En un artículo anterior discutimos el modelo de esquema en estrella. El esquema de copo de nieve está al lado del esquema de estrella en términos de su importancia en el modelado de almacenamiento de datos. Se desarrolló a partir del esquema en estrella y ofrece algunas ventajas sobre su predecesor. Pero estas ventajas tienen un costo. En este artículo, discutiremos cuándo y cómo usar el esquema de copo de nieve.
El esquema del copo de nieve
El nombre del esquema de copo de nieve proviene del hecho de que las tablas de dimensiones se ramifican y se parecen a un copo de nieve. Cuando miramos el modelo de arriba, notaremos que es una tabla de hechos rodeada por algunas tablas de dimensiones, algunas de las cuales hacen la bifurcación antes mencionada. A diferencia del esquema de estrella, las tablas de dimensiones del esquema de copo de nieve pueden tener sus propias categorías.
La idea dominante detrás del esquema de copo de nieve es que las tablas de dimensiones están completamente normalizadas. Cada tabla de dimensiones se puede describir mediante una o más tablas de búsqueda. Cada tabla de búsqueda se puede describir mediante una o más tablas de búsqueda adicionales. Esto se repite hasta que el modelo se normaliza por completo. El proceso de normalización de las tablas de dimensiones del esquema de estrella se denomina copo de nieve.
Escuchará mucho sobre la normalización en este artículo. ¿Qué es la normalización? Básicamente, está organizando una base de datos de una manera que minimiza las redundancias y protege la integridad de los datos. Consulte esta publicación para obtener más información sobre la normalización y la desnormalización.
Ejemplo de esquema de copo de nieve:modelo de ventas
Anteriormente, usamos un esquema de estrella para modelar un departamento de ventas ficticio; esto sería similar a un data mart que se usa para rastrear actividades y resultados de ventas. El modelo tiene cinco dimensiones:producto , tiempo , tienda , ventas tipo y empleado . En el fact_sales tabla, precio y cantidad se almacenan y agrupan en función de los valores de las tablas de dimensiones. Para refrescarte, echa un vistazo al modelo de ventas de esquema en estrella a continuación:
Aquí está el mismo modelo organizado como un esquema de copo de nieve:
El dim_employee y dim_sales_type las tablas de dimensiones son exactamente iguales que en el modelo de esquema en estrella porque ya están normalizadas.
Por otro lado, aplicamos reglas de normalización al resto de las tablas de dimensiones.


El dim_product la tabla de dimensiones del esquema de estrella se divide en dos tablas en el modelo de copo de nieve. El dim_product_type se agregó una tabla para hacer referencia al tipo coincidente en el dim_product mesa. Usando esto, evitamos algunos problemas de integridad de datos.
Es lógico suponer que ya tendremos todos los nombres de productos y sus tipos relacionados insertados como parte del proceso ETL, pero supongamos que necesitamos agregar más nombres y tipos de productos. En un esquema de estrella, podríamos ingresar por error el tipo de producto incorrecto en la tabla. En el esquema del copo de nieve:
- Si encontramos un nuevo nombre de tipo de producto, podemos agregar un nuevo tipo de producto y luego relacionar ese tipo con un registro recién agregado. Sin embargo, esto podría resultar en que el usuario ingrese información incorrecta, al igual que en el esquema de estrella.
- Podríamos verificar si el nombre del producto que queremos agregar ya existe. Si es así, podemos obtener su ID; si no, aparecerá una advertencia preguntándonos si queremos agregar un nuevo producto y un tipo relacionado.

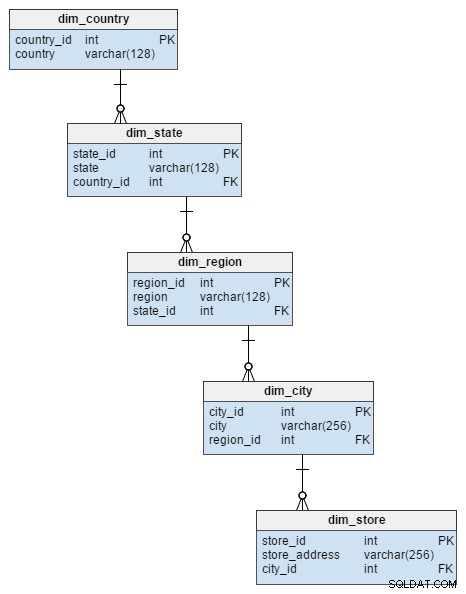
La dim_store La tabla de dimensiones del esquema de estrella está representada por 5 tablas en el esquema de copo de nieve. Estos dividen los atributos de ciudad, región, estado y país que se almacenaron en el dim_store mesa. La normalización de esta tabla no solo evitó el riesgo de integridad de datos, sino que también ahorró algo de espacio en disco.
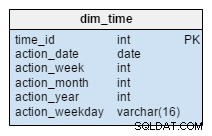
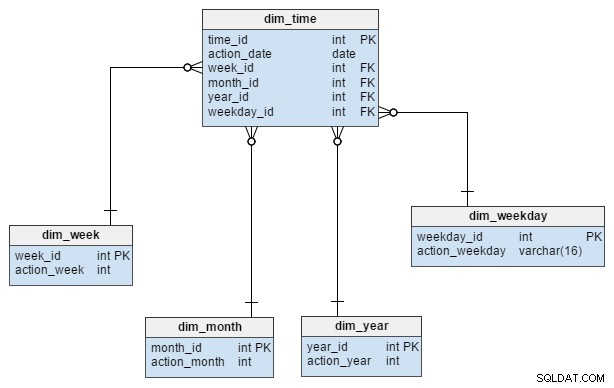
El dim_time dimensión se representa con cinco tablas. Podemos pensar en dim_week , dim_month , dim_year y el dim_weekday tablas como diccionarios que describen el dim_time mesa.
