La paginación es un caso de uso común en aplicaciones cliente y web en todas partes. Google le muestra 10 resultados a la vez, su banco en línea puede mostrar 20 facturas por página y el software de seguimiento de errores y control de fuente puede mostrar 50 elementos en la pantalla.
Quería ver el enfoque de paginación común en SQL Server 2012:OFFSET / FETCH (un estándar equivalente a la cláusula LIMIT de propiedad de MySQL), y sugerir una variación que conducirá a un rendimiento de paginación más lineal en todo el conjunto, en lugar de solo ser óptimo. al principio. Que, lamentablemente, es todo lo que probarán muchas tiendas.
¿Qué es la paginación en SQL Server?
Según la indexación de la tabla, las columnas necesarias y el método de clasificación elegido, la paginación puede ser relativamente sencilla. Si está buscando los "primeros" 20 clientes y el índice agrupado admite esa clasificación (por ejemplo, un índice agrupado en una columna IDENTIDAD o una columna Fecha de creación), entonces la consulta será relativamente eficiente. Si necesita admitir la clasificación que requiere índices no agrupados, y especialmente si tiene columnas necesarias para la salida que no están cubiertas por el índice (no importa si no hay un índice de soporte), las consultas pueden ser más costosas. E incluso la misma consulta (con un parámetro @PageNumber diferente) puede volverse mucho más costosa a medida que el @PageNumber aumenta, ya que es posible que se requieran más lecturas para llegar a esa "porción" de los datos.
Algunos dirán que progresar hacia el final del conjunto es algo que puede resolver lanzando más memoria al problema (para eliminar cualquier E/S física) y/o usando el almacenamiento en caché a nivel de aplicación (para que no vaya a la base de datos en absoluto). Supongamos para los propósitos de esta publicación que no siempre es posible tener más memoria, ya que no todos los clientes pueden agregar RAM a un servidor que no tiene ranuras de memoria o no está bajo su control, o simplemente chasquear los dedos y tener servidores más nuevos y más grandes listos. ir. Especialmente porque algunos clientes tienen la Edición estándar, por lo que tienen un límite de 64 GB (SQL Server 2012) o 128 GB (SQL Server 2014), o están usando ediciones aún más limitadas, como Express (1 GB) o una de las muchas ofertas en la nube.
Por lo tanto, quería ver el enfoque de paginación común en SQL Server 2012, OFFSET / FETCH, y sugerir una variación que conducirá a un rendimiento de paginación más lineal en todo el conjunto, en lugar de ser óptimo solo al principio. Que, lamentablemente, es todo lo que probarán muchas tiendas.
Configuración de datos de paginación/Ejemplo
Voy a tomar prestado de otra publicación, Malos hábitos:Centrarse solo en el espacio en disco al elegir claves, donde completé la siguiente tabla con 1,000,000 filas de datos de clientes aleatorios (pero no del todo realistas):
CREATE TABLE [dbo].[Customers_I] ( [CustomerID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT ((1)), [Created] [datetime] NOT NULL DEFAULT (sysdatetime()), [Updated] [datetime] NULL, CONSTRAINT [C_PK_Customers_I] PRIMARY KEY CLUSTERED ([CustomerID] ASC) ); GO CREATE NONCLUSTERED INDEX [C_Active_Customers_I] ON [dbo].[Customers_I] ([FirstName] ASC, [LastName] ASC, [EMail] ASC) WHERE ([Active] = 1); GO CREATE UNIQUE NONCLUSTERED INDEX [C_Email_Customers_I] ON [dbo].[Customers_I] ([EMail] ASC); GO CREATE NONCLUSTERED INDEX [C_Name_Customers_I] ON [dbo].[Customers_I] ([LastName] ASC, [FirstName] ASC) INCLUDE ([EMail]); GO
Como sabía que probaría E/S aquí, y probaría tanto desde una memoria caché tibia como fría, hice la prueba al menos un poco más justa al reconstruir todos los índices para minimizar la fragmentación (como se haría menos de manera disruptiva, pero regular, en la mayoría de los sistemas ocupados que realizan cualquier tipo de mantenimiento de índice):
ALTER INDEX ALL ON dbo.Customers_I REBUILD WITH (ONLINE = ON);
Después de la reconstrucción, la fragmentación llega ahora al 0,05 % - 0,17 % para todos los índices (nivel de índice =0), las páginas se llenan en más del 99 % y el número de filas/número de páginas para los índices es el siguiente:
| Índice | Recuento de páginas | Recuento de filas |
|---|---|---|
| C_PK_Customers_I (índice agrupado) | 19,210 | 1,000,000 |
| C_Email_Clientes_I | 7344 | 1,000,000 |
| C_Active_Customers_I (índice filtrado) | 13.648 | 815.235 |
| C_Nombre_Clientes_I | 16.824 | 1,000,000 |
Índices, recuentos de páginas, recuentos de filas
Obviamente, esta no es una tabla súper ancha, y esta vez dejé la compresión fuera de la imagen. Quizás exploraré más configuraciones en una prueba futura.
Cómo paginar efectivamente una consulta SQL
El concepto de paginación (mostrar al usuario solo filas a la vez) es más fácil de visualizar que de explicar. Piense en el índice de un libro físico, que puede tener varias páginas de referencias a puntos dentro del libro, pero organizadas alfabéticamente. Para simplificar, digamos que caben diez elementos en cada página del índice. Esto podría verse así:
Ahora, si ya he leído las páginas 1 y 2 del índice, sé que para llegar a la página 3, necesito saltarme 2 páginas. Pero como sé que hay 10 elementos en cada página, también puedo pensar en esto como saltar 2 x 10 elementos y comenzar con el elemento 21. O, dicho de otro modo, necesito omitir los primeros (10*(3-1)) elementos. Para hacer esto más genérico, puedo decir que para comenzar en la página n, necesito omitir los primeros (10 * (n-1)) elementos. Para llegar a la primera página, omito 10*(1-1) elementos, para terminar en el elemento 1. Para llegar a la segunda página, omito 10*(2-1) elementos, para terminar en el elemento 11. Y así activado.
