SQL Server 2005 agregó la capacidad de incluir columnas sin clave en un índice no agrupado. En SQL Server 2000 y versiones anteriores, para un índice no agrupado, todas las columnas definidas para un índice eran columnas clave, lo que significaba que formaban parte de todos los niveles del índice, desde la raíz hasta el nivel hoja. Cuando una columna se define como una columna incluida, es parte del nivel de hoja solamente. Books Online señala los siguientes beneficios de las columnas incluidas:
- Pueden ser tipos de datos no permitidos como columnas de clave de índice.
- Motor de base de datos no las tiene en cuenta al calcular el número de columnas de clave de índice o el tamaño de clave de índice.
Por ejemplo, una columna varchar(max) no puede ser parte de una clave de índice, pero puede ser una columna incluida. Además, esa columna varchar(max) no cuenta contra el límite de 900 bytes (o 16 columnas) impuesto para la clave de índice.
La documentación también señala el siguiente beneficio de rendimiento:
Un índice con columnas sin clave puede mejorar significativamente el rendimiento de la consulta cuando todas las columnas de la consulta se incluyen en el índice como columnas clave o no clave. Las ganancias de rendimiento se logran porque el optimizador de consultas puede ubicar todos los valores de columna dentro del índice; no se accede a los datos de la tabla o del índice agrupado, lo que da como resultado menos operaciones de E/S de disco.Podemos inferir que si las columnas del índice son columnas clave o no clave, obtenemos una mejora en el rendimiento en comparación con cuando todas las columnas no forman parte del índice. Pero, ¿hay alguna diferencia de rendimiento entre las dos variaciones?
La configuración
Instalé una copia de la base de datos AdventuresWork2012 y verifiqué los índices de la tabla Sales.SalesOrderHeader usando la versión de sp_helpindex de Kimberly Tripp:
USE [AdventureWorks2012]; GO EXEC sp_SQLskills_SQL2012_helpindex N'Sales.SalesOrderHeader';

Índices predeterminados para Sales.SalesOrderHeader
Comenzaremos con una consulta directa para realizar pruebas que recupera datos de varias columnas:
SELECT [CustomerID], [SalesPersonID], [SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 11000 and 11200;
Si ejecutamos esto contra la base de datos AdventureWorks2012 usando SQL Sentry Plan Explorer y verificamos el plan y la salida de E/S de la tabla, vemos que obtenemos un escaneo de índice agrupado con 689 lecturas lógicas:
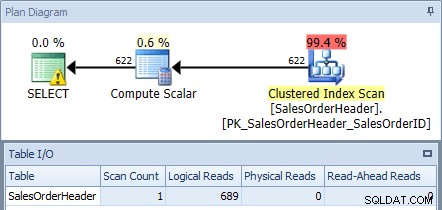
Plan de ejecución de la consulta original
(En Management Studio, podría ver las métricas de E/S usando SET STATISTICS IO ON; .)
El SELECT tiene un icono de advertencia, porque el optimizador recomienda un índice para esta consulta:
USE [AdventureWorks2012]; GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [Sales].[SalesOrderHeader] ([CustomerID]) INCLUDE ([OrderDate],[ShipDate],[SalesPersonID],[SubTotal]);
Prueba 1
Primero crearemos el índice que recomienda el optimizador (denominado NCI1_incluido), así como la variación con todas las columnas como columnas clave (denominada NCI1):
CREATE NONCLUSTERED INDEX [NCI1] ON [Sales].[SalesOrderHeader]([CustomerID], [SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO CREATE NONCLUSTERED INDEX [NCI1_included] ON [Sales].[SalesOrderHeader]([CustomerID]) INCLUDE ([SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO
Si volvemos a ejecutar la consulta original, una vez insinuándola con NCI1 y una vez insinuándola con NCI1_included, vemos un plan similar al original, pero esta vez hay una búsqueda de índice de cada índice no agrupado, con valores equivalentes para la Tabla I/ O, y costos similares (ambos alrededor de 0.006):
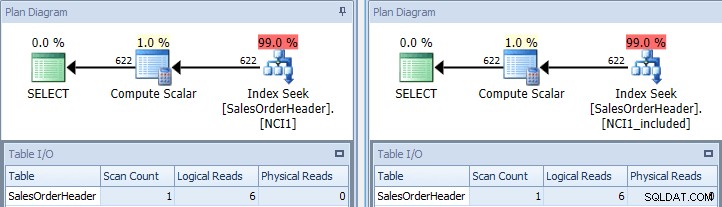
Consulta original con búsquedas de índice:clave a la izquierda, incluir en la derecha
(El recuento de escaneos sigue siendo 1 porque la búsqueda de índice es en realidad un escaneo de rango disfrazado).
