La replicación híbrida, es decir, combinar Galera y la replicación asincrónica de MySQL en la misma configuración, se volvió mucho más fácil desde que se introdujo GTID en MySQL 5.6. Aunque fue bastante sencillo replicar desde un servidor MySQL independiente a un Galera Cluster, hacerlo al revés (Galera → MySQL independiente) fue un poco más desafiante. Al menos hasta la llegada de GTID.
Hay algunas buenas razones para adjuntar un esclavo asíncrono a un Galera Cluster. Por un lado, las consultas de tipo OLAP/informe de ejecución prolongada en un nodo de Galera pueden ralentizar todo un clúster, si la carga de informes es tan intensa que el nodo tiene que dedicar un esfuerzo considerable a lidiar con ella. Por lo tanto, las consultas de informes se pueden enviar a un servidor independiente, aislando efectivamente a Galera de la carga de informes. En un enfoque de cinturones y tirantes, un esclavo asíncrono también puede servir como respaldo remoto en vivo.
En esta publicación de blog, le mostraremos cómo replicar un Galera Cluster en un servidor MySQL con GTID y cómo conmutar por error la replicación en caso de que falle el nodo maestro.
Replicación híbrida en MySQL 5.5
En MySQL 5.5, reanudar una replicación interrumpida requiere que determine el último archivo de registro binario y la posición, que son distintos en todos los nodos de Galera si el registro binario está habilitado. Podemos ilustrar esta situación con la siguiente figura:
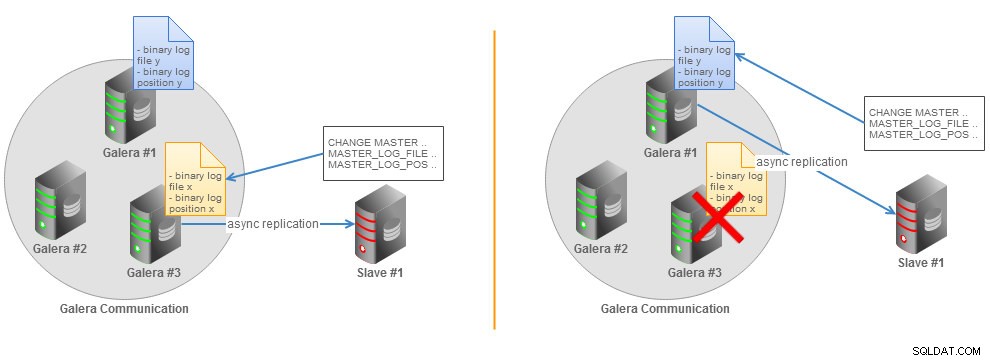 Topología de esclavo asíncrono de clúster de Galera sin GTID
Topología de esclavo asíncrono de clúster de Galera sin GTID Si el maestro MySQL falla, la replicación se interrumpe y el esclavo deberá cambiar a otro maestro. Deberá elegir un nuevo nodo Galera y determinar manualmente un nuevo archivo de registro binario y la posición de la última transacción ejecutada por el esclavo. Otra opción es volcar los datos del nuevo nodo maestro, restaurarlos en el esclavo e iniciar la replicación con el nuevo nodo maestro. Estas opciones son, por supuesto, factibles, pero no muy prácticas en producción.
Cómo GTID resuelve el problema
GTID (Identificador de transacción global) proporciona un mejor mapeo de transacciones entre nodos y es compatible con MySQL 5.6. En Galera Cluster, todos los nodos generarán diferentes archivos binlog. Los eventos binlog son los mismos y están en el mismo orden, pero los nombres de los archivos binlog y las compensaciones pueden variar. Con GTID, los esclavos pueden ver una transacción única proveniente de varios maestros y esto podría asignarse fácilmente a la lista de ejecución de esclavos si necesita reiniciar o reanudar la replicación.
