Si bien Jeff Atwood y Joe Celko parecen pensar que el costo de los GUID no es gran cosa (consulte la publicación de blog de Jeff, "Primary Keys:IDs versus GUIDs", y este hilo de grupo de noticias, titulado "Identity Vs. Uniqueidentifier"), otros expertos:más específicamente, los expertos en índices y arquitectura que se enfocan en el espacio de SQL Server tienden a estar en desacuerdo. Por ejemplo, Kimberly Tripp repasa algunos detalles en su publicación, "El espacio en disco es barato:¡ESE NO ES EL PUNTO!", donde explica que el impacto no es solo en el espacio en disco y la fragmentación, sino, lo que es más importante, en el tamaño del índice y la memoria. huella.
Lo que dice Kimberly es realmente cierto:me encuentro con la justificación de que "el espacio en disco es barato" para los GUID todo el tiempo (ejemplo de la semana pasada). Hay otras justificaciones para los GUID, incluida la necesidad de generar identificadores únicos fuera de la base de datos (y, a veces, antes de que se cree realmente la fila) y la necesidad de identificadores únicos en sistemas distribuidos separados (y donde los rangos de identidad no son prácticos). Pero realmente quiero disipar el mito de que los GUID no cuestan tanto, porque lo hacen, y debe sopesar estos costos en su decisión.
Me propuse esta misión para probar el rendimiento de diferentes tamaños de clave, dados los mismos datos en la misma cantidad de filas, con los mismos índices y aproximadamente la misma carga de trabajo (reproducir *exactamente* la misma carga de trabajo puede ser bastante desafiante). No solo quería medir las cosas básicas como el tamaño del índice y la fragmentación del índice, sino también los efectos que tienen en el futuro, como:
- impacto en el uso del grupo de búfer
- frecuencia de divisiones de página "incorrectas"
- impacto general en la duración realista de la carga de trabajo
- impacto en los tiempos de ejecución promedio de consultas individuales
- impacto en la duración del tiempo de ejecución de los disparadores posteriores
- impacto en el uso de tempdb
Usaré una variedad de técnicas para investigar estos datos, incluidos eventos extendidos, el seguimiento predeterminado, DMV relacionados con tempdb y SQL Sentry Performance Advisor.
Configuración
Primero, creé un millón de clientes para colocarlos en una tabla semilla utilizando algunos metadatos de SQL Server integrados; esto garantizaría que los clientes "aleatorios" consistirían en los mismos datos naturales a lo largo de cada prueba.
CREATE TABLE dbo.CustomerSeeds( rn INT PRIMARY KEY CLUSTERED, FirstName NVARCHAR(64), LastName NVARCHAR(64), EMail NVARCHAR(320) NOT NULL UNIQUE, Active BIT); INSERTAR dbo.CustomerSeeds CON (TABLOCKX) (rn, Nombre, Apellido, Correo electrónico, [Activo]) SELECCIONAR rn =ROW_NUMBER() SOBRE (ORDENAR POR n), fn, ln, em, aFROM ( SELECCIONAR ARRIBA (1000000) fn, ln , em, a =MAX(a), n =MAX(NUEVO()) DESDE ( SELECCIONE fn, ln, em, a, r =ROW_NUMBER() SOBRE (PARTICIÓN POR em ORDEN POR em) DESDE ( SELECCIONE ARRIBA (2000000) fn =IZQUIERDA(o.nombre, 64), ln =IZQUIERDA(c.nombre, 64), em =IZQUIERDA(o.nombre, LEN(c.nombre)%5+1) + '.' + IZQUIERDA(c. nombre, LARGO(o.nombre)%5+2) + '@' + DERECHA(c.nombre, LARGO(o.nombre+c.nombre)%12 + 1) + IZQUIERDA(RTRIM(CHECKSUM(NEWID()) ),3) + '.com', a =CASO CUANDO c.name LIKE '%y%' THEN 0 ELSE 1 END FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c ORDER BY NEWID() ) AS x ) COMO y DONDE r =1 AGRUPAR POR fn, ln, em ORDENAR POR n) COMO z ORDENAR POR rn;IR SELECCIONAR ARRIBA (10) * DESDE dbo.CustomerSeeds ORDENAR POR rn;IR
Su millaje puede variar, pero en mi sistema, esta población tardó 86 segundos. Diez filas representativas (haga clic para ampliar):