Ahora, la base de datos AdventureWorks2012 no es representativa de una base de datos de producción en términos de tamaño, y si observamos la cantidad de páginas en cada índice, vemos que son exactamente iguales:
SELECT [Table] = N'SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.SalesOrderHeader');
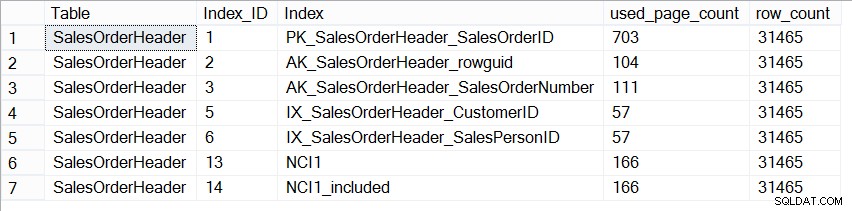
Tamaño de los índices en Sales.SalesOrderHeader
Si estamos analizando el rendimiento, es ideal (y más divertido) probar con un conjunto de datos más grande.
Prueba 2
Tengo una copia de la base de datos AdventureWorks2012 que tiene una tabla SalesOrderHeader con más de 200 millones de filas (script AQUÍ), así que creemos los mismos índices no agrupados en esa base de datos y volvamos a ejecutar las consultas:
USE [AdventureWorks2012_Big]; GO CREATE NONCLUSTERED INDEX [Big_NCI1] ON [Sales].[Big_SalesOrderHeader](CustomerID, SubTotal, OrderDate, ShipDate, SalesPersonID); GO CREATE NONCLUSTERED INDEX [Big_NCI1_included] ON [Sales].[Big_SalesOrderHeader](CustomerID) INCLUDE (SubTotal, OrderDate, ShipDate, SalesPersonID); GO SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE [CustomerID] between 11000 and 11200; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE [CustomerID] between 11000 and 11200;
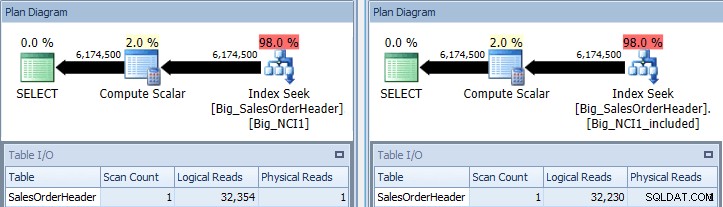
Consulta original con búsquedas de índice contra Big_NCI1 (l) y Big_NCI1_Included ( r)
Ahora obtenemos algunos datos. La consulta devuelve más de 6 millones de filas y la búsqueda de cada índice requiere poco más de 32 000 lecturas, y el costo estimado es el mismo para ambas consultas (31,233). Aún no hay diferencias de rendimiento, y si comprobamos el tamaño de los índices, vemos que el índice con las columnas incluidas tiene 5.578 páginas menos:
SELECT [Table] = N'Big_SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Tamaño de los índices en Sales.Big_SalesOrderHeader
Si profundizamos más en esto y verificamos dm_dm_index_physical_stats, podemos ver que existe una diferencia en los niveles intermedios del índice:
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 5, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] AS [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 6, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
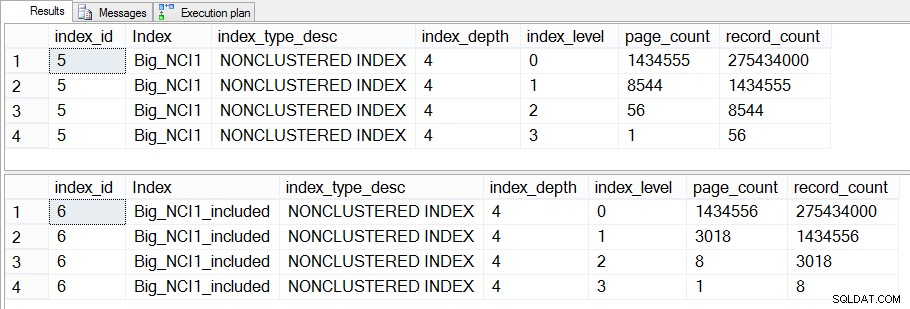
Tamaño de los índices (específico del nivel) en Sales.Big_SalesOrderHeader
La diferencia entre los niveles intermedios de los dos índices es de 43 MB, lo que puede no ser significativo, pero probablemente me incline a crear el índice con columnas incluidas para ahorrar espacio, tanto en el disco como en la memoria. Desde una perspectiva de consulta, aún no vemos un gran cambio en el rendimiento entre el índice con todas las columnas en la clave y el índice con las columnas incluidas.