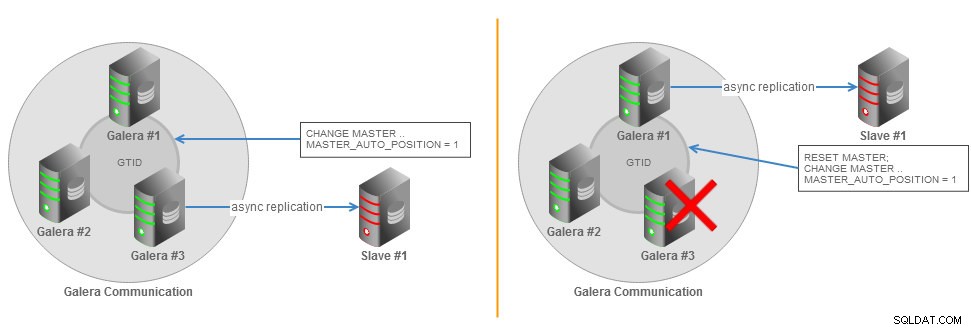 Topología de esclavo asíncrono de clúster de Galera con conmutación por error de GTID
Topología de esclavo asíncrono de clúster de Galera con conmutación por error de GTID Toda la información necesaria para sincronizar con el maestro se obtiene directamente del flujo de replicación. Esto significa que cuando usa GTID para la replicación, no necesita incluir las opciones MASTER_LOG_FILE o MASTER_LOG_POS en la instrucción CHANGE MASTER TO. En su lugar, solo es necesario habilitar la opción MASTER_AUTO_POSITION. Puede encontrar más detalles sobre el GTID en la página de documentación de MySQL.
Configuración manual de la replicación híbrida
Asegúrese de que los nodos Galera (maestros) y esclavos se estén ejecutando en MySQL 5.6 antes de continuar con esta configuración. Tenemos una base de datos llamada sbtest en Galera, que replicaremos en el nodo esclavo.
1. Habilite las opciones de replicación necesarias especificando las siguientes líneas dentro de my.cnf de cada nodo de base de datos (incluido el nodo esclavo):
Para nodos maestros (Galera):
gtid_mode=ON
log_bin=binlog
log_slave_updates=1
enforce_gtid_consistency
expire_logs_days=7
server_id=1 # 1 for master1, 2 for master2, 3 for master3
binlog_format=ROWPara nodo esclavo:
gtid_mode=ON
log_bin=binlog
log_slave_updates=1
enforce_gtid_consistency
expire_logs_days=7
server_id=101 # 101 for slave
binlog_format=ROW
replicate_do_db=sbtest
slave_net_timeout=602. Realice un reinicio continuo del clúster de Galera Cluster (desde la interfaz de usuario de ClusterControl> Administrar> Actualizar> Reinicio continuo). Esto recargará cada nodo con las nuevas configuraciones y habilitará GTID. Reinicie el esclavo también.
3. Cree un usuario de replicación esclavo y ejecute la siguiente instrucción en uno de los nodos de Galera:
mysql> GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' IDENTIFIED BY 'slavepassword';4. Inicie sesión en la base de datos esclava y de volcado sbtest desde uno de los nodos de Galera:
$ mysqldump -uroot -p -h192.168.0.201 --single-transaction --skip-add-locks --triggers --routines --events sbtest > sbtest.sql5. Restaure el archivo de volcado en el servidor esclavo:
$ mysql -uroot -p < sbtest.sql6. Inicie la replicación en el nodo esclavo:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.201', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Para verificar que la replicación se está ejecutando correctamente, examine la salida del estado del esclavo:
mysql> SHOW SLAVE STATUS\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...Configuración de la replicación híbrida mediante ClusterControl
En el párrafo anterior, describimos todos los pasos necesarios para habilitar los registros binarios, reiniciar el clúster nodo por nodo, copiar los datos y luego configurar la replicación. El procedimiento es una tarea tediosa y fácilmente puede cometer errores en uno de estos pasos. En ClusterControl hemos automatizado todos los pasos necesarios.