Con esa información, los usuarios formularán una consulta de paginación como esta, dado que las cláusulas OFFSET / FETCH agregadas en SQL Server 2012 fueron diseñadas específicamente para saltar tantas filas:
SELECT [a_bunch_of_columns] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY;
Como mencioné anteriormente, esto funciona bien si hay un índice que admita ORDER BY y que cubra todas las columnas en la cláusula SELECT (y, para consultas más complejas, las cláusulas WHERE y JOIN). Sin embargo, los costos de clasificación pueden ser abrumadores sin un índice de respaldo, y si las columnas de salida no están cubiertas, terminará con un montón de búsquedas clave o incluso puede obtener un escaneo de tabla en algunos escenarios.
Ordenar las mejores prácticas de paginación SQL
Dada la tabla y los índices anteriores, quería probar estos escenarios, donde queremos mostrar 100 filas por página y mostrar todas las columnas de la tabla:
- Predeterminado –
ORDER BY CustomerID(índice agrupado). Este es el orden más conveniente para la gente de la base de datos, ya que no requiere clasificación adicional, y se incluyen todos los datos de esta tabla que posiblemente se necesiten para la visualización. Por otro lado, este podría no ser el índice más eficiente para usar si está mostrando un subconjunto de la tabla. Es posible que el pedido no tenga sentido para los usuarios finales, especialmente si CustomerID es un identificador sustituto sin significado externo. - Guía telefónica –
ORDER BY LastName, FirstName(compatible con el índice no agrupado). Esta es la ordenación más intuitiva para los usuarios, pero requeriría un índice no agrupado para admitir tanto la clasificación como la cobertura. Sin un índice de apoyo, habría que escanear toda la tabla. - Definido por el usuario –
ORDER BY FirstName DESC, EMail(sin índice de apoyo). Esto representa la capacidad del usuario de elegir el orden de clasificación que desee, un patrón sobre el que advierte Michael J. Swart en "Patrones de diseño de interfaz de usuario que no escalan".
Quería probar estos métodos y comparar planes y métricas cuando, tanto en escenarios de caché tibia como de caché fría, miraba la página 1, la página 500, la página 5000 y la página 9999. Creé estos procedimientos (que difieren solo por la cláusula ORDER BY):
CREATE PROCEDURE dbo.Pagination_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Pagination_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Pagination_Test_3 -- ORDER BY FirstName DESC, EMail En realidad, probablemente solo tendrá un procedimiento que use SQL dinámico (como en mi ejemplo de "fregadero de cocina") o una expresión CASE para dictar el orden.
En cualquier caso, puede obtener mejores resultados si usa OPCIÓN (RECOMPILAR) en la consulta para evitar la reutilización de planes que son óptimos para una opción de clasificación, pero no para todas. Creé procedimientos separados aquí para eliminar esas variables; Agregué OPCIÓN (RECOMPILAR) para que estas pruebas se mantuvieran alejadas de la detección de parámetros y otros problemas de optimización sin vaciar todo el caché del plan repetidamente.
Un enfoque alternativo a la paginación de SQL Server para un mejor rendimiento
Un enfoque ligeramente diferente, que no veo implementado muy a menudo, es ubicar la "página" en la que estamos usando solo la clave de agrupación y luego unirla:
;WITH pg AS ( SELECT [key_column] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT t.[bunch_of_columns] FROM dbo.[some_table] AS t INNER JOIN pg ON t.[key_column] = pg.[key_column] -- or EXISTS ORDER BY [some_column_or_columns];
Es un código más detallado, por supuesto, pero es de esperar que quede claro lo que se puede obligar a SQL Server a hacer:evitar un escaneo, o al menos aplazar las búsquedas hasta que se reduzca un conjunto de resultados mucho más pequeño. Paul White (@SQL_Kiwi) investigó un enfoque similar en 2010, antes de que se introdujera OFFSET/FETCH en las primeras versiones beta de SQL Server 2012 (la primera vez que escribí en un blog ese mismo año).
Dados los escenarios anteriores, creé tres procedimientos más, con la única diferencia entre las columnas especificadas en las cláusulas ORDER BY (ahora necesitamos dos, una para la página en sí y otra para ordenar el resultado):
CREATE PROCEDURE dbo.Alternate_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
;WITH pg AS
(
SELECT CustomerID
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.Customers_I AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY c.CustomerID OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Alternate_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Alternate_Test_3 -- ORDER BY FirstName DESC, EMail Nota:Es posible que esto no funcione tan bien si su clave principal no está agrupada; parte del truco que hace que esto funcione mejor, cuando se puede usar un índice de soporte, es que la clave de agrupamiento ya está en el índice, por lo que un a menudo se evita la búsqueda.
