Las bases de datos están diseñadas de diferentes maneras. La mayoría de las veces podemos usar "ejemplos escolares":normalice la base de datos y todo funcionará bien. Pero hay situaciones que requerirán otro enfoque. Podemos eliminar referencias para ganar más flexibilidad. Pero, ¿y si tenemos que mejorar el rendimiento cuando todo se hizo al pie de la letra? En ese caso, la desnormalización es una técnica que debemos considerar. En este artículo, analizaremos las ventajas y desventajas de la desnormalización y qué situaciones pueden justificarla.
¿Qué es la desnormalización?
La desnormalización es una estrategia utilizada en una base de datos previamente normalizada para aumentar el rendimiento. La idea detrás de esto es agregar datos redundantes donde creemos que nos ayudarán más. Podemos usar atributos adicionales en una tabla existente, agregar nuevas tablas o incluso crear instancias de tablas existentes. El objetivo habitual es reducir el tiempo de ejecución de las consultas seleccionadas haciendo que los datos sean más accesibles para las consultas o generando informes resumidos en tablas separadas. Este proceso puede traer algunos problemas nuevos, y los discutiremos más adelante.
Una base de datos normalizada es el punto de partida para el proceso de desnormalización. Es importante diferenciar la base de datos que no ha sido normalizada y la base de datos que fue normalizada primero y luego desnormalizada más tarde. El segundo está bien; el primero es a menudo el resultado de un mal diseño de la base de datos o falta de conocimiento.
Ejemplo:un modelo normalizado para un CRM muy simple
El siguiente modelo servirá como nuestro ejemplo:
Echemos un vistazo rápido a las tablas:
- La
user_accountLa tabla almacena datos sobre los usuarios que inician sesión en nuestra aplicación (simplificando el modelo, los roles y los derechos de los usuarios están excluidos). - El
clientLa tabla contiene algunos datos básicos sobre nuestros clientes. - El
productla tabla enumera los productos ofrecidos a nuestros clientes. - La
taskLa tabla contiene todas las tareas que hemos creado. Puede pensar en cada tarea como un conjunto de acciones relacionadas con los clientes. Cada tarea tiene sus llamadas, reuniones y listas de productos ofrecidos y vendidos relacionados. - La
callymeetinglas tablas almacenan datos sobre todas las llamadas y reuniones y los relacionan con tareas y usuarios. - Los diccionarios
task_outcome,meeting_outcomeycall_outcomecontener todas las opciones posibles para el estado final de una tarea, reunión o llamada. - El
product_offeredalmacena una lista de todos los productos que se ofrecieron a los clientes en ciertas tareas mientrasproduct_soldcontiene una lista de todos los productos que el cliente realmente compró. - El
supply_orderLa tabla almacena datos sobre todos los pedidos que hemos realizado y losproducts_on_orderla tabla enumera los productos y su cantidad para pedidos específicos. - La
writeoffLa tabla es una lista de productos que se cancelaron debido a accidentes o similares (por ejemplo, espejos rotos).
La base de datos está simplificada pero perfectamente normalizada. No encontrará redundancias y debería hacer el trabajo. No deberíamos experimentar ningún problema de rendimiento en ningún caso, siempre que trabajemos con una cantidad de datos relativamente pequeña.
Cuándo y por qué usar la desnormalización
Como con casi cualquier cosa, debe estar seguro de por qué desea aplicar la desnormalización. También debe asegurarse de que la ganancia de usarlo supere cualquier daño. Hay algunas situaciones en las que definitivamente debería pensar en la desnormalización:
- Historial de mantenimiento: Los datos pueden cambiar con el tiempo y necesitamos almacenar valores que eran válidos cuando se creó un registro. ¿A qué tipo de cambios nos referimos? Bueno, el nombre y apellido de una persona pueden cambiar; un cliente también puede cambiar su razón social o cualquier otro dato. Los detalles de la tarea deben contener valores que eran reales en el momento en que se generó una tarea. No podríamos recrear correctamente los datos anteriores si esto no sucediera. Podríamos resolver este problema agregando una tabla que contuviera el historial de estos cambios. En ese caso, una consulta de selección que devuelva la tarea y un nombre de cliente válido sería más complicada. Tal vez una mesa extra no sea la mejor solución.