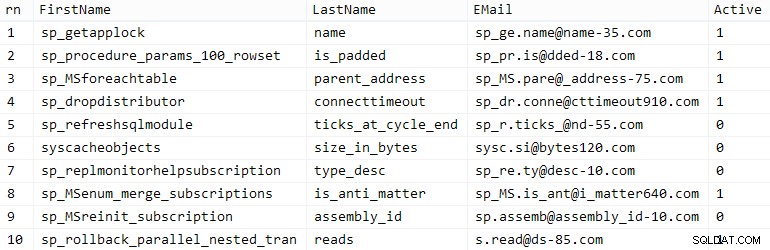 Clientes de muestra
Clientes de muestra
A continuación, necesitaba tablas para albergar los datos iniciales para cada caso de uso, con algunos índices adicionales para simular algún tipo de realidad, y se me ocurrieron sufijos cortos para facilitar todo tipo de diagnósticos más adelante:
| tipo de datos | predeterminado | compresión | sufijo de caso de uso |
|---|---|---|---|
| INT | IDENTIDAD | ninguno | Yo |
| INT | IDENTIDAD | página + fila | Ic |
| GRANDE | IDENTIDAD | ninguno | B |
| GRANDE | IDENTIDAD | página + fila | Bc |
| IDENTIFICADOR ÚNICO | NEWID() | ninguno | G |
| IDENTIFICADOR ÚNICO | NEWID() | página + fila | Gc |
| IDENTIFICADOR ÚNICO | NEWSEQUENTIALID() | ninguno | S |
| IDENTIFICADOR ÚNICO | NEWSEQUENTIALID() | página + fila | Sc |
Tabla 1:Casos de uso, tipos de datos y sufijos
Ocho tablas en total, todas basadas en la misma plantilla (simplemente cambiaría los comentarios para que coincidan con el caso de uso y reemplazaría $use_case$ con el sufijo apropiado de la tabla anterior):
CREATE TABLE dbo.Customers_$use_case$ -- I,Ic,B,Bc,G,Gc,S,Sc( CustomerID INT NOT NULL IDENTITY(1,1), --CustomerID BIGINT NOT NULL IDENTITY(1, 1), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID(), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWSEQUENTIALID(), FirstName NVARCHAR(64) NOT NULL, LastName NVARCHAR(64) NOT NULL, EMail NVARCHAR(320) NOT NULL, Active BIT NOT NULL DEFAULT 1, Creado DATETIME NOT NULL DEFAULT SYSDATETIME(), Updated DATETIME NULL, CONSTRAINT C_PK_Customers_$use_case$ PRIMARY KEY (CustomerID)) --WITH (DATA_COMPRESSION =PAGE)GO;CREAR ÚNICO ÍNDICE C_Email_Customers_$use_case$ ON dbo. Customers_$use_case$(Email) --WITH (DATA_COMPRESSION =PAGE);GOCREATE INDEX C_Active_Customers_$use_case$ ON dbo.Customers_$use_case$(FirstName, LastName, EMail) WHERE Active =1 --WITH (DATA_COMPRESSION =PAGE);GOCREATE ÍNDICE C_Name_Customers_$use_case$ ON dbo.Customers_$use_case$(LastName, FirstName) INCLUDE (Correo electrónico) --WITH (DATA_COMPRESSION =PAGE);GOUna vez que se crearon las tablas, procedí a completar las tablas y medir muchas de las métricas a las que aludí anteriormente. Reinicié el servicio de SQL Server entre cada prueba para asegurarme de que todos comenzaban desde la misma línea de base, que los DMV se restablecerían, etc.
Inserciones no impugnadas
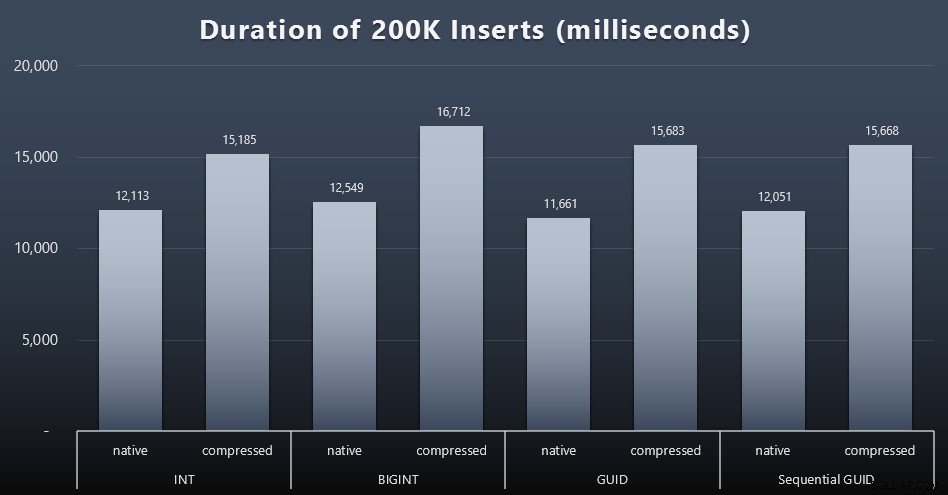
Mi objetivo final era llenar la tabla con 1 000 000 de filas, pero primero quería ver el impacto del tipo de datos y la compresión en las inserciones sin formato sin contención. Generé la siguiente consulta, que llenaría la tabla con los primeros 200 000 contactos, 2000 filas a la vez, y la ejecuté en cada tabla:
DECLARAR @i INT =1;WHILE @i <=100COMENZAR INSERTAR dbo.Customers_$use_case$(Nombre, Apellido, Correo electrónico, Activo) SELECCIONAR Nombre, Apellido, Correo electrónico, Activo DESDE dbo.CustomerSeeds COMO c ORDENAR POR rn COMPENSACIÓN 2000 * (@i-1) LAS FILAS BUSCAN LAS SIGUIENTES 2000 FILAS SOLAMENTE; CONFIGURAR @i +=1;FINResultados (haga clic para ampliar):
Cada caso tomó alrededor de 12 segundos (sin compresión) y 16 segundos (con compresión), sin un ganador claro en ninguno de los modos de almacenamiento. El efecto de la compresión (principalmente en la sobrecarga de la CPU) es bastante constante, pero dado que se ejecuta en un SSD rápido, el impacto de E/S de los diferentes tipos de datos es insignificante. De hecho, la compresión contra BIGINT pareció tener el mayor impacto (y esto tiene sentido, ya que todos los valores menores a 2 mil millones serían comprimidos).
