¿Tiene dificultades con SQL UNION? Sucede si los resultados que combinó paralizan su SQL Server. O un informe que ha estado funcionando antes aparece un cuadro con un icono de X rojo. Se produce un error de "Choque de tipo de operando" que apunta a una línea con UNION. Comienza el “fuego”. ¿Te suena familiar?
Ya sea que haya estado usando SQL UNION por un tiempo o recién esté comenzando, una hoja de trucos o un conjunto conciso de notas no le hará daño. Esto es lo que vas a encontrar hoy en este post. Esta lista ofrece 10 consejos útiles tanto para principiantes como para veteranos. Además, habrá ejemplos y algunas discusiones avanzadas.

[ID de formulario de envío de pulso =”11900″]
Pero antes de entrar en el primer punto, aclaremos los términos.
UNION es uno de los operadores de conjuntos en SQL que combina 2 o más conjuntos de resultados. Puede ser útil cuando necesite combinar nombres, estadísticas mensuales y más de diferentes fuentes. Y ya sea que use SQL Server, MySQL u Oracle, el propósito, el comportamiento y la sintaxis serán muy similares. Pero, ¿cómo funciona?
1. Use SQL UNION para combinar Unique Registros
El uso de UNION para combinar conjuntos de resultados elimina los duplicados.
¿Por qué es esto importante?
La mayoría de las veces, no desea resultados con duplicados. Un informe con líneas duplicadas desperdicia tinta y papel en copias impresas. Y esto enfadará a tus usuarios.
Cómo usarlo
Combina los resultados de las declaraciones SELECT con UNION en el medio.
Antes de comenzar con el ejemplo, preparemos nuestros datos de muestra.
USE AdventureWorks
GO
IF OBJECT_ID ('dbo.Customer1', 'U') IS NOT NULL
DROP TABLE dbo.Customer1;
GO
IF OBJECT_ID ('dbo.Customer2', 'U') IS NOT NULL
DROP TABLE dbo.Customer2;
GO
IF OBJECT_ID ('dbo.Customer3', 'U') IS NOT NULL
DROP TABLE dbo.Customer3;
GO
-- Get 3 customer names with Andersen lastname
SELECT TOP 3
p.LastName
, p.FirstName
, c.AccountNumber
INTO dbo.Customer1
FROM Person.Person AS p
INNER JOIN Sales.Customer c
ON c.PersonID = p.BusinessEntityID
WHERE p.LastName = 'Andersen';
-- Make sure we have a duplicate in another table
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer2
FROM Customer1 c
-- Seems it's not enough. Let's have a 3rd copy
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer3
FROM Customer1 c
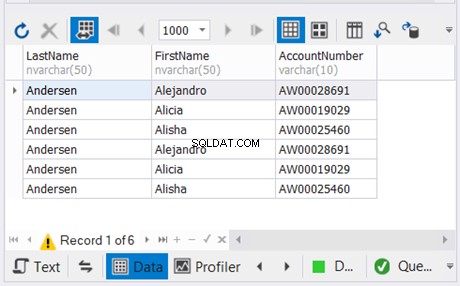
Usaremos los datos generados por el código anterior hasta el tercer consejo. Ahora que estamos listos, a continuación se muestra el ejemplo:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
Tenemos 3 copias de los mismos nombres de clientes y esperamos que desaparezcan los registros únicos. Ver los resultados:
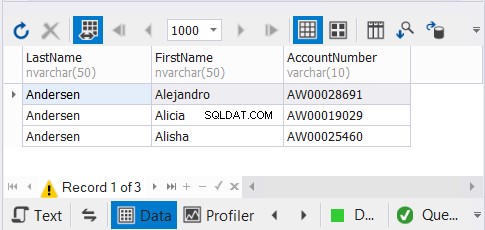
La solución dbForge Studio para SQL Server que usamos para nuestros ejemplos muestra solo 3 registros. Podrían haber sido 9. Al aplicar UNION, eliminamos los duplicados.
¿Cómo funciona?
