Jake Manske publicó esta pregunta en #sqlhelp y Erik Darling me la comunicó.
No recuerdo haber tenido problemas de rendimiento con sys.partitions . Mi idea inicial (reproducida por Joey D'Antoni) fue que un filtro en data_compression columna debería evite la exploración redundante y reduzca el tiempo de ejecución de consultas a la mitad. Sin embargo, este predicado no se reduce, y la razón por la que requiere un poco de desempaquetado.
¿Por qué sys.partitions es lento?
Si observa la definición de sys.partitions , es básicamente lo que Jake describió:un UNION ALL de todas las particiones de almacén de columnas y almacén de filas, con TRES referencias explícitas a sys.sysrowsets (fuente abreviada aquí):
CREATE VIEW sys.partitions AS
WITH partitions_columnstore(...cols...)
AS
(
SELECT ...cols...,
cmprlevel AS data_compression ...
FROM sys.sysrowsets rs OUTER APPLY OpenRowset(TABLE ALUCOUNT, rs.rowsetid, 0, 0, 0) ct
-------- *** ^^^^^^^^^^^^^^ ***
LEFT JOIN sys.syspalvalues cl ...
WHERE ... sysconv(bit, rs.status & 0x00010000) = 1 -- Consider only columnstore base indexes
),
partitions_rowstore(...cols...)
AS
(
SELECT ...cols...,
cmprlevel AS data_compression ...
FROM sys.sysrowsets rs
-------- *** ^^^^^^^^^^^^^^ ***
LEFT JOIN sys.syspalvalues cl ...
WHERE ... sysconv(bit, rs.status & 0x00010000) = 0 -- Ignore columnstore base indexes and orphaned rows.
)
SELECT ...cols...
from partitions_rowstore p OUTER APPLY OpenRowset(TABLE ALUCOUNT, p.partition_id, 0, 0, p.object_id) ct
union all
SELECT ...cols...
FROM partitions_columnstore as P1
LEFT JOIN
(SELECT ...cols...
FROM sys.sysrowsets rs OUTER APPLY OpenRowset(TABLE ALUCOUNT, rs.rowsetid, 0, 0, 0) ct