Carga de trabajo más contenciosa
A continuación, quería ver cómo una carga de trabajo mixta competiría por los recursos y, en general, se comportaría con cada tipo de datos. Así que creé estos procedimientos (reemplazando
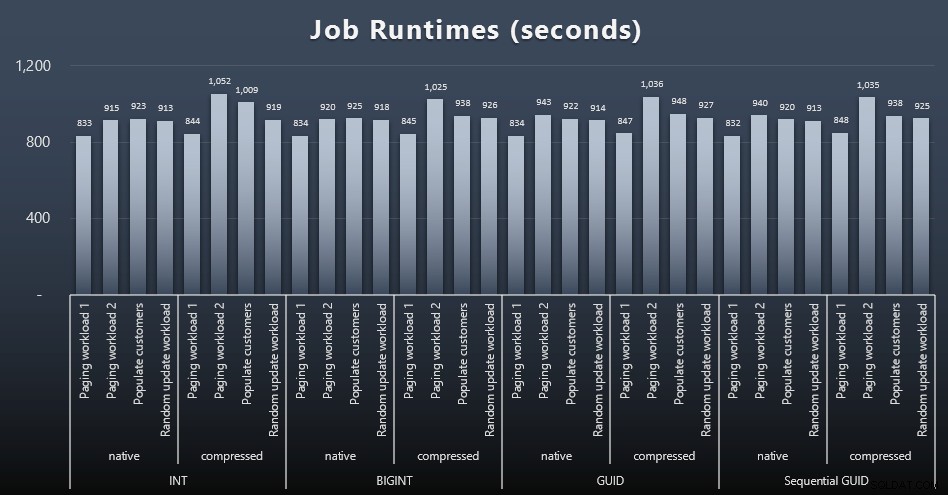
$use_case$y$data_type$apropiadamente para cada prueba):-- actualizaciones aleatorias de singleton a los datos en más de un indexCREATE PROCEDURE [dbo].[Customers_$use_case$_RandomUpdate] @Customers_$use_case$ $data_type$ASBEGIN SET NOCOUNT ON; ACTUALIZAR dbo.Customers_$use_case$ SET LastName =COALESCE(STUFF(LastName, 4, 1, 'x'),'x') WHERE CustomerID =@Customers_$use_case$;ENDGO -- lee ("paginación") - admite múltiples ordenaciones:use SQL dinámico para realizar un seguimiento de las estadísticas de consulta por separado CREAR PROCEDIMIENTO [dbo]. [Clientes_$use_case$_Page] @PageNumber INT =1, @PageSize INT =100, @sort SYSNAMEASBEGIN SET NOCOUNT ON; DECLARE @sql NVARCHAR(MAX) =N'SELECT CustomerID, FirstName, LastName, Email, Active, Created, Updated FROM dbo.Customers_$use_case$ ORDER BY ' + @sort + N' OFFSET ((@pn-1)*@ ps) FILAS FETCH SIGUIENTE @ps FILAS SOLAMENTE;'; EXEC sys.sp_executesql @sql, N'@pn INT, @ps INT', @PageNumber, @PageSize;ENDGOLuego creé trabajos que llamarían a esos procedimientos repetidamente, con ligeros retrasos, y también, simultáneamente, terminarían de poblar los 800,000 contactos restantes. Este script crea los 32 trabajos y también imprime una salida que se puede usar más adelante para llamar a todos los trabajos para una prueba específica de forma asíncrona:
USE msdb;VAYA DECLARE @typ TABLE(use_case VARCHAR(2), data_type SYSNAME);INSERT @typ(use_case, data_type) VALUES('I', N'INT'), ('Ic',N'INT '),('B', N'BIGINT'), ('Bc', N'BIGINT'),('G', N'UNIQUEIDENTIFIER'), ('Gc', N'UNIQUEIDENTIFIER'),('S ', N'IDENTIFICADOR ÚNICO'), ('Sc', N'IDENTIFICADOR ÚNICO'); DECLARE @jobs TABLE(name SYSNAME, cmd NVARCHAR(MAX));INSERT @jobs(name, cmd) VALUES( N'Carga de trabajo de actualización aleatoria', N'DECLARE @CustomerID $data_type$, @i INT =1; WHILE @i <=500 COMENZAR SELECCIONAR ARRIBA (1) @CustomerID =CustomerID FROM dbo.Customers_$use_case$ ORDER BY NEWID(); EXEC dbo.Customers_$use_case$_RandomUpdate @Customers_$use_case$ =@CustomerID; ESPERAR DEMORA ''00:00 :01''; SET @i +=1; END'),( N'Populate clients', N'SET QUOTED_IDENTIFIER ON; DECLARE @i INT =101; WHILE @i <=500 BEGIN INSERT dbo.Customers_$use_case$ (Nombre, Apellido, Correo electrónico, Activo) SELECCIONE Nombre, Apellido, Correo electrónico, Activo DESDE dbo.CustomerSeeds COMO c ORDENAR POR rn DESPLAZAMIENTO 2000 * (@i-1) FILAS FETCH SIGUIENTE 2000 FILAS SOLAMENTE; ESPERAR RETRASO ''00:00:01''; SET @i +=1; END'),( N'Carga de trabajo de paginación 1', N'DECLARAR @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- ordenar por ID de cliente SET @sql =N ''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''CustomerID'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; ESPERA POR RETRASO ''00:00:01''; CONFIGURAR @i +=2; FIN'),( N'Carga de trabajo de paginación 2', N'DECLARACIÓN @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- ordenar por Apellido, Nombre SET @sql =N''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''LastName, FirstName'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i;ESPERAR POR DEMORA ''00:00:01'';SET @i +=2;FIN'); DECLARAR @n SYSNAME, @c NVARCHAR(MAX); DECLARE c CURSOR LOCAL AVANCE RÁPIDO FORSELECT nombre =t.use_case + N' ' + j.name, cmd =REPLACE(REPLACE(j.cmd, N'$use_case$', t.use_case), N'$data_type$', t .tipo_de_datos) DESDE @typ COMO t CROSS JOIN @jobs COMO j; ABIERTO c; BUSCAR c EN @n, @c; MIENTRAS @@FETCH_STATUS <> -1COMENZAR SI EXISTE (SELECCIONE 1 DESDE msdb.dbo.sysjobs DONDE nombre =@n) COMENZAR EJECUTAR msdb.dbo.sp_delete_job @job_name =@n; END EXEC msdb.dbo.sp_add_job @job_name =@n, @enabled =0, @notify_level_eventlog =0, @category_id =0, @owner_login_name =N'sa'; EXEC msdb.dbo.sp_add_jobstep @job_name =@n, @step_name =@n, @command =@c, @database_name =N'ID'; EXEC msdb.dbo.sp_add_jobserver @job_name =@n, @server_name =N'(local)'; PRINT 'EXEC msdb.dbo.sp_start_job @job_name =N''' + @n + ''';'; FETCH c EN @n, @c;FINMedir los tiempos de trabajo en cada caso fue trivial:pude verificar las fechas de inicio/finalización en
msdb.dbo.sysjobhistoryo extráigalos de SQL Sentry Event Manager. Estos son los resultados (haga clic para ampliar):
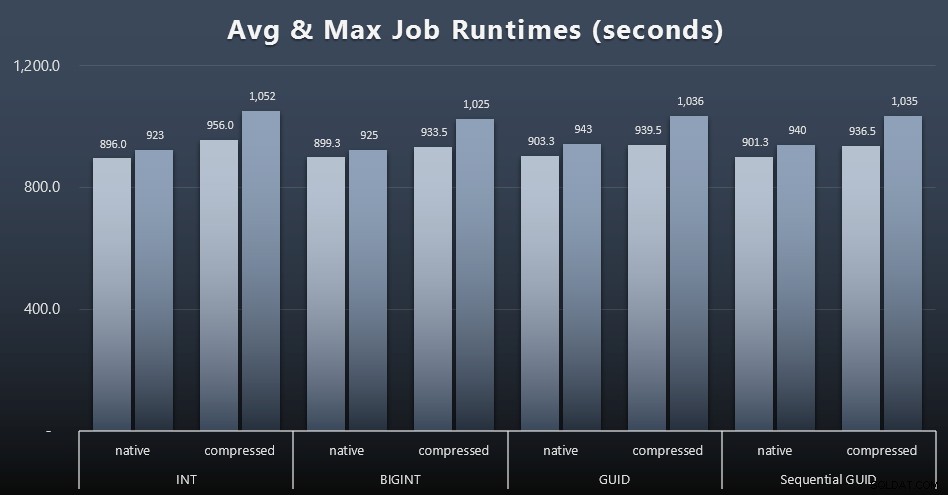
Y si desea tener un poco menos para digerir, solo mire los tiempos de ejecución promedio y máximo en los cuatro trabajos (haga clic para ampliar):
Pero incluso en este segundo gráfico, en realidad no hay suficiente variación para presentar un caso convincente a favor o en contra de cualquiera de los enfoques.
