Para algunas personas, es la pregunta equivocada. CURSOR SQL ES el error. ¡El diablo está en los detalles! Puede leer todo tipo de blasfemias en toda la blogósfera de SQL en nombre de SQL CURSOR.
Si sientes lo mismo, ¿qué te hizo llegar a esta conclusión?
Si es de un amigo y colega de confianza, no puedo culparte. Sucede. A veces mucho. Pero si alguien te convenció con pruebas, esa es una historia diferente.
No nos hemos conocido antes. No me conoces como amigo. Pero espero poder explicarlo con ejemplos y convencerte de que SQL CURSOR tiene su lugar. No es mucho, pero ese pequeño lugar en nuestro código tiene reglas.
Pero primero, déjame contarte mi historia.
Empecé a programar con bases de datos usando xBase. Eso fue en la universidad hasta mis primeros dos años de programación profesional. Te digo esto porque en el pasado, solíamos procesar los datos secuencialmente, no en lotes establecidos como SQL. Cuando aprendí SQL, fue como un cambio de paradigma. El motor de la base de datos decide por mí con sus comandos basados en conjuntos que emití. Cuando me enteré de SQL CURSOR, sentí que había vuelto a las formas antiguas pero cómodas.
Pero algunos colegas senior me advirtieron:"¡Evite SQL CURSOR a toda costa!" Recibí algunas explicaciones verbales y eso fue todo.
SQL CURSOR puede ser malo si lo usa para el trabajo incorrecto. Como usar un martillo para cortar madera, es ridículo. Por supuesto, pueden ocurrir errores, y ahí es donde estará nuestro enfoque.

1. Uso del CURSOR de SQL cuando los comandos basados en conjuntos servirán
No puedo enfatizar esto lo suficiente, pero ESTE es el corazón del problema. Cuando supe por primera vez qué era SQL CURSOR, se encendió una bombilla. “¡Bucles! ¡Yo sé eso!" Sin embargo, no hasta que me dio dolores de cabeza y mis mayores me regañaron.
Verá, el enfoque de SQL se basa en conjuntos. Emite un comando INSERT desde los valores de la tabla y hará el trabajo sin bucles en su código. Como dije antes, es trabajo del motor de la base de datos. Entonces, si fuerza un ciclo para agregar registros a una tabla, está eludiendo esa autoridad. Se va a poner feo.
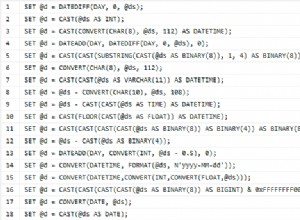
Antes de probar un ejemplo ridículo, preparemos los datos:
SELECT TOP (500)
val = ROW_NUMBER() OVER (ORDER BY sod.SalesOrderDetailID)
, modified = GETDATE()
, status = 'inserted'
INTO dbo.TestTable
FROM AdventureWorks.Sales.SalesOrderDetail sod
CROSS JOIN AdventureWorks.Sales.SalesOrderDetail sod2
SELECT
tt.val
,GETDATE() AS modified
,'inserted' AS status
INTO dbo.TestTable2
FROM dbo.TestTable tt
WHERE CAST(val AS VARCHAR) LIKE '%2%'
La primera declaración generará 500 registros de datos. El segundo obtendrá un subconjunto de él. Entonces, estamos listos. Vamos a insertar los datos faltantes de TestTable en TestTable2 utilizando SQL CURSOR. Ver a continuación:
DECLARE @val INT
DECLARE test_inserts CURSOR FOR
SELECT val FROM TestTable tt
WHERE NOT EXISTS(SELECT val FROM TestTable2 tt1
WHERE tt1.val = tt.val)
OPEN test_inserts
FETCH NEXT FROM test_inserts INTO @val
WHILE @@fetch_status = 0
BEGIN
INSERT INTO TestTable2
(val, modified, status)
VALUES
(@val, GETDATE(),'inserted')
FETCH NEXT FROM test_inserts INTO @val
END
CLOSE test_inserts
DEALLOCATE test_inserts
Así es como hacer un bucle usando SQL CURSOR para insertar un registro faltante uno por uno. Bastante largo, ¿no?
Ahora, probemos una mejor manera:la alternativa basada en conjuntos. Aquí va:
INSERT INTO TestTable2
(val, modified, status)
SELECT val, GETDATE(), status
FROM TestTable tt
WHERE NOT EXISTS(SELECT val FROM TestTable2 tt1
WHERE tt1.val = tt.val)
Eso es corto, ordenado y rápido. ¿Qué rápido? Consulte la Figura 1 a continuación:

Usando xEvent Profiler en SQL Server Management Studio, comparé las cifras de tiempo de CPU, la duración y las lecturas lógicas. Como puede ver en la Figura 1, el uso del comando basado en conjuntos para INSERTAR registros gana la prueba de rendimiento. Los números hablan por si mismos. El uso de SQL CURSOR consume más recursos y tiempo de procesamiento.
Por lo tanto, antes de usar SQL CURSOR, primero intente escribir un comando basado en conjuntos. Dará mejores resultados a largo plazo.
Pero, ¿qué sucede si necesita SQL CURSOR para realizar el trabajo?
2. No usar las opciones apropiadas del CURSOR de SQL
Otro error que cometí en el pasado fue no usar las opciones apropiadas en DECLARE CURSOR. Hay opciones para el alcance, el modelo, la concurrencia y si se puede desplazar o no. Estos argumentos son opcionales y es fácil ignorarlos. Sin embargo, si SQL CURSOR es la única forma de realizar la tarea, debe ser explícito con su intención.
Entonces, pregúntese:
- Al atravesar el ciclo, ¿navegará las filas solo hacia adelante o se moverá a la primera, última, anterior o siguiente fila? Debe especificar si el CURSOR es de solo avance o desplazable. Eso es DECLARAR
CURSOR FORWARD_ONLY o DECLAREDESPLAZAMIENTO DEL CURSOR . - ¿Va a actualizar las columnas en el CURSOR? Use READ_ONLY si no se puede actualizar.
- ¿Necesita los valores más recientes a medida que recorre el bucle? Use STATIC si los valores no importan si son los últimos o no. Use DINÁMICO si otras transacciones actualizan columnas o eliminan filas que usa en el CURSOR y necesita los valores más recientes. Nota :DYNAMIC será costoso.
- ¿El CURSOR es global para la conexión o local para el lote o un procedimiento almacenado? Especifique si LOCAL o GLOBAL.
Para obtener más información sobre estos argumentos, busque la referencia en Microsoft Docs.
Ejemplo
Probemos un ejemplo comparando tres CURSORES para el tiempo de CPU, las lecturas lógicas y la duración usando xEvents Profiler. El primero no tendrá opciones apropiadas después de DECLARE CURSOR. El segundo es LOCAL STATIC FORWARD_ONLY READ_ONLY. El último es LOtyuiCAL FAST_FORWARD.
Aquí está el primero:
-- NOTE: Don't just COPY and PASTE this code then run in your machine. Read and assess.
-- DECLARE CURSOR with no options
SET NOCOUNT ON
DECLARE @command NVARCHAR(2000) = N'SET NOCOUNT ON;'
CREATE TABLE #commands (
ID INT IDENTITY (1, 1) PRIMARY KEY CLUSTERED
,Command NVARCHAR(2000)
);
INSERT INTO #commands (Command)
VALUES (@command)
INSERT INTO #commands (Command)
SELECT
'SELECT ' + CHAR(39) + a.TABLE_SCHEMA + '.' + a.TABLE_NAME
+ ' - ' + CHAR(39)
+ ' + cast(count(*) as varchar) from '
+ a.TABLE_SCHEMA + '.' + a.TABLE_NAME
FROM INFORMATION_SCHEMA.tables a
WHERE a.TABLE_TYPE = 'BASE TABLE';
DECLARE command_builder CURSOR FOR
SELECT
Command
FROM #commands
OPEN command_builder
FETCH NEXT FROM command_builder INTO @command
WHILE @@fetch_status = 0
BEGIN
PRINT @command
FETCH NEXT FROM command_builder INTO @command
END
CLOSE command_builder
DEALLOCATE command_builder
DROP TABLE #commands
GO
Hay una mejor opción que el código anterior, por supuesto. Si el propósito es solo generar un script a partir de tablas de usuarios existentes, SELECT servirá. Luego, pegue el resultado en otra ventana de consulta.
Pero si necesita generar un script y ejecutarlo de inmediato, esa es una historia diferente. Debe evaluar el script de salida si va a gravar su servidor o no. Ver Error #4 más adelante.
Para mostrarle la comparación de tres CURSORES con diferentes opciones, esto servirá.
Ahora, tengamos un código similar pero con LOCAL STATIC FORWARD_ONLY READ_ONLY.
--- STATIC LOCAL FORWARD_ONLY READ_ONLY
SET NOCOUNT ON
DECLARE @command NVARCHAR(2000) = N'SET NOCOUNT ON;'
CREATE TABLE #commands (
ID INT IDENTITY (1, 1) PRIMARY KEY CLUSTERED
,Command NVARCHAR(2000)
);
INSERT INTO #commands (Command)
VALUES (@command)
INSERT INTO #commands (Command)
SELECT
'SELECT ' + CHAR(39) + a.TABLE_SCHEMA + '.' + a.TABLE_NAME
+ ' - ' + CHAR(39)
+ ' + cast(count(*) as varchar) from '
+ a.TABLE_SCHEMA + '.' + a.TABLE_NAME
FROM INFORMATION_SCHEMA.tables a
WHERE a.TABLE_TYPE = 'BASE TABLE';
DECLARE command_builder CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT
Command
FROM #commands
OPEN command_builder
FETCH NEXT FROM command_builder INTO @command
WHILE @@fetch_status = 0
BEGIN
PRINT @command
FETCH NEXT FROM command_builder INTO @command
END
CLOSE command_builder
DEALLOCATE command_builder
DROP TABLE #commands
GO
Como puede ver arriba, la única diferencia con el código anterior es el LOCAL STATIC FORWARD_ONLY READ_ONLY argumentos.
El tercero tendrá un LOCAL FAST_FORWARD. Ahora, según Microsoft, FAST_FORWARD es un CURSOR FORWARD_ONLY, READ_ONLY con optimizaciones habilitadas. Veremos cómo le irá a esto con los dos primeros.
¿Cómo se comparan? Ver figura 2:

El que requiere menos tiempo de CPU y duración es el CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY. Tenga en cuenta también que SQL Server tiene valores predeterminados si no especifica argumentos como STATIC o READ_ONLY. Eso tiene una consecuencia terrible, como verá en la siguiente sección.
Qué reveló sp_describe_cursor
sp_describe_cursor es un procedimiento almacenado del maestro base de datos que puede utilizar para obtener información del CURSOR abierto. Y esto es lo que reveló del primer lote de consultas sin opciones de CURSOR. Consulte la Figura 3 para ver el resultado de sp_describe_cursor :

¿Demasiado exagerado? tu apuesta El CURSOR del primer lote de consultas es:
- global a la conexión existente.
- dinámico, lo que significa que realiza un seguimiento de los cambios en la tabla #commands para actualizaciones, eliminaciones e inserciones.
- optimista, lo que significa que SQL Server agregó una columna adicional a una tabla temporal llamada CWT. Esta es una columna de suma de verificación para realizar un seguimiento de los cambios en los valores de la tabla #commands.
- desplazable, lo que significa que puede desplazarse a la fila anterior, siguiente, superior o inferior del cursor.
¿Absurdo? Estoy totalmente de acuerdo. ¿Por qué necesita una conexión global? ¿Por qué necesita realizar un seguimiento de los cambios en la tabla temporal #commands? ¿Nos desplazamos a otro lugar que no sea el siguiente registro en el CURSOR?
Como un servidor SQL determina esto por nosotros, el bucle CURSOR se convierte en un terrible error.
Ahora se da cuenta de por qué es tan crucial especificar explícitamente las opciones SQL CURSOR. Entonces, de ahora en adelante, siempre especifique estos argumentos CURSOR si necesita usar un CURSOR.
El plan de ejecución revela más
El plan de ejecución real tiene algo más que decir sobre lo que sucede cada vez que se ejecuta FETCH NEXT FROM command_builder INTO @command. En la figura 4, se inserta una fila en el índice agrupado CWT_PrimaryKey en la tempdb tabla CWT :