Prueba de clasificación de claves de agrupación
Primero probé el caso en el que no esperaba mucha variación entre los dos métodos:clasificación por clave de agrupación. Ejecuté estas declaraciones en un lote en SQL Sentry Plan Explorer y observé la duración, las lecturas y los planes gráficos, asegurándome de que cada consulta comenzara desde un caché completamente frío:
SET NOCOUNT ON; -- default method DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 9999; -- alternate method DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 9999;
Los resultados aquí no fueron asombrosos. Más de 5 ejecuciones, el número promedio de lecturas se muestra aquí, mostrando diferencias insignificantes entre las dos consultas, en todos los números de página, al ordenar por la clave de agrupación:
El plan para el método predeterminado (como se muestra en Plan Explorer) en todos los casos fue el siguiente:
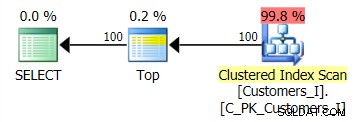
Mientras que el plan para el método basado en CTE se veía así:
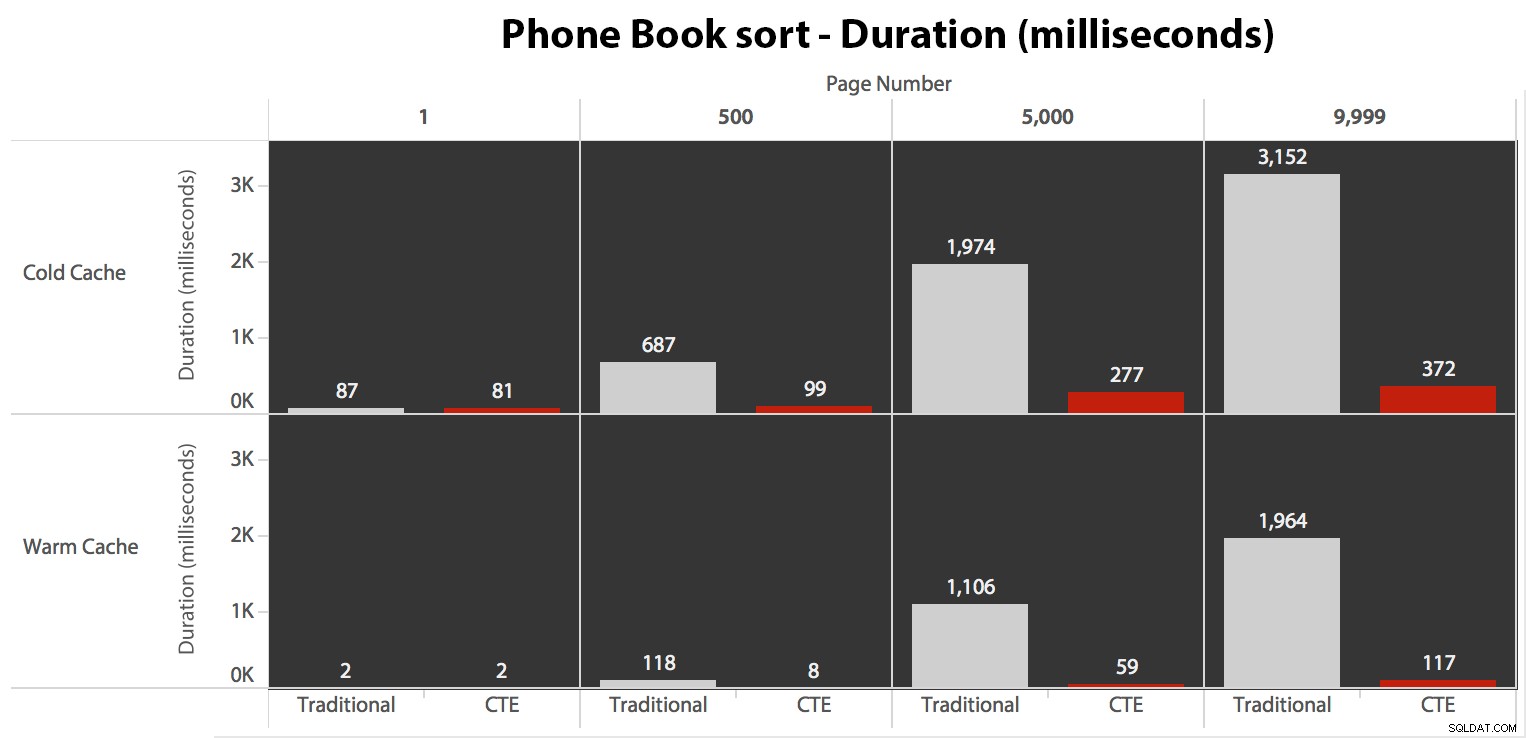
Ahora, aunque la E/S fue la misma independientemente del almacenamiento en caché (solo muchas más lecturas anticipadas en el escenario de caché en frío), medí la duración con un caché en frío y también con un caché en caliente (donde comenté los comandos DROPCLEANBUFFERS y ejecutó las consultas varias veces antes de medir). Estas duraciones se veían así:
Si bien puede ver un patrón que muestra que la duración aumenta a medida que aumenta el número de página, tenga en cuenta la escala:para llegar a las filas 999 801 -> 999 900, estamos hablando de medio segundo en el peor de los casos y 118 milisegundos en el mejor de los casos. El enfoque CTE gana, pero no por mucho.
