En cualquiera de los motores de bases de datos relacionales se requiere generar el mejor plan posible que corresponda a la ejecución de la consulta con el menor tiempo y recursos. Generalmente, todas las bases de datos generan planes en un formato de estructura de árbol, donde el nodo de hoja de cada árbol de plan se denomina nodo de exploración de tabla. Este nodo particular del plan corresponde al algoritmo que se usará para obtener datos de la tabla base.
Por ejemplo, considere un ejemplo de consulta simple como SELECT * FROM TBL1, TBL2 where TBL2.ID>1000; y supongamos que el plan generado es el siguiente:
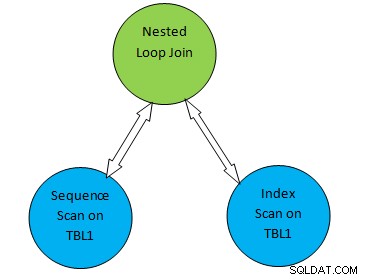
Entonces, en el árbol del plan anterior, "Exploración secuencial en TBL1" y " Exploración de índice en TBL2” corresponde al método de exploración de tabla en la tabla TBL1 y TBL2 respectivamente. Entonces, según este plan, TBL1 se obtendrá secuencialmente desde las páginas correspondientes y se puede acceder a TBL2 usando INDEX Scan.
Elegir el método de escaneo correcto como parte del plan es muy importante en términos del rendimiento general de las consultas.
Antes de entrar en todos los tipos de métodos de análisis compatibles con PostgreSQL, revisemos algunos de los puntos clave principales que se usarán con frecuencia a medida que avancemos en el blog.
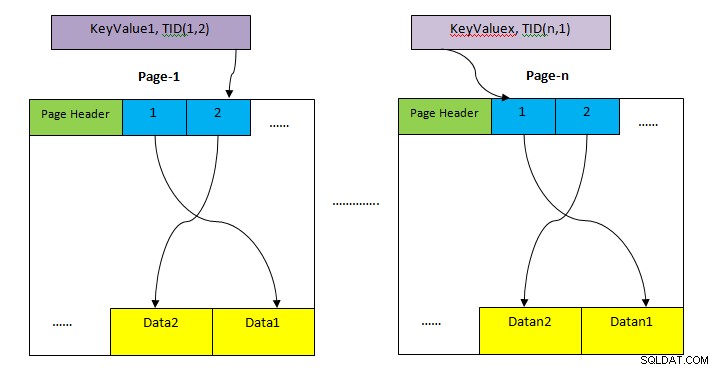
- MONTAJE: Zona de almacenaje para guardar toda la fila de la mesa. Esto se divide en varias páginas (como se muestra en la imagen de arriba) y cada página tiene un tamaño predeterminado de 8 KB. Dentro de cada página, cada puntero de elemento (por ejemplo, 1, 2, ….) apunta a datos dentro de la página.
- Almacenamiento de índice: Este almacenamiento almacena solo valores clave, es decir, valores de columnas contenidos por índice. Esto también se divide en varias páginas y cada página tiene un tamaño predeterminado de 8 KB.
- Identificador de tupla (TID): TID es un número de 6 bytes que consta de dos partes. La primera parte es el número de página de 4 bytes y el índice de tupla de 2 bytes restante dentro de la página. La combinación de estos dos números apunta de manera única a la ubicación de almacenamiento de una tupla en particular.
Actualmente, PostgreSQL admite los siguientes métodos de exploración mediante los cuales se pueden leer todos los datos necesarios de la tabla:
- Escaneo secuencial
- Escaneo de índice
- Escaneo de índice solamente
- Escaneo de mapa de bits
- Escaneo TID
Cada uno de estos métodos de escaneo es igualmente útil según la consulta y otros parámetros, p. cardinalidad de tabla, selectividad de tabla, costo de E/S de disco, costo de E/S aleatoria, costo de E/S de secuencia, etc. Vamos a crear una tabla preestablecida y completarla con algunos datos, que se usarán con frecuencia para explicar mejor estos métodos de escaneo .
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZEEntonces, en este ejemplo, se insertan un millón de registros y luego se analiza la tabla para que todas las estadísticas estén actualizadas.