Prueba 3
Para esta prueba, cambiemos la consulta y agreguemos un filtro para [SubTotal] >= 100 a la cláusula WHERE:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 AND [SubTotal] >= 100; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 AND [SubTotal] >= 100;
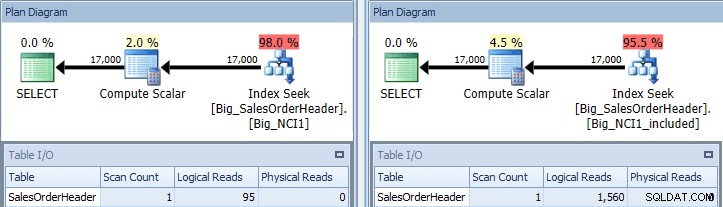
Plan de ejecución de consulta con predicado SubTotal contra ambos índices
Ahora vemos una diferencia en E/S (95 lecturas frente a 1560), costo (0,848 frente a 1,55) y una diferencia sutil pero notable en el plan de consulta. Cuando se utiliza el índice con todas las columnas de la clave, el predicado de búsqueda es el CustomerID y el SubTotal:
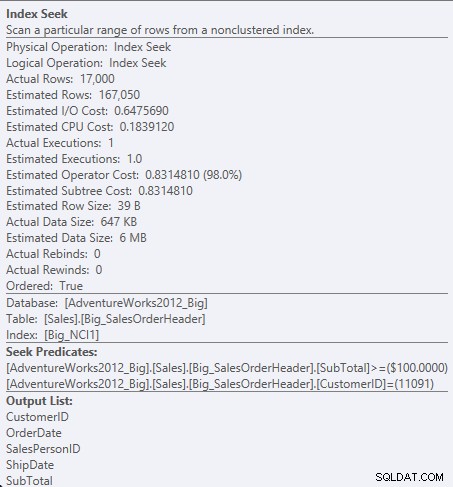
Buscar predicado contra NCI1
Dado que SubTotal es la segunda columna de la clave de índice, los datos están ordenados y el SubTotal existe en los niveles intermedios del índice. El motor puede buscar directamente el primer registro con un CustomerID de 11091 y un Subtotal mayor o igual a 100, y luego leer el índice hasta que no existan más registros para CustomerID 11091.
