Esta es la decimotercera y última entrega de una serie sobre expresiones de tablas. Este mes continúo la discusión que comencé el mes pasado sobre las funciones con valores de tabla en línea (iTVF).
El mes pasado expliqué que cuando SQL Server inserta iTVF que se consultan con constantes como entradas, aplica la optimización de incrustación de parámetros de forma predeterminada. La incrustación de parámetros significa que SQL Server reemplaza las referencias de parámetros en la consulta con los valores constantes literales de la ejecución actual, y luego se optimiza el código con las constantes. Este proceso permite simplificaciones que pueden resultar en planes de consulta más óptimos. Este mes profundizo en el tema, cubriendo casos específicos para tales simplificaciones como el plegado constante y el filtrado y orden dinámico. Si necesita refrescar la optimización de la integración de parámetros, consulte el artículo del mes pasado, así como el excelente artículo de Paul White, Análisis de parámetros, integración y opciones de RECOMPILE.
En mis ejemplos, usaré una base de datos de muestra llamada TSQLV5. Puede encontrar el script que lo crea y lo completa aquí y su diagrama ER aquí.
Plegado constante
Durante las primeras etapas del procesamiento de consultas, SQL Server evalúa ciertas expresiones que involucran constantes y las incorpora a las constantes de resultado. Por ejemplo, la expresión 40 + 2 se puede doblar a la constante 42. Puede encontrar las reglas para expresiones plegables y no plegables aquí en "Evaluación de expresión y plegado constante".
Lo interesante con respecto a los iTVF es que, gracias a la optimización de incrustación de parámetros, las consultas que involucran iTVF en las que pasa constantes como entradas pueden, en las circunstancias adecuadas, beneficiarse del plegado constante. Conocer las reglas para expresiones plegables y no plegables puede afectar la forma en que implementa sus iTVF. En algunos casos, al aplicar cambios muy sutiles a sus expresiones, puede habilitar planes más óptimos con una mejor utilización de la indexación.
Como ejemplo, considere la siguiente implementación de un iTVF llamado Sales.MyOrders:
USE TSQLV5;
GO
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT orderid + @add - @subtract AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GO Emita la siguiente consulta relacionada con el iTVF (me referiré a esto como Consulta 1):
SELECT myorderid, orderdate, custid, empid FROM Sales.MyOrders(1, 10248) ORDER BY myorderid;
El plan para la Consulta 1 se muestra en la Figura 1.
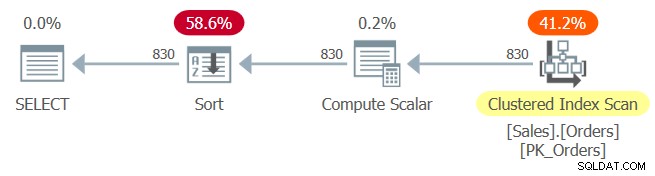 Figura 1:Plan para Consulta 1
Figura 1:Plan para Consulta 1
El índice agrupado PK_Orders se define con orderid como clave. Si se hubiera producido un plegamiento constante aquí después de la incrustación de parámetros, la expresión de orden orderid + 1 – 10248 se habría doblado a orderid – 10247. Esta expresión se habría considerado una expresión que preserva el orden con respecto a orderid, y como tal habría permitido la optimizador para confiar en el orden del índice. Por desgracia, ese no es el caso, como lo demuestra el operador Ordenar explícito en el plan. ¿Entonces qué pasó?
Las reglas de plegado constantes son delicadas. La expresión columna1 + constante1 – constante2 se evalúa de izquierda a derecha para el plegado constante. La primera parte, columna1 + constante1 no se pliega. Llamemos a esta expresión1. La siguiente parte que se evalúa se trata como expresión1 – constante2, que tampoco se pliega. Sin el plegado, una expresión en la forma columna1 + constante1 – constante2 no se considera que conserva el orden con respecto a la columna1 y, por lo tanto, no puede confiar en el ordenamiento del índice incluso si tiene un índice de apoyo en la columna1. De manera similar, la expresión constante1 + columna1 – constante2 no es plegable constante. Sin embargo, la expresión constante1 – constante2 + columna1 es plegable. Más específicamente, la primera parte constante1 – constante2 se pliega en una sola constante (llamémosla constante3), lo que da como resultado la expresión constante3 + columna1. Esta expresión se considera una expresión que preserva el orden con respecto a la columna1. Entonces, siempre que se asegure de escribir su expresión usando la última forma, puede habilitar el optimizador para que se base en el ordenamiento de índices.