Probar la ordenación de la guía telefónica
A continuación, probé el segundo caso, en el que la clasificación estaba respaldada por un índice sin cobertura en LastName, FirstName. La consulta anterior acaba de cambiar todas las instancias de Test_1 a Test_2 . Aquí estaban las lecturas usando un caché frío:
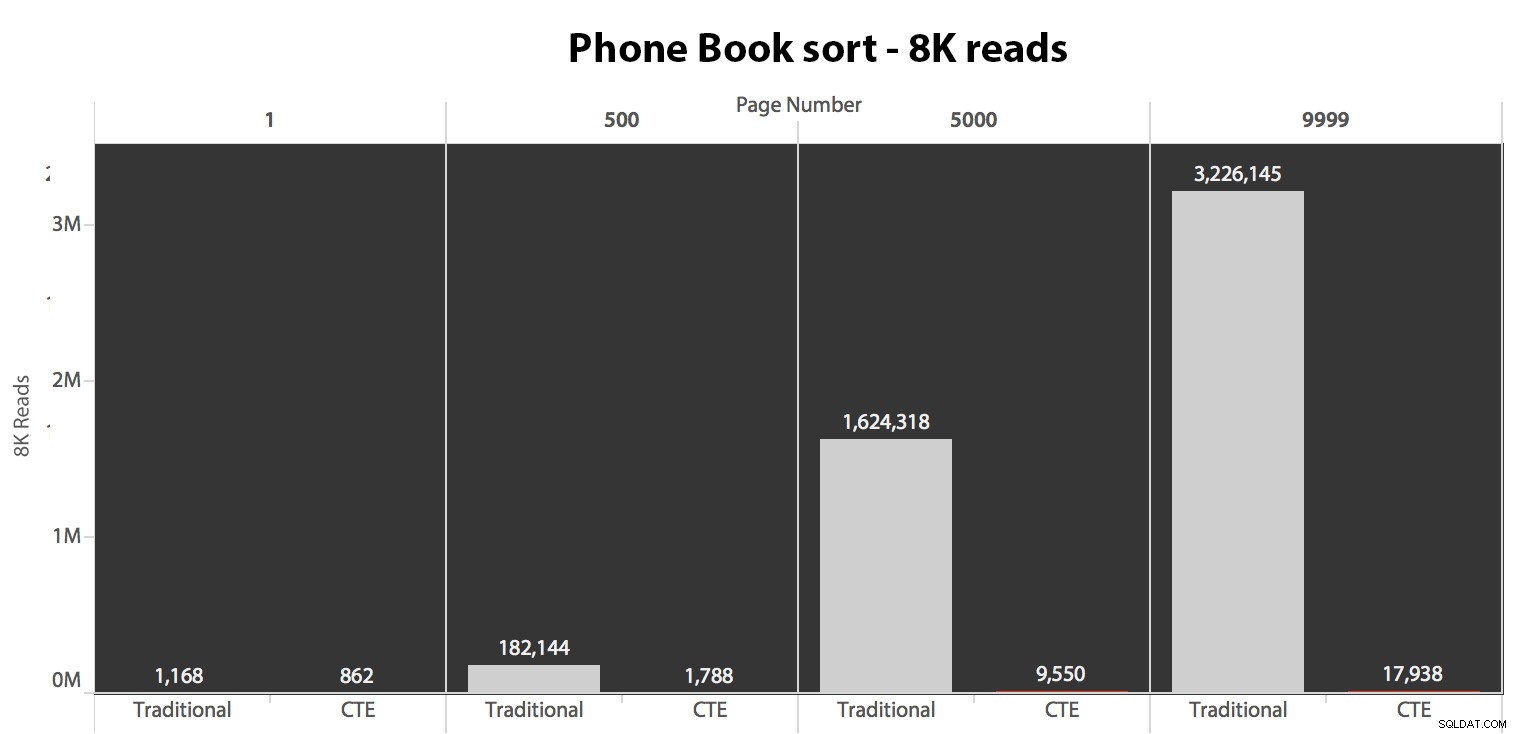
(Las lecturas bajo un caché cálido siguieron el mismo patrón:los números reales diferían ligeramente, pero no lo suficiente como para justificar un gráfico separado).
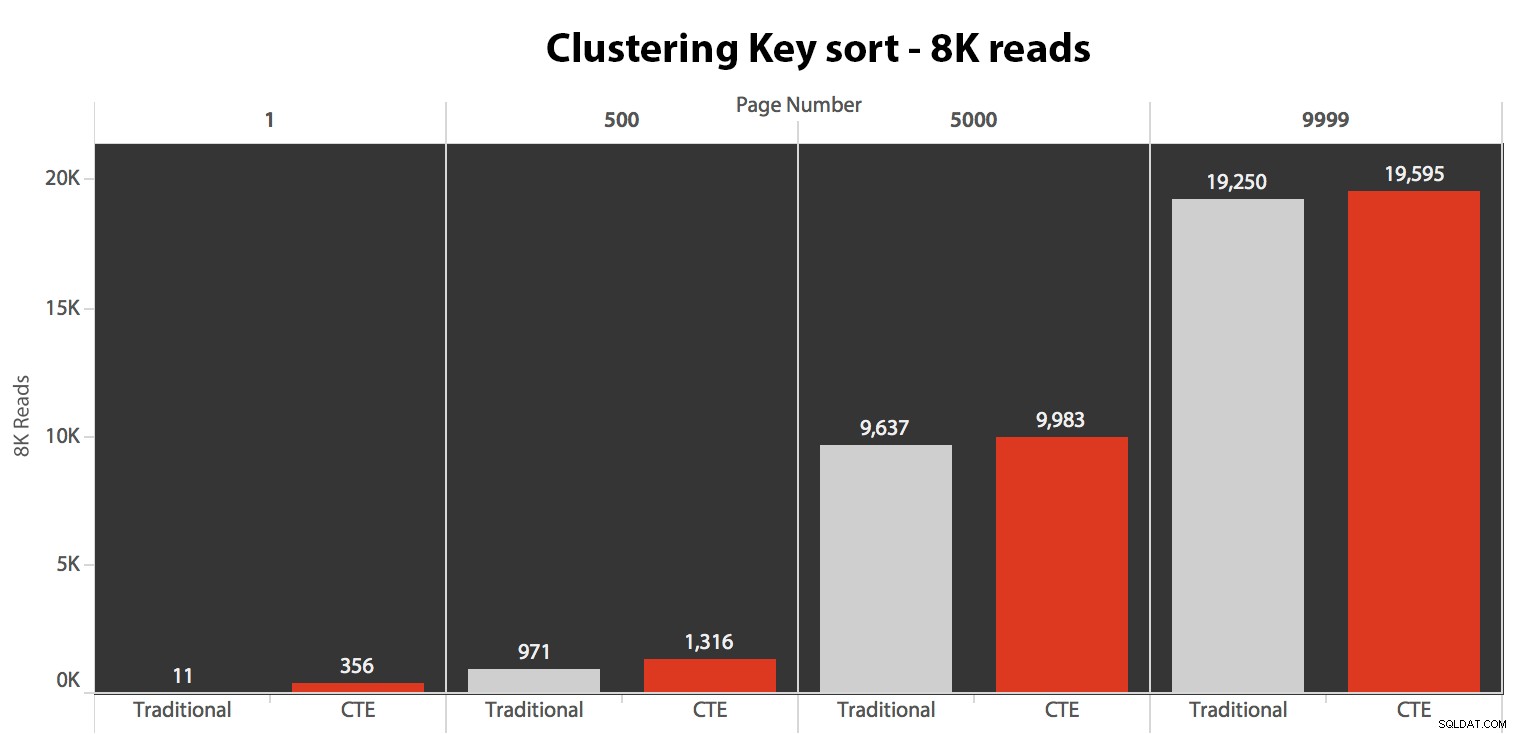
Cuando no usamos el índice agrupado para ordenar, está claro que los costos de E/S involucrados con el método tradicional de COMPENSACIÓN/FETCH son mucho peores que cuando se identifican las claves primero en un CTE y se extrae el resto de las columnas. solo para ese subconjunto.