1. Para los usuarios de ClusterControl, puede ir a los nodos en la página Nodos y habilitar el registro binario.
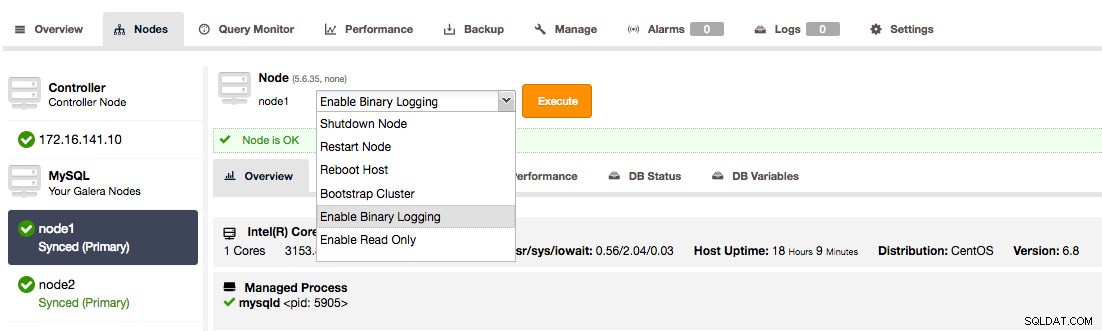 Habilite el registro binario en el clúster de Galera mediante ClusterControl
Habilite el registro binario en el clúster de Galera mediante ClusterControl Esto abrirá un cuadro de diálogo que le permitirá establecer la caducidad del registro binario, habilitar GTID y reinicio automático.
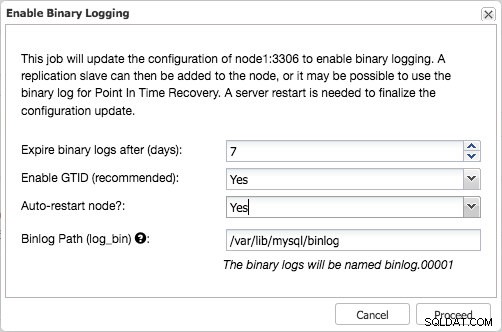 Habilitar registro binario con GTID habilitado
Habilitar registro binario con GTID habilitado Esto inicia un trabajo que escribirá de forma segura estos cambios en la configuración, creará usuarios de replicación con las concesiones adecuadas y reiniciará el nodo de forma segura.
 Descripción de la foto
Descripción de la foto Repita este proceso para cada nodo de Galera en el clúster, hasta que todos los nodos indiquen que son maestros.
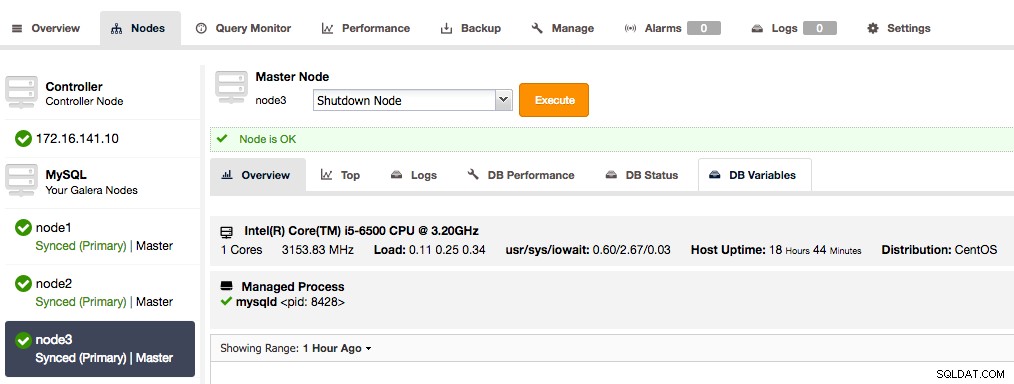 Todos los nodos de Galera Cluster ahora son maestros
Todos los nodos de Galera Cluster ahora son maestros 2. Agregue el esclavo de replicación asincrónica al clúster
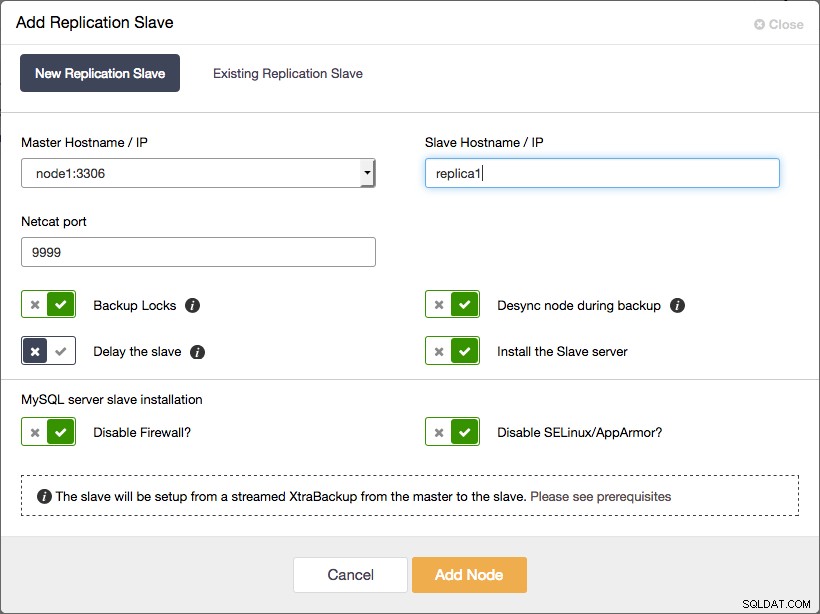 Agregar un esclavo de replicación asincrónica a Galera Cluster usando ClusterControl
Agregar un esclavo de replicación asincrónica a Galera Cluster usando ClusterControl Y esto es todo lo que tienes que hacer. Todo el proceso descrito en el párrafo anterior ha sido automatizado por ClusterControl.
Cambio de maestro
Si el maestro designado falla, el esclavo intentará volver a conectarse nuevamente en el valor de tiempo de espera de red_esclavo (nuestra configuración es de 60 segundos; el valor predeterminado es de 1 hora). Debería ver el siguiente error en el estado del esclavo:
Last_IO_Errno: 2003
Last_IO_Error: error reconnecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 1Dado que estamos utilizando Galera con GTID habilitado, la conmutación por error maestra es compatible a través de ClusterControl cuando Recuperación automática de clúster y nodo ha sido habilitado. Ya sea que el maestro falle debido a la conectividad de la red o por cualquier otro motivo, ClusterControl conmutará automáticamente al otro nodo maestro más adecuado en el clúster.