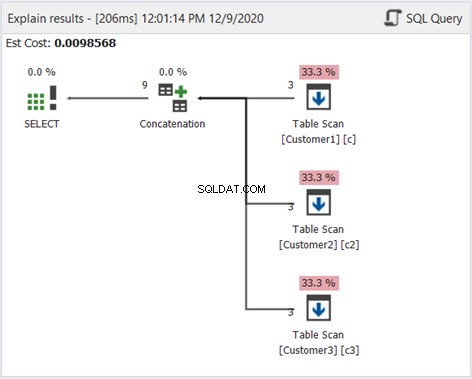
El diagrama del plan en dbForge Studio revela cómo SQL Server produce el resultado que se muestra en la Figura 1. Eche un vistazo:
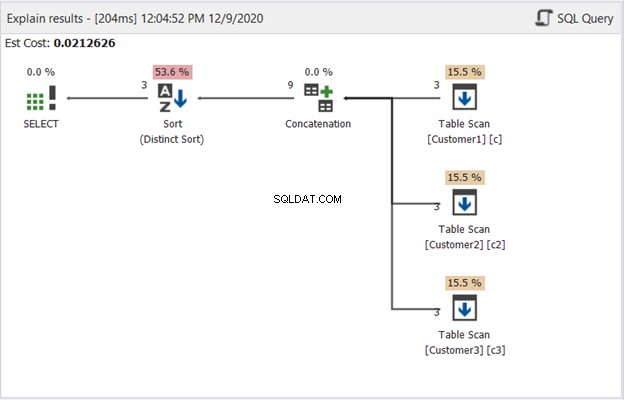
Para interpretar la Figura 2, comience de derecha a izquierda:
- Recuperamos 3 registros de cada operador de Table Scan. Esas son las 3 declaraciones SELECT del ejemplo anterior. Cada línea que sale muestra '3', lo que significa 3 registros cada uno.
- El operador Concatenación combina los resultados. La línea que sale muestra '9':una salida de 9 registros de la combinación de resultados.
- El operador Distinct Sort garantiza que los registros únicos sean el resultado final. La línea que sale muestra '3', que es consistente con la cantidad de registros en la Figura 1.
El diagrama anterior muestra cómo SQL Server procesa UNION. La cantidad y el tipo de operadores utilizados pueden ser diferentes según la consulta y la fuente de datos subyacente. Pero en resumen, una UNIÓN funciona de la siguiente manera:
- Recupere los resultados de cada instrucción SELECT.
- Combina los resultados con un operador de concatenación.
- Si los resultados combinados no son únicos, SQL Server filtrará los duplicados.
Todos los ejemplos exitosos con UNION siguen estos pasos básicos.
2. Use SQL UNION ALL para combinar registros con duplicados
El uso de UNION ALL combina conjuntos de resultados con duplicados incluidos.
¿Por qué es esto importante?
Es posible que desee combinar conjuntos de resultados y luego obtener los registros con duplicados para procesarlos más adelante. Esta tarea es útil para limpiar sus datos.
Cómo usarlo
Combina los resultados de las declaraciones SELECT con UNION ALL en el medio. Echa un vistazo al ejemplo:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION ALL
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
El código anterior genera 9 registros como se muestra en la Figura 3:
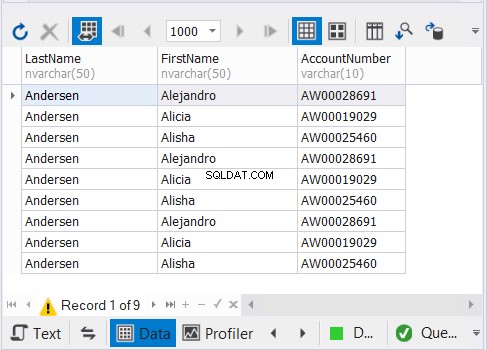
¿Cómo funciona?
Como antes, usamos el diagrama del Plan para saber cómo funciona esto:
Excepto por Sort Distinct en la Figura 2, el diagrama anterior es el mismo. Eso es apropiado porque no queremos filtrar los duplicados.
El diagrama anterior muestra cómo funciona UNION ALL. En resumen, estos son los pasos que seguirá SQL Server:
- Recupere los resultados de cada instrucción SELECT.
- Luego, combine los resultados con un operador de concatenación.
Los ejemplos exitosos con UNION ALL siguen este patrón.
3. Puede mezclar SQL UNION y UNION ALL pero agruparlos con paréntesis
Puede combinar el uso de UNION y UNION ALL en al menos tres sentencias SELECT.