Este es el plan para el enfoque de consulta tradicional:
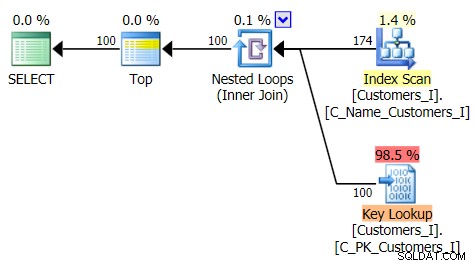
Y el plan para mi enfoque CTE alternativo:
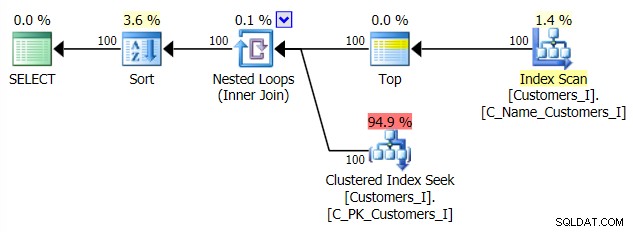
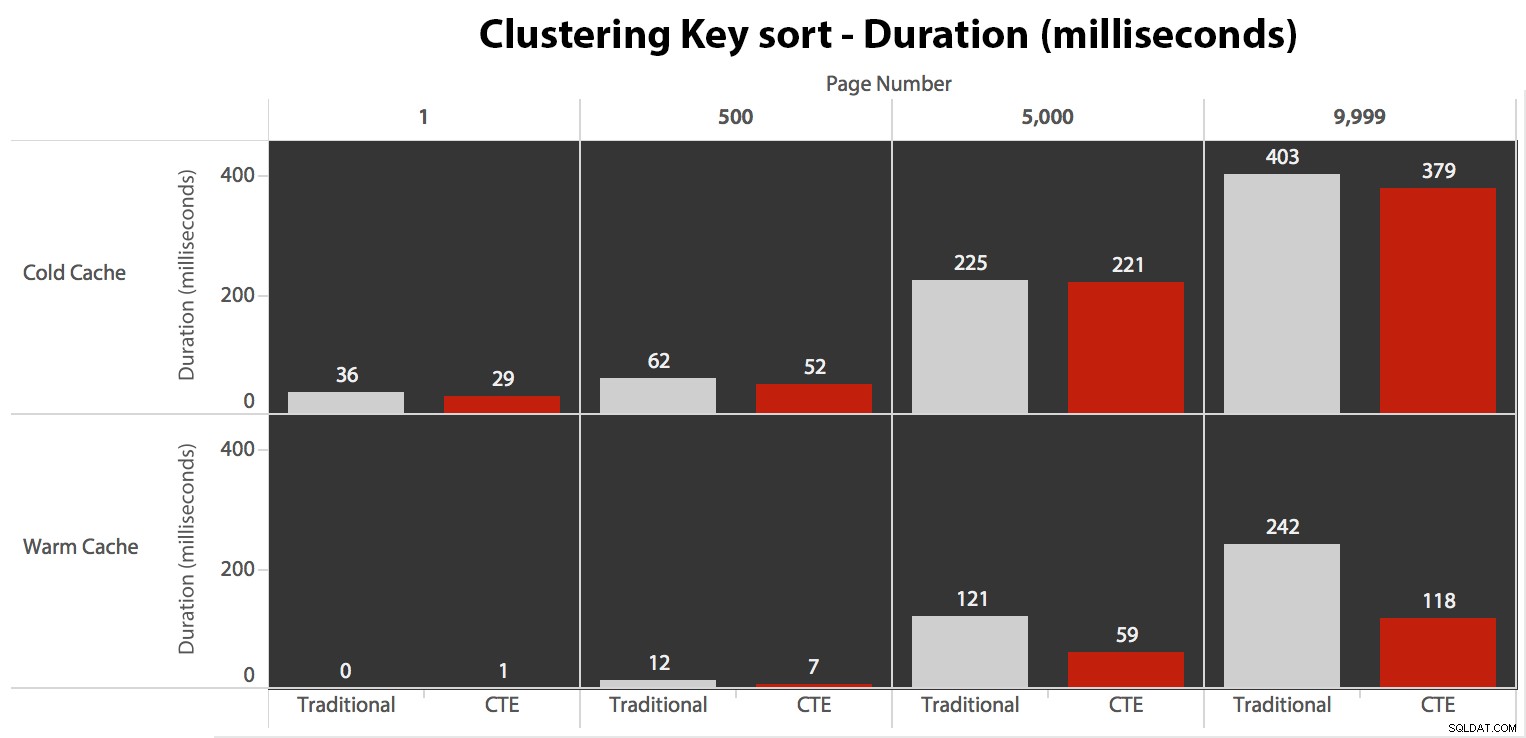
Finalmente, las duraciones:
El enfoque tradicional muestra un aumento muy evidente en la duración a medida que avanza hacia el final de la paginación. El enfoque CTE también muestra un patrón no lineal, pero es mucho menos pronunciado y produce una mejor sincronización en cada número de página. Vemos 117 milisegundos para la penúltima página, en comparación con el enfoque tradicional de casi dos segundos.
