En la primera parte de esta serie, presenté la terminología básica sobre el registro, por lo que le recomiendo que lea eso antes de continuar con esta publicación. Todo lo demás que cubriré en la serie requiere conocer algo de la arquitectura del registro de transacciones, así que eso es lo que voy a discutir esta vez. Incluso si no va a seguir la serie, vale la pena conocer algunos de los conceptos que voy a explicar a continuación para las tareas diarias que manejan los DBA en producción.
Jerarquía estructural
El registro de transacciones está organizado internamente mediante una jerarquía de tres niveles, como se muestra en la figura 1 a continuación.
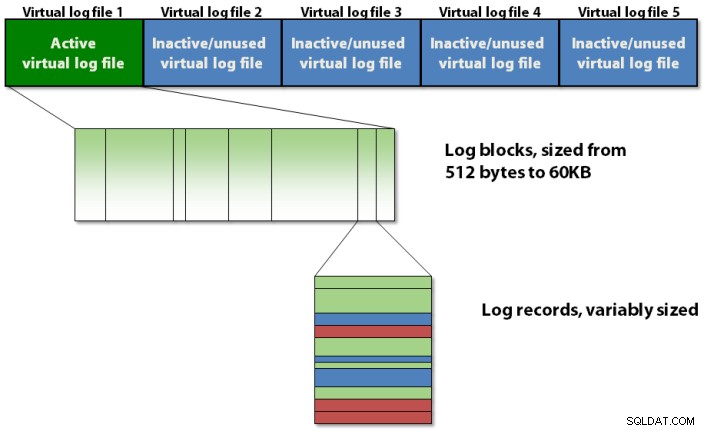 Figura 1:La jerarquía estructural de tres niveles del registro de transacciones
Figura 1:La jerarquía estructural de tres niveles del registro de transacciones
El registro de transacciones contiene archivos de registro virtuales, que contienen bloques de registro, que almacenan los registros de registro reales.
Archivos de registro virtuales
El registro de transacciones se divide en secciones denominadas archivos de registro virtuales , comúnmente llamados VLF . Esto se hace para que las operaciones de administración en el registro de transacciones sean más fáciles para el administrador de registros en SQL Server. No puede especificar cuántos VLF crea SQL Server cuando la base de datos se crea por primera vez o el archivo de registro crece automáticamente, pero puede influir en ello. El algoritmo de cuántos VLF se crean es el siguiente:
- Tamaño del archivo de registro inferior a 64 MB:cree 4 VLF, cada uno con un tamaño aproximado de 16 MB
- Tamaño del archivo de registro de 64 MB a 1 GB:cree 8 VLF, cada uno aproximadamente 1/8 del tamaño total
- Tamaño del archivo de registro superior a 1 GB:cree 16 VLF, cada uno aproximadamente 1/16 del tamaño total
Antes de SQL Server 2014, cuando el archivo de registro crece automáticamente, el algoritmo anterior determina la cantidad de VLF nuevos que se agregan al final del archivo de registro, según el tamaño de crecimiento automático. Sin embargo, con este algoritmo, si el tamaño de crecimiento automático es pequeño y el archivo de registro experimenta muchos crecimientos automáticos, puede generar una gran cantidad de VLF pequeños (llamados fragmentación de VLF). ) que puede ser un gran problema de rendimiento para algunas operaciones (ver aquí).
Debido a este problema, en SQL Server 2014, el algoritmo cambió para el crecimiento automático del archivo de registro. Si el tamaño de crecimiento automático es inferior a 1/8 del tamaño total del archivo de registro, solo se crea un VLF nuevo; de lo contrario, se utiliza el algoritmo antiguo. Esto reduce drásticamente la cantidad de VLF para un archivo de registro que ha experimentado una gran cantidad de crecimiento automático. Expliqué un ejemplo de la diferencia en esta publicación de blog.
Cada VLF tiene un número de secuencia que lo identifica de manera única y se usa en una variedad de lugares, que explicaré a continuación y en publicaciones futuras. Uno pensaría que los números de secuencia comenzarían en 1 para una base de datos completamente nueva, pero ese no es el caso.
En una instancia de SQL Server 2019, creé una nueva base de datos, sin especificar ningún tamaño de archivo, y luego verifiqué los VLF con el siguiente código:
CREATE DATABASE NewDB;
GO
SELECT
[file_id],
[vlf_begin_offset],
[vlf_size_mb],
[vlf_sequence_number]
FROM
sys.dm_db_log_info (DB_ID (N'NewDB'));
Tenga en cuenta el sys.dm_db_log_info DMV se agregó en SQL Server 2016 SP2. Antes de eso (y hoy, porque todavía existe) puede usar el DBCC LOGINFO no documentado comando, pero no puede darle una lista de selección, solo haga DBCC LOGINFO(N'NewDB'); y los números de secuencia VLF están en FSeqNo columna del conjunto de resultados.