¿Cómo usarlo?
Combina los resultados de las declaraciones SELECT con UNION o UNION ALL en el medio. Los paréntesis agrupan los resultados que se juntan. Usemos los mismos datos para el siguiente ejemplo:
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
(
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
)
El ejemplo anterior combina los resultados de las dos últimas declaraciones SELECT sin duplicados. Luego, combina eso con el resultado de la primera instrucción SELECT. El resultado se muestra en la Figura 5 a continuación:
4. Las columnas de cada instrucción SELECT deben tener tipos de datos compatibles
Las columnas en cada declaración SELECT que usa UNION pueden tener diferentes tipos de datos. Es aceptable siempre que sean compatibles y permitan la conversión implícita sobre ellos. El tipo de datos final de los resultados combinados utilizará el tipo de datos con la prioridad más alta. Además, la base del tamaño final de los datos son los datos de mayor tamaño. En el caso de cadenas, utilizará los datos con mayor número de caracteres.
¿Por qué es esto importante?
Si necesita insertar el resultado de UNIONs en una tabla, el tipo y el tamaño de los datos finales determinarán si cabe en la columna de la tabla de destino o no. Si no, se producirá un error. Por ejemplo, una de las columnas de UNION tiene un tipo final de NVARCHAR(50). Si la columna de la tabla de destino es VARCHAR(50), entonces no puede insertarla en la tabla.
¿Cómo funciona?
No hay mejor forma de explicarlo que con un ejemplo:
SELECT N'김지수' AS FullName
UNION
SELECT N'김제니' AS KoreanName
UNION
SELECT N'박채영' AS KoreanName
UNION
SELECT N'ลลิษา มโนบาล' AS ThaiName
UNION
SELECT 'Kim Ji-soo' AS EnglishName
UNION
SELECT 'Jennie Kim' AS EnglishName
UNION
SELECT 'Roseanne Park' AS EnglishName
UNION
SELECT 'Lalisa Manoban' AS EnglishName
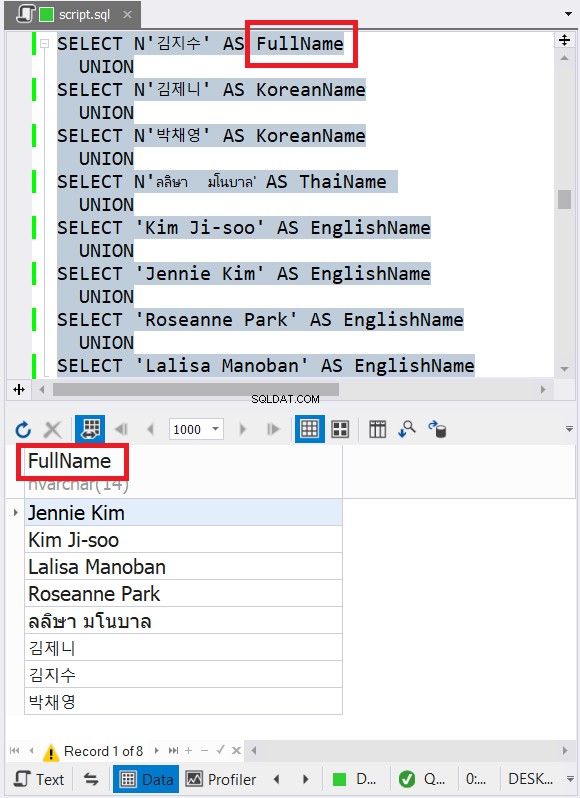
El ejemplo anterior contiene datos con nombres de caracteres en inglés, coreano y tailandés. El tailandés y el coreano son caracteres Unicode. Los caracteres ingleses no lo son. Entonces, ¿cuál cree que será el tipo y tamaño de datos final? dbForge Studio lo muestra en el conjunto de resultados:
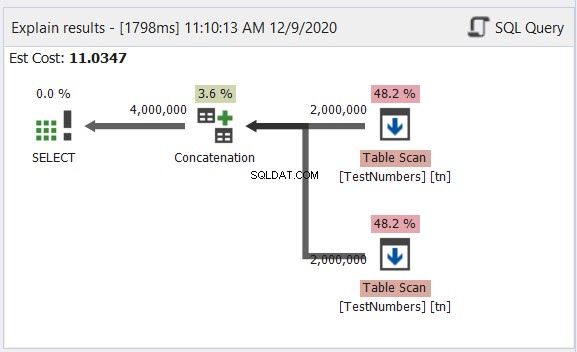
¿Notó el tipo de datos final en la Figura 6? No puede ser VARCHAR debido a los caracteres Unicode. Entonces, tiene que ser NVARCHAR. Mientras tanto, el tamaño no puede ser menor a 14 porque el dato con mayor número de caracteres tiene 14 caracteres. Vea los títulos en rojo en la Figura 6. Es bueno incluir el tipo de datos y el tamaño en el encabezado de la columna en dbForge Studio.