------- *** ^^^^^^^^^^^^^^ ***
) ...
Esta vista parece improvisada, probablemente debido a problemas de compatibilidad con versiones anteriores. Seguramente podría reescribirse para que sea más eficiente, en particular para que solo haga referencia a sys.sysrowsets y TABLE ALUCOUNT objetos una vez. Pero no hay mucho que tú o yo podamos hacer al respecto en este momento.
La columna cmprlevel proviene de sys.sysrowsets (habría sido útil un prefijo de alias en la referencia de la columna). Esperaría que un predicado contra una columna ocurra lógicamente antes de cualquier OUTER APPLY y podría evitar uno de los escaneos, pero eso no es lo que sucede. Ejecutando la siguiente consulta simple:
SELECT * FROM sys.partitions AS p INNER JOIN sys.objects AS o ON p.object_id = o.object_id WHERE o.is_ms_shipped = 0;
Produce el siguiente plan cuando hay índices de almacén de columnas en las bases de datos (haga clic para ampliar):
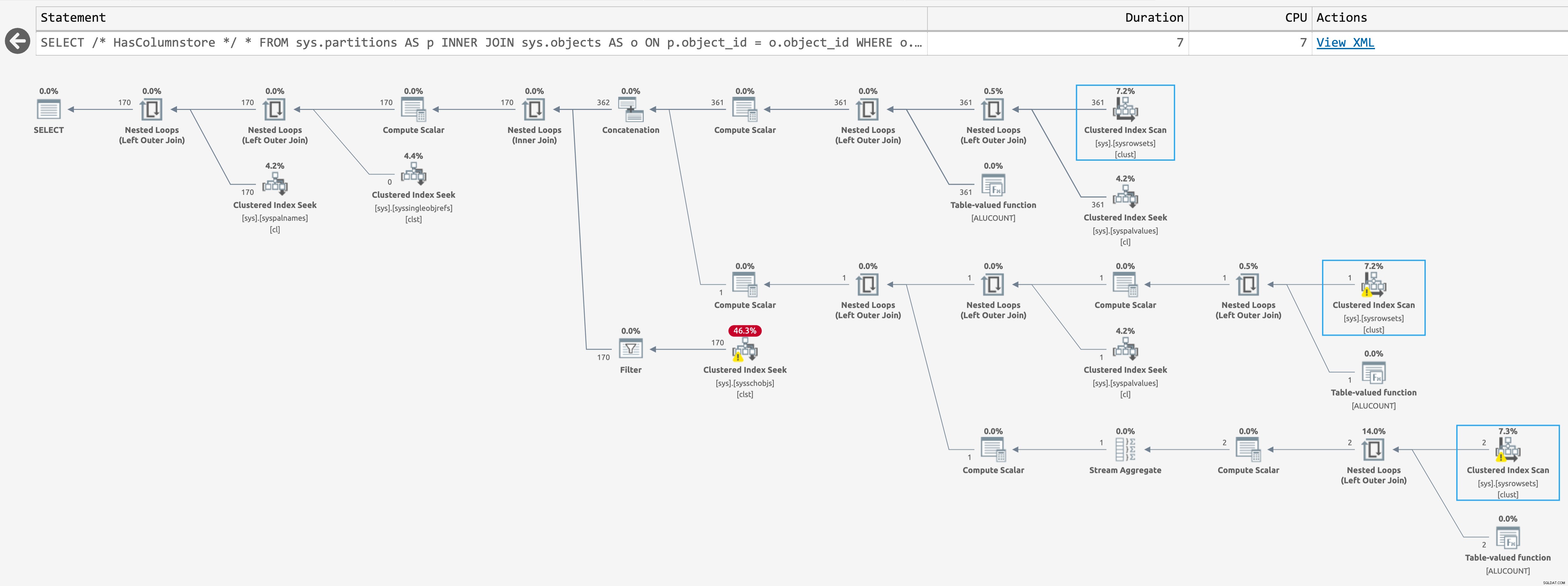 Plan para sys.partitions, con índices de almacén de columnas
Plan para sys.partitions, con índices de almacén de columnas
Y el siguiente plan cuando no los haya (click para ampliar):
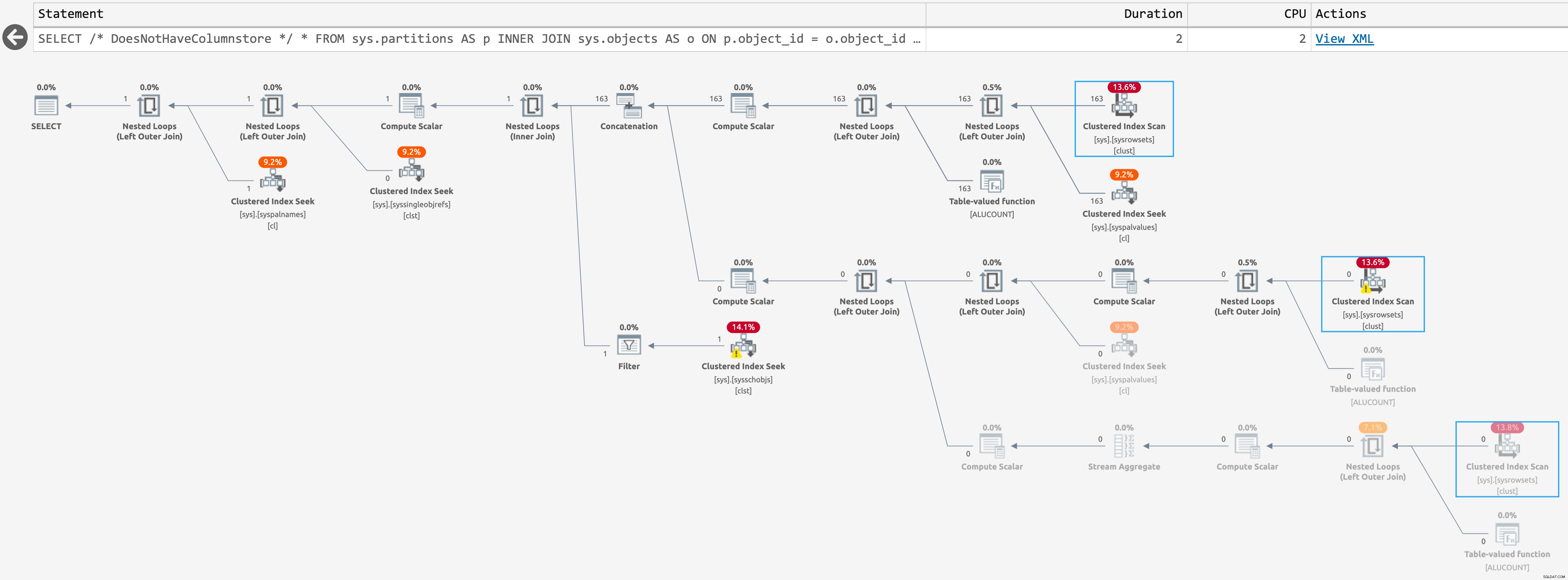 Plan para sys.partitions, sin índices de almacén de columnas
Plan para sys.partitions, sin índices de almacén de columnas
Estos son el mismo plan estimado, pero SentryOne Plan Explorer puede resaltar cuándo se omite una operación en tiempo de ejecución. Esto sucede para el tercer escaneo en el último caso, pero no sé si hay alguna forma de reducir aún más el recuento de escaneos en tiempo de ejecución; el segundo escaneo ocurre incluso cuando la consulta devuelve cero filas.