Tiempos de ejecución de consultas
Tomé algunas métricas de
sys.dm_exec_query_statsysys.dm_exec_trigger_statspara determinar cuánto tiempo tomaban en promedio las consultas individuales.
Población
Los primeros 200 000 clientes se cargaron con bastante rapidez (menos de 20 segundos) debido a que no hubo cargas de trabajo competitivas. Sin embargo, una vez que los cuatro trabajos se ejecutaban simultáneamente, hubo un impacto significativo en las duraciones de escritura debido a la simultaneidad. Las 800 000 filas restantes requirieron al menos un orden de magnitud más de tiempo para completarse, en promedio. Estos son los resultados de promediar cada inserción de 2000 clientes (haga clic para ampliar):
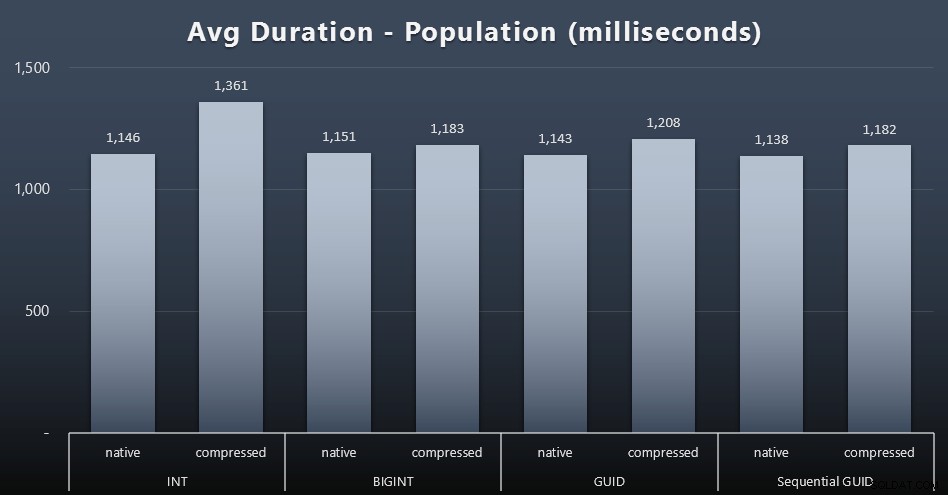
Vemos aquí que comprimir un INT fue el único valor atípico real. Tengo algunas teorías al respecto, pero aún no hay nada concluyente.
Cargas de trabajo de paginación
Los tiempos de ejecución promedio de las consultas de paginación también parecen haberse visto afectados significativamente por la simultaneidad en comparación con mis ejecuciones de prueba aisladas. Estos son los resultados (haga clic para ampliar):
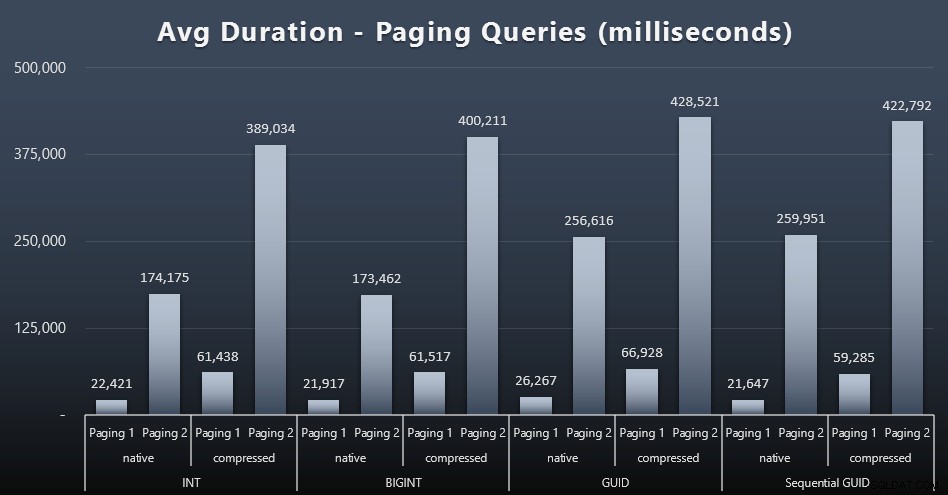
(Paging 1 =pedido por CustomerID, Paging 2 =pedido por LastName, FirstName.)