De todos modos, los resultados de consultar sys.dm_db_log_info fueron:
file_id vlf_begin_offset vlf_size_mb vlf_sequence_number ------- ---------------- ----------- ------------------- 2 8192 1.93 37 2 2039808 1.93 0 2 4071424 1.93 0 2 6103040 2.17 0
Tenga en cuenta que el primer VLF comienza en el desplazamiento de 8192 bytes en el archivo de registro. Esto se debe a que todos los archivos de la base de datos, incluido el registro de transacciones, tienen una página de encabezado de archivo que ocupa los primeros 8 KB y almacena varios metadatos sobre el archivo.
Entonces, ¿por qué SQL Server elige 37 y no 1 para el primer número de secuencia VLF? Encuentra el número de secuencia VLF más alto en el model base de datos y luego, para cualquier base de datos nueva, el primer VLF del registro de transacciones usa ese número más 1 para su número de secuencia. No sé por qué se eligió este algoritmo en la noche de los tiempos, pero ha sido así desde al menos SQL Server 7.0.
Para probarlo, ejecuté este código:
SELECT
MAX ([vlf_sequence_number]) AS [Max_VLF_SeqNo]
FROM
sys.dm_db_log_info (DB_ID (N'model')); Y los resultados fueron:
Max_VLF_SeqNo -------------------- 36
Así que ahí lo tienes.
Hay más para discutir sobre los VLF y cómo se usan, pero por ahora es suficiente saber que cada VLF tiene un número de secuencia, que aumenta en uno para cada VLF.
Bloques de registro
Cada VLF contiene un pequeño encabezado de metadatos y el resto del espacio se llena con bloques de registro. Cada bloque de registro comienza con 512 bytes y crecerá en incrementos de 512 bytes hasta un tamaño máximo de 60 KB, momento en el que debe escribirse en el disco. Un bloque de registro puede escribirse en el disco antes de que alcance su tamaño máximo si ocurre uno de los siguientes:
- Se confirma una transacción y no se utiliza la durabilidad retrasada para esta transacción, por lo que el bloque de registro debe escribirse en el disco para que la transacción sea duradera
- La durabilidad retrasada está en uso y se activa la tarea del temporizador de 1 ms "vaciar el bloque de registro actual en el disco"
- Una página de archivo de datos se está escribiendo en el disco mediante un punto de control o el escritor diferido, y hay uno o más registros en el bloque de registro actual que afectan a la página que está a punto de escribirse (recuerde que el registro de escritura anticipada debe ser garantizado)
Puede considerar un bloque de registro como algo así como una página de tamaño variable que almacena registros en el orden en que son creados por transacciones que cambian la base de datos. No hay un bloque de registro para cada transacción; los registros de registro para múltiples transacciones simultáneas se pueden entremezclar en un bloque de registro. Puede pensar que esto presentaría dificultades para las operaciones que necesitan encontrar todos los registros de registro para una sola transacción, pero no es así, como explicaré cuando cubra cómo funcionan las reversiones de transacciones en una publicación posterior.
Además, cuando un bloque de registro se escribe en el disco, es muy posible que contenga registros de transacciones no confirmadas. Esto tampoco es un problema debido a la forma en que funciona la recuperación de fallas, que es una buena cantidad de publicaciones en el futuro de la serie.
Números de secuencia de registro
Los bloques de registro tienen una ID dentro de un VLF, comenzando en 1 y aumentando en 1 por cada nuevo bloque de registro en el VLF. Los registros de registro también tienen una identificación dentro de un bloque de registro, comenzando en 1 y aumentando en 1 por cada nuevo registro de registro en el bloque de registro. Por lo tanto, los tres elementos en la jerarquía estructural del registro de transacciones tienen una identificación y se juntan en un identificador tripartito llamado número de secuencia de registro. , más comúnmente conocido simplemente como LSN .
Un LSN se define como <VLF sequence number>:<log block ID>:<log record ID> (4 bytes:4 bytes:2 bytes) e identifica de forma única un único registro. Es un identificador cada vez mayor, porque los números de secuencia VLF aumentan para siempre.
¡Trabajo hecho!
Si bien es importante conocer los VLF, en mi opinión, el LSN es el concepto más importante para comprender la implementación del registro de SQL Server, ya que los LSN son la piedra angular sobre la cual se construyen la reversión de transacciones y la recuperación de fallas, y los LSN aparecerán una y otra vez como Progreso a través de la serie. En la próxima publicación, cubriré el truncamiento de registros y la naturaleza circular del registro de transacciones, que tiene que ver con los VLF y cómo se reutilizan.