Si desea realizar la conmutación por error manualmente, simplemente cambie el nodo maestro de la siguiente manera:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.202', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;En algunos casos, es posible que encuentre un error de "Entrada duplicada... para la clave" después de cambiar el nodo maestro:
Last_Errno: 1062
Last_Error: Could not execute Write_rows event on table sbtest.sbtest; Duplicate entry '1089775' for key 'PRIMARY', Error_code: 1062; handler error HA_ERR_FOUND_DUPP_KEY; the event's master log mysqld-bin.000009, end_log_pos 85789000En versiones anteriores de MySQL, solo puede usar SET GLOBAL SQL_SLAVE_SKIP_COUNTER =n para saltar declaraciones, pero no funciona con GTID. Miguel de Percona escribió una excelente publicación de blog sobre cómo reparar esto mediante la inyección de transacciones vacías.
Otro enfoque, para bases de datos más pequeñas, también podría ser obtener un volcado nuevo de cualquiera de los nodos de Galera disponibles, restaurarlo y usar la instrucción RESET MASTER:
mysql> STOP SLAVE;
mysql> RESET MASTER;
mysql> DROP SCHEMA sbtest; CREATE SCHEMA sbtest; USE sbtest;
mysql> SOURCE /root/sbtest_from_galera2.sql; -- repeat step #4 above to get this dump
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.202', MASTER_PORT = 3306, MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;También puede usar pt-table-checksum para verificar la integridad de la replicación, más información en esta publicación de blog.
Nota:Dado que en la replicación de MySQL el aplicador esclavo sigue siendo de un solo subproceso de forma predeterminada, no espere que el rendimiento de la replicación asíncrona sea el mismo que el de la replicación en paralelo de Galera. Para MySQL 5.6 y 5.7 hay opciones para hacer que la replicación asíncrona se ejecute en paralelo en los nodos esclavos, pero en principio esta replicación todavía depende del orden correcto de las transacciones dentro del mismo esquema para que suceda. Si la carga de replicación es intensiva y continua, el retraso del esclavo seguirá creciendo. Hemos visto casos en los que el esclavo nunca pudo alcanzar al maestro.