Vemos que tanto para la paginación 1 (pedido por ID de cliente) como para la paginación 2 (ordenado por nombres), hay un impacto significativo en el tiempo de ejecución debido a la compresión (hasta ~700%). Ambos GUID parecen ser los caballos más lentos en esta carrera, con NEWID() rindiendo peor.
Actualizar cargas de trabajo
Las actualizaciones de singleton fueron bastante rápidas, incluso con mucha simultaneidad, pero aún hubo algunas diferencias notables debido a la compresión e incluso algunas diferencias sorprendentes entre los tipos de datos (haga clic para ampliar):
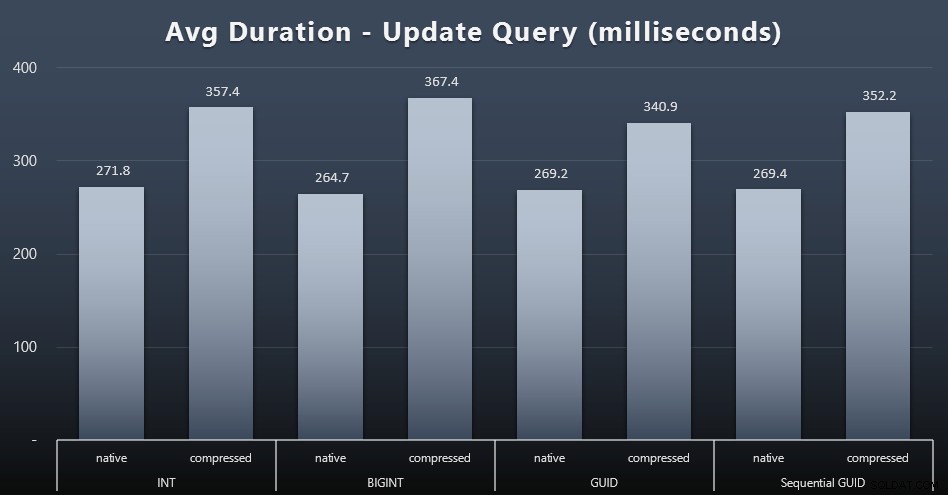
En particular, las actualizaciones de las filas que contienen valores GUID fueron en realidad más rápidas que las actualizaciones que contienen INT/BIGINT, cuando la compresión estaba en uso. Con el almacenamiento nativo, las diferencias eran menos notables (pero INT todavía perdía allí).
Estadísticas de activación
Estos son los tiempos de ejecución promedio y máximo para el disparador simple en cada caso (haga clic para ampliar):
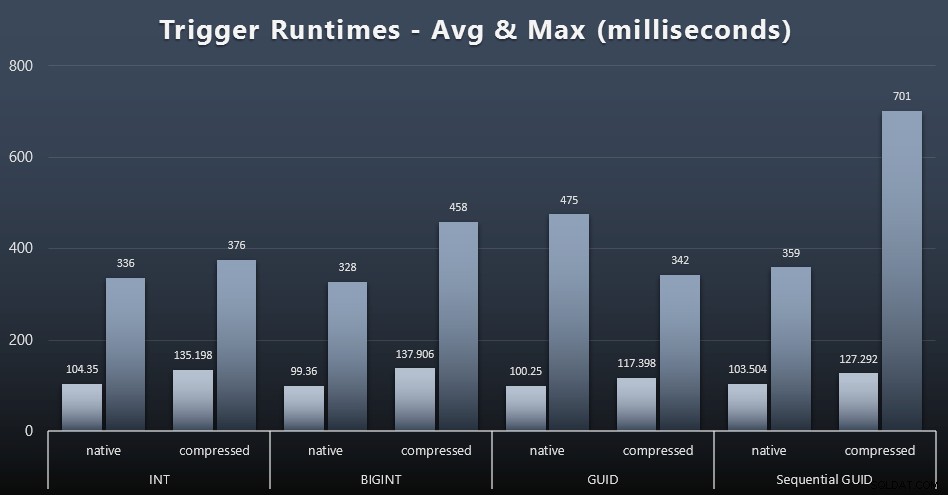
La compresión parece tener un impacto mucho mayor aquí que la elección del tipo de datos (aunque esto probablemente sería más pronunciado si parte de mi carga de trabajo de actualización hubiera actualizado muchas filas en lugar de consistir únicamente en búsquedas de una sola fila). El máximo para GUID secuencial es claramente un valor atípico de algún tipo que no investigué (se puede decir que es insignificante según el promedio que sigue en línea en todos los ámbitos).
¿Qué esperaban estas consultas?
Después de cada carga de trabajo, también eché un vistazo a las esperas principales en el sistema, eliminando las esperas obvias de cola/temporizador (como lo describe Paul Randal) y la actividad irrelevante del software de monitoreo (como TRACEWRITE ). Estas fueron las 3 esperas principales en cada caso (haga clic para ampliar):
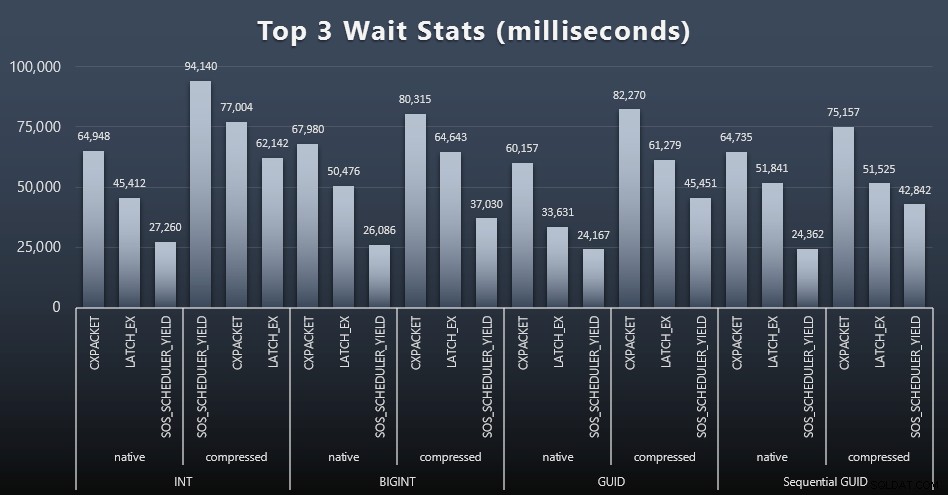
En la mayoría de los casos, las esperas fueron CXPACKET, luego LATCH_EX, luego SOS_SCHEDULER_YIELD. Sin embargo, en el caso de uso que involucra enteros y compresión, SOS_SCHEDULER_YIELD se hizo cargo, lo que para mí implica cierta ineficiencia en el algoritmo para comprimir enteros (que puede no tener ninguna relación con el algoritmo utilizado para comprimir BIGINT en INT). No investigué esto más a fondo, ni encontré justificación para rastrear las esperas por consulta individual.
