
T-SQL Tuesday #78 está siendo presentado por Wendy Pastrick, y el desafío de este mes es simplemente "aprender algo nuevo y bloguear al respecto". Su propaganda se inclina hacia las nuevas funciones de SQL Server 2016, pero dado que escribí en un blog y presenté muchas de ellas, pensé en explorar otra cosa de primera mano por la que siempre he tenido mucha curiosidad.
He visto a varias personas afirmar que un montón puede ser mejor que un índice agrupado para ciertos escenarios. No puedo estar en desacuerdo con eso. Sin embargo, una de las razones interesantes que he visto es que una búsqueda RID es más rápida que una búsqueda clave. Soy un gran admirador de los índices agrupados y no un gran admirador de los montones, por lo que sentí que esto necesitaba algunas pruebas.
Entonces, ¡vamos a probarlo!
Pensé que sería bueno crear una base de datos con dos tablas, idénticas excepto que una tenía una clave principal agrupada y la otra tenía una clave principal no agrupada. Me gustaría cargar algunas filas en la tabla, actualizar un montón de filas en un bucle y seleccionar desde un índice (forzando una búsqueda de clave o RID).
Especificaciones del sistema
Esta pregunta surge a menudo, así que para aclarar los detalles importantes sobre este sistema, estoy en una máquina virtual de 8 núcleos con 32 GB de RAM, respaldada por almacenamiento PCIe. La versión de SQL Server es 2014 SP1 CU6, sin cambios de configuración especiales ni indicadores de seguimiento en ejecución:
Microsoft SQL Server 2014 (SP1-CU6) (KB3144524) – 12.0.4449.0 (X64)13 de abril de 2016 12:41:07
Copyright (c) Microsoft Corporation
Developer Edition (64- bit) en Windows NT 6.3
La base de datos
Creé una base de datos con mucho espacio libre tanto en los datos como en el archivo de registro para evitar que los eventos de crecimiento automático interfirieran con las pruebas. También configuré la base de datos en recuperación simple para minimizar el impacto en el registro de transacciones.
CREATE DATABASE HeapVsCIX ON ( name = N'HeapVsCIX_data', filename = N'C:\...\HeapCIX.mdf', size = 100MB, filegrowth = 10MB ) LOG ON ( name = N'HeapVsCIX_log', filename = 'C:\...\HeapCIX.ldf', size = 100MB, filegrowth = 10MB ); GO ALTER DATABASE HeapVsCIX SET RECOVERY SIMPLE;
Las Mesas
Como dije, dos tablas, con la única diferencia de si la clave principal está agrupada.
CREATE TABLE dbo.ObjectHeap ( ObjectID int PRIMARY KEY NONCLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oh_name ON dbo.ObjectHeap(Name) INCLUDE(SchemaID); CREATE TABLE dbo.ObjectCIX ( ObjectID INT PRIMARY KEY CLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
Una tabla para capturar el tiempo de ejecución
Podría monitorear la CPU y todo eso, pero en realidad la curiosidad casi siempre está relacionada con el tiempo de ejecución. Así que creé una tabla de registro para capturar el tiempo de ejecución de cada prueba:
CREATE TABLE dbo.Timings ( Test varchar(32) NOT NULL, StartTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME(), EndTime datetime2 );
La prueba de inserción
Entonces, ¿cuánto se tarda en insertar 2000 filas, 100 veces? Estoy obteniendo algunos datos bastante básicos de sys.all_objects y extrayendo la definición para cualquier procedimiento, función, etc.:
INSERT dbo.Timings(Test) VALUES('Inserting Heap');
GO
TRUNCATE TABLE dbo.ObjectHeap;
INSERT dbo.ObjectHeap(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
-- CIX:
INSERT dbo.Timings(Test) VALUES('Inserting CIX');
GO
TRUNCATE TABLE dbo.ObjectCIX;
INSERT dbo.ObjectCIX(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; La prueba de actualización
Para la prueba de actualización, solo quería probar la velocidad de escritura en un índice agrupado frente a un montón de una manera muy fila por fila. Así que volqué 200 filas aleatorias en una tabla #temp, luego construí un cursor alrededor (la tabla #temp simplemente garantiza que las mismas 200 filas se actualicen en ambas versiones de la tabla, lo que probablemente sea excesivo).
