Failover es la capacidad de un sistema para continuar funcionando incluso si ocurre alguna falla. Sugiere que las funciones del sistema sean asumidas por componentes secundarios si los componentes primarios fallan o si es necesario. Entonces, si lo traduce a un entorno de múltiples nubes de PostgreSQL, significa que cuando su nodo principal falla (u otra razón, como mencionaremos en la siguiente sección) en su proveedor de nube principal, debe poder promocionar el nodo en espera en el secundario para mantener los sistemas en funcionamiento.
En general, todos los proveedores de la nube le brindan una opción de conmutación por error en el mismo proveedor de la nube, pero es posible que necesite una conmutación por error a otro proveedor de la nube diferente. Por supuesto, puede hacerlo manualmente, pero también puede usar algunas de las funciones de ClusterControl, como la conmutación por error automática o promover la acción de esclavos, para que esto sea fácil y amigable.
En este blog, verá por qué debería necesitar conmutación por error, cómo hacerlo manualmente y cómo usar ClusterControl para esta tarea. Asumiremos que tiene una instalación de ClusterControl en ejecución y que ya ha creado su clúster de base de datos en dos proveedores de nube diferentes.
¿Para qué se utiliza la conmutación por error?
Hay varios usos posibles de la conmutación por error.
Falla maestra
Si su nodo principal está inactivo o incluso si su proveedor de nube principal tiene algunos problemas, debe realizar la conmutación por error para garantizar la disponibilidad de su sistema. En este caso, podría ser necesario tener una forma automática de hacerlo para disminuir el tiempo de inactividad.
Migración
Si desea migrar sus sistemas de un proveedor de nube a otro minimizando el tiempo de inactividad, puede utilizar la conmutación por error. Puede crear una réplica en el proveedor de la nube secundario y, una vez sincronizada, debe detener su sistema, promocionar su réplica y realizar la conmutación por error antes de apuntar su sistema al nuevo nodo principal en el proveedor de la nube secundario.
Mantenimiento
Si necesita realizar alguna tarea de mantenimiento en su nodo principal de PostgreSQL, puede promocionar su réplica, realizar la tarea y reconstruir su antiguo principal como un nodo de reserva.
Después de esto, puede promocionar el principal antiguo y repetir el proceso de reconstrucción en el nodo en espera, volviendo al estado inicial.
De esta forma, podrías trabajar en tu servidor, sin correr el riesgo de quedarte desconectado o perder información mientras realizas alguna tarea de mantenimiento.
Actualizaciones
Es posible actualizar su versión de PostgreSQL (desde PostgreSQL 10) o incluso actualizar su sistema operativo usando replicación lógica sin tiempo de inactividad, como se puede hacer con otros motores.
Los pasos serían los mismos que para migrar a un nuevo proveedor de nube, solo que su réplica estaría en una versión más nueva de PostgreSQL o sistema operativo y necesita usar la replicación lógica ya que no puede usar la transmisión replicación entre diferentes versiones.
Failover no se trata solo de la base de datos, sino también de la aplicación. ¿Cómo saben a qué base de datos conectarse? Probablemente no quiera tener que modificar su aplicación, ya que esto solo extenderá su tiempo de inactividad, por lo que puede configurar un Load Balancer que cuando su nodo principal esté inactivo, señalará automáticamente al servidor que se promocionó.
Tener una sola instancia de Load Balancer no es la mejor opción, ya que puede convertirse en un único punto de falla. Por lo tanto, también puede implementar la conmutación por error para Load Balancer, utilizando un servicio como Keepalived. De esta forma, si tienes un problema con tu Load Balancer principal, Keepalived migrará la IP Virtual a tu Load Balancer secundario, y todo seguirá funcionando de forma transparente.
Otra opción es el uso de DNS. Al promocionar el nodo en espera en el proveedor de la nube secundario, modifica directamente la dirección IP del nombre de host que apunta al nodo principal. De esta forma, evitas tener que modificar tu aplicación, y aunque no se puede hacer de forma automática, es una alternativa si no quieres implementar un Load Balancer.
Cómo conmutar por error PostgreSQL manualmente
Antes de realizar una conmutación por error manual, debe verificar el estado de la replicación. Es posible que, cuando necesite una conmutación por error, el nodo en espera no esté actualizado debido a una falla en la red, una carga alta u otro problema, por lo que debe asegurarse de que su nodo en espera tenga todos (o casi). toda la información. Si tiene más de un nodo en espera, también debe verificar cuál es el nodo más avanzado y elegirlo para la conmutación por error.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Cuando elige el nuevo nodo principal, primero puede ejecutar el comando pg_lsclusters para obtener la información del clúster:
$ pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
12 main 5432 online,recovery postgres /var/lib/postgresql/12/main log/postgresql-%Y-%m-%d_%H%M%S.logLuego, solo necesita ejecutar el comando pg_ctlcluster con la acción de promoción:
$ pg_ctlcluster 12 main promoteEn lugar del comando anterior, puede ejecutar el comando pg_ctl de esta manera:
$ /usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main/
waiting for server to promote.... done
server promotedLuego, su nodo en espera se promocionará a principal y podrá validarlo ejecutando la siguiente consulta en su nuevo nodo principal:
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Si el resultado es "f", es su nuevo nodo principal.
Ahora, debe cambiar la dirección IP de la base de datos principal en su aplicación, Load Balancer, DNS o la implementación que está utilizando, que, como mencionamos, cambiar esto manualmente aumentará el tiempo de inactividad. También debe asegurarse de que su conectividad entre los proveedores de la nube funcione correctamente, la aplicación puede acceder al nuevo nodo principal, el usuario de la aplicación tiene privilegios para acceder desde un proveedor de nube diferente y debe reconstruir los nodos en espera en el remoto o incluso en el proveedor de la nube local, para replicar desde el nuevo principal; de lo contrario, no tendrá una nueva opción de conmutación por error si es necesario.
Cómo conmutar por error PostgreSQL usando ClusterControl
ClusterControl tiene una serie de características relacionadas con la replicación de PostgreSQL y la conmutación por error automatizada. Asumiremos que tiene instalado su servidor ClusterControl y que está administrando su entorno Multi-Cloud PostgreSQL.
Con ClusterControl, puede agregar tantos nodos en espera o nodos Load Balancer como necesite sin ninguna restricción de IP de red. Significa que no es necesario que el nodo en espera esté en la misma red de nodos primarios o incluso en el mismo proveedor de nube. En términos de conmutación por error, ClusterControl le permite hacerlo de forma manual o automática.
Conmutación por error manual
Para realizar una conmutación por error manual, vaya a ClusterControl -> Seleccionar clúster -> Nodos, y en Acciones de nodo de uno de sus nodos en espera, seleccione "Promocionar esclavo".
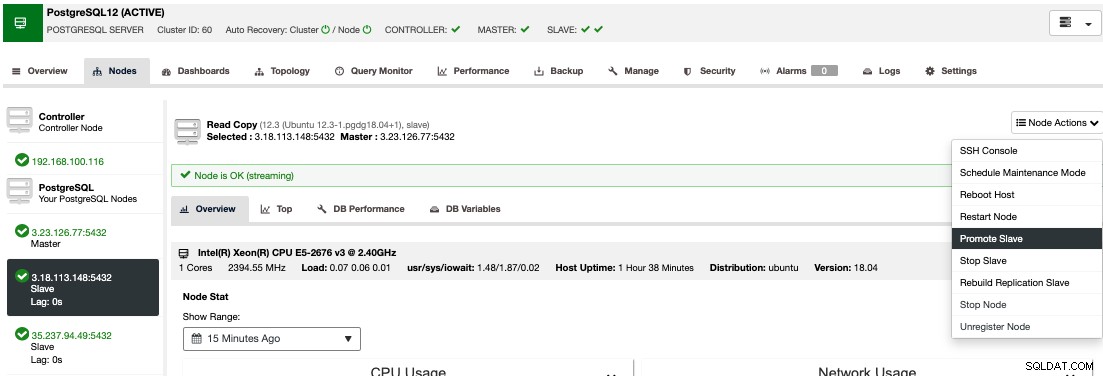
De esta manera, después de unos segundos, su nodo de reserva se convierte en principal, y lo que antes era su principal, se convierte en uno de reserva. Por lo tanto, si su réplica estaba en otro proveedor de nube, su nuevo nodo principal estará allí, en funcionamiento.
Conmutación automática por error
En el caso de una conmutación por error automática, ClusterControl detecta fallas en el nodo principal y promueve un nodo en espera con los datos más actuales como el nuevo principal. También funciona en el resto de los nodos en espera para que se repliquen desde este nuevo primario.