En el caso de Jake, tiene mucho de objetos, por lo que realizar este escaneo incluso dos veces es notable, doloroso y una vez demasiado. Y, sinceramente, no sé si TABLE ALUCOUNT , una llamada de loopback interna y no documentada, también tiene que escanear algunos de estos objetos más grandes varias veces.
Mirando hacia atrás en la fuente, me preguntaba si había algún otro predicado que pudiera pasarse a la vista que pudiera forzar la forma del plan, pero realmente no creo que haya nada que pueda tener un impacto.
¿Funcionará otra vista?
Sin embargo, podríamos probar una vista completamente diferente. Busqué otras vistas que contenían referencias a ambos sys.sysrowsets y ALUCOUNT , y hay varios que aparecen en la lista, pero solo dos son prometedores:sys.internal_partitions y sys.system_internals_partitions .
sys.particiones_internas
Probé sys.internal_partitions primero:
SELECT * FROM sys.internal_partitions AS p INNER JOIN sys.objects AS o ON p.object_id = o.object_id WHERE o.is_ms_shipped = 0;
Pero el plan no era mucho mejor (haga clic para ampliar):
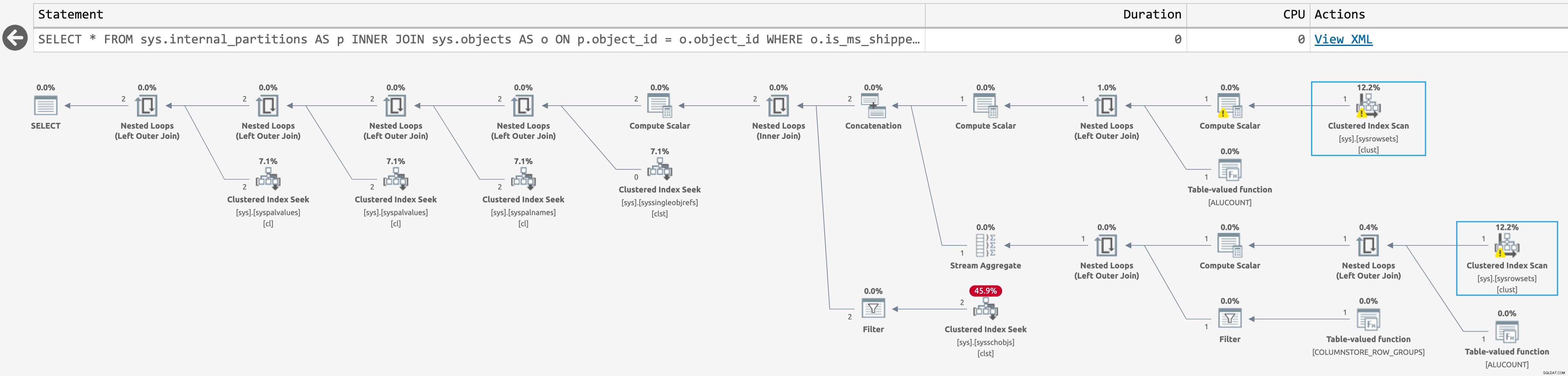 Plan para sys.internal_partitions
Plan para sys.internal_partitions
Solo hay dos escaneos contra sys.sysrowsets esta vez, pero los escaneos son irrelevantes de todos modos porque la consulta no se acerca a producir las filas que nos interesan. Solo vemos filas para objetos relacionados con el almacén de columnas (como indica la documentación).