Espacio en disco / Fragmentación
Si bien tiendo a estar de acuerdo en que no se trata del espacio en disco, sigue siendo una métrica que vale la pena presentar. Incluso en este caso muy simplista en el que solo hay una tabla y la clave no está presente en todas las demás tablas relacionadas (que seguramente existirían en una aplicación real), la diferencia es significativa. Primero, veamos el reserved columna de sp_spaceused (haga clic para ampliar):
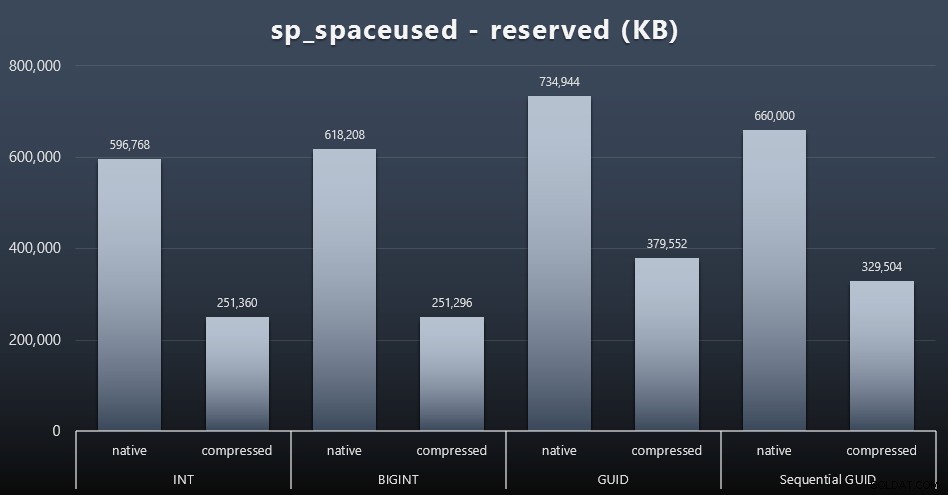
Aquí, BIGINT solo ocupó un poco más de espacio que INT, y GUID (como se esperaba) tuvo un salto mayor. El GUID secuencial tuvo un aumento menos significativo en el espacio utilizado y también se comprimió mucho mejor que el GUID tradicional. Nuevamente, no hay sorpresas aquí:un GUID es más grande que un número, punto. Ahora, los defensores de GUID podrían argumentar que el precio que paga en términos de espacio en disco no es mucho (18 % sobre BIGINT sin compresión, alrededor del 50 % con compresión). Pero recuerde que esta es una sola tabla de 1 millón de filas. Imagine cómo se extrapolará eso cuando tenga 10 millones de clientes y muchos de ellos tengan 10, 30 o 500 pedidos:esas claves podrían repetirse en una docena de otras tablas y ocupar el mismo espacio adicional en cada fila.
Cuando observé la fragmentación después de cada carga de trabajo (recuerde, no se realiza ningún mantenimiento de índice) usando esta consulta:
SELECCIONE index_id, FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('dbo.Customers_$use_case$'), -1, 0, 'DETALLE'); Los resultados generaron imágenes mucho menos interesantes; todos los índices no agrupados estaban fragmentados en más del 99 %. Sin embargo, los índices agrupados estaban muy fragmentados o no estaban fragmentados en absoluto (haga clic para ampliar):
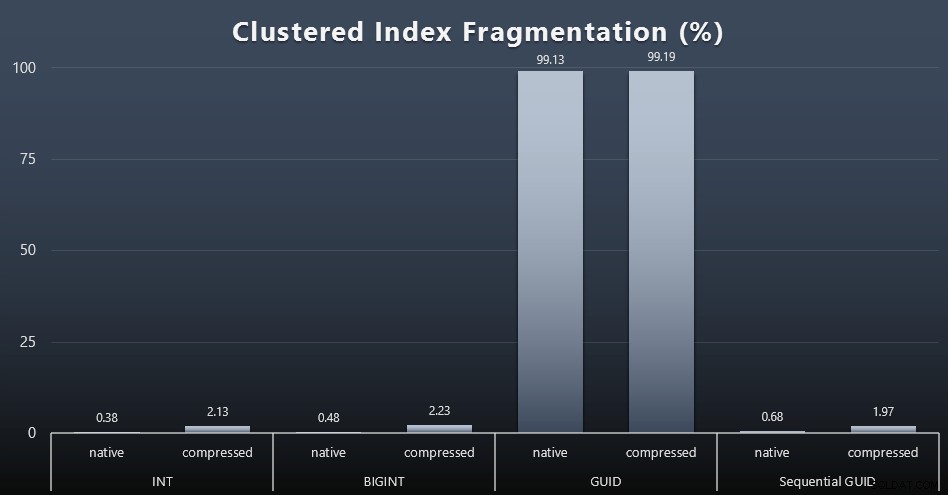
La fragmentación es otra métrica que a menudo significa mucho menos cuando hablamos de SSD, pero es importante tenerlo en cuenta de todos modos, ya que no todos los sistemas pueden darse el lujo de ignorar el impacto que la fragmentación puede tener en los patrones de E/S. Creo que al usar GUID no secuenciales, en un sistema más vinculado a E/S, el impacto de esta fragmentación por sí sola se amplificaría drásticamente en la mayoría de las demás métricas de esta prueba.