Probar el ordenamiento definido por el usuario
Finalmente, cambié la consulta para usar Test_3 procedimientos almacenados, probando el caso en el que el usuario definió la clasificación y no tenía un índice de soporte. El I/O fue consistente en cada conjunto de pruebas; el gráfico es tan poco interesante, solo voy a vincularlo. Para resumir:hubo un poco más de 19,000 lecturas en todas las pruebas. La razón es que cada variación tuvo que realizar un escaneo completo debido a la falta de un índice para respaldar el pedido. Este es el plan para el enfoque tradicional:
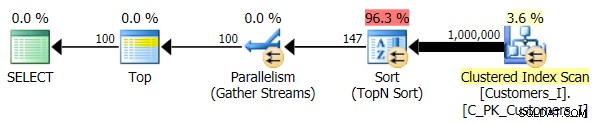
Y aunque el plan para la versión CTE de la consulta parece alarmantemente más complejo...
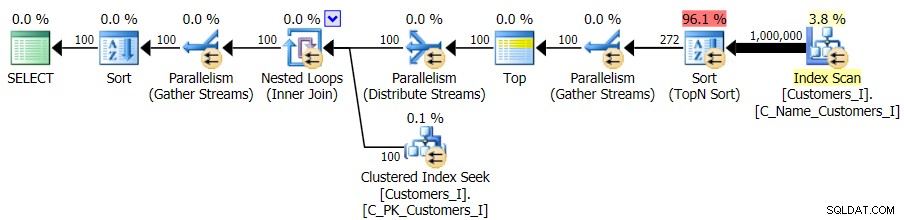
…conduce a duraciones más bajas en todos los casos excepto en uno. Estas son las duraciones:
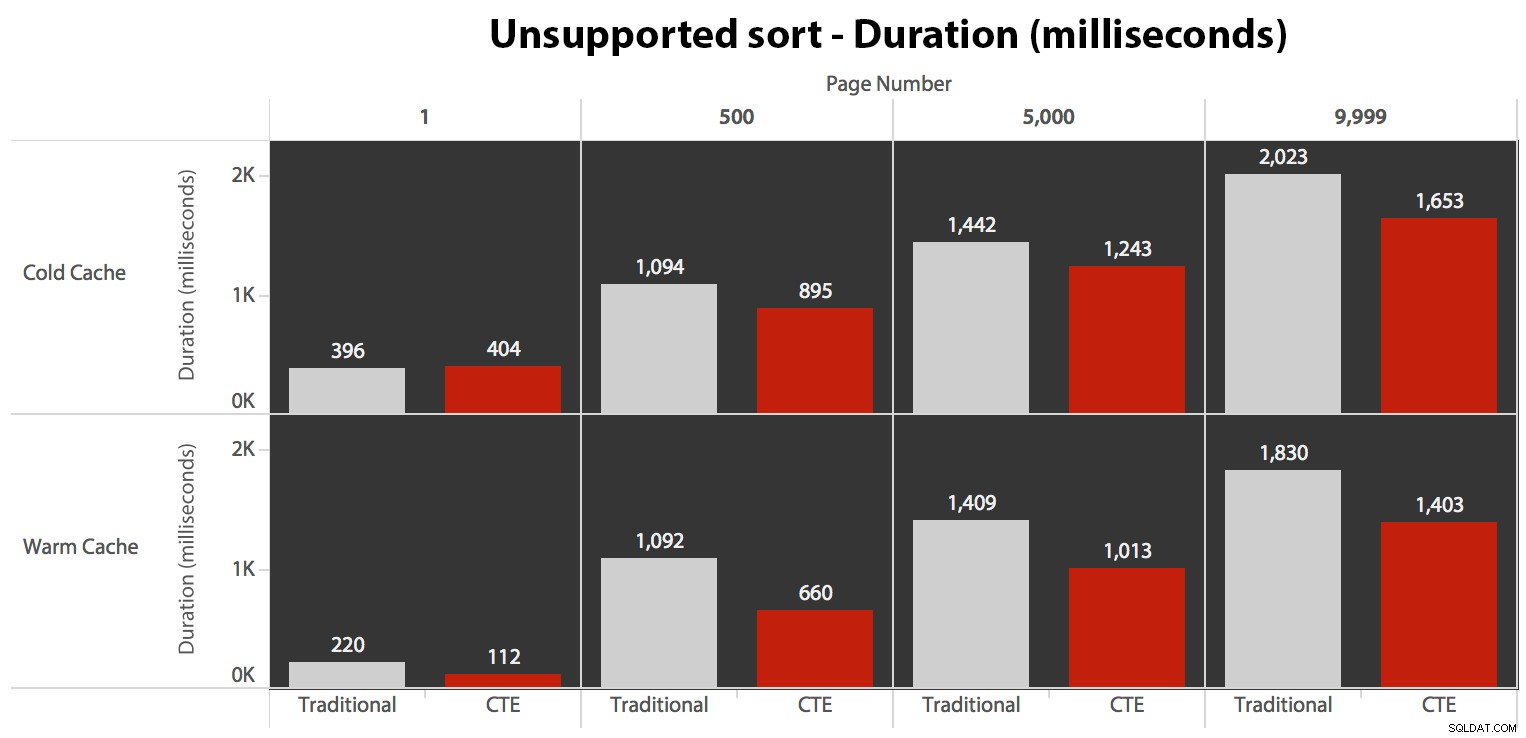
Puede ver que no podemos obtener un rendimiento lineal aquí con ninguno de los métodos, pero el CTE se destaca por un buen margen (entre un 16 % y un 65 % mejor) en todos los casos, excepto en la consulta de caché en frío contra el primero. página (donde se perdió por la friolera de 8 milisegundos). También es interesante notar que el método tradicional no se ve muy ayudado por un caché tibio en el "medio" (páginas 500 y 5000); solo hacia el final del set vale la pena mencionar alguna eficiencia.