Considere las siguientes consultas (me referiré a ellas como Consulta 2, Consulta 3 y Consulta 4), y antes de mirar los planes de consulta, vea si puede saber cuál implicará una clasificación explícita en el plan y cuál no:
-- Query 2 SELECT orderid + 1 - 10248 AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid; -- Query 3 SELECT 1 + orderid - 10248 AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid; -- Query 4 SELECT 1 - 10248 + orderid AS myorderid, orderdate, custid, empid FROM Sales.Orders ORDER BY myorderid;
Ahora examine los planes para estas consultas como se muestra en la Figura 2.
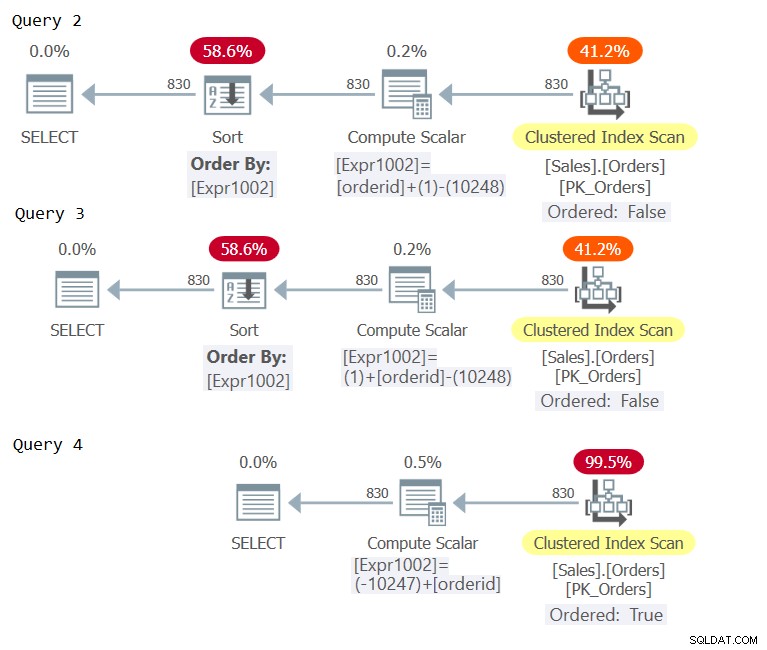 Figura 2:Planes para Consulta 2, Consulta 3 y Consulta 4
Figura 2:Planes para Consulta 2, Consulta 3 y Consulta 4
Examine los operadores Compute Scalar en los tres planes. Solo el plan para la consulta 4 incurrió en plegamiento constante, lo que resultó en una expresión de orden que se considera que preserva el orden con respecto a orderid, evitando la ordenación explícita.
Al comprender este aspecto del plegado constante, puede arreglar fácilmente el iTVF cambiando la expresión orderid + @add – @subtract a @add – @subtract + orderid, así:
CREATE OR ALTER FUNCTION Sales.MyOrders
( @add AS INT, @subtract AS INT )
RETURNS TABLE
AS
RETURN
SELECT @add - @subtract + orderid AS myorderid,
orderdate, custid, empid
FROM Sales.Orders;
GO Consulta la función de nuevo (me referiré a esto como Consulta 5):
SELECT myorderid, orderdate, custid, empid FROM Sales.MyOrders(1, 10248) ORDER BY myorderid;
El plan para esta consulta se muestra en la Figura 3.