Uso del grupo de almacenamiento intermedio
Aquí es donde realmente vale la pena ser juicioso con respecto a la cantidad de espacio en disco utilizado por sus tablas:cuanto más grandes son sus tablas, más espacio ocupan en el grupo de búfer. Mover datos dentro y fuera del grupo de búfer es costoso y, de nuevo, este es un caso muy simple en el que las pruebas se ejecutaron de forma aislada y no había otras aplicaciones y bases de datos en la instancia compitiendo por la valiosa memoria.
Esta es una medida simple de la siguiente consulta al final de cada carga de trabajo:
SELECCIONE total_kb DESDE sys.dm_os_memory_broker_clerks DONDE clerk_name =N'Grupo de búfer';
Resultados (haga clic para ampliar):
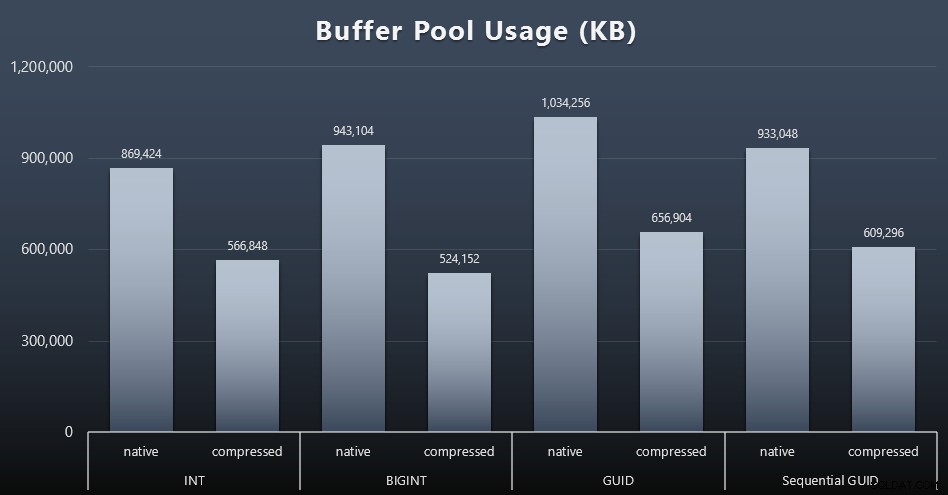
Si bien la mayor parte de este gráfico no sorprende en absoluto (GUID ocupa más espacio que BIGINT, BIGINT más que INT), me pareció interesante que un GUID secuencial ocupaba menos espacio que un BIGINT, incluso sin compresión. Tomé nota para realizar algunos análisis forenses a nivel de página para determinar qué tipo de eficiencias se están produciendo aquí debajo de las sábanas.
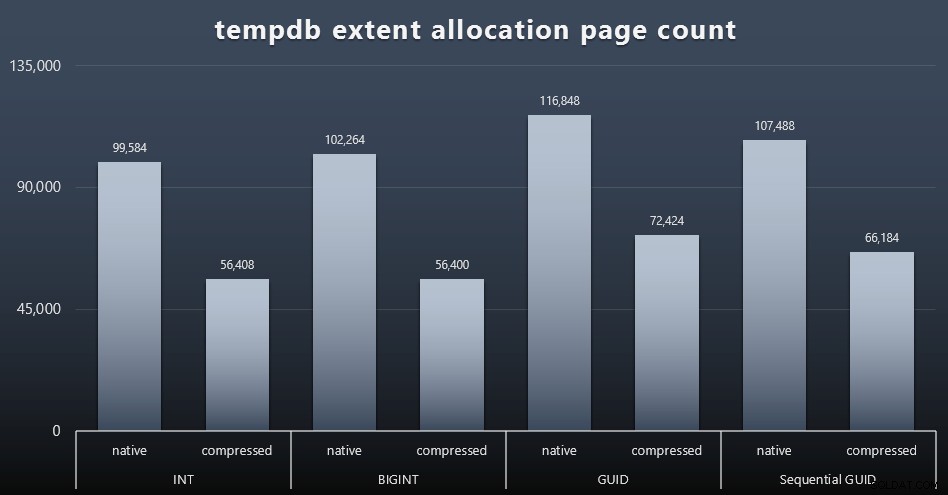
Uso de tempdb
No estoy seguro de lo que esperaba aquí, pero después de cada carga de trabajo, reuní el contenido de los tres DMV de uso de espacio relacionados con tempdb, sys.dm_db_file|session|task_space_usage . El único que parecía mostrar volatilidad según el tipo de datos era sys.dm_db_file_space_usage extent_allocation_page_count . Esto muestra que, al menos en mi configuración y esta carga de trabajo específica, los GUID someterán a tempdb a un entrenamiento un poco más completo (haga clic para ampliar):
Divisiones de página "incorrectas"
Una de las cosas que quería medir era el impacto en las divisiones de página, no en las divisiones de página normales (cuando agrega una página nueva), sino cuando realmente tiene que mover datos entre páginas para dejar espacio para más filas. Jonathan Kehayias habla de esto con más profundidad en su publicación de blog, "Seguimiento de divisiones de páginas problemáticas en eventos extendidos de SQL Server 2012:¡no, esta vez!", que también proporciona la base para la sesión de eventos extendidos que utilicé para capturar los datos:
CREAR SESIÓN DE EVENTO [BadPageSplits] EN EL SERVIDOR AGREGAR EVENTO sqlserver.transaction_log (WHERE operación =11 Y base de datos_id =10) AGREGAR OBJETIVO paquete0.histograma ( SET filtering_event_name ='sqlserver.transaction_log', source_type =0, source ='alloc_unit_id' );SESIÓN DE EVENTO DE PORTERO [BadPageSplits] EN ESTADO DEL SERVIDOR =INICIO;IR
Y la consulta que usé para trazarlo:
SELECT t.name, SUM(tab.split_count)FROM ( SELECT n.value('(value)[1]', 'bigint') AS alloc_unit_id, n.value('(@count)[1]' , 'bigint') AS split_count FROM ( SELECT CAST(target_data as XML) target_data FROM sys.dm_xe_sessions AS s INNER JOIN sys.dm_xe_session_targets AS t ON s.address =t.event_session_address WHERE s.name ='BadPageSplits' AND t.target_name ='histograma' ) AS x CROSS APPLY target_data.nodes('HistogramTarget/Slot') as q(n)) AS tabINNER JOIN sys.allocation_units AS au ON tab.alloc_unit_id =au.allocation_unit_idINNER JOIN sys.partitions AS p ON au. container_id =p.partition_idINNER JOIN sys.tables AS t ON p.object_id =t.[object_id]GROUP BY t.name; Y aquí están los resultados (haga clic para ampliar):
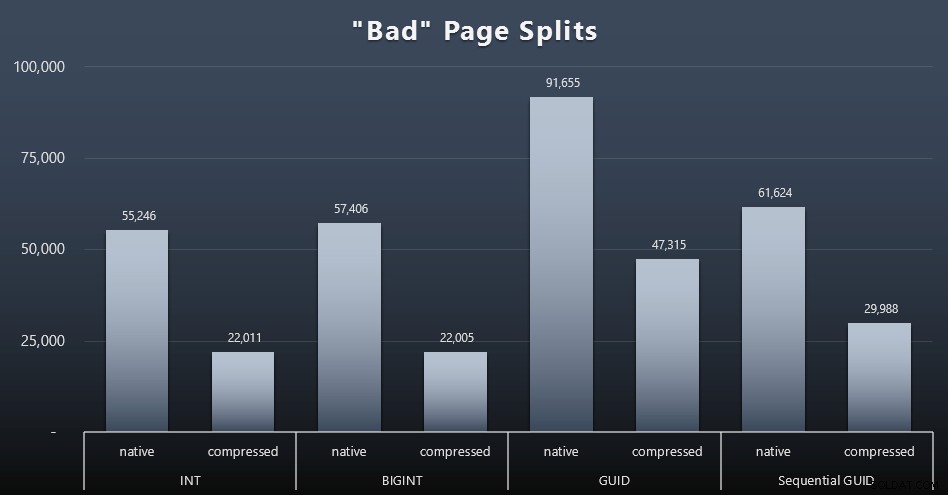
Aunque ya he notado que en mi escenario (donde estoy usando SSD rápidos) la diferencia indiscutible en la actividad de E/S no afecta directamente el tiempo de ejecución general, esta es una métrica que querrá considerar, especialmente si no tiene SSD o si su carga de trabajo ya está vinculada a E/S.