- Mejorar el rendimiento de las consultas: Algunas de las consultas pueden usar varias tablas para acceder a los datos que necesitamos con frecuencia. Piense en una situación en la que necesitaríamos unir 10 mesas para devolver el nombre del cliente y los productos que se le vendieron. Algunas tablas a lo largo de la ruta también podrían contener grandes cantidades de datos. En ese caso, tal vez sería conveniente agregar un
client_idatribuir directamente a losproducts_soldmesa. - Aceleración de los informes: Necesitamos ciertas estadísticas con mucha frecuencia. Crearlos a partir de datos en vivo requiere bastante tiempo y puede afectar el rendimiento general del sistema. Digamos que queremos realizar un seguimiento de las ventas de los clientes durante ciertos años para algunos o todos los clientes. La generación de dichos informes a partir de datos en vivo "excavaría" casi toda la base de datos y la ralentizaría mucho. ¿Y qué sucede si usamos esa estadística con frecuencia?
- Cálculo de valores comúnmente necesarios por adelantado: Queremos tener algunos valores calculados para no tener que generarlos en tiempo real.
Es importante señalar que no necesita usar la desnormalización si no hay problemas de rendimiento En la aplicacion. Pero si nota que el sistema se está ralentizando, o si sabe que esto podría suceder, entonces debería pensar en aplicar esta técnica. Sin embargo, antes de hacerlo, considere otras opciones, como la optimización de consultas y la indexación adecuada. También puede usar la desnormalización si ya está en producción, pero es mejor resolver los problemas en la fase de desarrollo.
¿Cuáles son las desventajas de la desnormalización?
Obviamente, la mayor ventaja del proceso de desnormalización es un mayor rendimiento. Pero tenemos que pagar un precio por ello, y ese precio puede consistir en:
- Espacio en disco: Esto es de esperar, ya que tendremos datos duplicados.
- Anomalías de datos: Tenemos que ser muy conscientes de que los datos ahora se pueden cambiar en más de un lugar. Debemos ajustar cada pieza de datos duplicados en consecuencia. Eso también se aplica a los valores e informes calculados. Podemos lograr esto mediante el uso de disparadores, transacciones y/o procedimientos para todas las operaciones que deben completarse juntas.
- Documentación: Debemos documentar adecuadamente cada regla de desnormalización que hayamos aplicado. Si modificamos el diseño de la base de datos más adelante, tendremos que mirar todas nuestras excepciones y tenerlas en cuenta una vez más. Tal vez ya no los necesitemos porque hemos resuelto el problema. O tal vez necesitamos agregar a las reglas de desnormalización existentes. (Por ejemplo:agregamos un nuevo atributo a la tabla del cliente y queremos almacenar su valor de historial junto con todo lo que ya almacenamos. Tendremos que cambiar las reglas de desnormalización existentes para lograrlo).
- Ralentización de otras operaciones: Podemos esperar que reduzcamos la velocidad de las operaciones de inserción, modificación y eliminación de datos. Si estas operaciones ocurren relativamente raramente, esto podría ser un beneficio. Básicamente, dividiríamos una selección lenta en un mayor número de consultas de inserción/actualización/eliminación más lentas. Si bien una consulta de selección muy compleja técnicamente podría ralentizar notablemente todo el sistema, ralentizar múltiples operaciones "pequeñas" no debería dañar la usabilidad de nuestra aplicación.
- Más codificación: Las reglas 2 y 3 requerirán codificación adicional, pero al mismo tiempo simplificarán mucho algunas consultas de selección. Si estamos desnormalizando una base de datos existente, tendremos que modificar estas consultas de selección para obtener los beneficios de nuestro trabajo. También tendremos que actualizar los valores en los atributos recién agregados para los registros existentes. Esto también requerirá un poco más de codificación.