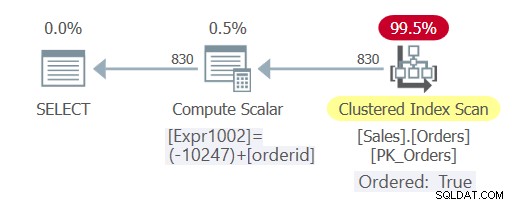 Figura 3:Plan para Consulta 5
Figura 3:Plan para Consulta 5
Como puede ver, esta vez la consulta experimentó un plegamiento constante y el optimizador pudo confiar en la ordenación de índices, evitando la ordenación explícita.
Usé un ejemplo simple para demostrar esta técnica de optimización y, como tal, puede parecer un poco artificial. Puede encontrar una aplicación práctica de esta técnica en el artículo Soluciones del desafío del generador de series numéricas - Parte 1.
Filtrado dinámico/Ordenamiento
El mes pasado cubrí la diferencia entre la forma en que SQL Server optimiza una consulta en un iTVF frente a la misma consulta en un procedimiento almacenado. SQL Server normalmente aplicará la optimización de incrustación de parámetros de manera predeterminada para una consulta que involucre un iTVF con constantes como entradas, pero optimizará la forma parametrizada de una consulta en un procedimiento almacenado. Sin embargo, si agrega OPTION(RECOMPILE) a la consulta en el procedimiento almacenado, SQL Server normalmente también aplicará la optimización de incrustación de parámetros en este caso. Los beneficios en el caso de iTVF incluyen el hecho de que puede involucrarlo en una consulta y, siempre que pase la repetición de entradas constantes, existe la posibilidad de reutilizar un plan previamente almacenado en caché. Con un procedimiento almacenado, no puede involucrarlo en una consulta, y si agrega OPCIÓN (RECOMPILAR) para obtener la optimización de incrustación de parámetros, no hay posibilidad de reutilización del plan. El procedimiento almacenado permite mucha más flexibilidad en cuanto a los elementos de código que puede utilizar.
Veamos cómo se desarrolla todo esto en una tarea clásica de incrustación y ordenación de parámetros. A continuación, se muestra un procedimiento almacenado simplificado que aplica filtrado dinámico y clasificación similar al que usó Paul en su artículo:
CREATE OR ALTER PROCEDURE HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT AS SET NOCOUNT ON; SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL ORDER BY CASE WHEN @sort = 1 THEN empid END, CASE WHEN @sort = 2 THEN firstname END, CASE WHEN @sort = 3 THEN lastname END; GO
Observe que la implementación actual del procedimiento almacenado no incluye OPCIÓN (RECOMPILAR) en la consulta.
Considere la siguiente ejecución del procedimiento almacenado:
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;
El plan para esta ejecución se muestra en la Figura 4.
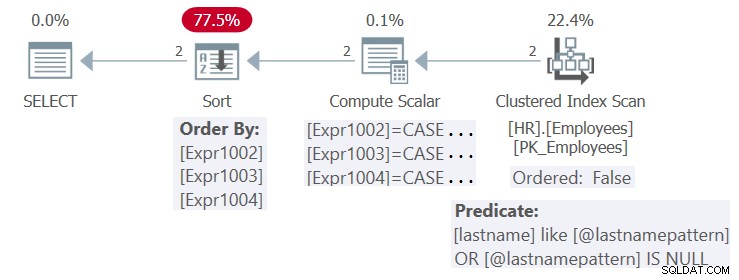 Figura 4:Plan para el procedimiento HR.GetEmpsP
Figura 4:Plan para el procedimiento HR.GetEmpsP
Hay un índice definido en la columna del apellido. Teóricamente, con las entradas actuales, el índice podría ser beneficioso tanto para las necesidades de filtrado (con una búsqueda) como de ordenación (con un escaneo ordenado:rango verdadero) de la consulta. Sin embargo, dado que de forma predeterminada SQL Server optimiza la forma parametrizada de la consulta y no aplica la incrustación de parámetros, no aplica las simplificaciones necesarias para poder beneficiarse del índice con fines de filtrado y ordenación. Entonces, el plan es reutilizable, pero no es óptimo.