Volumen más alto
Después de realizar pruebas individuales de algunas ejecuciones y tomar promedios, pensé que también tendría sentido probar un gran volumen de transacciones que simularían un poco el tráfico real en un sistema ocupado. Así que creé un trabajo con 6 pasos, uno para cada combinación de método de consulta (paginación tradicional frente a CTE) y tipo de clasificación (clave de agrupación, directorio telefónico y no compatible), con una secuencia de 100 pasos para presionar los cuatro números de página anteriores , 10 veces cada uno, y otros 60 números de página elegidos al azar (pero los mismos para cada paso). Así es como generé el script de creación de trabajo:
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX), @job SYSNAME = N'Paging Test', @step SYSNAME, @command NVARCHAR(MAX);
;WITH t10 AS (SELECT TOP (10) number FROM master.dbo.spt_values),
f AS (SELECT f FROM (VALUES(1),(500),(5000),(9999)) AS f(f))
SELECT @sql = STUFF((SELECT CHAR(13) + CHAR(10)
+ N'EXEC dbo.$p$_Test_$v$ @PageNumber = ' + RTRIM(f) + ';'
FROM
(
SELECT f FROM
(
SELECT f.f FROM t10 CROSS JOIN f
UNION ALL
SELECT TOP (60) f = ABS(CHECKSUM(NEWID())) % 10000
FROM sys.all_objects
) AS x
) AS y ORDER BY NEWID()
FOR XML PATH(''),TYPE).value(N'.[1]','nvarchar(max)'),1,0,'');
IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name = @job)
BEGIN
EXEC msdb.dbo.sp_delete_job @job_name = @job;
END
EXEC msdb.dbo.sp_add_job
@job_name = @job,
@enabled = 0,
@notify_level_eventlog = 0,
@category_id = 0,
@owner_login_name = N'sa';
EXEC msdb.dbo.sp_add_jobserver
@job_name = @job,
@server_name = N'(local)';
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT step = p.p + '_' + v.v,
command = REPLACE(REPLACE(@sql, N'$p$', p.p), N'$v$', v.v)
FROM
(SELECT v FROM (VALUES('1'),('2'),('3')) AS v(v)) AS v
CROSS JOIN
(SELECT p FROM (VALUES('Alternate'),('Pagination')) AS p(p)) AS p
ORDER BY p.p, v.v;
OPEN c; FETCH c INTO @step, @command;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC msdb.dbo.sp_add_jobstep
@job_name = @job,
@step_name = @step,
@command = @command,
@database_name = N'IDs',
@on_success_action = 3;
FETCH c INTO @step, @command;
END
EXEC msdb.dbo.sp_update_jobstep
@job_name = @job,
@step_id = 6,
@on_success_action = 1; -- quit with success
PRINT N'EXEC msdb.dbo.sp_start_job @job_name = ''' + @job + ''';'; Aquí está la lista de pasos de trabajo resultante y una de las propiedades del paso:
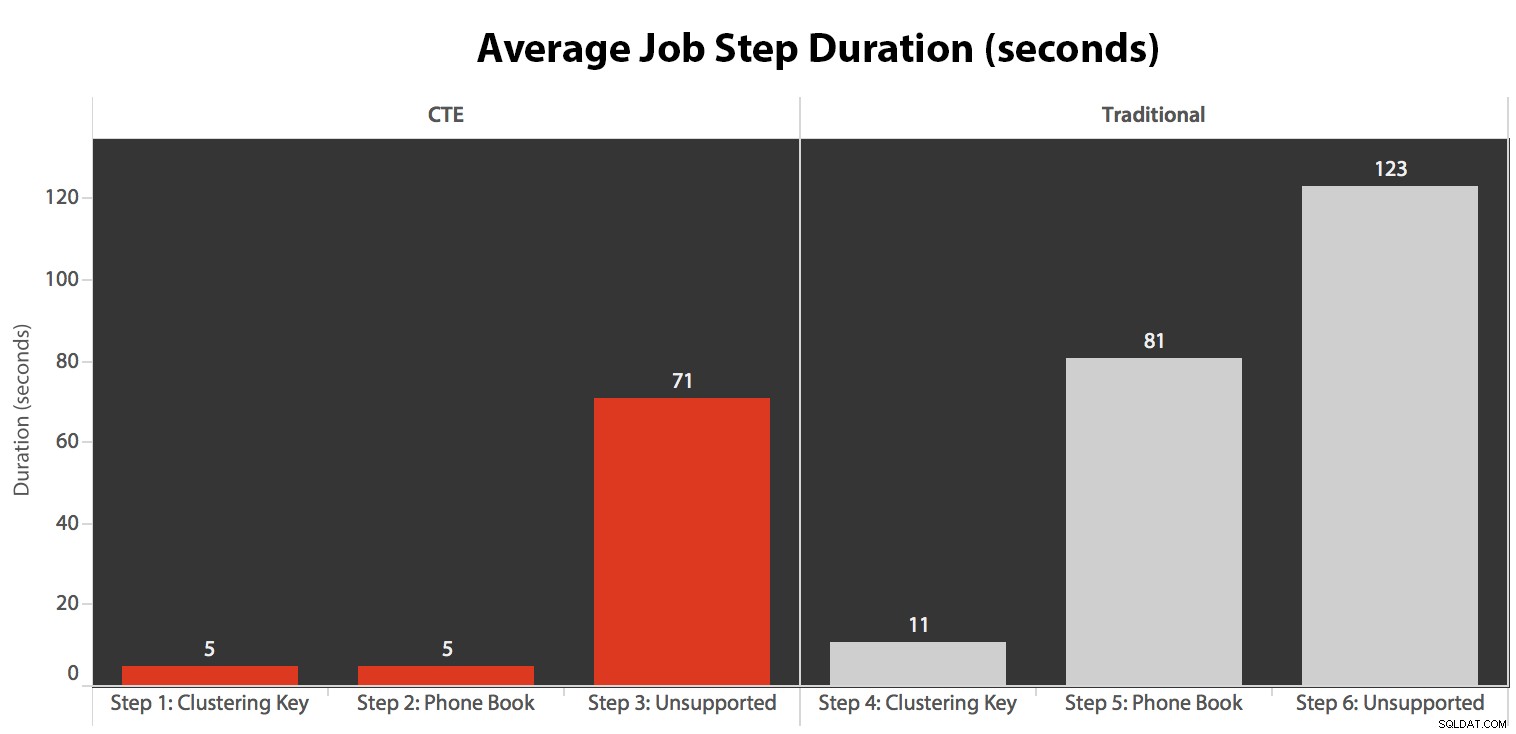
Ejecuté el trabajo cinco veces, luego revisé el historial del trabajo y estos fueron los tiempos de ejecución promedio de cada paso:
También correlacioné una de las ejecuciones en el calendario de SQL Sentry Event Manager...