Exploración secuencial
Como sugiere el nombre, un escaneo secuencial de una tabla se realiza escaneando secuencialmente todos los punteros de elementos de todas las páginas de las tablas correspondientes. Entonces, si hay 100 páginas para una tabla en particular y luego hay 1000 registros en cada página, como parte del escaneo secuencial obtendrá 100 * 1000 registros y verificará si coincide según el nivel de aislamiento y también según la cláusula de predicado. Entonces, incluso si solo se selecciona 1 registro como parte del escaneo de la tabla completa, tendrá que escanear 100 000 registros para encontrar un registro calificado según la condición.
Según la tabla y los datos anteriores, la siguiente consulta dará como resultado un escaneo secuencial ya que la mayoría de los datos se están seleccionando.
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)NOTA
Aunque sin calcular y comparar el costo del plan, es casi imposible saber qué tipo de escaneos se utilizarán. Pero para que se utilice el análisis secuencial, al menos los siguientes criterios deben coincidir:
- No hay índice disponible en la clave, que es parte del predicado.
- La mayoría de las filas se obtienen como parte de la consulta SQL.
CONSEJOS
En caso de que solo se obtenga un pequeño porcentaje de filas y el predicado esté en una (o más) columna, intente evaluar el rendimiento con o sin índice.
Exploración de índice
A diferencia del escaneo secuencial, el escaneo de índice no obtiene todos los registros secuencialmente. Más bien, utiliza una estructura de datos diferente (dependiendo del tipo de índice) correspondiente al índice involucrado en la consulta y ubica la cláusula de datos requeridos (según el predicado) con escaneos mínimos. Luego, la entrada que se encuentra usando el escaneo de índice apunta directamente a los datos en el área del montón (como se muestra en la figura anterior), que luego se recupera para verificar la visibilidad según el nivel de aislamiento. Entonces, hay dos pasos para el escaneo de índice:
- Obtener datos de la estructura de datos relacionada con el índice. Devuelve el TID de los datos correspondientes en el montón.
- Luego se accede directamente a la página del montón correspondiente para obtener los datos completos. Este paso adicional es necesario por las siguientes razones:
- Es posible que la consulta haya solicitado obtener más columnas de las disponibles en el índice correspondiente.
- La información de visibilidad no se mantiene junto con los datos del índice. Entonces, para verificar la visibilidad de los datos según el nivel de aislamiento, necesita acceder a los datos del montón.
Ahora podemos preguntarnos por qué no usar siempre Index Scan si es tan eficiente. Entonces, como sabemos, todo tiene un costo. Aquí el costo involucrado está relacionado con el tipo de E/S que estamos haciendo. En el caso de la exploración de índice, la E/S aleatoria está involucrada, ya que para cada registro que se encuentra en el almacenamiento de índice, tiene que obtener los datos correspondientes del almacenamiento HEAP, mientras que en el caso de la exploración secuencial, la E/S de secuencia está involucrada, lo que requiere aproximadamente solo el 25 %. de temporización de E/S aleatoria.
Por lo tanto, el escaneo de índice debe elegirse solo si la ganancia general supera la sobrecarga incurrida debido al costo de E/S aleatoria.
Según la tabla y los datos anteriores, la siguiente consulta dará como resultado un escaneo de índice ya que solo se selecciona un registro. Por lo tanto, la E/S aleatoria es menor y la búsqueda del registro correspondiente es rápida.
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15)
Index Cond: (num = '21000'::numeric)
(2 rows)Escaneo de índice solamente
Index Only Scan es similar a Index Scan excepto por el segundo paso, es decir, como su nombre lo indica, solo analiza la estructura de datos del índice. Hay dos condiciones previas adicionales para elegir Escaneo de índice solamente en comparación con Escaneo de índice:
- La consulta debe obtener solo las columnas clave que forman parte del índice.
- Todas las tuplas (registros) en la página del montón seleccionada deben estar visibles. Como se discutió en la sección anterior, la estructura de datos del índice no mantiene la información de visibilidad, por lo que para seleccionar datos solo del índice, debemos evitar verificar la visibilidad y esto podría suceder si todos los datos de esa página se consideran visibles.