Para el índice con las columnas incluidas, el SubTotal solo existe en el nivel de hoja del índice, por lo que CustomerID es el predicado de búsqueda y SubTotal es un predicado residual (aparece como Predicado en la captura de pantalla):
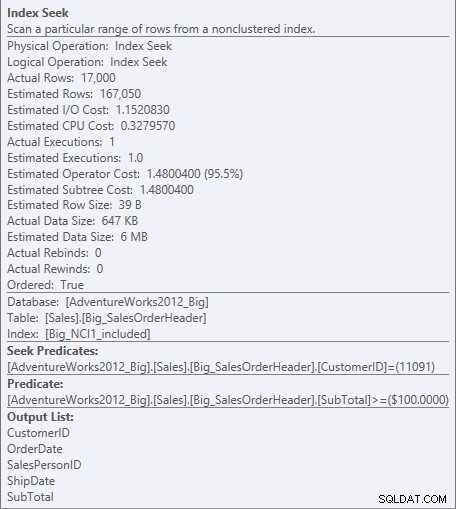
Buscar predicado y predicado residual contra NCI1_incluido
El motor puede buscar directamente en el primer registro donde CustomerID es 11091, pero luego tiene que buscar en cada registre para CustomerID 11091 para ver si el Subtotal es 100 o más, porque los datos están ordenados por CustomerID y SalesOrderID (clave de agrupación).
Prueba 4
Probaremos una variación más de nuestra consulta, y esta vez agregaremos un ORDEN POR:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 ORDER BY [SubTotal]; SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 ORDER BY [SubTotal];
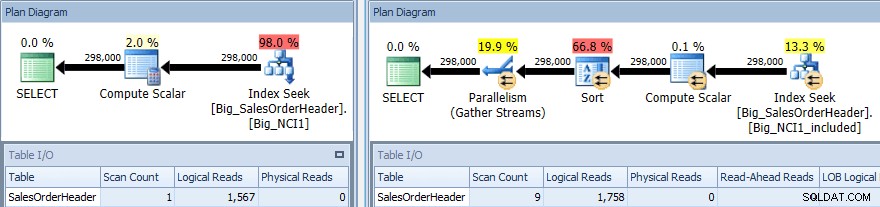
Plan de ejecución de consulta con SORT contra ambos índices
De nuevo, tenemos un cambio en E/S (aunque muy leve), un cambio en el costo (1.5 frente a 9.3) y un cambio mucho mayor en la forma del plan; también vemos una mayor cantidad de escaneos (1 frente a 9). La consulta requiere que los datos estén ordenados por SubTotal; cuando SubTotal es parte de la clave de índice, se ordena, de modo que cuando se recuperan los registros para CustomerID 11091, ya están en el orden solicitado.
Cuando SubTotal existe como una columna incluida, los registros para CustomerID 11091 deben ordenarse antes de que puedan devolverse al usuario, por lo tanto, el optimizador inserta un operador Sort en la consulta. Como resultado, la consulta que utiliza el índice Big_NCI1_included también solicita (y recibe) una concesión de memoria de 29 312 KB, que es notable (y se encuentra en las propiedades del plan).
Resumen
La pregunta original que queríamos responder era si veríamos una diferencia de rendimiento cuando una consulta usaba el índice con todas las columnas en la clave, en comparación con el índice con la mayoría de las columnas incluidas en el nivel hoja. En nuestro primer conjunto de pruebas no hubo diferencia, pero en nuestra tercera y cuarta prueba sí. En última instancia, depende de la consulta. Solo observamos dos variaciones:una tenía un predicado adicional, la otra tenía un ORDEN POR; existen muchas más.
Lo que los desarrolladores y los administradores de bases de datos deben comprender es que incluir columnas en un índice tiene grandes beneficios, pero no siempre funcionarán igual que los índices que tienen todas las columnas en la clave. Puede ser tentador mover las columnas que no forman parte de los predicados y las uniones fuera de la clave, e incluirlas simplemente, para reducir el tamaño total del índice. Sin embargo, en algunos casos esto requiere más recursos para la ejecución de consultas y puede degradar el rendimiento. La degradación puede ser insignificante; puede que no sea... no lo sabrá hasta que haga la prueba. Por lo tanto, al diseñar un índice, es importante pensar en las columnas después de la inicial y comprender si deben ser parte de la clave (por ejemplo, porque mantener los datos ordenados proporcionará beneficios) o si pueden cumplir su propósito como incluidos. columnas
Como es típico con la indexación en SQL Server, debe probar sus consultas con sus índices para determinar la mejor estrategia. Sigue siendo un arte y una ciencia:tratar de encontrar la cantidad mínima de índices para satisfacer tantas consultas como sea posible.