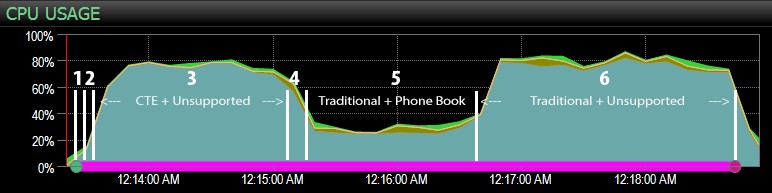
…con el tablero de SQL Sentry, y marqué manualmente aproximadamente dónde se ejecutaba cada uno de los seis pasos. Aquí está el gráfico de uso de la CPU desde el lado de Windows del tablero:
Y desde el lado de SQL Server del tablero, las métricas interesantes estaban en los gráficos de Búsquedas clave y Esperas:
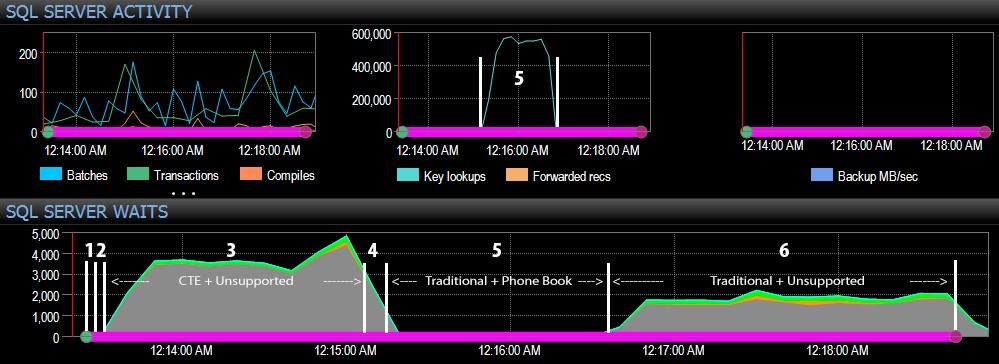
Las observaciones más interesantes solo desde una perspectiva puramente visual:
- La CPU está bastante caliente, alrededor del 80 %, durante el paso 3 (CTE + sin índice de soporte) y el paso 6 (tradicional + sin índice de soporte);
- Las esperas de CXPACKET son relativamente altas durante el paso 3 y en menor medida durante el paso 6;
- puede ver el salto masivo en las búsquedas clave, a casi 600.000, en aproximadamente un lapso de un minuto (correlacionado con el paso 5:el enfoque tradicional con un índice al estilo de una guía telefónica).
En una prueba futura, como en mi publicación anterior sobre GUID, me gustaría probar esto en un sistema donde los datos no caben en la memoria (fácil de simular) y donde los discos son lentos (no tan fácil de simular) , ya que algunos de estos resultados probablemente se benefician de cosas que no todos los sistemas de producción tienen:discos rápidos y suficiente RAM. También debo expandir las pruebas para incluir más variaciones (usando columnas delgadas y anchas, índices delgados y anchos, un índice de guía telefónica que realmente cubra todas las columnas de salida y ordenando en ambas direcciones). El avance del alcance definitivamente limitó el alcance de mis pruebas para este primer conjunto de pruebas.
Cómo mejorar la paginación de SQL Server
La paginación no siempre tiene que ser dolorosa; SQL Server 2012 sin duda facilita la sintaxis, pero si solo conecta la sintaxis nativa, es posible que no siempre vea un gran beneficio. Aquí he demostrado que una sintaxis un poco más detallada usando un CTE puede conducir a un rendimiento mucho mejor en el mejor de los casos, y diferencias de rendimiento posiblemente insignificantes en el peor de los casos. Al separar la ubicación de datos de la recuperación de datos en dos pasos diferentes, podemos ver un tremendo beneficio en algunos escenarios, fuera de las esperas más altas de CXPACKET en un caso (e incluso entonces, las consultas paralelas terminaron más rápido que las otras consultas mostrando poca o ninguna espera, por lo que es poco probable que sean las "malas" esperas de CXPACKET de las que todos te advierten).
Aún así, incluso el método más rápido es lento cuando no hay un índice de apoyo. Si bien puede tener la tentación de implementar un índice para cada algoritmo de clasificación posible que un usuario pueda elegir, es posible que desee considerar proporcionar menos opciones (ya que todos sabemos que los índices no son gratuitos). Por ejemplo, ¿su aplicación necesita absolutamente admitir la clasificación por Apellido ascendente *y* Apellido descendente? Si quieren ir directamente a los clientes cuyos apellidos comienzan con Z, ¿no pueden ir a la *última* página y trabajar hacia atrás? Esa es una decisión comercial y de usabilidad más que técnica, solo manténgala como una opción antes de colocar índices en cada columna de clasificación, en ambas direcciones, para obtener el mejor rendimiento incluso para las opciones de clasificación más oscuras.