Las escrituras ocurren en tempdb en cada FETCH NEXT. Además, hay más. ¿Recuerda que el CURSOR es OPTIMISTA en la Figura 3? Las propiedades del análisis de índice agrupado en la parte más a la derecha del plan revelan la columna desconocida adicional llamada Chk1002 :

¿Podría ser esta la columna Checksum? El Plan XML confirma que este es el caso:

Ahora, compare el plan de ejecución real de FETCH NEXT cuando el CURSOR sea LOCAL STATIC FORWARD_ONLY READ_ONLY:

Utiliza tempdb también, pero es mucho más simple. Mientras tanto, la Figura 8 muestra el plan de ejecución cuando se usa LOCAL FAST_FORWARD:

Puntos para llevar
Uno de los usos apropiados de SQL CURSOR es generar scripts o ejecutar algunos comandos administrativos hacia un grupo de objetos de base de datos. Incluso si tiene usos menores, su primera opción es usar el CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY o LOCAL FAST_FORWARD. El que tenga un mejor plan y lecturas lógicas ganará.
Luego, reemplace cualquiera de estos con el apropiado según lo dicte la necesidad. ¿Pero sabes que? En mi experiencia personal, solo usé un CURSOR local de solo lectura con recorrido de solo hacia adelante. Nunca necesité hacer el CURSOR global y actualizable.
Además de usar estos argumentos, el momento de la ejecución es importante.
3. Uso del CURSOR de SQL en transacciones diarias
No soy administrador. Pero tengo una idea de cómo se ve un servidor ocupado por las herramientas del DBA (o por cuántos decibeles gritan los usuarios). Bajo estas circunstancias, ¿querrá agregar más carga?
Si está tratando de crear su código con un CURSOR para las transacciones diarias, piénselo de nuevo. Los CURSORES están bien para ejecuciones únicas en un servidor menos ocupado con pequeños conjuntos de datos. Sin embargo, en un día ajetreado típico, un CURSOR puede:
- Bloquear filas, especialmente si el argumento de simultaneidad SCROLL_LOCKS se especifica explícitamente.
- Provocar un uso elevado de la CPU.
- Usar tempdb extensamente.
Imagina que tienes varios de estos ejecutándose simultáneamente en un día típico.
Estamos a punto de terminar, pero hay un error más del que debemos hablar.
4. No evaluar el impacto que trae SQL CURSOR
Sabes que las opciones de CURSOR son buenas. ¿Crees que especificarlos es suficiente? Ya has visto los resultados anteriores. Sin las herramientas, no llegaríamos a la conclusión correcta.
Además, hay código dentro del CURSOR . Dependiendo de lo que haga, agrega más a los recursos consumidos. Estos pueden haber estado disponibles para otros procesos. Toda su infraestructura, su hardware y la configuración de SQL Server agregarán más a la historia.
¿Qué tal el volumen de datos? ? Solo usé SQL CURSOR en unos pocos cientos de registros. Puede ser diferente para ti. El primer ejemplo solo tomó 500 registros porque ese era el número que aceptaría esperar. 10,000 o incluso 1000 no lo cortaron. Se desempeñaron mal.
Eventualmente, no importa cuán menos o más, verificar las lecturas lógicas, por ejemplo, puede marcar la diferencia.
¿Qué sucede si no verifica el plan de ejecución, las lecturas lógicas o el tiempo transcurrido? ¿Qué cosas terribles pueden suceder aparte de las congelaciones de SQL Server? Solo podemos imaginar todo tipo de escenarios del fin del mundo. Entiendes el punto.
Conclusión
SQL CURSOR funciona procesando datos fila por fila. Tiene su lugar, pero puede ser malo si no tienes cuidado. Es como una herramienta que rara vez sale de la caja de herramientas.
Entonces, primero, intente resolver el problema usando comandos basados en conjuntos. Responde a la mayoría de nuestras necesidades de SQL. Y si alguna vez usa SQL CURSOR, úselo con las opciones correctas. Calcule el impacto con el plan de ejecución, STATISTICS IO y xEvent Profiler. Luego, elija el momento adecuado para ejecutar.
Todo esto hará que su uso de SQL CURSOR sea un poco mejor.