La dim_week , dim_month , dim_year y dim_weekday Las tablas son cuatro jerarquías diferentes que se utilizan para describir nuestra dimensión temporal. Podríamos agregar más dimensiones como cuartos u otras tablas relacionadas si las necesitáramos. En este ejemplo, dim_month es un diccionario que contiene 12 meses; solo de esta dimensión, no tenemos forma de saber a qué año pertenece ese mes; esa es la función del dim_year mesa.
Ejemplo de esquema de copo de nieve:modelo de pedidos de suministro
El otro mercado de datos que discutimos fue para pedidos de suministro. La idea es almacenar y agregar todos los datos de pedidos de suministro para las siguientes cuatro dimensiones:producto , tiempo , proveedor y empleado . Una vez más, echaremos un vistazo al esquema de estrella relevante:
Al convertir esto al esquema de copo de nieve, obtenemos el siguiente modelo:
Se utilizaron las mismas reglas de normalización que las descritas para el modelo de ventas en el dim_product , dim_time y dim_supplier tablas de dimensiones.
Ventajas y desventajas del esquema de copo de nieve
Hay dos ventajas principales al esquema de copo de nieve:
- Mejor calidad de datos (los datos están más estructurados, por lo que se reducen los problemas de integridad de datos)
- Se utiliza menos espacio en disco que en un modelo desnormalizado
La desventaja más notable para el modelo de copo de nieve es que requiere consultas más complejas. Estas consultas, con su mayor número de uniones, podrían disminuir significativamente el rendimiento.
Volveremos a escribir la misma consulta utilizada en el artículo del esquema de estrella para el modelo de ventas del esquema de copo de nieve. Esta es la consulta necesaria para devolver la cantidad de todos los productos de tipo teléfono vendidos en las tiendas de Berlín en 2016:
SELECT dim_store.store_address, SUM(fact_sales.quantity) AS quantity_sold FROM fact_sales INNER JOIN dim_product ON fact_sales.product_id = dim_product.product_id INNER JOIN dim_product_type ON dim_product.product_type_id = dim_product_type.product_type_id INNER JOIN dim_time ON fact_sales.time_id = dim_time.time_id INNER JOIN dim_year ON dim_time.year_id = dim_year.year_id INNER JOIN dim_store ON fact_sales.store_id = dim_store.store_id INNER JOIN dim_city ON dim_store.city_id = dim_city.city_id WHERE dim_year.action_year = 2016 AND dim_city.city = 'Berlin' AND dim_product_type.product_type_name = 'phone' GROUP BY dim_store.store_id, dim_store.store_address
El esquema de Starflake
Un esquema de copo de estrella es una combinación de los esquemas de copo de nieve y estrella. Podemos verlo como un esquema de copo de nieve que tiene algunas tablas de dimensiones desnormalizadas. Cuando se usa correctamente, el esquema de copo de estrella puede brindar un enfoque de lo mejor de ambos mundos. Obviamente, la parte del copo de nieve del modelo debería ahorrar espacio en disco, mientras que la parte de la estrella debería mejorar el rendimiento.
El modelo anterior es básicamente un modelo de copo de nieve con un dim_time mesa. Dado que este esquema reduce la cantidad de uniones de consulta necesarias, podría mejorar el rendimiento. Por otro lado, no perderemos una cantidad notable de espacio en disco, ya que la mayoría de los atributos de la tabla y los atributos de clave externa comparten el int tipo.
El esquema de la galaxia
En el almacenamiento de datos, un esquema de galaxia es cuando dos o más tablas de hechos comparten una o más tablas de dimensiones. Una razón para usar este esquema es ahorrar espacio en disco. Hemos creado un esquema de galaxia de muestra a continuación:
Aquí tenemos dos tablas de hechos, fact_sales y fact_supply_order , que comparten directamente tres tablas de dimensiones:dim_product , dim_employee y dim_time . Tenga en cuenta que incluso dim_store y dim_supplier compartir la misma tabla de búsqueda, dim_city .
Ahorraremos espacio de esta manera, pero debemos tener algunas cosas en mente antes de unir dos data marts (en este caso, pedidos de ventas y suministros) en un esquema de galaxia:
- ¿Hay alguna lógica detrás de unirse a ellos? Por ejemplo ¿Ambos data marts serían utilizados por el mismo departamento?
- ¿Estamos seguros de que necesitamos precisamente la misma dimensión y granulación para ambos data marts?
El esquema de copo de nieve se usa a menudo en el modelado de datos. Puede ser la elección correcta en situaciones donde el espacio en disco es más importante que el rendimiento. Si queremos un equilibrio entre el ahorro de espacio y el rendimiento, podemos usar el esquema starflake. Aún así, el ajuste adecuado para cualquier problema específico depende de muchos parámetros. Esta es una de las áreas de TI donde podemos "jugar" con los factores para encontrar la mejor solución.