CREATE TABLE #IdsToUpdate(ObjectID int PRIMARY KEY CLUSTERED);
INSERT #IdsToUpdate(ObjectID)
SELECT TOP (200) ObjectID
FROM dbo.ObjectCIX ORDER BY NEWID();
GO
INSERT dbo.Timings(Test) VALUES('Updating Heap');
GO
-- update speed - update 200 rows 1,000 times
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectHeap SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Updating CIX');
GO
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectCIX SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; La Prueba Selecta
Entonces, arriba viste que creé un índice con Name como columna clave en cada tabla; para evaluar el costo de realizar búsquedas para una cantidad significativa de filas, escribí una consulta que asigna la salida a una variable (eliminando la E/S de la red y el tiempo de representación del cliente), pero fuerza el uso del índice:
INSERT dbo.Timings(Test) VALUES('Forcing RID Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectHeap WITH (INDEX(oh_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Forcing Key Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectCIX WITH (INDEX(oc_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Para este, quería mostrar algunos aspectos interesantes de los planes antes de cotejar los resultados de las pruebas. Ejecutarlos individualmente frente a frente proporciona estas métricas comparativas:

La duración es intrascendente para una sola declaración, pero mire esas lecturas. Si tiene un almacenamiento lento, esa es una gran diferencia que no verá en una escala más pequeña o en su SSD de desarrollo local.
Y luego los planes que muestran las dos búsquedas diferentes, utilizando SQL Sentry Plan Explorer:

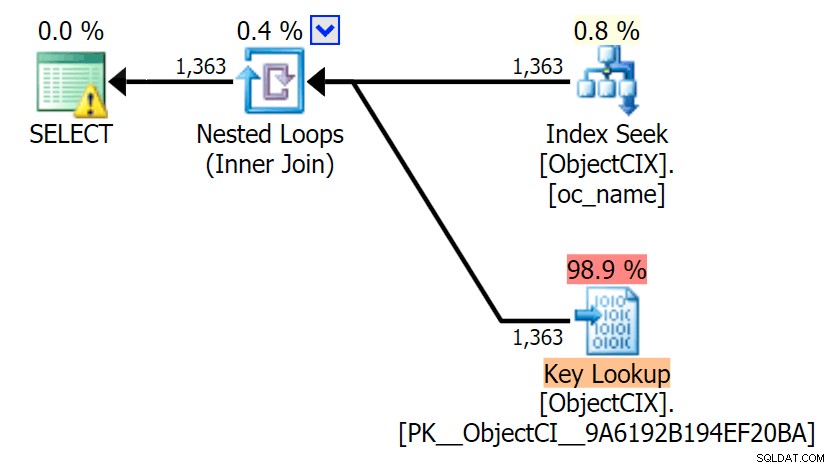
Los planes parecen casi idénticos y es posible que no note la diferencia en las lecturas en SSMS a menos que esté capturando la E/S de estadísticas. Incluso los costos de E/S estimados para las dos búsquedas fueron similares:1,69 para la búsqueda de claves y 1,59 para la búsqueda de RID. (El ícono de advertencia en ambos planes es para un índice de cobertura faltante).
Es interesante notar que si no forzamos una búsqueda y permitimos que SQL Server decida qué hacer, elige un escaneo estándar en ambos casos, sin advertencia de índice faltante, y mira qué tan cerca están las lecturas:

El optimizador sabe que un escaneo será mucho más económico que buscar + búsquedas en este caso. Elegí una columna LOB para la asignación de variables simplemente por efecto, pero los resultados fueron similares usando una columna que no es LOB también.
