Lo primero que se me ocurre es que tengo una solución al 50 % para ti.
El problema
SSIS de verdad se preocupa por los metadatos, por lo que sus variaciones tienden a dar lugar a excepciones. DTS fue mucho más indulgente en este sentido. Esa fuerte necesidad de metadatos consistentes hace que el uso de Flat File Source sea problemático.
Solución basada en consultas
Si el problema es el componente, no lo usemos. Lo que me gusta de este enfoque es que, conceptualmente, es lo mismo que consultar una tabla:el orden de las columnas no importa ni la presencia de columnas adicionales.
Variables
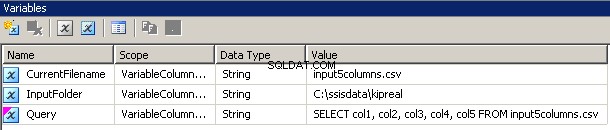
Creé 3 variables, todas de tipo cadena:CurrentFileName, InputFolder y Query.
- InputFolder está conectado a la carpeta de origen. En mi ejemplo, es
C:\ssisdata\Kipreal - CurrentFileName es el nombre de un archivo. Durante el tiempo de diseño, era
input5columns.csvpero eso cambiará en tiempo de ejecución. - La consulta es una expresión
"SELECT col1, col2, col3, col4, col5 FROM " + @[User::CurrentFilename]
Administrador de conexiones
Configure una conexión con el archivo de entrada mediante el controlador JET OLEDB. Después de crearlo como se describe en el artículo vinculado, le cambié el nombre a FileOLEDB y establecí una expresión en ConnectionManager de "Data Source=" + @[User::InputFolder] + ";Provider=Microsoft.Jet.OLEDB.4.0;Extended Properties=\"text;HDR=Yes;FMT=CSVDelimited;\";"
Flujo de control
Mi flujo de control parece una tarea de flujo de datos anidada en un enumerador de archivos Foreach
Enumerador de archivos Foreach
Mi enumerador de archivos Foreach está configurado para operar en archivos. Puse una expresión en el Directorio para @[User::InputFolder] Tenga en cuenta que en este punto, si el valor de esa carpeta necesita cambiar, se actualizará correctamente tanto en el Administrador de conexiones como en el enumerador de archivos. En "Recuperar nombre de archivo", en lugar de "Totalmente calificado" predeterminado, elija "Nombre y extensión"
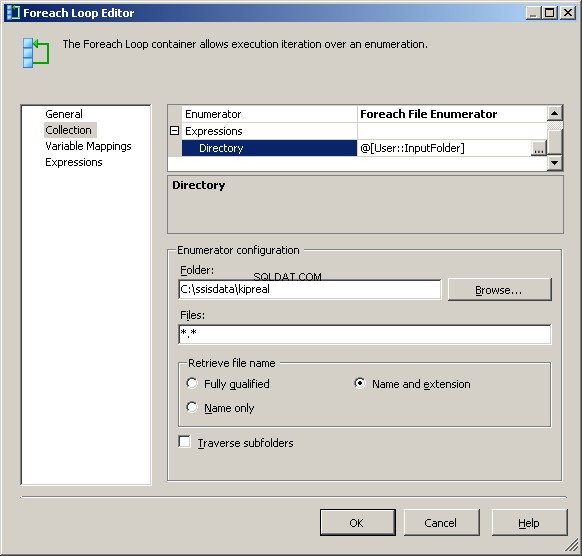
En la pestaña Asignaciones de variables, asigne el valor a nuestro @[User::CurrentFileName] variables
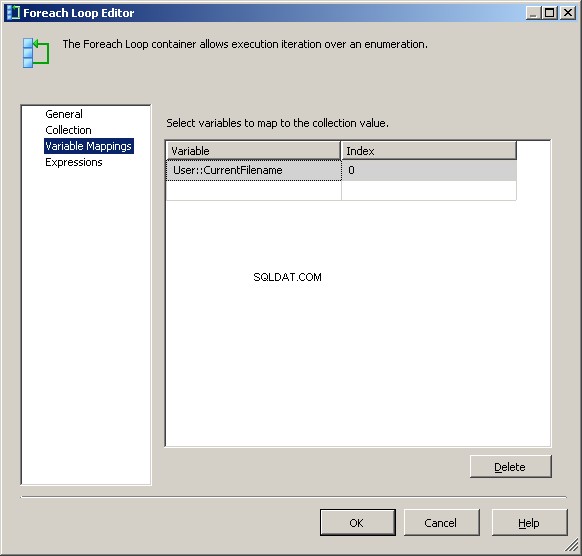
En este punto, cada iteración del bucle cambiará el valor de @[User::Query para reflejar el nombre del archivo actual.