Es el caso no solo para los tipos de datos de cadena. También se aplica a números y fechas. Mientras tanto, si intenta combinar datos con tipos de datos incompatibles, se producirá un error. Vea el siguiente ejemplo:
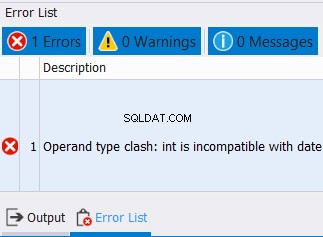
SELECT CAST('12/25/2020' AS DATE) AS col1
UNION
SELECT CAST('10' AS INT) AS col1
No podemos combinar fechas y números enteros en una columna. Entonces, espere un error como el siguiente:
5. Los nombres de columna de los resultados combinados utilizarán los nombres de columna de la primera instrucción SELECT
Este problema se relaciona con el consejo anterior. Observe los nombres de las columnas en el código del consejo n.° 4. Hay diferentes nombres de columna en cada instrucción SELECT. Sin embargo, vimos el nombre de la columna final en el resultado combinado de la Figura 6 anterior. Por lo tanto, la base es el nombre de la columna de la primera sentencia SELECT.
¿Por qué es esto importante?
Esto puede ser útil cuando necesita volcar el resultado de UNION en una tabla temporal. Si necesita hacer referencia a los nombres de sus columnas en las declaraciones siguientes, debe estar seguro de los nombres. A menos que esté utilizando un editor de código avanzado con IntelliSense, se encontrará con otro error en su código T-SQL.
¿Cómo funciona?
Consulte la Figura 8 para obtener resultados más claros del uso de dbForge Studio:
6. Agregue ORDER BY en la última instrucción SELECT con SQL UNION para ordenar los resultados
Necesita ordenar los resultados combinados. En una serie de sentencias SELECT con UNION en el medio, puede hacerlo con la cláusula ORDER BY en la última sentencia SELECT.
¿Por qué es esto importante?
Los usuarios quieren ordenar los datos de la forma que prefieran en aplicaciones, páginas web, informes, hojas de cálculo y más.
Cómo usarlo
Utilice ORDER BY en la última instrucción SELECT. He aquí un ejemplo:
SELECT
e.BusinessEntityID
,p.FirstName
,p.MiddleName
,p.LastName
,'Employee' AS PersonType
FROM HumanResources.Employee e
INNER JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID
UNION
SELECT
c.PersonID
,p.FirstName
,p.MiddleName
,p.LastName
,'Customer' AS PersonType
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
ORDER BY p.LastName, p.FirstName
El ejemplo anterior hace que parezca que la clasificación solo ocurre en la última instrucción SELECT. Pero no lo es. Funcionará para el resultado combinado. Tendrá problemas si lo coloca en cada instrucción SELECT. Ver el resultado:
Sin ORDER BY, el conjunto de resultados tendrá todos los empleados PersonType primero seguido de todos los Clientes PersonType . Sin embargo, la Figura 9 demuestra que los nombres se convierten en el orden de clasificación del resultado combinado.