Los resultados de la prueba
Con la tabla de Tiempos en su lugar, pude ejecutar fácilmente las pruebas varias veces (realicé una docena de pruebas) y luego obtuve los promedios de las pruebas con la siguiente consulta:
SELECT Test, Avg_Duration = AVG(1.0*DATEDIFF(MILLISECOND, StartTime, EndTime)) FROM dbo.Timings GROUP BY Test;
Un gráfico de barras simple muestra cómo se comparan:
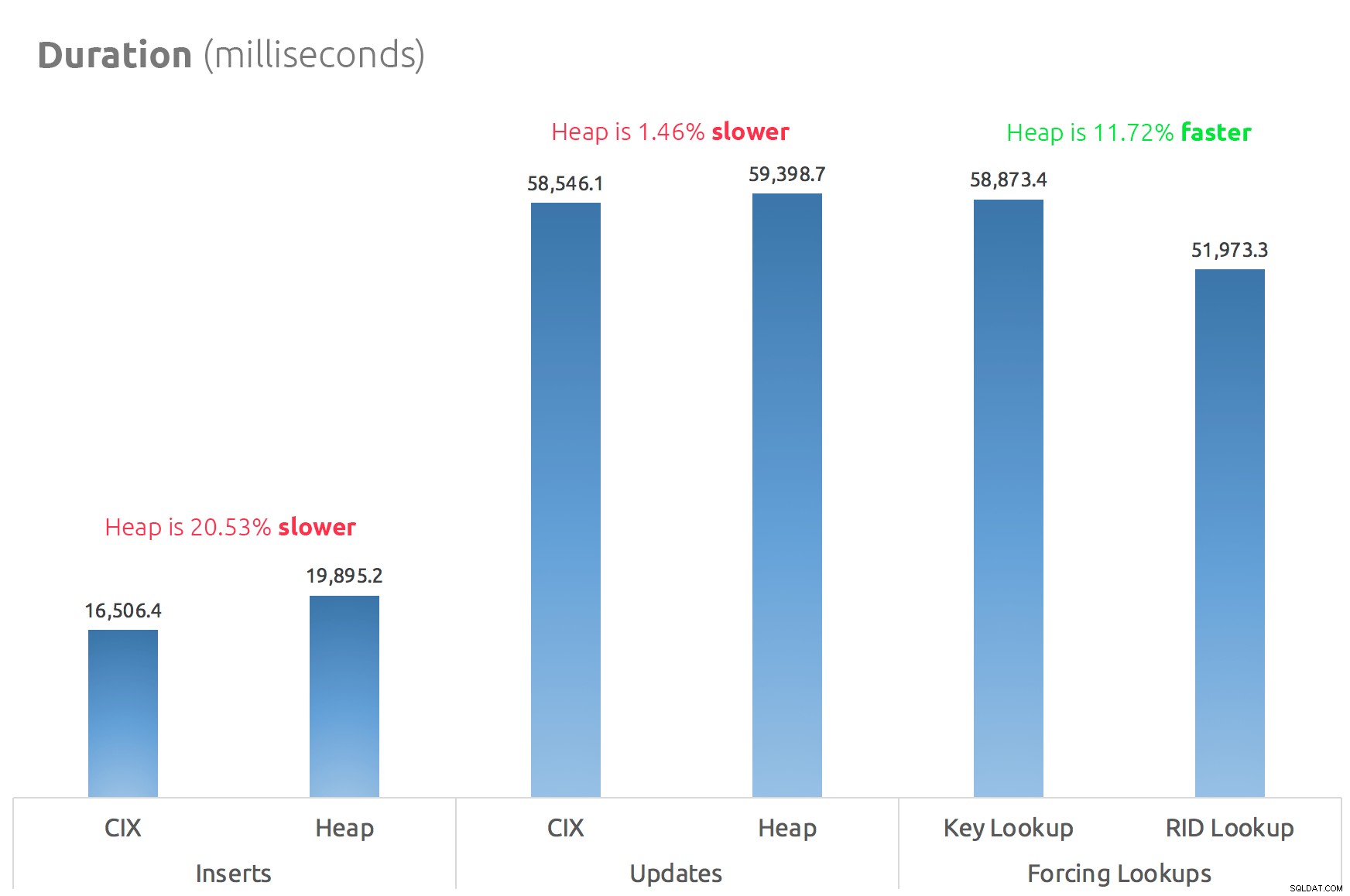
Conclusión
Entonces, los rumores son ciertos:al menos en este caso, una búsqueda RID es significativamente más rápida que una búsqueda clave. Ir directamente a archivo:página:ranura es obviamente más eficiente en términos de E/S que seguir el árbol b (y si no está en un almacenamiento moderno, el delta podría ser mucho más notable).
Si desea aprovechar eso y traer todos los demás aspectos del montón, dependerá de su carga de trabajo:el montón es un poco más costoso para las operaciones de escritura. Pero esto no definitivo:esto podría variar mucho según la estructura de la tabla, los índices y los patrones de acceso.
Probé cosas muy simples aquí, y si está indeciso sobre esto, le recomiendo probar su carga de trabajo real en su propio hardware y compararlo usted mismo (y no olvide probar la misma carga de trabajo donde están presentes los índices de cobertura; probablemente obtendrá un rendimiento general mucho mejor si simplemente puede eliminar las búsquedas por completo). Asegúrese de medir todas las métricas que son importantes para usted; el hecho de que me concentre en la duración no significa que sea lo que más debas preocuparte. :-)



