En mi última publicación, mostré algunos enfoques eficientes para la concatenación agrupada. Esta vez, quería hablar sobre un par de facetas adicionales de este problema que podemos lograr fácilmente con FOR XML PATH enfoque:ordenar la lista y eliminar los duplicados.
Hay algunas formas en que he visto que la gente quiere que se ordene la lista separada por comas. A veces quieren que el elemento de la lista se ordene alfabéticamente; Ya lo mostré en mi post anterior. Pero a veces quieren ordenarlo por algún otro atributo que en realidad no se está introduciendo en la salida; por ejemplo, tal vez quiera ordenar primero la lista por el elemento más reciente. Tomemos un ejemplo simple, donde tenemos una tabla de Empleados y una tabla de CoffeeOrders. Completemos los pedidos de una persona durante unos días:
CREATE TABLE dbo.Employees
(
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(128)
);
INSERT dbo.Employees(EmployeeID, Name) VALUES(1, N'Jack');
CREATE TABLE dbo.CoffeeOrders
(
EmployeeID INT NOT NULL REFERENCES dbo.Employees(EmployeeID),
OrderDate DATE NOT NULL,
OrderDetails NVARCHAR(64)
);
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
VALUES(1,'20140801',N'Large double double'),
(1,'20140802',N'Medium double double'),
(1,'20140803',N'Large Vanilla Latte'),
(1,'20140804',N'Medium double double');
Si usamos el enfoque existente sin especificar un ORDER BY , obtenemos un orden arbitrario (en este caso, lo más probable es que vea las filas en el orden en que se insertaron, pero no dependa de eso con conjuntos de datos más grandes, más índices, etc.):
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultados (recuerde, puede obtener resultados *diferentes* a menos que especifique un ORDER BY ):
Jack | Doble doble grande, Doble doble mediana, Latte de vainilla grande, Doble doble mediana
Si queremos ordenar alfabéticamente la lista, es sencillo; simplemente agregamos ORDER BY c.OrderDetails :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDetails -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultados:
Nombre | PedidosJack | Doble doble grande, Latte vainilla grande, Doble doble mediana, Doble doble mediana
También podemos ordenar por una columna que no aparece en el conjunto de resultados; por ejemplo, podemos ordenar primero por orden de café más reciente:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDate DESC -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultados:
Nombre | PedidosJack | Doble doble mediana, Latte vainilla grande, Doble doble mediana, Doble doble grande
Otra cosa que a menudo queremos hacer es eliminar los duplicados; después de todo, hay pocas razones para ver "Medium double double" dos veces. Podemos eliminar eso usando GROUP BY :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails -- removed ORDER BY and added GROUP BY here FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Ahora, esto *sucede* para ordenar la salida alfabéticamente, pero de nuevo no puedes confiar en esto:
Nombre | PedidosJack | Doble doble grande, Latte de vainilla grande, Doble doble mediana
Si desea garantizar que ordene de esta manera, simplemente puede agregar un PEDIDO POR nuevamente:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDetails -- added ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Los resultados son los mismos (pero repito, esto es solo una coincidencia en este caso; si quieres este orden, siempre dilo):
Nombre | PedidosJack | Doble doble grande, Latte de vainilla grande, Doble doble mediana
Pero, ¿qué pasa si queremos eliminar los duplicados *y* ordenar primero la lista según el pedido de café más reciente? Su primera inclinación podría ser mantener el GROUP BY y simplemente cambie el ORDER BY , así:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDate DESC -- changed ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Eso no funcionará, ya que OrderDate no está agrupado o agregado como parte de la consulta:
La columna "dbo.CoffeeOrders.OrderDate" no es válida en la cláusula ORDER BY porque no está incluida en una función agregada ni en la cláusula GROUP BY.
Una solución alternativa, que ciertamente hace que la consulta sea un poco más fea, es agrupar primero los pedidos por separado y luego tomar solo las filas con la fecha máxima para ese pedido de café por empleado:
;WITH grouped AS ( SELECT EmployeeID, OrderDetails, OrderDate = MAX(OrderDate) FROM dbo.CoffeeOrders GROUP BY EmployeeID, OrderDetails ) SELECT e.Name, Orders = STUFF((SELECT N', ' + g.OrderDetails FROM grouped AS g WHERE g.EmployeeID = e.EmployeeID ORDER BY g.OrderDate DESC FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultados:
Nombre | PedidosJack | Doble doble mediana, Latte de vainilla grande, Doble doble grande
Esto logra nuestros dos objetivos:eliminamos los duplicados y ordenamos la lista por algo que no está realmente en la lista.
