La eliminación y prevención de la fragmentación de índices ha sido durante mucho tiempo parte de las operaciones normales de mantenimiento de bases de datos, no solo en SQL Server, sino en muchas plataformas. La fragmentación del índice afecta el rendimiento por muchas razones, y la mayoría de la gente habla de los efectos de pequeños bloques aleatorios de E/S que pueden ocurrir físicamente en el almacenamiento basado en disco como algo que debe evitarse. La preocupación general sobre la fragmentación de índices es que afecta el rendimiento de los escaneos al limitar el tamaño de las E/S de lectura anticipada. Se basa en esta comprensión limitada de los problemas que causa la fragmentación de índices que algunas personas han comenzado a circular la idea de que la fragmentación de índices no importa con los dispositivos de almacenamiento de estado sólido (SSD) y que simplemente puede ignorar la fragmentación de índices en el futuro.
Sin embargo, ese no es el caso por varias razones. Este artículo explicará y demostrará una de esas razones:la fragmentación del índice puede afectar negativamente la elección del plan de ejecución para las consultas. Esto ocurre porque la fragmentación del índice generalmente hace que un índice tenga más páginas (estas páginas adicionales provienen de la división de página operaciones, como se describe en esta publicación en este sitio), por lo que el optimizador de consultas de SQL Server considera que el uso de ese índice tiene un costo más alto.
Veamos un ejemplo.
Lo primero que debemos hacer es crear una base de datos de prueba adecuada y un conjunto de datos para examinar cómo la fragmentación del índice puede afectar la elección del plan de consulta en SQL Server. El siguiente script creará una base de datos con dos tablas con datos idénticos, una muy fragmentada y otra mínimamente fragmentada.