Para ver cómo cambian las cosas con la optimización de incrustación de parámetros, modifique la consulta del procedimiento almacenado agregando OPTION(RECOMPILE), así:
CREATE OR ALTER PROCEDURE HR.GetEmpsP @lastnamepattern AS NVARCHAR(50), @sort AS TINYINT AS SET NOCOUNT ON; SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL ORDER BY CASE WHEN @sort = 1 THEN empid END, CASE WHEN @sort = 2 THEN firstname END, CASE WHEN @sort = 3 THEN lastname END OPTION(RECOMPILE); GO
Ejecute el procedimiento almacenado nuevamente con las mismas entradas que usó antes:
EXEC HR.GetEmpsP @lastnamepattern = N'D%', @sort = 3;
El plan para esta ejecución se muestra en la Figura 5.
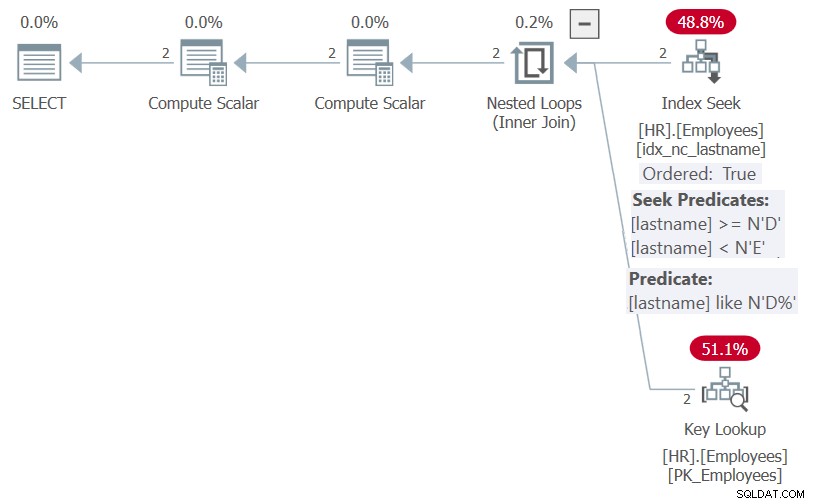 Figura 5:Plan para el procedimiento HR.GetEmpsP con OPCIÓN (RECOMPILE)
Figura 5:Plan para el procedimiento HR.GetEmpsP con OPCIÓN (RECOMPILE)
Como puede ver, gracias a la optimización de incrustación de parámetros, SQL Server pudo simplificar el predicado de filtro al predicado sargable lastname LIKE N'D%', y la lista de pedidos a NULL, NULL, lastname. Ambos elementos podrían beneficiarse del índice en el apellido y, por lo tanto, el plan muestra una búsqueda en el índice y no una clasificación explícita.
Teóricamente, espera poder obtener una simplificación similar si implementa la consulta en un iTVF y, por lo tanto, beneficios de optimización similares, pero con la capacidad de reutilizar los planes almacenados en caché cuando se reutilizan los mismos valores de entrada. Entonces, intentemos...
Aquí hay un intento de implementar la misma consulta en un iTVF (no ejecute este código todavía):
CREATE OR ALTER FUNCTION HR.GetEmpsF
(
@lastnamepattern AS NVARCHAR(50),
@sort AS TINYINT
)
RETURNS TABLE
AS
RETURN
SELECT empid, firstname, lastname
FROM HR.Employees
WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL
ORDER BY
CASE WHEN @sort = 1 THEN empid END,
CASE WHEN @sort = 2 THEN firstname END,
CASE WHEN @sort = 3 THEN lastname END;
GO Antes de intentar ejecutar este código, ¿puede ver algún problema con esta implementación? Recuerde que al principio de esta serie expliqué que una expresión de tabla es una tabla. El cuerpo de una tabla es un conjunto (o multiconjunto) de filas y, como tal, no tiene orden. Por lo tanto, normalmente, una consulta utilizada como expresión de tabla no puede tener una cláusula ORDER BY. De hecho, si intenta ejecutar este código, obtendrá el siguiente error:
Mensaje 1033, Nivel 15, Estado 1, Procedimiento GetEmps, Línea 16 [Batch Start Line 128]La cláusula ORDER BY no es válida en vistas, funciones en línea, tablas derivadas, subconsultas y expresiones de tablas comunes, a menos que TOP, OFFSET o FOR XML también se especifica.