Flujo de datos
Esta es en realidad la pieza más fácil. Use una fuente OLE DB y conéctela como se indica.
Use el administrador de conexión FileOLEDB y cambie el modo de acceso a datos a "Comando SQL desde variable". Utilice el @[User::Query] variable allí, haga clic en Aceptar y estará listo para trabajar. 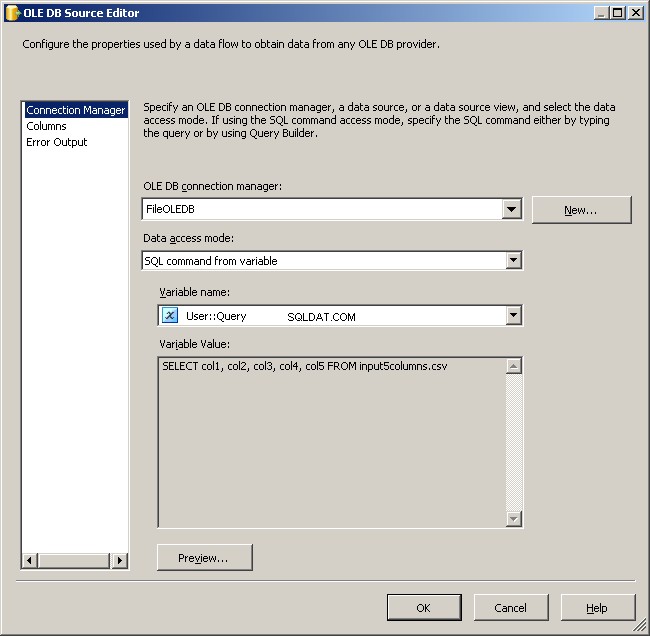
Datos de muestra
Creé dos archivos de muestra input5columns.csv y input7columns.csv Todas las columnas de 5 están en 7 pero 7 las tiene en un orden diferente (col2 es la posición ordinal 2 y 6). Negué todos los valores en 7 para que sea evidente en qué archivo se está operando.
col1,col3,col2,col5,col4
1,3,2,5,4
1111,3333,2222,5555,4444
11,33,22,55,44
111,333,222,555,444
y
col1,col3,col7,col5,col4,col6,col2
-1111,-3333,-7777,-5555,-4444,-6666,-2222
-111,-333,-777,-555,-444,-666,-222
-1,-3,-7,-5,-4,-6,-2
-11,-33,-77,-55,-44,-666,-222
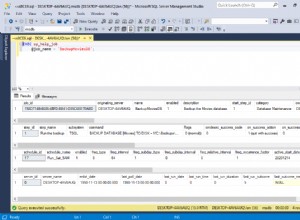
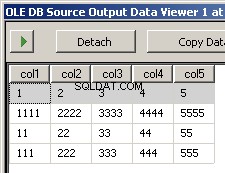
Ejecutar el paquete da como resultado estas dos capturas de pantalla
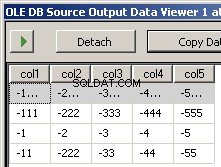
Lo que falta
No conozco una forma de decirle al enfoque basado en consultas que está bien si no existe una columna. Si hay una clave única, supongo que podría definir su consulta para tener solo las columnas que deben estar allí y luego realizar búsquedas en el archivo para tratar de obtener las columnas que deben para estar allí y no fallar en la búsqueda si la columna no existe. Aunque bastante chapucero.