El modelo de ejemplo, desnormalizado
En el modelo a continuación, apliqué algunas de las reglas de desnormalización antes mencionadas. Las mesas rosas se han modificado, mientras que la mesa azul claro es completamente nueva.
¿Qué cambios se aplican y por qué?

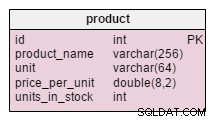
El único cambio en el product tabla es la suma de las units_in_stock atributo. En un modelo normalizado, podríamos calcular estos datos como unidades pedidas – unidades vendidas – (unidades ofrecidas) – unidades canceladas . Repetiríamos el cálculo cada vez que un cliente pida ese producto, lo que llevaría mucho tiempo. En cambio, calcularemos el valor por adelantado; cuando un cliente nos lo pida, lo tendremos listo. Por supuesto, esto simplifica mucho la consulta de selección. Por otro lado, las units_in_stock el atributo debe ajustarse después de cada inserción, actualización o eliminación en products_on_order , writeoff , product_offered y product_sold mesas.
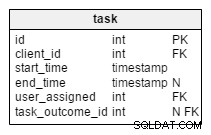
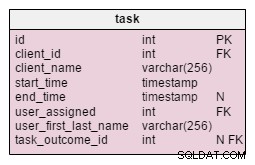
En la task tabla, encontramos dos nuevos atributos:client_name y user_first_last_name . Ambos almacenan valores cuando se creó la tarea. La razón es que ambos valores pueden cambiar con el tiempo. También mantendremos una clave externa que los relacione con el cliente original y la ID de usuario. Hay más valores que nos gustaría almacenar, como la dirección del cliente, el ID de IVA, etc.




El product_offered la tabla tiene dos atributos nuevos, price_per_unit y price . El price_per_unit El atributo se almacena porque necesitamos almacenar el precio real cuando se ofreció el producto . El modelo normalizado solo mostraría su estado actual, por lo que cuando el precio del producto cambie, nuestros precios de "historial" también cambiarán. Nuestro cambio no solo hace que la base de datos se ejecute más rápido:también hace que funcione mejor. El price atributo es el valor calculado units_sold * price_per_unit . Lo agregué aquí para evitar hacer ese cálculo cada vez que queremos echar un vistazo a una lista de productos ofrecidos. Es un costo pequeño, pero mejora el rendimiento.
Los cambios realizados en el product_sold mesa son muy similares. La estructura de la tabla es la misma, pero almacena una lista de artículos vendidos.
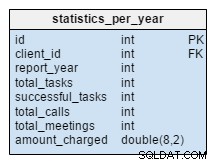
Las statistics_per_year La mesa es completamente nueva para nuestro modelo. Deberíamos verlo como una tabla desnormalizada porque todos sus datos se pueden calcular a partir de las otras tablas. La idea detrás de esta tabla es almacenar la cantidad de tareas, tareas exitosas, reuniones y llamadas relacionadas con un cliente determinado. También maneja la suma total cobrada por cada año. Después de insertar, actualizar o eliminar algo en la task , meeting , call y product_sold tablas, debemos recalcular los datos de esta tabla para ese cliente y año correspondiente. Podemos esperar que en su mayoría tengamos cambios solo para el año en curso. Los informes de años anteriores no deberían cambiar.
Los valores de esta tabla se calculan por adelantado, por lo que gastaremos menos tiempo y recursos en el momento en que necesitemos el resultado del cálculo. Piense en los valores que necesitará con frecuencia. Tal vez no los necesite todos regularmente y puede correr el riesgo de calcular algunos de ellos en vivo.
La desnormalización es un concepto muy interesante y poderoso. Aunque no es lo primero que debe tener en cuenta para mejorar el rendimiento, en algunas situaciones puede ser la mejor o incluso la única solución.
Antes de elegir usar la desnormalización, asegúrese de que la desea. Haga un poco de análisis y realice un seguimiento del rendimiento. Probablemente decida ir con la desnormalización después de que ya se haya puesto en marcha. No tenga miedo de usarlo, pero haga un seguimiento de los cambios y no debería experimentar ningún problema (es decir, las temidas anomalías de datos).