Claro, como dice el error, SQL Server hará una excepción si usa un elemento de filtrado como TOP o OFFSET-FETCH, que se basa en la cláusula ORDER BY para definir el aspecto de orden del filtro. Pero incluso si incluye una cláusula ORDER BY en la consulta interna gracias a esta excepción, aún no obtiene una garantía del orden del resultado en una consulta externa contra la expresión de la tabla, a menos que tenga su propia cláusula ORDER BY. .
Si aún desea implementar la consulta en un iTVF, puede hacer que la consulta interna maneje la parte de filtrado dinámico, pero no el orden dinámico, así:
CREATE OR ALTER FUNCTION HR.GetEmpsF ( @lastnamepattern AS NVARCHAR(50) ) RETURNS TABLE AS RETURN SELECT empid, firstname, lastname FROM HR.Employees WHERE lastname LIKE @lastnamepattern OR @lastnamepattern IS NULL; GO
Por supuesto, puede hacer que la consulta externa maneje cualquier necesidad de pedido específica, como en el siguiente código (me referiré a esto como Consulta 6):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(N'D%') ORDER BY lastname;
El plan para esta consulta se muestra en la Figura 6.
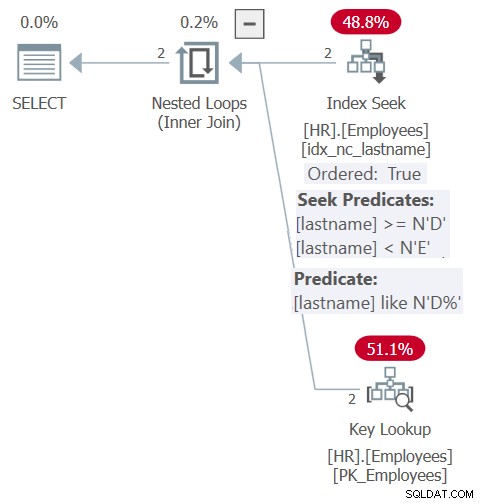 Figura 6:Plan para Consulta 6
Figura 6:Plan para Consulta 6
Gracias a la integración y la incrustación de parámetros, el plan es similar al que se mostró anteriormente para la consulta del procedimiento almacenado en la Figura 5. El plan se basa de manera eficiente en el índice para fines de filtrado y ordenación. Sin embargo, no obtiene la flexibilidad de la entrada de pedidos dinámica como la que tenía con el procedimiento almacenado. Debe ser explícito con el orden en la cláusula ORDER BY en la consulta contra la función.
El siguiente ejemplo tiene una consulta contra la función sin filtrado y sin requisitos de pedido (me referiré a esto como Consulta 7):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(NULL);
El plan para esta consulta se muestra en la Figura 7.
 Figura 7:Plan para Consulta 7
Figura 7:Plan para Consulta 7
Después de la integración y la incrustación de parámetros, la consulta se simplifica para que no tenga predicado de filtro ni orden, y se optimiza con un análisis completo sin ordenar del índice agrupado.
Finalmente, consulte la función con N'D%' como el patrón de filtrado de apellido de entrada y ordene el resultado por la columna de nombre (me referiré a esto como Consulta 8):
SELECT empid, firstname, lastname FROM HR.GetEmpsF(N'D%') ORDER BY firstname;
El plan para esta consulta se muestra en la Figura 8.