Con la opción "Autorecovery" activada, ClusterControl realizará una conmutación por error automática como así como notificarle del problema. De esta manera, sus sistemas pueden recuperarse en segundos y sin su intervención.
ClusterControl le ofrece la posibilidad de configurar una lista blanca/lista negra para definir cómo desea que se tengan (o no) en cuenta sus servidores al decidir sobre un candidato principal.
ClusterControl también realiza varias comprobaciones sobre el proceso de conmutación por error, por ejemplo, de forma predeterminada, si logra recuperar su antiguo nodo principal fallido, no se reintroducirá automáticamente en el clúster, ni como principal ni como modo de espera, deberá hacerlo manualmente. Esto evitará la posibilidad de pérdida de datos o inconsistencias en el caso de que su standby (que promovió) se retrasó en el momento de la falla. También es posible que desee analizar el problema en detalle, pero al agregarlo a su clúster, es posible que pierda información de diagnóstico.
Equilibradores de carga
Como mencionamos anteriormente, Load Balancer es una herramienta importante a considerar para su conmutación por error, especialmente si desea utilizar la conmutación por error automática en la topología de su base de datos.
Para que la conmutación por error sea transparente tanto para el usuario como para la aplicación, necesita un componente intermedio, ya que no es suficiente promover un nuevo nodo principal. Para ello, puedes utilizar HAProxy + Keepalived.
Para implementar esta solución con ClusterControl, vaya a Acciones de clúster -> Agregar equilibrador de carga -> HAProxy en su clúster de PostgreSQL. En el caso de que desee implementar la conmutación por error para su Load Balancer, debe configurar al menos dos instancias HAProxy y luego puede configurar Keepalived (Cluster Actions -> Add Load Balancer -> Keepalived). Puede encontrar más información sobre esta implementación en esta publicación de blog.
Después de esto, tendrá la siguiente topología:

HAProxy está configurado de forma predeterminada con dos puertos diferentes, uno de lectura y escritura y uno de solo lectura.
En el puerto de lectura y escritura, tiene su nodo principal en línea y el resto de los nodos en línea. En el puerto de solo lectura, tiene en línea tanto el nodo principal como el de reserva. De esta forma, puede equilibrar el tráfico de lectura entre los nodos. Al escribir, se utilizará el puerto de lectura y escritura, que apuntará al nodo principal actual.

Cuando HAProxy detecta que uno de los nodos, ya sea principal o en espera, está no accesible, lo marca automáticamente como fuera de línea. HAProxy no le enviará ningún tráfico. Esta verificación se realiza mediante secuencias de comandos de verificación de estado configuradas por ClusterControl en el momento de la implementación. Estos comprueban si las instancias están activas, si se están recuperando o si son de solo lectura.
Cuando ClusterControl promueve un nuevo nodo principal, HAProxy marca el anterior como fuera de línea (para ambos puertos) y pone el nodo promovido en línea en el puerto de lectura y escritura. De esta manera, sus sistemas continúan funcionando con normalidad.
Si el HAProxy activo (que ha asignado una dirección IP virtual a la que se conectan sus sistemas) falla, Keepalived migra esta IP virtual al HAProxy pasivo automáticamente. Esto significa que sus sistemas podrán continuar funcionando normalmente.
Replicación de clúster a clúster en la nube
Para tener un entorno de múltiples nubes, puede usar la acción Agregar esclavo de ClusterControl sobre su clúster de PostgreSQL, pero también la función de replicación de clúster a clúster. Por el momento, esta característica tiene una limitación para PostgreSQL que le permite tener solo un nodo remoto, pero estamos trabajando para eliminar esa limitación pronto en una versión futura.
Para implementarlo, puede consultar la sección "Replicación de clúster a clúster en la nube" en esta publicación de blog.

Cuando esté en su lugar, puede promocionar el clúster remoto que generará un clúster de PostgreSQL independiente con un nodo principal que se ejecuta en el proveedor de nube secundario.

Entonces, en caso de que lo necesite, tendrá el mismo clúster ejecutándose en un nuevo proveedor de nube en solo unos segundos.
Conclusión
Tener un proceso de conmutación por error automático es obligatorio si desea tener el menor tiempo de inactividad posible, y también usar diferentes tecnologías como HAProxy y Keepalived mejorará esta conmutación por error.
Las funciones de ClusterControl que mencionamos anteriormente le permitirán realizar una conmutación por error rápida entre diferentes proveedores de la nube y administrar la configuración de una manera fácil y amigable.
Lo más importante a tener en cuenta antes de realizar un proceso de conmutación por error entre diferentes proveedores de la nube es la conectividad. Debe asegurarse de que su aplicación o las conexiones de su base de datos funcionen como de costumbre utilizando el proveedor de la nube principal pero también el secundario en caso de conmutación por error y, por razones de seguridad, debe restringir el tráfico solo de fuentes conocidas, por lo que solo entre la nube. Proveedores y no permitirlo de ninguna fuente externa.