USE master;
GO
DROP DATABASE FragmentationTest;
GO
CREATE DATABASE FragmentationTest;
GO
USE FragmentationTest;
GO
CREATE TABLE GuidHighFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidHighFragmentation_LastName
ON GuidHighFragmentation(LastName);
GO
CREATE TABLE GuidLowFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidLowFragmentation_LastName
ON GuidLowFragmentation(LastName);
GO
INSERT INTO GuidHighFragmentation (FirstName, LastName)
SELECT TOP 100000 a.name, b.name
FROM master.dbo.spt_values AS a
CROSS JOIN master.dbo.spt_values AS b
WHERE a.name IS NOT NULL
AND b.name IS NOT NULL
ORDER BY NEWID();
GO 70
INSERT INTO GuidLowFragmentation (UniqueID, FirstName, LastName)
SELECT UniqueID, FirstName, LastName
FROM GuidHighFragmentation;
GO
ALTER INDEX ALL ON GuidLowFragmentation REBUILD;
GO Después de reconstruir el índice, podemos ver los niveles de fragmentación con la siguiente consulta:
SELECT
OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name,
ps.index_id,
ps.index_depth,
avg_fragmentation_in_percent,
fragment_count,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(
DB_ID(),
NULL,
NULL,
NULL,
'DETAILED') AS ps
JOIN sys.indexes AS i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE index_level = 0;
GO Resultados:

Aquí podemos ver que nuestra GuidHighFragmentation la tabla está fragmentada en un 99 % y utiliza un 31 % más de espacio de página que GuidLowFragmentation tabla en la base de datos, a pesar de que tienen las mismas 7,000,000 filas de datos. Si realizamos una consulta de agregación básica en cada una de las tablas y comparamos los planes de ejecución en una instalación predeterminada (con opciones y valores de configuración predeterminados) de SQL Server utilizando SentryOne Plan Explorer:
-- Aggregate the data from both tables SELECT LastName, COUNT(*) FROM GuidLowFragmentation GROUP BY LastName; GO SELECT LastName, COUNT(*) FROM GuidHighFragmentation GROUP BY LastName; GO


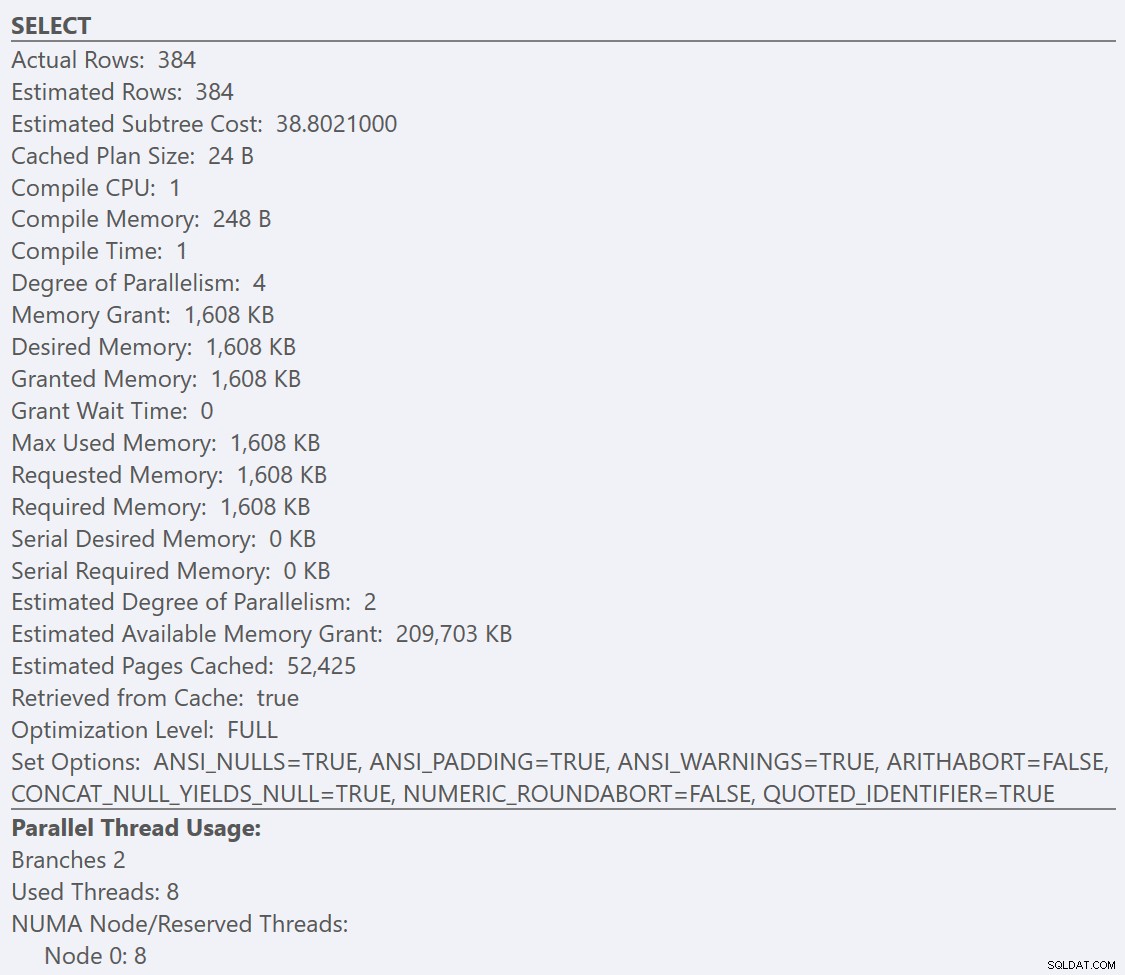

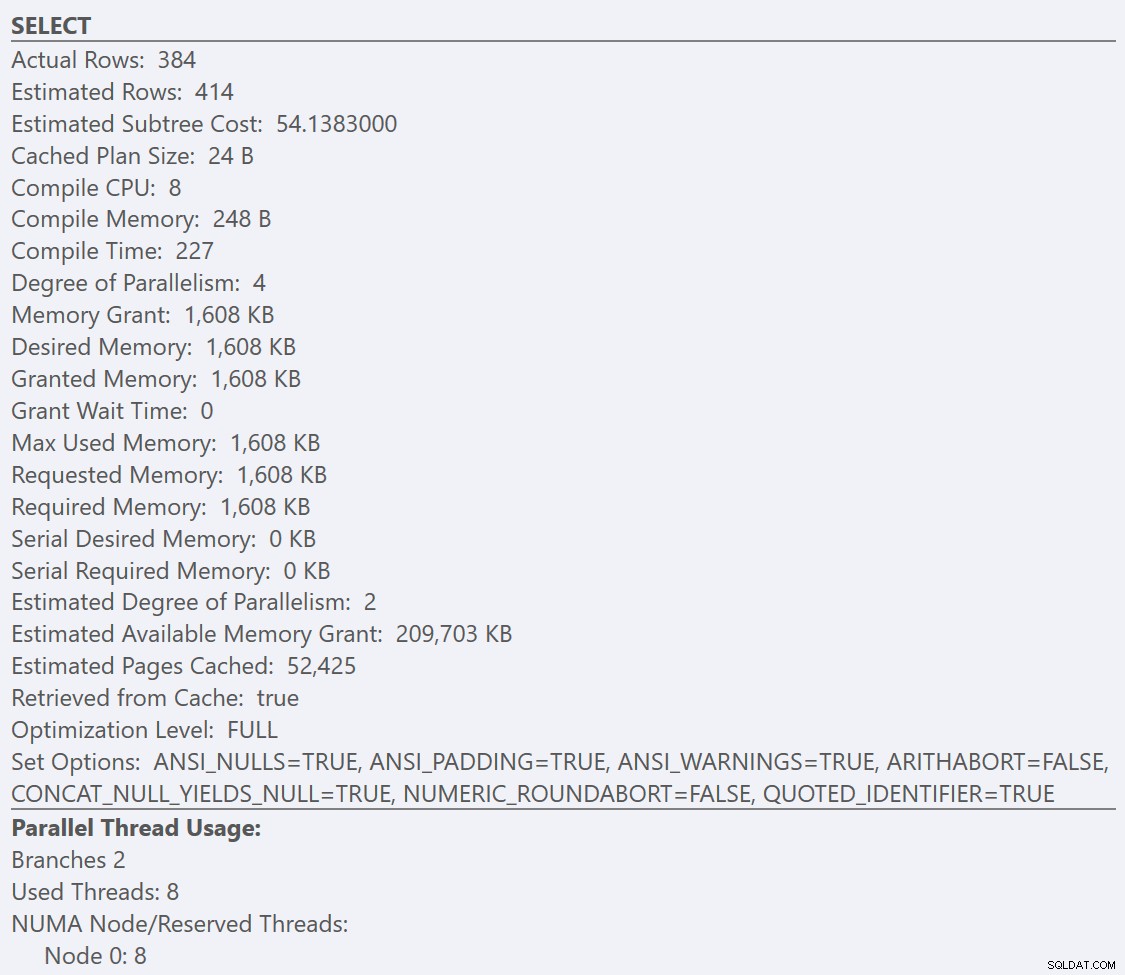
Si miramos la información sobre herramientas de SELECT operador para cada plan, el plan para GuidLowFragmentation table tiene un costo de consulta de 38,80 (la tercera línea hacia abajo desde la parte superior de la información sobre herramientas) frente a un costo de consulta de 54,14 para el plan GuidHighFragmentation.
Bajo una configuración predeterminada para SQL Server, ambas consultas terminan generando un plan de ejecución paralelo ya que el costo estimado de la consulta es más alto que el valor predeterminado de la opción sp_configure del 'umbral de costo para el paralelismo' de 5. Esto se debe a que el optimizador de consultas primero produce una serie plan (que solo puede ser ejecutado por un único subproceso) al compilar el plan para una consulta. Si el costo estimado de ese plan en serie excede el valor configurado de 'umbral de costo para el paralelismo', entonces se genera y almacena en caché un plan paralelo.
Sin embargo, ¿qué sucede si la opción sp_configure de 'umbral de costo para el paralelismo' no está configurada en el valor predeterminado de 5 y está configurada más alta? Es una práctica recomendada (y correcta) aumentar esta opción del valor predeterminado bajo de 5 a cualquier lugar de 25 a 50 (o incluso mucho más) para evitar que las consultas pequeñas incurran en la sobrecarga adicional de ir en paralelo.