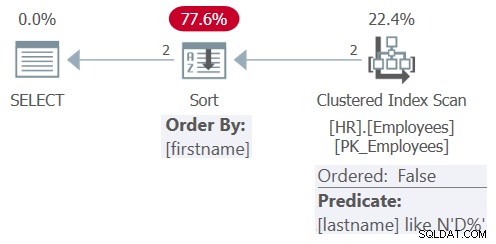 Figura 8:Plan para Consulta 8
Figura 8:Plan para Consulta 8
Después de la simplificación, la consulta implica solo el apellido del predicado de filtrado LIKE N'D%' y el nombre del elemento de ordenación. Esta vez, el optimizador opta por aplicar un análisis desordenado del índice agrupado, con el predicado residual lastname LIKE N'D%', seguido de una clasificación explícita. Decidió no aplicar una búsqueda en el índice en el apellido porque el índice no cubre uno, la tabla es muy pequeña y el orden del índice no es beneficioso para las necesidades actuales de orden de consultas. Además, no hay un índice definido en la columna de nombre, por lo que se debe aplicar una ordenación explícita de todos modos.
Conclusión
La optimización de incrustación de parámetros predeterminada de los iTVF también puede dar como resultado un plegado constante, lo que permite planes más óptimos. Sin embargo, debe tener en cuenta las reglas de plegado constantes para determinar cómo formular mejor sus expresiones.
La implementación de la lógica en un iTVF tiene ventajas y desventajas en comparación con la implementación de la lógica en un procedimiento almacenado. Si no está interesado en la optimización de incrustación de parámetros, la optimización de consulta parametrizada predeterminada de los procedimientos almacenados puede generar un comportamiento de reutilización y almacenamiento en caché de planes más óptimo. En los casos en los que esté interesado en la optimización de incrustación de parámetros, normalmente la obtiene de forma predeterminada con iTVF. Para obtener esta optimización con procedimientos almacenados, debe agregar la opción de consulta RECOMPILE, pero luego no obtendrá la reutilización del plan. Al menos con iTVF, puede obtener la reutilización del plan siempre que se repitan los mismos valores de parámetro. Por otra parte, tiene menos flexibilidad con los elementos de consulta que puede usar en un iTVF; por ejemplo, no puede tener una cláusula ORDER BY de presentación.
Volviendo a toda la serie sobre expresiones de tablas, creo que el tema es muy importante para los profesionales de las bases de datos. La serie más completa incluye la subserie en el generador de series de números, que se implementa como un iTVF. En total, la serie incluye las siguientes 19 partes:
- Fundamentos de las expresiones de tabla, Parte 1
- Fundamentos de las expresiones de tablas, Parte 2:tablas derivadas, consideraciones lógicas
- Fundamentos de las expresiones de tablas, Parte 3:tablas derivadas, consideraciones de optimización
- Fundamentos de las expresiones de tablas, Parte 4:tablas derivadas, consideraciones de optimización, continuación
- Fundamentos de las expresiones de tablas, Parte 5:CTE, consideraciones lógicas
- Fundamentos de expresiones de tabla, Parte 6:CTE recursivos
- Fundamentos de las expresiones de tabla, Parte 7:CTE, consideraciones de optimización
- Fundamentos de las expresiones de tablas, Parte 8:CTE, consideraciones de optimización, continuación
- Fundamentos de expresiones de tabla, Parte 9:Vistas, en comparación con tablas derivadas y CTE
- Fundamentos de las expresiones de tabla, Parte 10:Vistas, SELECT * y cambios DDL
- Fundamentos de expresiones de tabla, parte 11:vistas, consideraciones de modificación
- Fundamentos de expresiones de tabla, parte 12:funciones con valores de tabla en línea
- Fundamentos de expresiones de tabla, parte 13:funciones con valores de tabla en línea, continuación
- ¡El desafío está en marcha! Convocatoria comunitaria para crear el generador de series numéricas más rápido
- Soluciones para el desafío del generador de series de números:parte 1
- Soluciones para el desafío del generador de series de números:parte 2
- Soluciones del desafío del generador de series de números:parte 3
- Soluciones del desafío del generador de series de números:Parte 4
- Soluciones para el desafío del generador de series de números:Parte 5