Si intenta colocar ORDER BY en cada declaración SELECT para ordenar, esto es lo que sucederá:
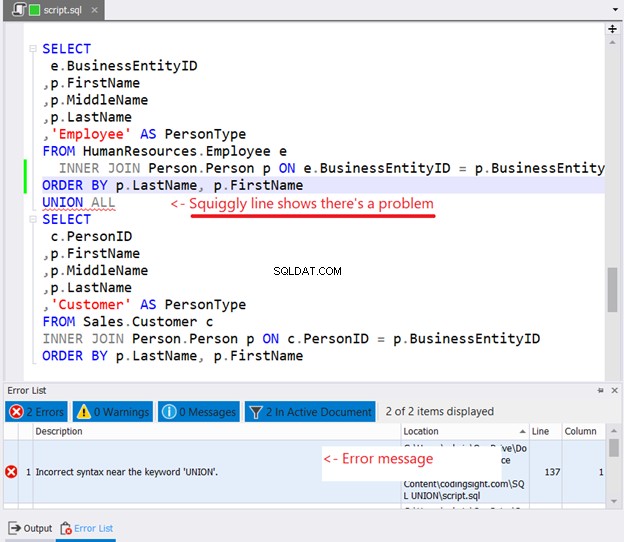
¿Viste la línea ondulada en la Figura 10? Es una advertencia. Si no lo notó y continuó, aparecerá un error en la ventana de la lista de errores de dbForge Studio.
7. Las cláusulas WHERE y GROUP BY se pueden usar en cada instrucción SELECT con SQL UNION
La cláusula ORDER BY no funciona en cada declaración SELECT con UNION en el medio. Sin embargo, las cláusulas WHERE y GROUP BY funcionan.
¿Por qué es esto importante?
Es posible que desee combinar los resultados de diferentes consultas que filtran, cuentan o resumen datos. Por ejemplo, puede hacer esto para obtener el total de pedidos de venta de enero de 2012 y compararlo con enero de 2013, enero de 2014, etc.
Cómo usarlo
Coloque las cláusulas WHERE y/o GROUP BY en cada instrucción SELECT. Mira el siguiente ejemplo:
USE AdventureWorks
GO
-- Get the number of orders for January 2012, 2013, 2014 for comparison
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
El código anterior combina el número de pedidos de enero durante tres años consecutivos. Ahora, verifique la salida:
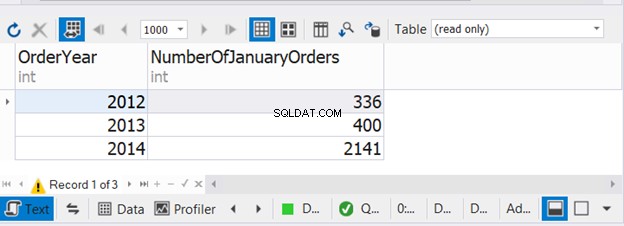
Este ejemplo muestra que es posible usar WHERE y GROUP BY en cada una de las tres instrucciones SELECT con UNION.
8. SELECCIONAR EN Funciona con SQL UNION
Cuando necesite insertar los resultados de una consulta con SQL UNION en una tabla, puede hacerlo usando SELECT INTO.
¿Por qué es esto importante?
Habrá ocasiones en las que necesite colocar los resultados de una consulta con UNION en una tabla para su posterior procesamiento.
Cómo usarlo
Coloque la cláusula INTO en la primera instrucción SELECT. He aquí un ejemplo:
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
INTO JanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
Recuerde colocar solo una cláusula INTO en la primera instrucción SELECT.
Cómo funciona
SQL Server sigue el patrón de procesamiento UNION. Luego, inserta el resultado en la tabla especificada en la cláusula INTO.
9. Diferenciar SQL UNION de SQL JOIN
Tanto SQL UNION como SQL JOIN combinan los datos de la tabla, pero la diferencia en la sintaxis y los resultados es como la noche y el día.
¿Por qué es esto importante?
Si su informe o algún requisito necesita un JOIN pero hizo un UNION, el resultado será incorrecto.
Cómo se utilizan SQL UNION y SQL JOIN
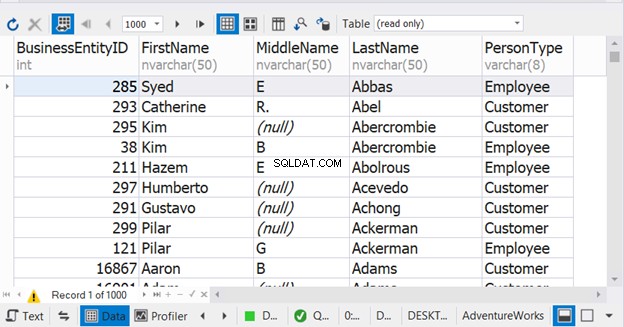
Es SQL UNION vs. JOIN. Esta es una de las consultas y preguntas de búsqueda relacionadas que hace un novato en Google cuando aprende sobre SQL UNION. Aquí está la tabla de diferencias:
| UNIÓN SQL | UNIR SQL | |
| Qué se combina | Filas | Columnas (usando una clave) |
| Número de columnas por tabla | Lo mismo para todas las tablas | Variable (Cero a todas las columnas/tabla) |
En todos los proyectos en los que he estado, SQL JOIN se aplica la mayor parte del tiempo. Solo tuve algunos casos que usaron SQL UNION. Pero como has visto hasta ahora, SQL UNION está lejos de ser inútil.