EXEC sys.sp_configure N'show advanced options', N'1'; RECONFIGURE; GO EXEC sys.sp_configure N'cost threshold for parallelism', N'50'; RECONFIGURE; GO EXEC sys.sp_configure N'show advanced options', N'0'; RECONFIGURE; GO
Después de seguir las pautas de mejores prácticas y aumentar el "umbral de costo para el paralelismo" a 50, volver a ejecutar las consultas da como resultado el mismo plan de ejecución para GuidHighFragmentation tabla, pero GuidLowFragmentation el costo en serie de la consulta, 44,68, ahora está por debajo del valor del 'umbral de costo para el paralelismo' (recuerde que su costo paralelo estimado era 38,80), por lo que obtenemos un plan de ejecución en serie:
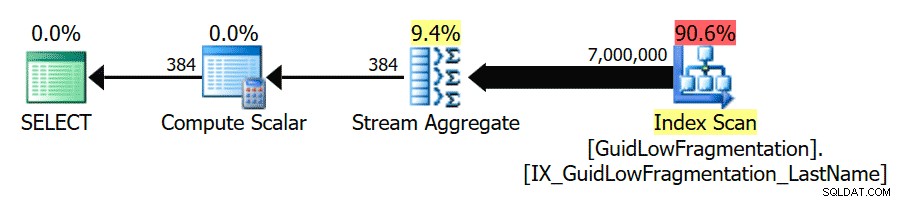
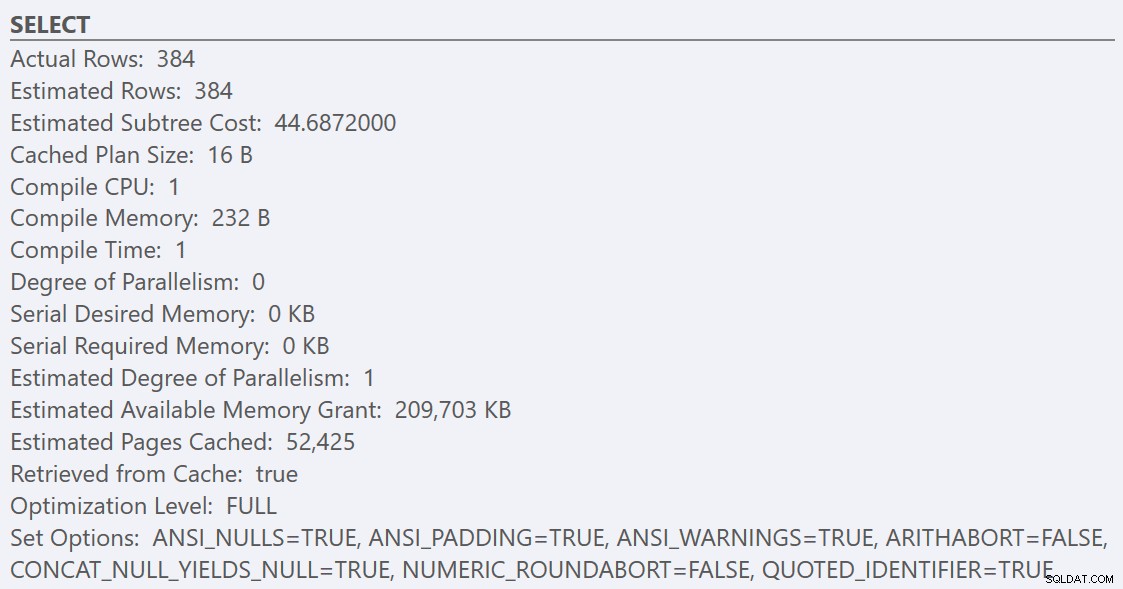
El espacio de página adicional en GuidHighFragmentation el índice agrupado mantuvo el costo por encima de la configuración de mejores prácticas para el "umbral de costo para el paralelismo" y dio como resultado un plan paralelo.
Ahora imagine que este era un sistema en el que siguió la guía de mejores prácticas e inicialmente configuró el 'umbral de costo para el paralelismo' en un valor de 50. Luego siguió el consejo erróneo de simplemente ignorar la fragmentación del índice por completo.
En lugar de ser una consulta básica, es más compleja, pero si también se ejecuta con mucha frecuencia en su sistema y, como resultado de la fragmentación del índice, el recuento de páginas inclina el costo hacia un plan paralelo, utilizará más CPU y afectar el rendimiento general de la carga de trabajo como resultado.
¿A qué te dedicas? ¿Aumenta el 'umbral de costo para el paralelismo' para que la consulta mantenga un plan de ejecución en serie? ¿Sugiere la consulta con OPCIÓN (MAXDOP 1) y simplemente la fuerza a un plan de ejecución en serie?
Tenga en cuenta que es probable que la fragmentación del índice no solo afecte una tabla en su base de datos, ahora que la está ignorando por completo; es probable que muchos índices agrupados y no agrupados estén fragmentados y tengan un recuento de páginas superior al necesario, por lo que los costos de muchas operaciones de E/S están aumentando como resultado de la fragmentación generalizada del índice, lo que genera potencialmente muchas consultas ineficientes. planes.
Resumen
No puede simplemente ignorar la fragmentación del índice por completo, como algunos quieren que crea. Entre otras desventajas de hacer esto, los costos acumulados de la ejecución de consultas lo alcanzarán, con cambios en el plan de consultas porque el optimizador de consultas es un optimizador basado en costos y, por lo tanto, considera que esos índices fragmentados son más costosos de utilizar.
Las consultas y el escenario aquí obviamente son artificiales, pero hemos visto cambios en el plan de ejecución causados por la fragmentación en la vida real en los sistemas cliente.
Debe asegurarse de abordar la fragmentación de índices para aquellos índices en los que la fragmentación provoca problemas de rendimiento de la carga de trabajo, independientemente del hardware que esté utilizando.