sys.system_internals_partitions
Probemos sys.system_internals_partitions . Soy un poco cauteloso con esto, porque no es compatible (vea la advertencia aquí), pero tenga paciencia conmigo un momento:
SELECT * FROM sys.system_internals_partitions AS p INNER JOIN sys.objects AS o ON p.object_id = o.object_id WHERE o.is_ms_shipped = 0;
En la base de datos con índices de almacén de columnas, hay un escaneo contra sys.sysschobjs , pero ahora solo uno escanear contra sys.sysrowsets (haga clic para ampliar):
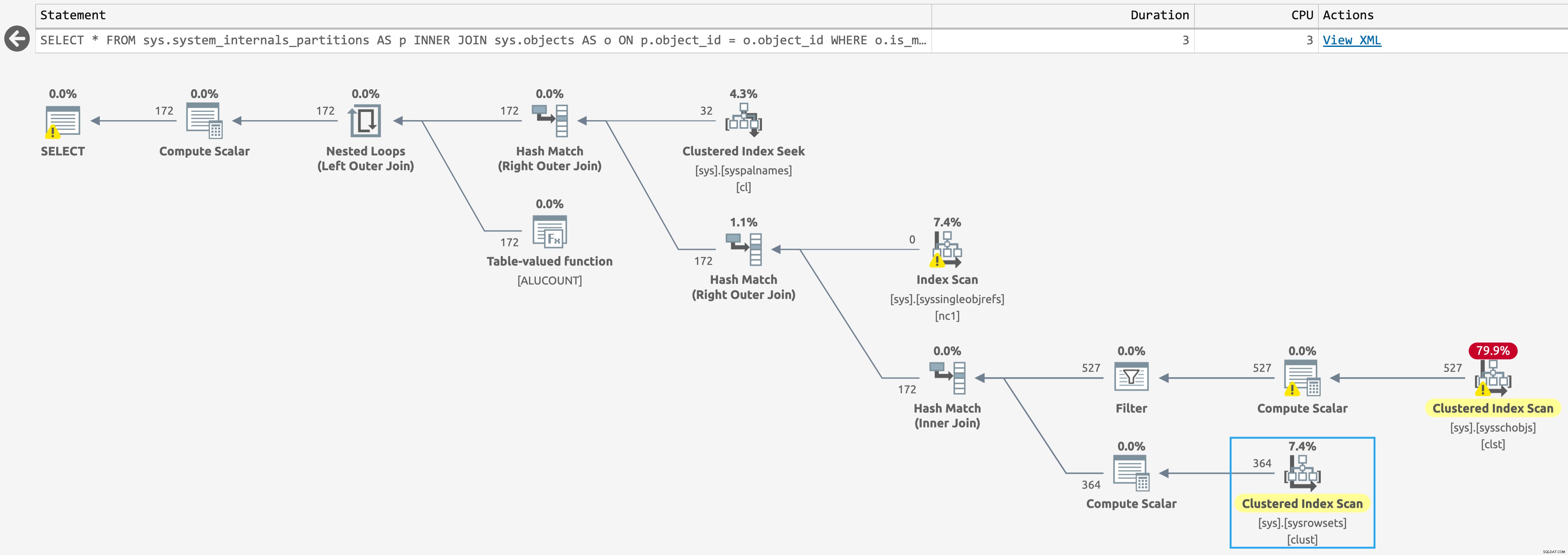 Plan para sys.system_internals_partitions, con índices de almacén de columnas
Plan para sys.system_internals_partitions, con índices de almacén de columnas
Si ejecutamos la misma consulta en la base de datos sin índices de almacén de columnas, el plan es aún más simple, con una búsqueda contra sys.sysschobjs (haga clic para ampliar):
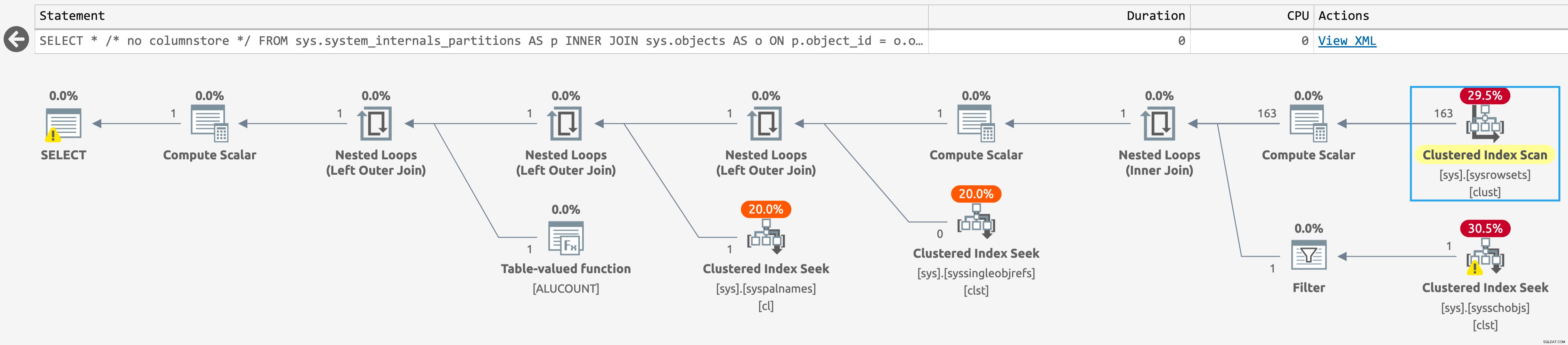 Plan para sys.system_internals_partitions, sin índices de almacén de columnas
Plan para sys.system_internals_partitions, sin índices de almacén de columnas
Sin embargo, esto no es bastante lo que buscamos, o al menos no exactamente lo que buscaba Jake, porque también incluye artefactos de índices de almacén de columnas. Si agregamos estos filtros, el resultado real ahora coincide con nuestra consulta anterior, mucho más costosa:
SELECT *
FROM sys.system_internals_partitions AS p
INNER JOIN sys.objects AS o ON p.object_id = o.object_id
WHERE o.is_ms_shipped = 0
AND p.is_columnstore = 0
AND p.is_orphaned = 0;