Conclusión
Si bien estas pruebas me han abierto los ojos un poco más acerca de cómo las percepciones que he tenido durante mucho tiempo han sido alteradas por hardware más moderno, sigo estando firmemente en contra de desperdiciar espacio en el disco o en la memoria. Si bien traté de demostrar cierto equilibrio y dejar que los GUID brillen, hay muy poco aquí desde una perspectiva de rendimiento para admitir el cambio de INT/BIGINT a cualquiera de las formas de UNIQUEIDENTIFIER, a menos que lo necesite por otras razones menos tangibles (como crear la clave en la aplicación o mantener valores clave únicos en sistemas dispares). Un resumen rápido, que muestra que NEWID() es la peor opción en muchas de las métricas en las que hubo una diferencia sustancial (y en la mayoría de esos casos, NEWSEQUENTIALID() quedó en segundo lugar)):
| Métrica | ¿Borrar perdedor(es)? |
|---|---|
| Inserciones no impugnadas | – dibujar– |
| Carga de trabajo simultánea | – dibujar– |
| Consultas individuales – Población | INT (comprimido) |
| Consultas individuales:paginación | NEWID() / NEWSEQUENTIALID() |
| Consultas individuales:actualización | INT (nativo) / BIGINT (comprimido) |
| Consultas individuales:DESPUÉS del activador | – dibujar– |
| Espacio en disco | NEWID() |
| Fragmentación de índices agrupados | NEWID() |
| Uso del grupo de búfer | NEWID() |
| Uso de tempdb | NEWID() |
| Divisiones de página "incorrectas" | NEWID() |
Tabla 2:Los mayores perdedores
Siéntete libre de probar estas cosas por ti mismo; Puedo ensamblar mi conjunto completo de scripts si desea ejecutarlos en su propio entorno. El propósito resumido de toda esta publicación es bastante simple:hay muchas métricas importantes a considerar además del impacto predecible en el espacio en disco, por lo que no debe usarse solo como un argumento en ninguna dirección.
Ahora bien, no quiero que esta línea de pensamiento se limite a las claves per se. Realmente se debe considerar cada vez que se realiza una elección de tipo de datos. Veo datetime siendo elegido a menudo, por ejemplo, cuando sólo una date o smalldatetime se necesita En las tablas transaccionales, esto también puede generar una gran cantidad de espacio en disco desperdiciado, y esto también se filtra a algunos de estos otros recursos.
En una prueba futura, me gustaría comparar los resultados de una tabla mucho más grande (> 2 mil millones de filas). Puedo simular esto con INT configurando la semilla de identidad en -2 mil millones, lo que permite ~4 mil millones de filas. Y me gustaría que las comparaciones de carga de trabajo y espacio en disco/huella de memoria involucren más de una sola tabla, ya que una de las ventajas de una clave delgada es cuando esa clave se representa en docenas de tablas relacionadas. Estaba monitoreando los eventos de crecimiento automático, pero no había ninguno, ya que la base de datos tenía un tamaño predeterminado lo suficientemente grande como para acomodar el crecimiento, y no pensé en medir el uso real del registro dentro del archivo de registro existente, así que me gustaría probar nuevamente con los valores predeterminados para el tamaño del registro y el crecimiento automático, y esta vez midiendo DBCC SQLPERF(LOGSPACE); . También sería interesante cronometrar las reconstrucciones y medir el uso de registros como resultado de esas operaciones. Finalmente, me gustaría hacer que la E/S sea un factor más relevante al encontrar un servidor con discos duros mecánicos. Sé que hay muchos, pero en algunas tiendas son bastante escasos.