Rendimiento
Quizás se pregunte qué tan mal funcionan estos métodos frente a un conjunto de datos más sólido. Voy a llenar nuestra tabla con 100 000 filas, veré cómo funcionan sin índices adicionales y luego ejecutaré las mismas consultas nuevamente con un poco de ajuste de índice para respaldar nuestras consultas. Primero, obtener 100 000 filas distribuidas entre 1000 empleados:
-- clear out our tiny sample data
DELETE dbo.CoffeeOrders;
DELETE dbo.Employees;
-- create 1000 fake employees
INSERT dbo.Employees(EmployeeID, Name)
SELECT TOP (1000)
EmployeeID = ROW_NUMBER() OVER (ORDER BY t.[object_id]),
Name = LEFT(t.name + c.name, 128)
FROM sys.all_objects AS t
INNER JOIN sys.all_columns AS c
ON t.[object_id] = c.[object_id];
-- create 100 fake coffee orders for each employee
-- we may get duplicates in here for name
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
SELECT e.EmployeeID,
OrderDate = DATEADD(DAY, ROW_NUMBER() OVER
(PARTITION BY e.EmployeeID ORDER BY c.[guid]), '20140630'),
LEFT(c.name, 64)
FROM dbo.Employees AS e
CROSS APPLY
(
SELECT TOP (100) name, [guid] = NEWID()
FROM sys.all_columns
WHERE [object_id] < e.EmployeeID
ORDER BY NEWID()
) AS c; Ahora simplemente ejecutemos cada una de nuestras consultas dos veces y veamos cómo es el tiempo en el segundo intento (haremos un acto de fe aquí y supondremos que, en un mundo ideal, estaremos trabajando con un caché preparado ). Ejecuté estos en SQL Sentry Plan Explorer, ya que es la forma más fácil que conozco de cronometrar y comparar un montón de consultas individuales:
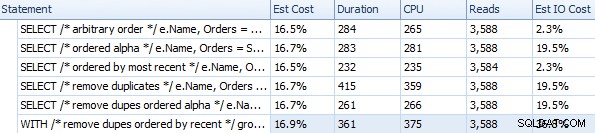 Duración y otras métricas de tiempo de ejecución para diferentes enfoques FOR XML PATH
Duración y otras métricas de tiempo de ejecución para diferentes enfoques FOR XML PATH
Estos tiempos (la duración es en milisegundos) realmente no son tan malos en mi humilde opinión, cuando piensas en lo que realmente se está haciendo aquí. El plan más complicado, al menos visualmente, parecía ser aquel en el que eliminamos los duplicados y ordenamos por orden más reciente:
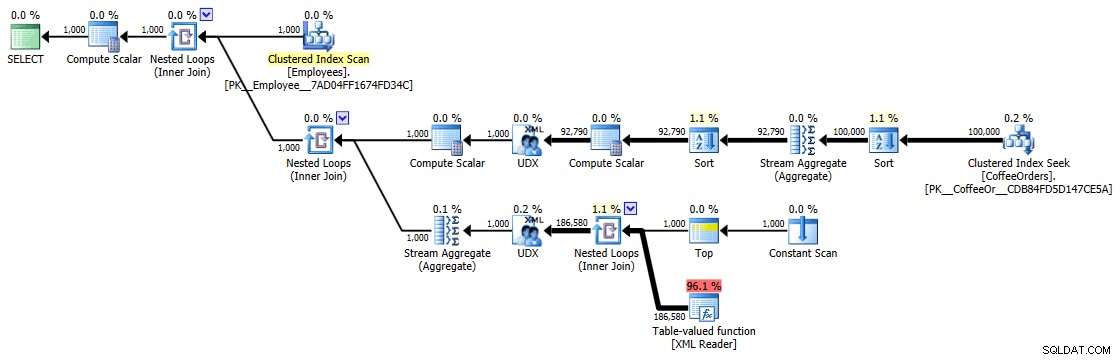 Plan de ejecución para consulta agrupada y ordenada
Plan de ejecución para consulta agrupada y ordenada
Pero incluso el operador más costoso aquí, la función con valores de tabla XML, parece ser solo CPU (aunque admito libremente que no estoy seguro de cuánto del trabajo real está expuesto en los detalles del plan de consulta):
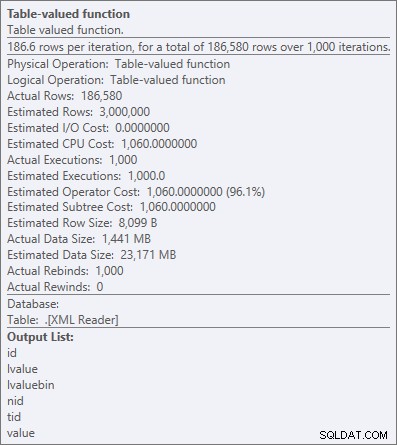 Propiedades del operador para la función con valores de tabla XML
Propiedades del operador para la función con valores de tabla XML
"Toda la CPU" normalmente está bien, ya que la mayoría de los sistemas están vinculados a E/S y/o vinculados a la memoria, no vinculados a la CPU. Como digo con bastante frecuencia, en la mayoría de los sistemas cambiaré parte de mi margen de CPU por memoria o disco cualquier día de la semana (una de las razones por las que me gusta OPTION (RECOMPILE) como una solución a los problemas generalizados de rastreo de parámetros).
Dicho esto, le recomiendo encarecidamente que pruebe estos enfoques con resultados similares que puede obtener del enfoque GROUP_CONCAT CLR en CodePlex, además de realizar la agregación y clasificación en el nivel de presentación (especialmente si mantiene los datos normalizados de algún modo). de la capa de almacenamiento en caché).