10. SQL UNION ALL es más rápido que UNION
Los Diagramas de planes de la Figura 2 y la Figura 4 anteriores sugieren que UNION requiere un operador adicional para garantizar resultados únicos. Por eso UNION ALL es más rápido.
¿Por qué es esto importante?
Usted, sus usuarios, sus clientes, su jefe, todos quieren resultados rápidos. Saber que UNION ALL es más rápido que UNION le hace preguntarse qué hacer si necesita resultados combinados únicos. Hay una solución, como verá más adelante.
SQL UNION ALL frente a rendimiento de UNION
La figura 2 y la figura 4 ya te dieron una idea de cuál es más rápido. Pero los ejemplos de código utilizados son simples con un pequeño conjunto de resultados. Agreguemos algunas comparaciones más usando millones de registros para que sea convincente.
Para empezar, preparemos los datos:
SELECT TOP (2000000)
val = ROW_NUMBER() OVER (ORDER BY sod.SalesOrderDetailID)
INTO dbo.TestNumbers
FROM AdventureWorks.Sales.SalesOrderDetail sod
CROSS JOIN AdventureWorks.Sales.SalesOrderDetail sod2
Son 2 millones de registros. Espero que sea lo suficientemente convincente. Ahora, veamos los siguientes dos ejemplos de consulta a continuación.
-- Using UNION ALL
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
-- Using UNION
SELECT
val
FROM TestNumbers tn
UNION
SELECT
val
FROM TestNumbers tn
Examinemos los procesos involucrados en estas consultas comenzando con el más rápido.
Análisis de diagrama de planta
El diagrama de la Figura 12 parece típico de un proceso UNION ALL. Sin embargo, el resultado es de 4 millones de resultados combinados. Vea la flecha que sale del operador Concatenación. Aún así, normalmente se debe a que no se ocupa de los duplicados.
Ahora, tengamos el diagrama de la consulta UNION en la Figura 13:
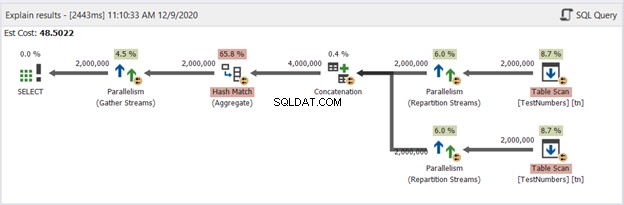
Este ya no es típico. El plan se convierte en un plan de consulta paralelo para gestionar la eliminación de duplicados en cuatro millones de filas. El plan de consultas paralelas significa que SQL Server necesita dividir el proceso por la cantidad de núcleos de procesador disponibles.
Interpretémoslo, empezando por los operadores de la derecha hacia la izquierda:
- Dado que estamos combinando una tabla consigo misma, SQL Server necesita recuperarla dos veces. Vea los dos Table Scans con dos millones de registros cada uno.
- Los operadores de Repartition Stream controlarán la distribución de cada fila al siguiente subproceso disponible.
- La concatenación duplica el resultado a cuatro millones. Esto todavía está considerando la cantidad de núcleos de procesador.
- Se aplica una coincidencia hash para eliminar los duplicados. Este es un proceso costoso con un costo del operador del 65,8%. Como resultado, se descartaron dos millones de registros.
- Gather Streams recombina los resultados realizados en cada núcleo de procesador o subproceso en uno.
Eso es demasiado trabajo a pesar de que el proceso se divide en varios subprocesos. Por lo tanto, concluirá que funcionará más lento. Pero, ¿y si existe una solución para obtener registros únicos con UNION ALL pero más rápido que esto?