La siguiente consulta dará como resultado un análisis de índice solamente. Aunque esta consulta es casi similar en términos de seleccionar el número de registros, pero como solo se selecciona el campo clave (es decir, "num"), elegirá Index Only Scan.
postgres=# explain SELECT num FROM demotable WHERE num = 21000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11)
Index Cond: (num = '21000'::numeric)
(2 rows)Escaneo de mapa de bits
La exploración de mapa de bits es una combinación de Exploración de índice y Exploración secuencial. Intenta resolver la desventaja del escaneo de índice, pero aún conserva todas sus ventajas. Como se discutió anteriormente para cada dato encontrado en la estructura de datos del índice, necesita encontrar los datos correspondientes en la página del montón. Entonces, alternativamente, debe buscar la página de índice una vez y luego seguir con la página del montón, lo que provoca una gran cantidad de E/S aleatorias. Por lo tanto, el método de escaneo de mapa de bits aprovecha el beneficio del escaneo de índice sin E/S aleatorias. Esto funciona en dos niveles como se muestra a continuación:
- Escaneo de índice de mapa de bits:primero obtiene todos los datos de índice de la estructura de datos de índice y crea un mapa de bits de todos los TID. Para una comprensión simple, puede considerar que este mapa de bits contiene un hash de todas las páginas (hash basado en el número de página) y cada entrada de página contiene una matriz de todos los desplazamientos dentro de esa página.
- Escaneo de montón de mapa de bits:como su nombre lo indica, lee el mapa de bits de las páginas y luego escanea los datos del montón correspondientes a la página almacenada y el desplazamiento. Al final, comprueba la visibilidad y el predicado, etc. y devuelve la tupla en función del resultado de todas estas comprobaciones.
La siguiente consulta dará como resultado un análisis de mapa de bits, ya que no selecciona muy pocos registros (es decir, demasiado para el análisis de índice) y, al mismo tiempo, no selecciona una gran cantidad de registros (es decir, demasiado poco para un análisis secuencial). escanear).
postgres=# explain SELECT * FROM demotable WHERE num < 210;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15)
Recheck Cond: (num < '210'::numeric)
-> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0)
Index Cond: (num < '210'::numeric)
(4 rows)Ahora considere la siguiente consulta, que selecciona la misma cantidad de registros pero solo campos clave (es decir, solo columnas de índice). Dado que solo selecciona la clave, no necesita consultar las páginas del montón para otras partes de los datos y, por lo tanto, no hay E/S aleatorias involucradas. Por lo tanto, esta consulta elegirá Escaneo de solo índice en lugar de Escaneo de mapa de bits.
postgres=# explain SELECT num FROM demotable WHERE num < 210;
QUERY PLAN
---------------------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11)
Index Cond: (num < '210'::numeric)
(2 rows)Escaneo TID
TID, como se mencionó anteriormente, es un número de 6 bytes que consta de un número de página de 4 bytes y un índice de tupla de 2 bytes restantes dentro de la página. El escaneo TID es un tipo de escaneo muy específico en PostgreSQL y se selecciona solo si hay TID en el predicado de consulta. Considere la siguiente consulta que demuestra el TID Scan:
postgres=# select ctid from demotable where id=21000;
ctid
----------
(115,42)
(1 row)
postgres=# explain select * from demotable where ctid='(115,42)';
QUERY PLAN
----------------------------------------------------------
Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15)
TID Cond: (ctid = '(115,42)'::tid)
(2 rows)Así que aquí en el predicado, en lugar de dar un valor exacto de la columna como condición, se proporciona TID. Esto es algo similar a la búsqueda basada en ROWID en Oracle.
Bonificación
Todos los métodos de escaneo son ampliamente utilizados y famosos. Además, estos métodos de escaneo están disponibles en casi todas las bases de datos relacionales. Pero hay otro método de escaneo recientemente discutido en la comunidad de PostgreSQL y también agregado recientemente en otras bases de datos relacionales. Se llama "Loose IndexScan" en MySQL, "Index Skip Scan" en Oracle y "Jump Scan" en DB2.
Este método de exploración se utiliza para un escenario específico en el que se selecciona un valor distinto de la columna clave principal del índice B-Tree. Como parte de este escaneo, evita atravesar todos los valores de columna de clave iguales, en lugar de simplemente atravesar el primer valor único y luego saltar al siguiente grande.
Este trabajo todavía está en progreso en PostgreSQL con el nombre tentativo de "Escaneo de omisión de índice" y podemos esperar verlo en una versión futura.