Como beneficio adicional, el escaneo contra sys.sysschobjs se ha convertido en una búsqueda incluso en la base de datos con objetos de almacén de columnas. La mayoría de nosotros no notaremos esa diferencia, pero si estás en un escenario como el de Jake, podrías (haz clic para ampliar):
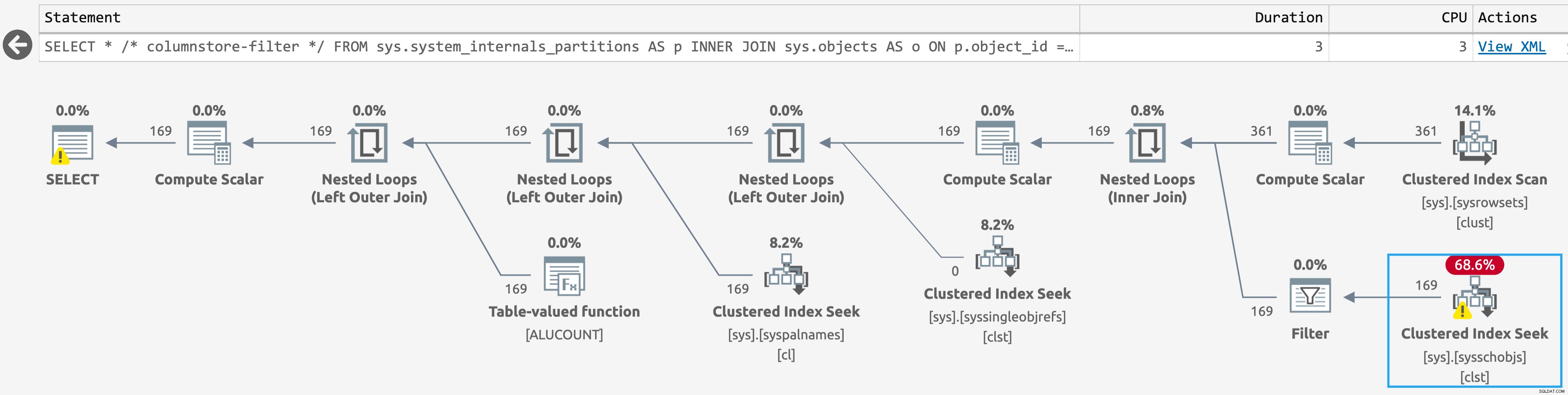 Plan más simple para sys.system_internals_partitions, con filtros adicionales
Plan más simple para sys.system_internals_partitions, con filtros adicionales
sys.system_internals_partitions expone un conjunto diferente de columnas que sys.partitions (algunos son completamente diferentes, otros tienen nombres nuevos), por lo tanto, si está consumiendo la salida aguas abajo, tendrá que ajustarlos. También querrá validar que devuelve toda la información que desea en los índices de almacén de filas, optimizado para memoria y de almacén de columnas, y no se olvide de esos molestos montones. Y, finalmente, prepárate para omitir los s en internals muchas, muchas veces.
Conclusión
Como mencioné anteriormente, esta vista del sistema no es oficialmente compatible, por lo que su funcionalidad puede cambiar en cualquier momento; también podría moverse bajo la Conexión de administrador dedicado (DAC) o eliminarse del producto por completo. Siéntase libre de usar este enfoque si sys.partitions no te está funcionando bien pero, por favor, asegúrate de tener un plan alternativo. Y asegúrese de que esté documentado como algo que realice una prueba de regresión cuando comience a probar versiones futuras de SQL Server, o después de actualizar, por si acaso.



