calcular el número de filas presentes para cada vendedor) usa bloqueos de nivel de página automáticamente. Este es un punto interesante. El comportamiento de bloqueo detallado del motor de SQL Server no está documentado en gran medida en los Libros en línea, pero varios miembros del equipo de SQL Server han hecho algunos comentarios generales a lo largo de los años, incluido el hecho de que los análisis sin restricciones tienden a comenzar tomando la página. bloqueos, mientras que las operaciones más pequeñas tienden a comenzar con bloqueos de fila.
El optimizador de consultas pone cierta información a disposición del motor de almacenamiento, incluidas las estimaciones de cardinalidad, las sugerencias internas para el nivel de aislamiento y la granularidad de bloqueo, qué optimizaciones internas se pueden aplicar de forma segura, etc. Nuevamente, estos detalles no están documentados en los Libros en línea. Al final, el motor de almacenamiento utiliza una variedad de información para decidir qué bloqueos se requieren en tiempo de ejecución y con qué granularidad deben tomarse.
Como nota al margen, y recordando que estamos hablando de una consulta que se ejecuta bajo el nivel de aislamiento de transacción confirmada de lectura de bloqueo predeterminado, tenga en cuenta que los bloqueos de fila tomados sin la sugerencia de granularidad no escalarán a un bloqueo de tabla en este caso. Esto se debe a que el comportamiento normal en la lectura confirmada es liberar el bloqueo anterior justo antes de adquirir el siguiente bloqueo, lo que significa que solo se mantendrá un bloqueo de fila compartida (con sus bloqueos compartidos de intención de nivel superior asociados) en un momento determinado. Dado que el número de bloqueos de fila mantenidos simultáneamente nunca alcanza el umbral, no se intenta escalar el bloqueo.
La solución de mediana única OFFSET
La prueba de rendimiento para el cálculo de una única mediana utiliza un conjunto diferente de datos de muestra, nuevamente reproducidos del artículo anterior de Aaron. El siguiente script crea una tabla con diez millones de filas de datos pseudoaleatorios:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
El OFFSET la solución es:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); El plan posterior a la ejecución es:

Esta consulta se ejecuta en 910 ms en promedio en mi máquina de prueba. El rendimiento no cambia si un PAGLOCK se agrega una pista, pero la razón de eso no es lo que podrías estar pensando...
Análisis de bloqueo de mediana única
Es posible que espere que el motor de almacenamiento elija bloqueos compartidos a nivel de página de todos modos, debido a la exploración del índice agrupado, lo que explica por qué un PAGLOCK la sugerencia no tiene efecto. De hecho, monitorear los bloqueos tomados mientras se ejecuta esta consulta revela que no se toman bloqueos compartidos (S) en absoluto, en cualquier granularidad . Los únicos bloqueos tomados son de intención compartida (IS) a nivel de objeto y página.
La explicación de este comportamiento viene en dos partes. Lo primero que debe notar es que el escaneo de índice agrupado está debajo de un operador superior en el plan de ejecución. Esto tiene un efecto importante en las estimaciones de cardinalidad, como se muestra en el plan previo a la ejecución (estimado):

El OFFSET y FETCH Las cláusulas de la consulta hacen referencia a una expresión y una variable, por lo que el optimizador de consultas adivina el número de filas que se necesitarán en tiempo de ejecución. La conjetura estándar para Top es de cien filas. Esta es una conjetura terrible, por supuesto, pero es suficiente para convencer al motor de almacenamiento de que se bloquee en la granularidad de fila en lugar de en el nivel de página.
Si deshabilitamos el efecto de "objetivo de fila" del operador Superior mediante el indicador de seguimiento documentado 4138, la cantidad estimada de filas en el escaneo cambia a diez millones (que sigue siendo incorrecto, pero en la otra dirección). Esto es suficiente para cambiar la decisión de granularidad de bloqueo del motor de almacenamiento, de modo que se tomen los bloqueos compartidos a nivel de página (nota, no los bloqueos compartidos por intención):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1
OPTION (QUERYTRACEON 4138); -- NEW!
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); El plan de ejecución estimado producido bajo el indicador de rastreo 4138 es:

Volviendo al ejemplo principal, la estimación de cien filas debido al objetivo de fila adivinado significa que el motor de almacenamiento elige bloquearse en el nivel de fila. Sin embargo, solo observamos bloqueos de intención compartida (IS) en el nivel de tabla y página. Estos bloqueos de nivel superior serían bastante normales si viéramos bloqueos compartidos (S) de nivel de fila, entonces, ¿a dónde fueron?
La respuesta es que el motor de almacenamiento contiene otra optimización que puede omitir los bloqueos compartidos de nivel de fila en determinadas circunstancias. Cuando se aplica esta optimización, los bloqueos de intención compartida de nivel superior aún se adquieren.
Para resumir, para la consulta de mediana única:
- El uso de una variable y expresión en el
OFFSETcláusula significa que el optimizador adivina la cardinalidad. - La estimación baja significa que el motor de almacenamiento decide una estrategia de bloqueo a nivel de fila.
- Una optimización interna significa que los bloqueos S de nivel de fila se omiten en el tiempo de ejecución, dejando solo los bloqueos IS en el nivel de página y objeto.
La consulta de la mediana única habría tenido el mismo problema de rendimiento de bloqueo de filas que la mediana agrupada (debido a la estimación inexacta del optimizador de consultas), pero se salvó mediante una optimización del motor de almacenamiento independiente que dio como resultado que solo se tomaran bloqueos de tablas y páginas compartidas por intención. en tiempo de ejecución.
Revisión de la prueba de la mediana agrupada
Quizás se pregunte por qué la Búsqueda de índice agrupado en la prueba de mediana agrupada no aprovechó la misma optimización del motor de almacenamiento para omitir los bloqueos compartidos a nivel de fila. ¿Por qué se usaron tantos bloqueos de fila compartidos, haciendo que el PAGLOCK sugerencia necesaria?
La respuesta corta es que esta optimización no está disponible para INSERT...SELECT consultas Si ejecutamos el SELECT por sí solo (es decir, sin escribir los resultados en una tabla) y sin un PAGLOCK sugerencia, la optimización de omisión de bloqueo de fila es aplicado:
DECLARE @s datetime2 = SYSUTCDATETIME();
--DECLARE @Result AS table
--(
-- SalesPerson integer PRIMARY KEY,
-- Median float NOT NULL
--);
--INSERT @Result
-- (SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());
Solo se utilizan bloqueos de intención compartida (IS) a nivel de tabla y página, y el rendimiento aumenta al mismo nivel que cuando usamos PAGLOCK insinuación. Por supuesto, no encontrará este comportamiento en la documentación y podría cambiar en cualquier momento. Aún así, es bueno estar al tanto.
Además, en caso de que se lo pregunte, el indicador de seguimiento 4138 no tiene efecto en la elección de granularidad de bloqueo del motor de almacenamiento en este caso porque el número estimado de filas en la búsqueda es demasiado bajo (por iteración de aplicación) incluso con el objetivo de fila deshabilitado.
Antes de sacar conclusiones sobre el rendimiento de una consulta, asegúrese de verificar la cantidad y el tipo de bloqueos que está tomando durante la ejecución. Aunque SQL Server normalmente elige la granularidad "correcta", hay momentos en los que puede hacer las cosas mal, a veces con efectos dramáticos en el rendimiento.