Resultados únicos pero soluciones más rápidas con UNION ALL:¿cómo?
No te haré esperar. Aquí está el código:
SELECT DISTINCT
val
FROM
(
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
) AS uniqtn
Esta puede ser una solución poco convincente. Pero echa un vistazo a su Diagrama de planta en la Figura 14:
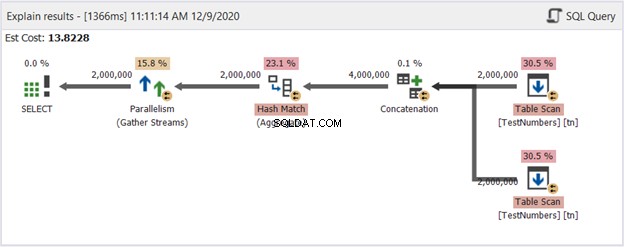
Entonces, ¿qué lo hizo mejor? Si lo compara con la Figura 13, verá que los operadores de Repartition Stream han desaparecido. Sin embargo, todavía utiliza múltiples subprocesos para hacer el trabajo. Por otro lado, implica que el optimizador de consultas considera que este proceso es más sencillo de realizar que la consulta mediante UNION.
¿Podemos concluir con seguridad que debemos evitar el uso de UNION y usar este enfoque en su lugar? ¡De nada! ¡Revise siempre el diagrama del plan de ejecución! Siempre depende de lo que quieras que te proporcione SQL Server. Este solo muestra que si se topa con un muro de rendimiento, debe cambiar su enfoque de consulta.
¿Qué hay de las estadísticas de E/S?
No podemos descartar la cantidad de recursos que SQL Server necesita para procesar nuestros ejemplos de consulta. Es por eso que también necesitamos examinar sus ESTADÍSTICAS IO. Comparando las tres consultas anteriores, obtenemos las siguientes lecturas lógicas:
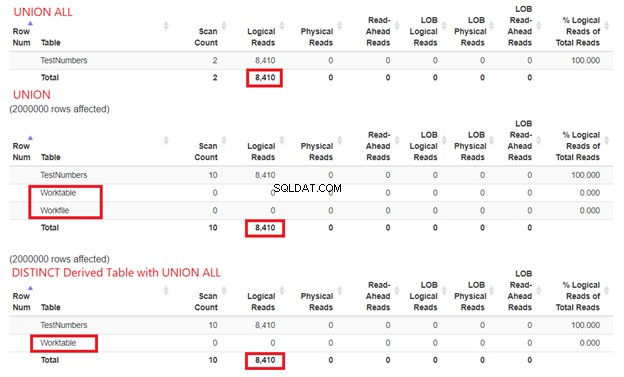
De la Figura 15, todavía podemos concluir que UNION ALL es más rápido que UNION aunque las lecturas lógicas son las mismas. La presencia de Worktable y archivo de trabajo programas usando tempdb para hacer el trabajo. Mientras tanto, cuando usamos SELECT DISTINCT de una tabla derivada con UNION ALL, tempdb el uso es menor en comparación con UNION. Esto reconfirma aún más que nuestro análisis de los diagramas del plan anterior es correcto.
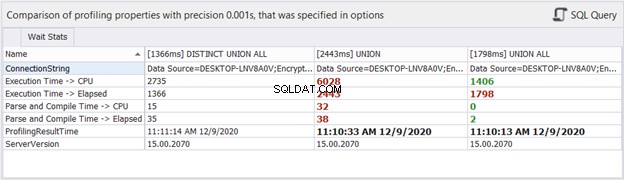
¿Qué hay de las estadísticas de tiempo?
Aunque el tiempo transcurrido puede cambiar en cada ejecución que hacemos a las mismas consultas, puede darnos una idea y agregar más evidencia a nuestro análisis. dbForge Studio muestra las diferencias de tiempo de las tres consultas anteriores. Esta comparación es consistente con el análisis anterior que hicimos.
Conclusión
Cubrimos muchos antecedentes para brindarle lo que necesita para usar SQL UNION y UNION ALL. Es posible que no recuerdes todo después de leer esta publicación, así que asegúrate de marcar esta página como favorita.
Si te gusta la publicación, no dudes en compartirla en las redes sociales.